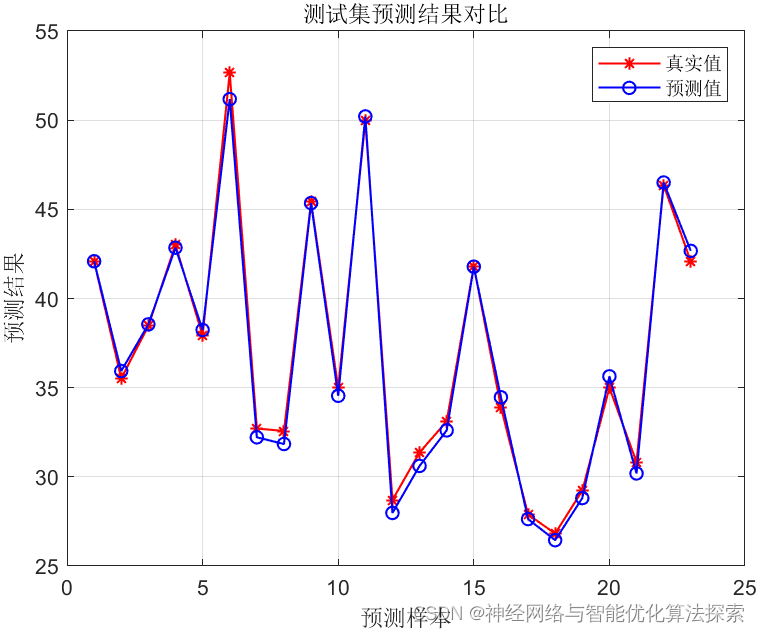
对于AI大模型未来发展趋势与挑战的个人看法:
1、未来的发展趋势:

AI大模型未来发展趋势可以从以下几个关键方面来讨论:
1. 能源与计算效率
- 绿色计算与节能技术:随着硬件技术的发展,预计未来的AI大模型将进一步降低能源消耗,采用更高效的处理器、专门针对AI任务设计的定制芯片(如TPU、IPU等),以及热管理和冷却技术的改进,减少碳排放,推动可持续发展。
- 算法优化:研究人员将继续研发新的训练方法,如动态缩放、稀疏化训练、量化训练等,旨在在不影响模型性能的前提下,大幅减少计算需求和能源消耗。
2. 算法创新
- 模型结构创新:新型神经网络结构(如Transformer、Mixture-of-Experts架构等)将继续涌现,以实现更高的学习能力和更强的泛化性能,同时兼顾计算效率。
- 元学习与终身学习:大模型将具备更好的自我更新与持续学习能力,无需从头开始训练就能适应新任务和新场景,大大减少了整体的训练成本。
3. 模型进化
- 模型精简与轻量化:大模型的小型化将是重要趋势,通过知识蒸馏、模型剪枝、权重共享等方式,使得大模型的能力能够嵌入到小型模型中,在边缘设备上实现更快捷高效的部署。
- 自监督与无监督学习:随着数据获取成本的增加和隐私保护意识的提高,大模型将更加依赖于自监督和无监督学习技术,减少对大量标注数据的依赖。
4. 分布式与边缘计算
- 分布式训练与推理:大模型训练将更加依赖于分布式系统,并利用云计算和边缘计算的优势,实现更快的训练速度和更低的延迟响应,尤其是在物联网和实时分析场景中。
- 边缘智能与端侧推理:随着计算资源向边缘节点下沉,大模型将适应更广泛的部署环境,例如通过微调、模型分割等技术实现在智能手机、IoT设备上的本地推理。
5. 模型解释性和透明度
- 可解释AI:未来的大模型不仅要具备高性能,还需要更加透明和可解释,以便用户理解和信任模型决策过程,满足法规监管和社会伦理的要求。
6. 融合跨学科技术
- 跨模态学习:AI大模型将整合视觉、听觉、语言等多种模态信息,实现跨模态理解和生成,催生更多元化的应用场景。
- 量子计算结合:长远来看,随着量子计算技术的发展,量子机器学习有可能为大模型带来指数级的性能提升,打破现有计算能力的天花板。
个人认为AI大模型的未来发展将以解决上述挑战为导向,逐步实现模型的智能化、节能化、自主化和普适化,赋能各行各业,并促进人机共生与和谐发展。

2、当前面临的主要挑战:
AI大模型学习的未来发展离不开在能源、算法、模型效率、技术实施以及伦理安全等多方面的深入研究和技术创新。那当前面临的主要挑战也可以从能源消耗、算法优化、模型效率与鲁棒性、技术瓶颈以及伦理与安全问题等方面来讨论说明:
1. 能源与计算资源挑战
能源消耗:训练大模型特别是那些拥有数十亿乃至数千亿参数的模型,需要庞大的计算资源和能源投入。研究表明,大型AI模型的训练可能产生相当于上百户家庭一年的能耗,这不仅对环境构成压力,也加剧了数据中心的运营成本和可持续性问题。
硬件设施与基础设施建设:随着模型规模的不断扩大,对计算硬件的需求也在激增。现有的GPU集群和其他加速器设备可能不足以满足训练大模型的速度和效率要求,需要更高性能、更低能耗的AI专用芯片和更先进的数据中心设计。
2. 算法与优化挑战
算法效率:目前大模型的训练依然依赖于大量的数据和计算量,如何设计出更为高效、低耗的训练算法,例如改进的优化器、正则化策略、自适应学习率调整等,以降低训练时间和资源消耗,是一个重要挑战。
模型压缩与知识蒸馏:在保持模型性能的同时,减小模型大小,使之能在边缘设备上运行,或者在有限资源条件下实现快速推理,是大模型部署的关键问题之一。
3. 模型效能与鲁棒性挑战
泛化能力与过拟合:大模型虽具有强大的学习能力,但也更容易过拟合,特别是在少量标注数据的情况下,如何确保模型在未见过的数据上仍能表现良好,是提升模型泛化能力的重要议题。
模型稳定性与鲁棒性:大模型容易受到对抗样本攻击,且在处理噪声数据时表现不稳定,如何增强模型的鲁棒性,使其能够在各种情况下稳定输出,是一项核心技术难题。
4. 技术瓶颈
分布式训练与协同学习:随着模型参数数量的增长,如何有效利用分布式计算系统,协调大规模GPU集群进行并行训练,同时解决通信开销、数据一致性等问题,是一大挑战。
存储与传输:大模型的参数量庞大,存储和传输这些模型文件需要大量的存储空间和高速稳定的网络连接,这在实际应用中构成了技术瓶颈。
5. 伦理与安全挑战
伦理价值对齐:大模型可能无意中学习到并输出带有偏见、歧视或有害信息,如何实现价值对齐,确保模型生成的内容符合社会伦理规范,是一个新兴的研究热点。
数据隐私与安全:在处理个人数据时,保护用户隐私不受侵犯,防止数据泄露,以及防范模型被恶意利用进行欺诈、攻击等行为,是AI大模型技术发展的必要保障。