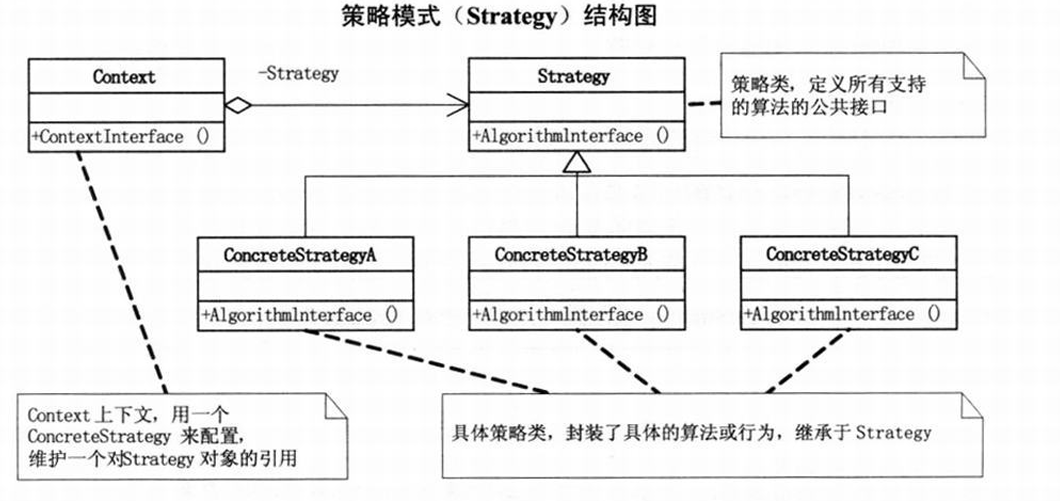
文章目录
- 阻塞控制
- 面向字节流
- TCP链接异常
本篇总结TCP的最后一点小知识
阻塞控制
首先对于阻塞控制的概念是,它是和网络环境息息相关的
如果在发送数据的时候出现问题,不仅仅是由于对方链接出错,其实还和当前的网络情况有关,假设现在有下面的这样的场景:当客户端和服务器进行通信的时候,如果出现了少量的丢包,那么可能是发出端和接收端有部分的问题,但是如果要是绝大多数的包都被丢掉了呢?那这意味着一定不是服务端和客户端这两个端口的问题,而是问题来源于网络本身,当网络通信中如果出现了大量的丢包,那么就意味着可能是因为网络本身出现问题,那如何理解网络本身出现问题呢?
最极端的情况是网卡这样的硬件设备出问题,这是可能导致出错的原因之一,也可能是由于在网络中的数据量过大,导致的一系列问题,引起了阻塞的现象,但是不管怎么样,在进行网络传输的时候都要对于网络的健康状况进行一个综合的评估,那么如何进行评估呢?
假设现在通信的双方进行了评估之后,发现了出现了大量的丢包,那么就意味着可能会有网络本身的问题,这个现象可以通过在滑动窗口内的数据来判断,如果在短时间内滑动窗口中的大部分数据都超时了,此时就意味着是网络出现了问题,而一旦网络出现了问题之后,TCP本身也无法改变什么
假设现在出现了大量的报文丢失,那发送方应该做什么呢?应该大量进行补发吗?结论当然是不能了,因为现在的网络处于一个瘫痪的状态,继续发包还依旧可能会导致阻塞丢失的问题,所以此时所有在这个网络当中的TCP设备都应该停止进行网络消息的发送
这才是对于TCP协议的理解,TCP协议不仅仅是在两个和主机相关的设备上进行协议约定,同时对于整个处于网络中的设备来说都有很强的协议性,这个叫做是达成了共识,因此现在看当发现网络不能进行发送的时候,发送方就会选择等一等再发送,那它会选择什么时候继续发送呢?
