错误率前五的神经网络(图-1):

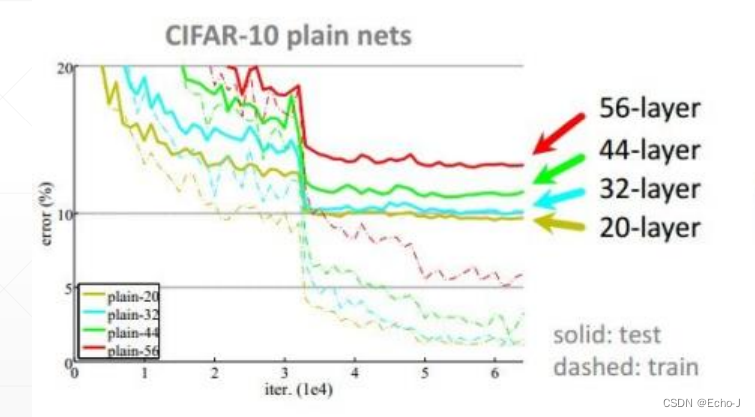
可以很直观的看到,随着层数的增加Error也在逐渐降低,因此深度是非常重要的,但是学习更好的网络模型和堆叠层数一样简单吗?通过实现表明(图-2),并不是如此,会出现梯度消失和梯度爆炸的现象,甚至比堆叠之前的训练效果更差,这种现象被称为梯度退化。
如何保证梯度不退化,即随着堆叠层数的增加,训练模型不会比堆叠之前还要差?深度残差网络(Deep Residual Learning,ResNet)的提出很好的解决了这一问题,并且不仅没有增加额外的参数,也没有增加计算的复杂度。
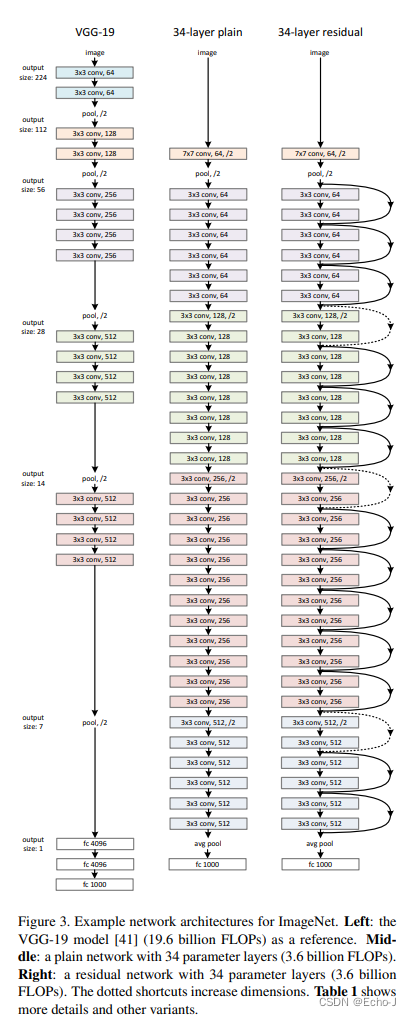
ResNet在普通网络的基础上插入了短路(shortcut connection)(图-3),将这个网络变成了ResNet。
以上的叙述知识思想层面的,将思想转化为实操,离不开背后的数学原理(图-4)。
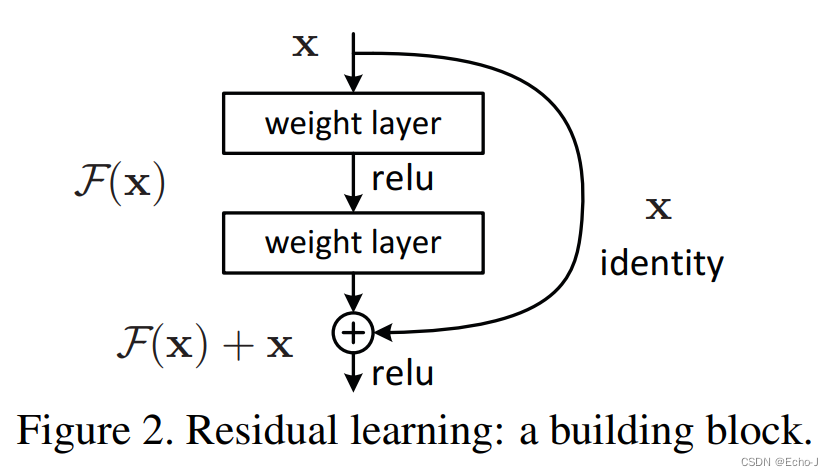
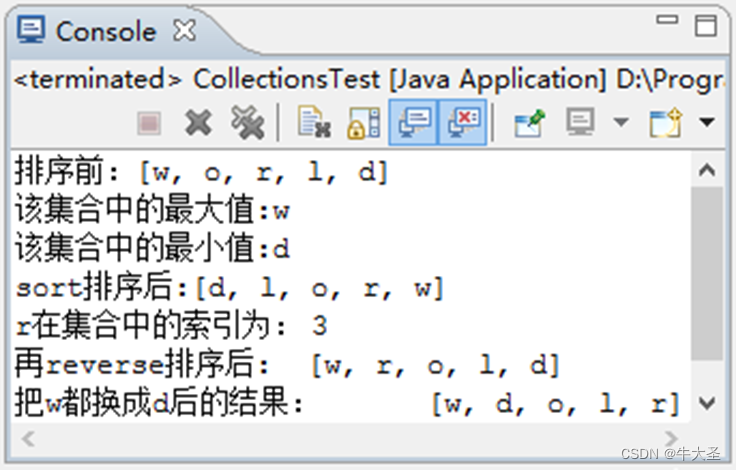
我们将最后的输出设置为 H(x) ,我们将堆叠的非线性层去拟合F(x) = H(x) - x ,原来的映射就变成了F(x) + x (F(x)必须和x的维度相同,如果不相同可是使用1*1卷积或者增加padding)。相当于我们在一些非线性对叠层之间插入了一个短路(shortcut connection),如果堆叠之后的模型的训练Error比之前还要差,就会直接走短路通道,如果堆叠之后的模型比之前好了,就进行堆叠,至于在几个堆叠层之间插入一个短路,这取决于训练的参数。
使用ResNet模型并不需要建立新的求解器,我们可以直接使用公共库,代码演示如下:
class ResBlk(nn.Module):
"""
resnet block
"""
def __init__(self, ch_in, ch_out):
"""
:param ch_in:
:param ch_out:
"""
