论文标题:Deep Learning for Trajectory Data Management
and Mining: A Survey and Beyond
作者:Wei Chen(陈伟), Yuxuan Liang(梁宇轩), Yuanshao Zhu, Yanchuan Chang, Kang Luo, Haomin Wen(温皓珉), Lei Li, Yanwei Yu(于彦伟), Qingsong Wen(文青松), Chao Chen(陈超), Kai Zheng(郑凯), Yunjun Gao(高云君), Xiaofang Zhou(周晓方), Yu Zheng(郑宇)
机构:香港科技大学(广州),墨尔本大学,浙江大学,中国海洋大学,松鼠AI,重庆大学,电子科技大学,香港科技大学,京东
论文链接:https://arxiv.org/abs/2403.14151
Cool Paper:https://papers.cool/arxiv/2403.14151
项目地址:https://github.com/yoshall/Awesome-Trajectory-Computing

🌟【紧跟前沿】“时空探索之旅”与你一起探索时空奥秘!🚀
欢迎大家关注时空探索之旅
声明:结合Cool Paper的论文速读与Github项目分类方法,中间的图片会穿插Github项目的内容。
摘要
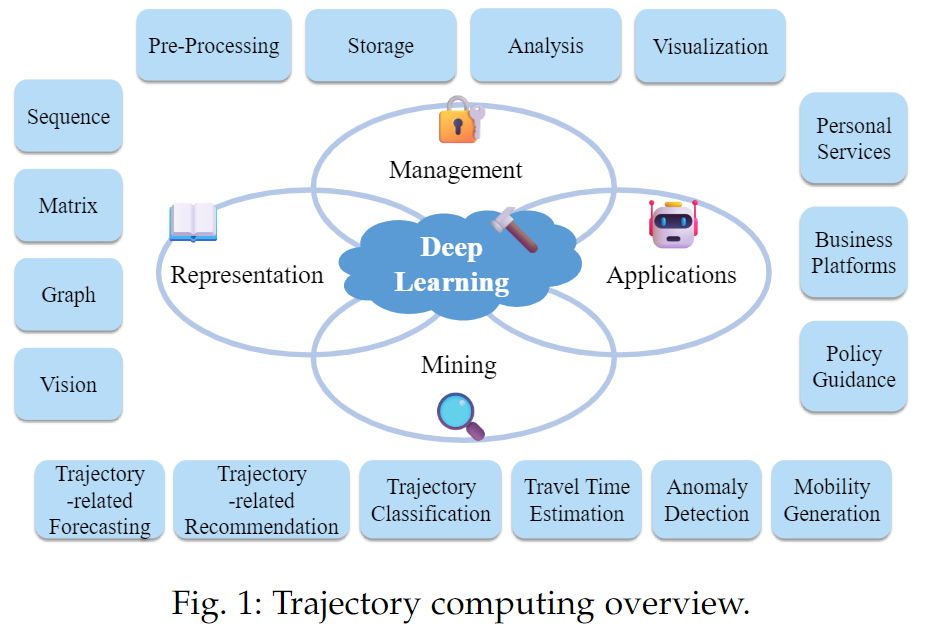
轨迹计算是轨迹数据管理和挖掘的关键领域,由于其在位置服务、城市交通和公共安全等各种实际应用中的关键作用而受到广泛关注。 传统方法侧重于简单的时空特征,面临着计算复杂、可扩展性有限以及对现实世界复杂性适应性不足的挑战。 在本文中,全面回顾了轨迹计算深度学习(DL4Traj)的发展和最新进展。 本文首先定义轨迹数据并简要概述广泛使用的深度学习模型。 并系统地探索深度学习在**轨迹管理(预处理、存储、分析和可视化)和挖掘(轨迹相关预测、轨迹相关推荐、轨迹分类、行程时间估计、异常检测和移动性生成)**中的应用。值得一提的是,本文还概括了大型语言模型(LLM)的最新进展,这些进展具有增强轨迹计算的潜力。 此外,还总结了应用场景、公共数据集和工具包。 最后,还概述了 DL4Traj 研究当前面临的挑战并提出了未来的方向。
Q: 这篇论文试图解决什么问题?
A: 这篇论文《Deep Learning for Trajectory Data Management and Mining: A Survey and Beyond》主要解决了如何有效地管理和挖掘轨迹数据的问题。具体来说,它关注以下几个方面:
- 轨迹数据管理:论文探讨了如何使用深度学习技术来处理轨迹数据的预处理、存储、分析和可视化。这包括简化轨迹点、从轨迹中恢复丢失的信息、将轨迹映射到道路网络以及有效地存储和查询轨迹数据。
- 轨迹数据挖掘:论文讨论了如何利用深度学习进行与轨迹相关的预测、推荐、分类、行程时间估计、异常检测和移动性生成等任务。这些任务有助于理解移动模式、预测未来位置、提供个性化推荐等。
- 应用场景和资源:论文总结了深度学习在轨迹计算中的各种应用,如个人服务、商业平台和政策指导,并提供了相关数据集和工具的资源。
- 挑战和未来方向:论文识别了当前深度学习在轨迹数据管理与挖掘中面临的挑战,并提出了未来可能的研究方向,如从预测到规划的转变、解决分布偏移、多模态融合、基础模型和大型语言模型的应用、可解释性、隐私和安全等。
总体而言,这篇论文提供了一个全面的视角,展示了深度学习在轨迹数据管理和挖掘领域的最新进展,为研究人员和从业者提供了一个结构化的理解框架,并为未来的研究和应用提供了指导。
Q: 有哪些相关研究?
