背景
【DA-CLIP】生成图像描述generate_captions.py代码理解+实践-CSDN博客![]() https://blog.csdn.net/m0_60350022/article/details/137180758?spm=1001.2014.3001.5502生成csv文件
https://blog.csdn.net/m0_60350022/article/details/137180758?spm=1001.2014.3001.5502生成csv文件

参考md.
条件有限我只看单GPU训练的,还有一个四GPU的分布训练配置
cd ./src
python -m training.main \
--save-frequency 1 \
--zeroshot-frequency 1 \
--report-to tensorboard \
--train-data="datasets/universal/daclip_train.csv" \
--val-data="datasets/universal/daclip_val.csv" \
--csv-img-key filepath \
--csv-caption-key title \
--warmup 100 \
--batch-size=784 \
--lr=2e-5 \
--wd=0.05 \
--epochs=30 \
--workers=8 \
--model daclip_ViT-B-32 \
--name "daclip_ViT-B-32_b784x1_lr2e-5_e50" \
--pretrained "laion2b_s34b_b79k" \
--da
您还可以更改模型并删除`——da`选项以启用正常的CLIP训练/微调。
运行training模块文件的主函数 ,扒了一下模块在这
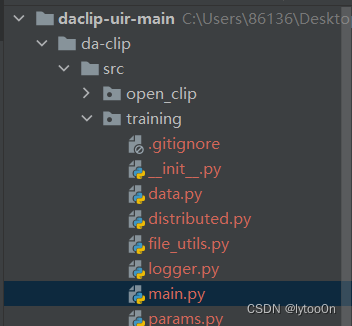
写成py去运行 。记得放在daclip/src下下面有几个错误就是由于这个问题
import subprocess
# 修正后的命令,移除了反斜杠续行符
command = [
"python", "-m", "training.main",
"--save-frequency", "1",
"--zeroshot-frequency", "1",
"--report-to", "tensorboard",
"--train-data", "datasets/universal/daclip_train.csv",#地址要改
"--val-data", "datasets/universal/daclip_val.csv",
"--csv-img-key", "filepath",
"--csv-caption-key", "title",
"--warmup", "100",
"--batch-size", "784",
"--lr", "2e-5",
"--wd", "0.05",
"--epochs", "30",
"--workers", "8",
"--model", "daclip_ViT-B-32",
"--name", "daclip_ViT-B-32_2024_3_30_23_39",
"--pretrained", "laion2b_s34b_b79k" #这可能要改
# "--da"
# 这里假设 --da 参数已经被正确添加和赋值
]
# 执行命令
subprocess.run(command, shell=True)建议看完我的报错再运行
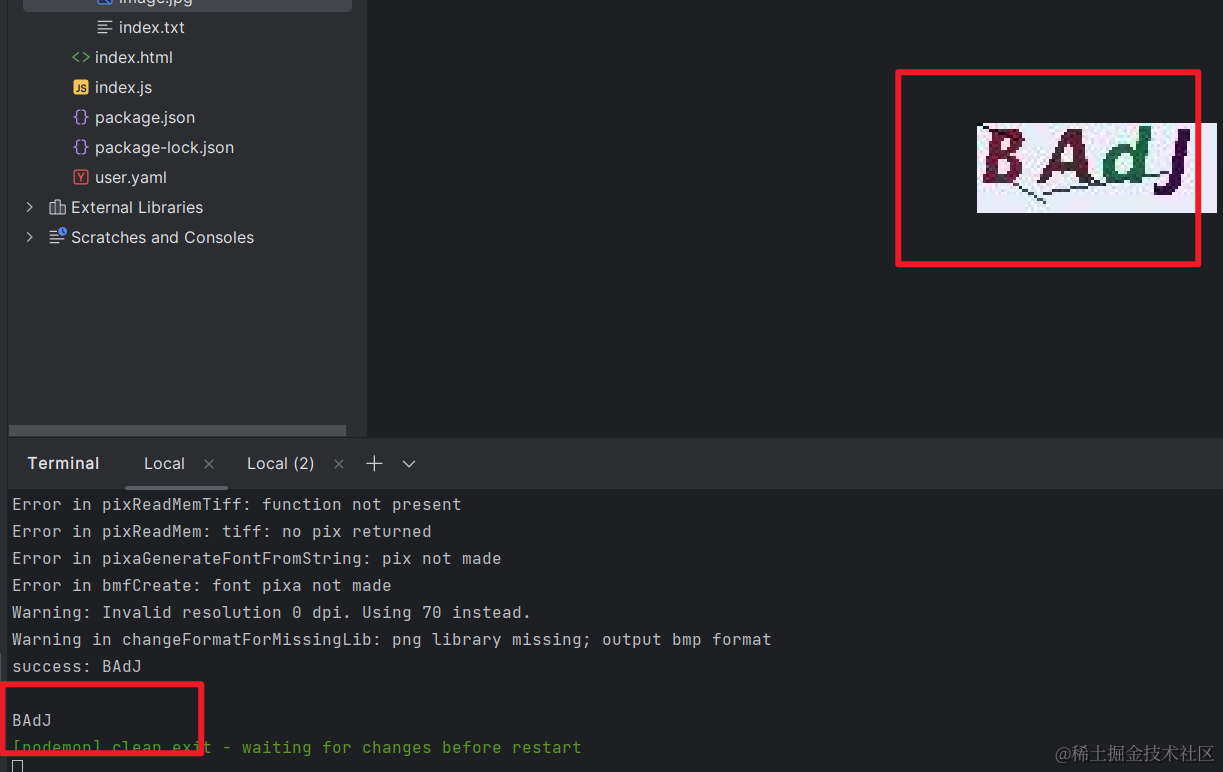
报错 ModuleNotFoundError: No module named 'braceexpand'
pip装一下
No module named 'webdataset'
pip
RuntimeError: Model config for daclip_ViT-B-32 not found.
尴尬了明明是有的。