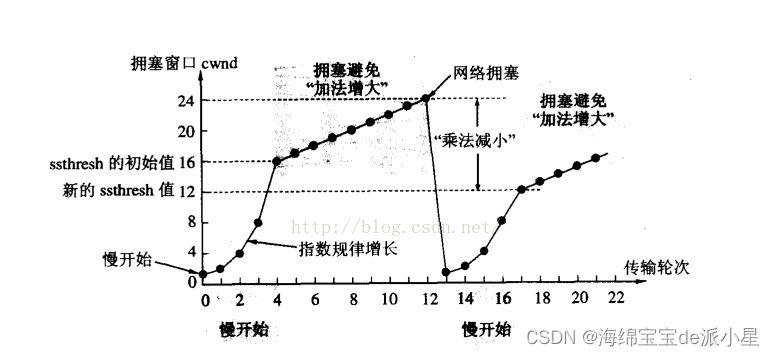
按正常逻辑来说,想要判断能不能继续发送,可以先试探性的发一个报文看看情况,而实际的运用中也确实如此,当出现这样的情况触发超时重传的机制后,就会一个报文一个报文的试探性的发送,如果在重发的时候发现成功了,那么就在此基础上进行指数级的增长发送报文的数量
阻塞窗口
为了更方便的描述上面的这些信息,我引出一个新的概念叫做阻塞窗口
在最开始的时候,可以把阻塞窗口设置为1
那接收端反馈的窗口大小和阻塞窗口有什么关系呢?
接收端反馈的窗口大小表示的是对方的接收能力,在滑动窗口的理解中我们写到,滑动窗口的大小是由对方的接收端的反馈窗口大小决定的,这样的说法其实并不准确,而是与阻塞窗口取最小值,这个最小值才是滑动窗口的真正大小
反馈窗口反应的是对方主机的接收能力,而如果对方的主机已经在等待接受数据,接受能力非常强,但是这一定意味着传递过去的数据都能被正常的接收吗?这和网络状况是有关系的。同理,对于阻塞窗口来说,反应的是网络状况,那网络状况非常好的情况下,在不考虑对方接收能力的情况下就去发送消息,其实也是不合逻辑的,所以才有了上面的结论,滑动窗口的大小其实是综合考虑了网络状况和对方的接收能力,最终得出的一个结论
所以在网络通信中要正确进行理解,有三种窗口,滑动窗口,接收窗口,阻塞窗口,在实际的TCP传输数据的过程中,一定是这三个窗口进行相互配合,又要考虑网络,又要考虑接收能力,综合考量进行数据的传输
慢启动
因此在实际的传输过程中,一定是先发送少量的数据,再发送大量的数据,前期的过程就叫做是慢启动的过程,通过调整运作窗的大小来进行动态控制,而调整滑动窗口的大小从而进行发送数据量的大小,这整个过程就是慢启动的过程
而当发送了几个报文,发现都成功了,那么此时TCP就判断这个网络环境还不错,是一个健康的环境,所以就可以开始大量的发送报文了,此时发送的报文数量就应该由对方的接收能力来进行决定了
面向字节流
在之前的内容中其实对于面向字节流这个概念已经谈过了很多次,但是这里是真正进行说这个面向字节流,TCP的Socket是要在内核当中为这段链接创建一个对应的发送缓冲区和接受缓冲区,而整个TCP正是因为有这个缓冲区的存在,所以在进行写入的时候可以直接向缓冲区中写入对应比如100个字节的数据,而不用考虑对方是如何进行写入的,而对方也可以不用关心你是怎么写的,它只关心它该用什么策略去读,读多少,这个完全不需要进行匹配的过就叫做是面向字节流
那站在上层的角度来看,可能现在对方给我发了十个报文,我都没时间接收,等我有时间的时候一口气把这十个报文都接收了,这叫面向字节流,而对于UDP来说,它是面向数据报的,这也就意味着对方发多少次,我就要收多少次
如果想要对于面向字节流更加深刻的理解,我将从两个层面上来对于面向字节流进行阐述
1. 生活的角度
站在生活的角度来说,UDP其实和邮件是一样的,对方发多少次,就要接收多少次,这就是面向数据报,而在UDP的报文中,是存在有报文自身的大小的,这也就意味着作为发送方必须要把UDP完整的报文直接发过去,而UDP是没有接收和发送缓冲区的,这也就意味着直接把有效载荷加上报头组成报文就发出去了,而站在接收方的角度来说,它可以根据报头中的长度直接把有效载荷读出来,交付给上层,那上层此时就已经有了完整的UDP报文了,这个就叫做是面向数据报
2. 站在TCP的角度
