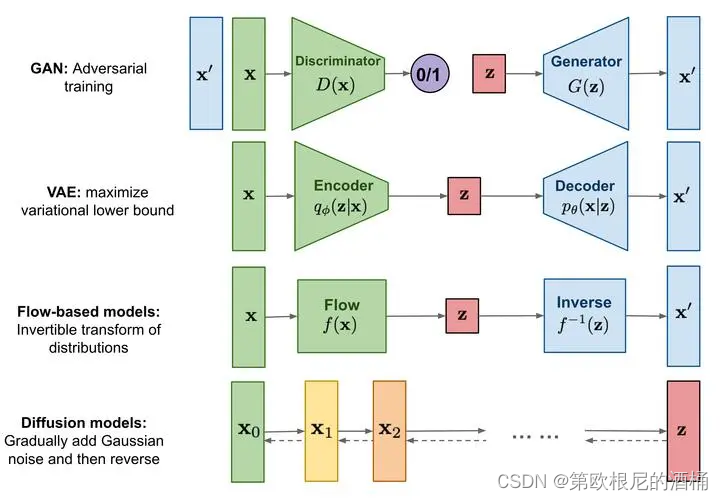
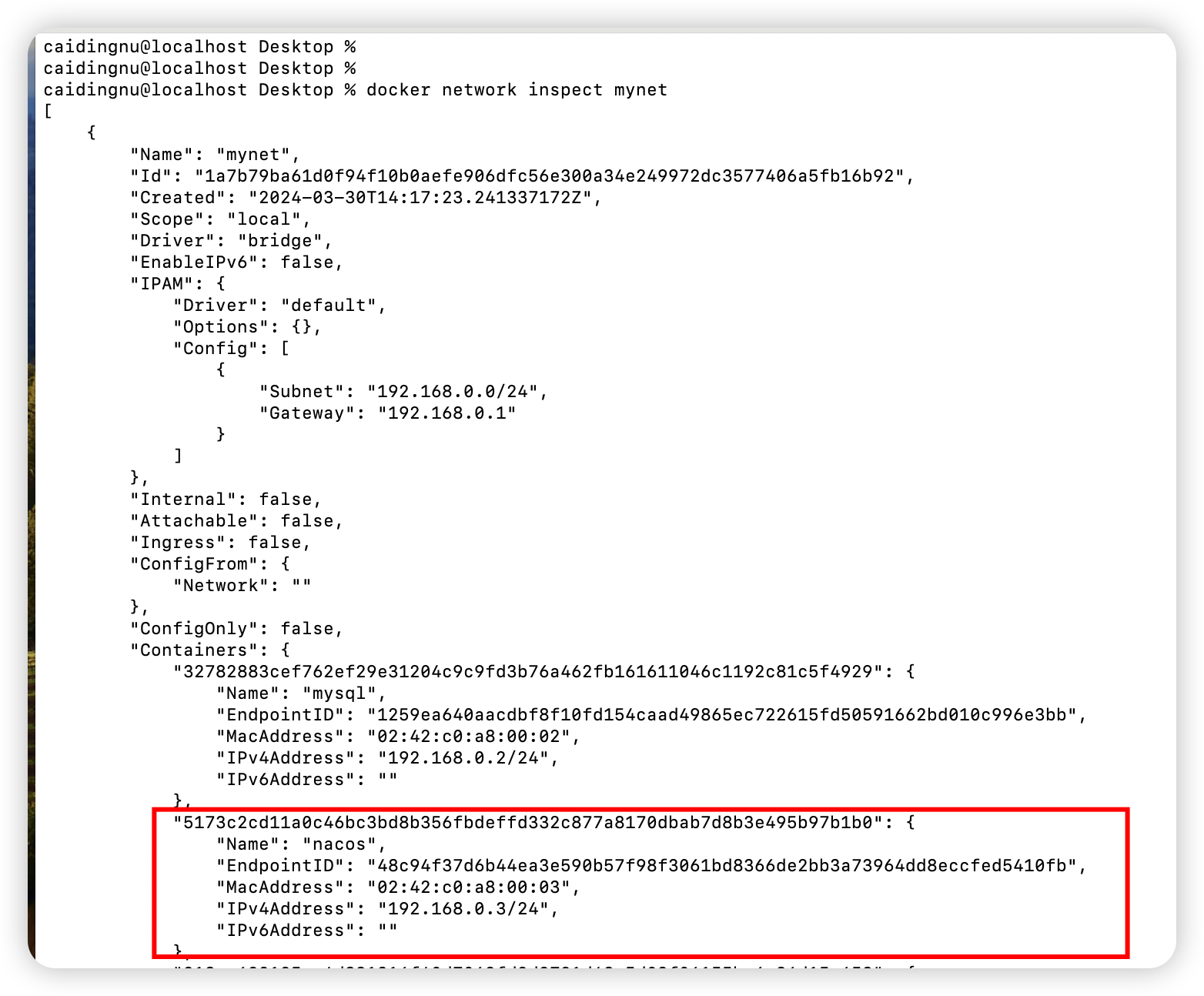
本文为此系列的第三篇WGAN-GP,上一篇为DCGAN。文中仍然不会过多详细的讲解之前写过的,只会写WGAN-GP相对于之前版本的改进点,若有不懂的可以重点看第一篇比较详细。
原理
具有梯度惩罚的 Wasserstein GAN (WGAN-GP)可以解决 GAN 的一些稳定性问题。 具体来说,使用W-loss 作为损失函数替代传统的 BCE 等 loss,并使用梯度惩罚来防止 mode collapse。
- WGAN-GP 使用了 Wasserstein distance(也成为Earth Mover’s distance, EMD)作为训练 GAN 模型的目标函数,Wasserstein distance is a function of amount and distance,体现的是生成的数据的分布移动到真实数据的分布之间所需的距离与量。