我寻思是不是--da参数是完整的,把参数da补上
main.py: error: ambiguous option: --da could match --dataset-type, --dataset-resampled
我觉得--da确实是不完整的。。。
报错的包是环境open_clip里的,但是写了daclip判断的包在项目的open_clip
当您在项目中重写了
open_clip的factory.py代码,但是调用时却使用了环境的open_clip包,这通常是因为Python的模块搜索路径(sys.path)导致的。Python解释器会在sys.path中列出的目录中查找要导入的模块。如果环境的open_clip包在搜索路径中的位置比您的项目目录更靠前,它将优先被导入。
import sys
from pathlib import Path
# 将项目目录添加到sys.path的开头
project_dir = Path(__file__).parent.parent # 根据实际情况调整
sys.path = [str(project_dir)] + sys.path
# 现在尝试导入重写的open_clip
import open_clip.factory还是不行,感觉是太多层调用了
pip还删不了


原来用的环境的training而不是项目的
把刚刚写的py放在daclip/src下.解决
Error. Experiment already exists. Use --name {} to specify a new experiment.
实验名称重复,找到--name修改你想要的实验名称
huggingface_hub.utils._errors.LocalEntryNotFoundError: An error happened while trying to locate the file on the Hub and we cannot find the requested files in the local cache. Please check your connection and try again or make sure your Internet connection is on.
又想下东西了,原来是参数用的是laion2b_s34b_b79k模型,而不是作者训练好的模型。
"--pretrained", "laion2b_s34b_b79k"
直接修改为我的地址
"--pretrained", "E:\\daclip\\pretrained\\daclip_ViT-B-32.pt"
FileNotFoundError: [Errno 2] No such file or directory: 'datasets/universal/daclip_train.csv'
修改到daclip/src后该相对地址失效
改为绝对地址
1Torch was not compiled with flash attention:The size of tensor a (39) must match the size of tensor b (77) at non-singleton dimension 1
表示您正在尝试使用的 PyTorch 版本没有包含对 Flash Attention 功能的编译支持。Flash Attention 是一种用于加速 Transformer 模型中自注意力机制的技术,它可以显著提高处理速度,尤其是在大型模型和数据集上。
之前好像遇到过这个问题。可以参考该博文
flash attention安装教程 - 知乎 (zhihu.com)![]() https://zhuanlan.zhihu.com/p/655077866
https://zhuanlan.zhihu.com/p/655077866
然而,目前原生的flash attention仅支持Ampere、Hopper等架构的GPU,例如:A100、H100等,很遗憾,V100属于Volta架构并不支持,所以需要先看下自己的显卡是否支持再进行上述操作。如果不支持,建议使用xformers或者torch.nn.functional.scaled_dot_product_attention,前者需要PyTorch 2.1.2版本,后者需要PyTorch 2.0及以上版本,但如果不是Ampere或者Hopper架构的GPU,那xformers或者torch.nn.functional.scaled_dot_product_attention也只能使用显存优化技术(xformers的memory_efficient_attention支持cuda compute capability在6.0以上的显卡),节省显存空间,但并不能起到加速attention计算的效果(在计算softmax的过程中无需实例化完整的注意力矩阵S和P,但并没有减少对HBM的访问次数,注:S=QK^T,P=Softmax(S))。
We present expected speedup (combined forward + backward pass) and memory savings from using FlashAttention against PyTorch standard attention, depending on sequence length, on different GPUs (speedup depends on memory bandwidth - we see more speedup on slower GPU memory).
We currently have benchmarks for these GPUs:
- A100
- H100
十分建议去github看readme.flash-attention:这里简单贴一下机翻
安装及特点
要求:CUDA 11.6及以上版本。
PyTorch 1.12及以上版本。
Linux。可能适用于Windows从v2.3.2开始(我们已经看到一些积极的报告),但Windows编译仍然需要更多的测试。FlashAttention-2目前支持:
Ampere,Ada或Hopper gpu(例如,A100, RTX 3090, RTX 4090, H100)。即将支持图灵gpu (T4, RTX 2080),请使用FlashAttention 1。x表示图灵gpu。
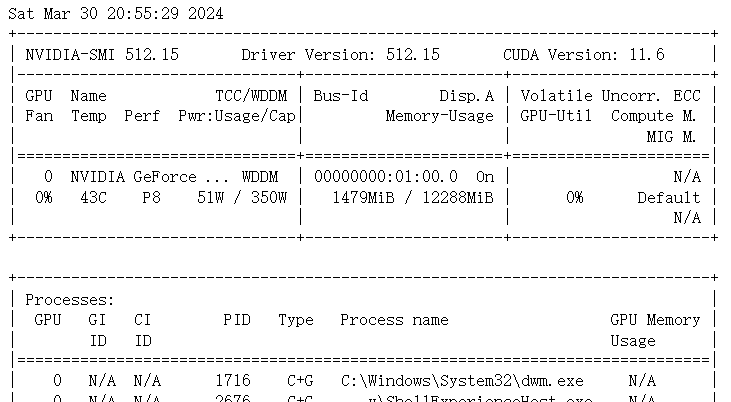
本机Windows,使用的NVIDIA GeForce GTX 1660 Ti 是一款中端图灵架构的显卡

![[激光原理与应用-82]:激光器研发常见难题](https://img-blog.csdnimg.cn/direct/82855060120e4189829dadfed119eaec.png)