那再看看TCP,对于TCP来说,客户端和服务器都有自己的接收缓冲区和发送缓冲区,那么用户构建的请求或者是自己定义的要存储到缓冲区当中的数据,并不是直接发送到对方的缓冲区中,向平时使用的read和write的这些接口,本质上其实都是把数据拷贝到对应的发送缓冲区中,那么拷贝到发送缓冲区其实就是按照字节的方式在缓冲区里面把数据存储起来,而在这当中又会有对应的滑动窗口这些概念,那么在后续想要进行发送的时候,如果发错了之后要进行如何的处理,这一切都是由对应的TCP来进行处理
那么假设现在要发送一段数据,有1000个字节,那么在进行发送的时候就把这1000个字节单独拿过来,之后就给他拼接上对应的TCP的报头,有了TCP的报头之后就把它给下层,然后进行传输,传输过去了以后到了对方的缓冲区当中,再进行报头和有效载荷的分离,在当前的发送端的缓冲区中是什么样子,发送过去就还是什么样子,但是因为对应的TCP发送数据以及对方的TCP接收数据和上层用户读取数据,这些过程是没有明显的步调,换句话说是在这个传输的过程中,可能在操作系统当中的内核部分已经存储了很多的数据了,那么在上层进行读取的时候,可能会把一个半或者两个半读取上去,内核当中的数据被用户读走完全是由用户自己决定的,那么对于发送方来说,可能要从用户层拷贝到内核层,拷贝了好多次,这些数据都是以字节的方式来呈现出来的,TCP就根据当前网络的状况以及对方的接收缓冲区的带下进行综合评估,可以发送多少字节的数据
但是现在的问题是,缓冲区当中可能有4个请求,但是上层看到的就是一些字节,上层是网络服务器,假设现在一个请求是40字节,那么对于TCP来说,它只负责怎么能把这160个字节更加高效的,安全的弄到对面的缓冲区当中,而至于这些字节的信息怎么被上层解析,或者封装,这些操作完全是由用户层自己来进行决定的,换句话说,对于TCP这一层压根就不关心上层协议是什么,它关心的是需要它发多少个字节,需要给对方传递的字节数有多少,传递到对方之后,它只需要关心的时候上层可以使用多少字节就可以,所以对于TCP来说,它关心的内容只有字节的概念,对应的TCP其实就是不断的需要把数据从发送缓冲区拷贝到接收方的接收缓冲区当中,由于存在数据流动的原因,此时的TCP只认识字节,在发送的时候字节信息就会源源不断的进入队列当中,然后进出到缓冲区当中,这样的存在一个字节流动的概念,我们就称他为叫做面向字节流
因此假设现在对应的内核发送了160个字节过来,站在上帝视角我们知道这160个字节是4个请求,但是站在内核的角度却不知道,它看起来就是160个字节而已,那么这就意味着在代码中一定是要进行边读边进行解析的,如果解析成功了我们就拿到了一个请求,如果解析不成功就下次再读,这也就是为什么在之前进行的代码中,对于accept一个套接字当中,缓冲区的内容是无脑写的,直接进行无脑读就可以,因为实际上并不清楚一个请求的报文有多大,所以定义出来具体的大小其实也没什么用,更何况TCP本身就是变长的,它并不知道具体的信息有多少,所以在之前的代码当中,就是无脑的把对应的信息传递给用户,然后用户直接进行报文的解析,解析的时候如果返回值为空,就表示解析报文失败了,也就意味着这个报文并不是一个完整的报文,那么就进行break,那么返回之后就让外部进行重新的拼接,而当如果解析成功了之后,就可以返回给上层了