super(ResBlk, self).__init__()
self.conv1 = nn.Conv2d(ch_in, ch_out, kernel_size=3, stride=1, padding=1)
self.bn1 = nn.BatchNorm2d(ch_out)
self.conv2 = nn.Conv2d(ch_out, ch_out, kernel_size=3, stride=1, padding=1)
self.bn2 = nn.BatchNorm2d(ch_out)
#如果shortcut的输入和输出层的channel不一样,可以用一个1*1的卷积让他们变成一样
self.extra = nn.Sequential()
if ch_out != ch_in:
# [b, ch_in, h, w] => [b, ch_out, h, w]
self.extra = nn.Sequential(
nn.Conv2d(ch_in, ch_out, kernel_size=1, stride=1),
nn.BatchNorm2d(ch_out)
)
def forward(self, x):
"""
:param x: [b, ch, h, w]
:return:
"""
out = F.relu(self.bn1(self.conv1(x))) #激活函数,也可以在上面的网络(第25行)写nn.ReLU
out = self.bn2(self.conv2(out))
# short cut.
# extra module: [b, ch_in, h, w] => [b, ch_out, h, w]
# element-wise add:
out = self.extra(x) + out
return out这个代码来自于课时72 ResNet与DenseNet-2_哔哩哔哩_bilibili
中间关于这个思想的解释来自于我自己对Deep Residual Learning for Image Recognition 论文的理解,如果有什么问题,欢迎各位大佬指正,我将会感激不尽。