随着判别器训练的越来越好,使用 BCE loss 的话会让鉴别器给出接近于 0 或者接近于 1 的极端值,如下为 sigmoid 曲线,极端值的梯度无限接近于 0,这样判别器就没有太多有用的信息反馈给生成器让它学习,导致梯度消失或 model collapse。使用距离的方式可以有效解决,分布距离再远都不再限制。


- BCE loss 本质是一个 minimax game, d 即 discriminator 希望尽可能的 minimize,g 即 generator 希望尽可能的 maximize(意味着造出来的假东西对于鉴别器来说看起来很真实),可以进行如下的简化:

基于 Wasserstein distance 的 W-loss 的的式子与其简化版进行对比:

在 Wasserstein GAN 中不再是 discriminator 了,因为输出不再是 0-1 之间来进行分类,既然不分类了就不是 discriminator 了,而是 critic,所以这里使用 c 代表 critic。critic 希望其尽可能的 maximize,因为希望让 real 和 feak 的距离尽可能的大,起到划清界限的目的;generator 希望其尽可能的minimize,减小两者之间的距离,达到以假乱真的目的。 - mode collapse 即模式崩溃,当生成器学会从单个类生成特征来欺骗鉴别器时,就会发生 mode collapse(陷入一种模式出不来),跟 cnn 的局部最优是一个概念。这会导致输出出现重复,缺乏多样性和细节。
但在使用 W-loss 训练 GAN 时需要对 critic 有一定的条件 —— critic 需要 1-L(1-Lipschitz)连续:
∣
f
(
x
1
)
−
f
(
x
2
)
∣
≤
k
∣
x
1
−
x
2
∣
|f(x_1)-f(x_2)|\le k|x_1-x_2\ |
∣f(x1)−f(x2)∣≤k∣x1−x2 ∣
这里的 k = 1,也就是 critic 的 nn 函数曲线的梯度(斜率)始终在 -1 到 1 之间,即梯度的 L2 范数不超过1:

如图:

曲线的每个点的斜率都是在绿色区域内,很显然这个曲线并不符合。像如下这个曲线就是符合的:

达到 1-L 连续有两种方法:weigh clipping、gradient penalty。
- weigh clipping 将权重裁剪到固定范围内,从而限制 critic 的学习能力。但是这样有缺点,可能让所有参数走极端,要么取最大值要么取最小值,critic 会非常倾向于学习一个简单的映射函数。
- gradient penalty 则是添加一个正则项在 loss function 中,相比 weigh clipping 更加柔和对critic参数的限制更加灵活,通常不会导致梯度消失或梯度爆炸问题。

这里的 λ \lambda λ 为超参值,reg 等于 critic 神经网络梯度范数 -1 的平方,即:

当 critic 神经网络梯度范数 >1 时正则化项发挥作用。平方的作用是为了让其偏离越大,惩罚越大。
这里的 x ^ \hat{x} x^ 为真实数据与生成数据之间随机取样得到的中间数据,随机值 ϵ \epsilon ϵ 作为权重值,假设 ϵ \epsilon ϵ 为0.3,那么 1- ϵ \epsilon ϵ 为0.7。

代码
model.py
from torch import nn
class Generator(nn.Module):
def __init__(self, z_dim=10, im_chan=1, hidden_dim=64):
super(Generator, self).__init__()
self.z_dim = z_dim
# Build the neural network
self.gen = nn.Sequential(
self.make_gen_block(z_dim, hidden_dim * 4),
self.make_gen_block(hidden_dim * 4, hidden_dim * 2, kernel_size=4, stride=1),
self.make_gen_block(hidden_dim * 2, hidden_dim),
self.make_gen_block(hidden_dim, im_chan, kernel_size=4, final_layer=True),
)
def make_gen_block(self, input_channels, output_channels, kernel_size=3, stride=2, final_layer=False):
if not final_layer:
return nn.Sequential(
nn.ConvTranspose2d(input_channels, output_channels, kernel_size, stride),
nn.BatchNorm2d(output_channels),
nn.ReLU(inplace=True),
)
else:
return nn.Sequential(
nn.ConvTranspose2d(input_channels, output_channels, kernel_size, stride),
nn.Tanh(),
)
def forward(self, noise):
x = noise.view(len(noise), self.z_dim, 1, 1)
return self.gen(x)
class Critic(nn.Module):
def __init__(self, im_chan=1, hidden_dim=64):
super(Critic, self).__init__()
self.crit = nn.Sequential(
self.make_crit_block(im_chan, hidden_dim),
self.make_crit_block(hidden_dim, hidden_dim * 2),
self.make_crit_block(hidden_dim * 2, 1, final_layer=True),
)
def make_crit_block(self, input_channels, output_channels, kernel_size=4, stride=2, final_layer=False):
if not final_layer:
return nn.Sequential(
nn.Conv2d(input_channels, output_channels, kernel_size, stride),
nn.BatchNorm2d(output_channels),
nn.LeakyReLU(0.2, inplace=True),
)
else:
return nn.Sequential(
nn.Conv2d(input_channels, output_channels, kernel_size, stride),
)
def forward(self, image):
crit_pred = self.crit(image)
return crit_pred.view(len(crit_pred), -1)
train.py
import torch
from torch import nn
from tqdm.auto import tqdm
from torchvision import transforms
from torchvision.datasets import MNIST
from torchvision.utils import make_grid
from torch.utils.data import DataLoader
import matplotlib.pyplot as plt
from model import *
torch.manual_seed(0) # Set for testing purposes, please do not change!
def show_tensor_images(image_tensor, num_images=25, size=(1, 28, 28)):
image_tensor = (image_tensor + 1) / 2
image_unflat = image_tensor.detach().cpu()
image_grid = make_grid(image_unflat[:num_images], nrow=5)
plt.imshow(image_grid.permute(1, 2, 0).squeeze())
plt.show()
def get_noise(n_samples, z_dim, device='cpu'):
return torch.randn(n_samples, z_dim, device=device)
n_epochs = 100
z_dim = 64
display_step = 50
batch_size = 128
lr = 0.0002
beta_1 = 0.5
beta_2 = 0.999
c_lambda = 10
crit_repeats = 5
device = 'cuda'
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.5,), (0.5,)),
])
dataloader = DataLoader(
MNIST('.', download=False, transform=transform),
batch_size=batch_size,
shuffle=True)
gen = Generator(z_dim).to(device)
gen_opt = torch.optim.Adam(gen.parameters(), lr=lr, betas=(beta_1, beta_2))
crit = Critic().to(device)
crit_opt = torch.optim.Adam(crit.parameters(), lr=lr, betas=(beta_1, beta_2))
def weights_init(m):
if isinstance(m, nn.Conv2d) or isinstance(m, nn.ConvTranspose2d):
torch.nn.init.normal_(m.weight, 0.0, 0.02)
if isinstance(m, nn.BatchNorm2d):
torch.nn.init.normal_(m.weight, 0.0, 0.02)
torch.nn.init.constant_(m.bias, 0)
gen = gen.apply(weights_init)
crit = crit.apply(weights_init)
def get_gradient(crit, real, fake, epsilon):