在之前的代码中有对于这样encode和decode这样的概念,所谓decode就是把数据从用户传递到缓冲区当中,在用户层的访问当中就根据分割符来判断有没有一个完整的请求,如果有这个完整的请求就把完整的请求读出来,读出来之后就把对应的报头去掉,取出来它的有效载荷,这就是最开始设计代码时候的逻辑
说白了,对于接收方来讲,其实它并不知道这些数据该如何进行解析,甚至可能一个报文40字节,它只是传递了20字节过去,这个报文压根就不完整,那么即使读上去了也不知道这个报文是什么意思,所以在上层中对于收到的数据来说,就要在上层的用户层定义一个缓冲区,然后把内核当中接受到的数据都依次拼接到对应的用户缓冲区当中,未来对于用户缓冲区的内容来进行判断如何进行解析,所以这就叫做是TCP的面向字节流
在TCP协议的定制中其实也能看出来,TCP的协议定制其实是没有对应的报文长度的,这是因为TCP协议中本身是存在有序号的概念的,这个序号就已经可以保证我们数据段的一个按序性,而TCP的链接是可靠的,这就意味着当底层收到了一个TCP的报文之后,它要做的工作并不是说要把这个有效载荷和报文进行分离,而是只需要把这些数据放到自己的缓冲区中就可以了,这也就是为什么TCP压根不带长度的原因,因为它压根就不需要,从建立链接开始到最后断开连接释放,从此往后只有一个面向字节流的概念了,只需要把序号拼在一起就可以了,双方缓冲区的数据都不用进行处理,只需要把信息传递给上层,让上面的应用层来处理
换句话说,在当年的TCP Socket通信的时候,当时写的对于测试代码造成的效果是,发送端发送了一个报文,对应的接收端收到了,那接收端收到这个报文,这个感觉其实是不对的,比如现在有一个数据,要进行send或者write,本质上来说其实就是把这个数据拷贝到了对应的发送缓冲区当中,具体的数据发送多少,怎么发送,一次发多少,发错了怎么办,这些数据其实用户都不清楚,也不用清楚,而发送到接受缓冲区当中,是全都接收了,还是只接收了半个,哪怕是接收方它也是不清楚的,只能是把这些数据都读上来,然后再进行解析,并不是和UDP一样发一个我收一个
在网络带宽压力不大的情况下,TCP的传输是正常的,我们可以做到收一个发一个这样的情况,但是如果网络压力比较大的情况下,比如发的报文是Hello World,那么可能一次只传过去一个Hello,而这个World还需要下次再进行传输,那如果上层已经读取了呢?这就意味着上层必须要先缓存起来这个Hello,然后下次再一起读到这个World进行匹配信息
TCP链接异常
假设现在客户端和服务器已经可以正常通信了,那么就意味着它们已经正常的三次握手成功了,那在进行建立链接的时候一定是要有通过网络的,但是如果要是突然有一个服务掉了,进程终止了,那么此时曾经建立的链接该怎么办呢?
进程不管是正常终止还是异常终止,都是终止了,而链接本身是和文件有关系的,每创建一个套接字,就要在对应的系统中新增一个文件描述符,而文件的生命周期是随进程的,这也就是意味着不管进程是怎么终止了,操作系统都不会允许这个模块的错误导致另外一个模块也出错,所以操作系统也会和普通进程出错一样,把对应的空间释放,占用释放,就好像这个进程从来没出现过一样,对于TCP来说,出错之后也会进行正常的四次挥手,把链接断开就可以了




![[激光原理与应用-82]:激光器研发常见难题](https://img-blog.csdnimg.cn/direct/82855060120e4189829dadfed119eaec.png)