# Mix the images together
mixed_images = real * epsilon + fake * (1 - epsilon)
# Calculate the critic's scores on the mixed images
mixed_scores = crit(mixed_images)
# Take the gradient of the scores with respect to the images
gradient = torch.autograd.grad(
inputs=mixed_images,
outputs=mixed_scores,
# These other parameters have to do with the pytorch autograd engine works
grad_outputs=torch.ones_like(mixed_scores),
create_graph=True,
retain_graph=True,
)[0]
return gradient
def gradient_penalty(gradient):
# Flatten the gradients so that each row captures one image
gradient = gradient.view(len(gradient), -1)
# Calculate the magnitude of every row
gradient_norm = gradient.norm(2, dim=1)
# Penalize the mean squared distance of the gradient norms from 1
penalty = torch.mean((gradient_norm - 1) ** 2)
return penalty
def get_gen_loss(crit_fake_pred):
gen_loss = -1. * torch.mean(crit_fake_pred)
return gen_loss
def get_crit_loss(crit_fake_pred, crit_real_pred, gp, c_lambda):
crit_loss = torch.mean(crit_fake_pred) - torch.mean(crit_real_pred) + c_lambda * gp
return crit_loss
cur_step = 0
generator_losses = []
critic_losses = []
for epoch in range(n_epochs):
# Dataloader returns the batches
for real, _ in tqdm(dataloader):
cur_batch_size = len(real)
real = real.to(device)
mean_iteration_critic_loss = 0
for _ in range(crit_repeats):
### Update critic ###
crit_opt.zero_grad()
fake_noise = get_noise(cur_batch_size, z_dim, device=device)
fake = gen(fake_noise)
crit_fake_pred = crit(fake.detach())
crit_real_pred = crit(real)
epsilon = torch.rand(len(real), 1, 1, 1, device=device, requires_grad=True)
gradient = get_gradient(crit, real, fake.detach(), epsilon)
gp = gradient_penalty(gradient)
crit_loss = get_crit_loss(crit_fake_pred, crit_real_pred, gp, c_lambda)
# Keep track of the average critic loss in this batch
mean_iteration_critic_loss += crit_loss.item() / crit_repeats
# Update gradients
crit_loss.backward(retain_graph=True)
# Update optimizer
crit_opt.step()
critic_losses += [mean_iteration_critic_loss]
### Update generator ###
gen_opt.zero_grad()
fake_noise_2 = get_noise(cur_batch_size, z_dim, device=device)
fake_2 = gen(fake_noise_2)
crit_fake_pred = crit(fake_2)
gen_loss = get_gen_loss(crit_fake_pred)
gen_loss.backward()
# Update the weights
gen_opt.step()
# Keep track of the average generator loss
generator_losses += [gen_loss.item()]
### Visualization code ###
if cur_step % display_step == 0 and cur_step > 0:
gen_mean = sum(generator_losses[-display_step:]) / display_step
crit_mean = sum(critic_losses[-display_step:]) / display_step
print(f"Step {cur_step}: Generator loss: {gen_mean}, critic loss: {crit_mean}")
show_tensor_images(fake)
show_tensor_images(real)
step_bins = 20
num_examples = (len(generator_losses) // step_bins) * step_bins
plt.plot(
range(num_examples // step_bins),
torch.Tensor(generator_losses[:num_examples]).view(-1, step_bins).mean(1),
label="Generator Loss"
)
plt.plot(
range(num_examples // step_bins),
torch.Tensor(critic_losses[:num_examples]).view(-1, step_bins).mean(1),
label="Critic Loss"
)
plt.legend()
plt.show()
cur_step += 1

代码讲解
网络模型与上一篇的DCGAN没有变动。

这个模块进行梯度计算,即上文原理中正则项公式里面的梯度L2范数里的梯度。首先计算真实数据与生成数据之间随机取样的混合数据,然后输入 critic,最后计算出其梯度。

梯度惩罚模块,即上文原理中的整个正则项公式,梯度范数 -1 的平方。

critic 的 loss function 公式如下,generator 因为和真实数据无关,且与正则项也无关,所以只有中间一项。
 ————————————————————————————————————————————
————————————————————————————————————————————
总之,WGAN-GP 不一定要提高 GAN 的整体性能,但会很好的提高稳定性并避免模式崩溃。
下一篇条件生成GAN。