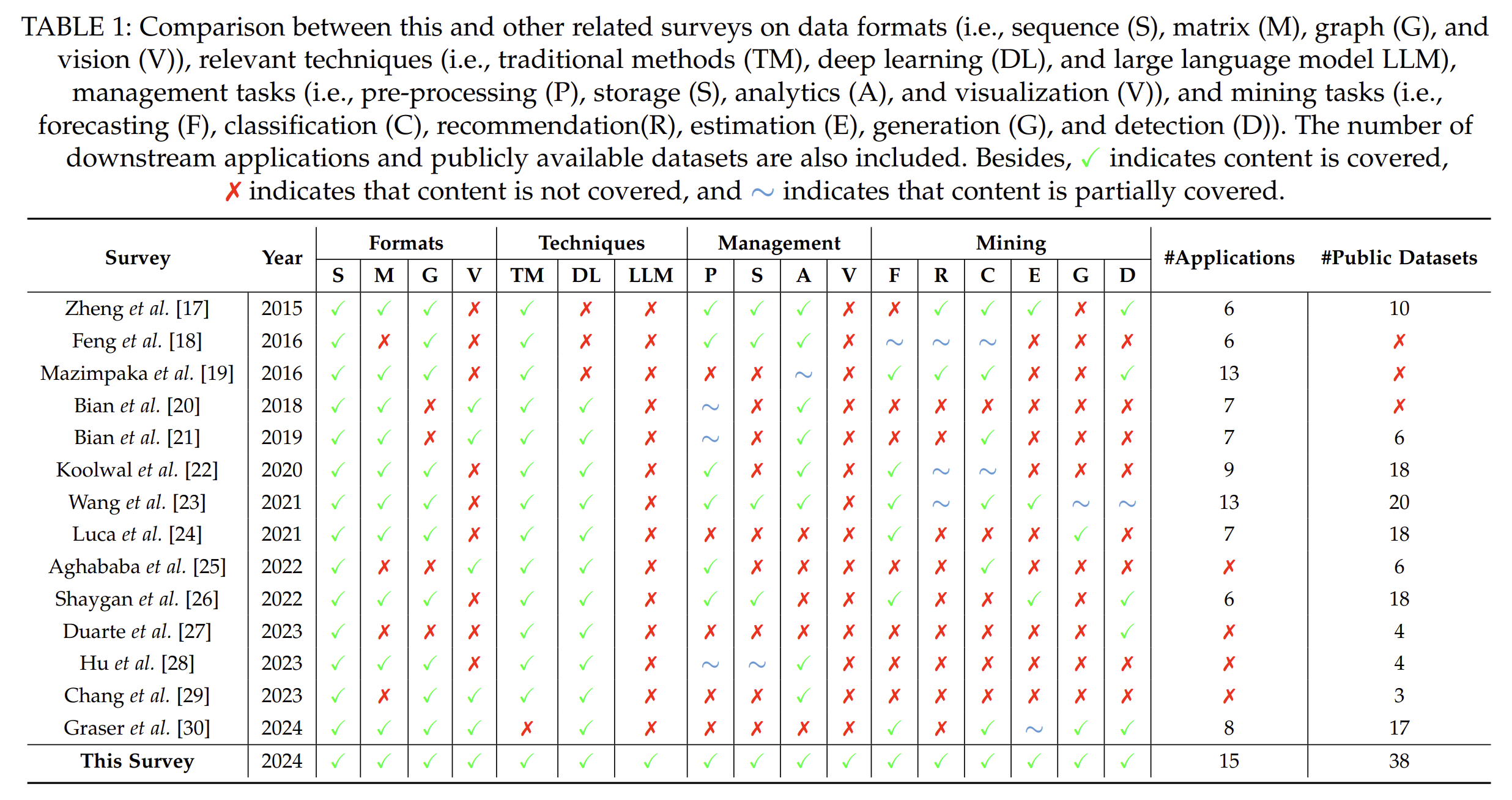
数据格式:序列(S)、矩阵(M)、图(G)和视觉(V)
相关技术:传统方法(TM)、深度学习(DL)和大型语言模型LLM
管理任务:预处理§、存储(S)、分析(A)和可视化(V))
挖掘任务:预测(F)、分类©、推荐®、估计(E)、生成(G)和检测(D)。
下游应用程序的数量和公开可用的数据集的数量也包括在内。
✓表示内容被覆盖,✗表示未被覆盖内容,∼表示内容部分被覆盖。
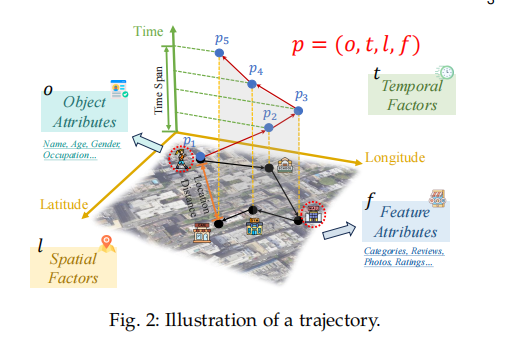
A: 这篇论文提到了许多与轨迹数据管理和挖掘相关的研究,以下是一些关键的研究领域和相关工作:
轨迹数据管理(Trajectory Data Management)
-
轨迹预处理(Pre-Processing):
- 轨迹简化:如DP [207], DPTS [208]等
- 轨迹恢复:如DHTR [36], AttnMove [63]等。
- 地图匹配:将轨迹点映射到道路网络的研究(如DeepMM [75], GraphMM [78])。
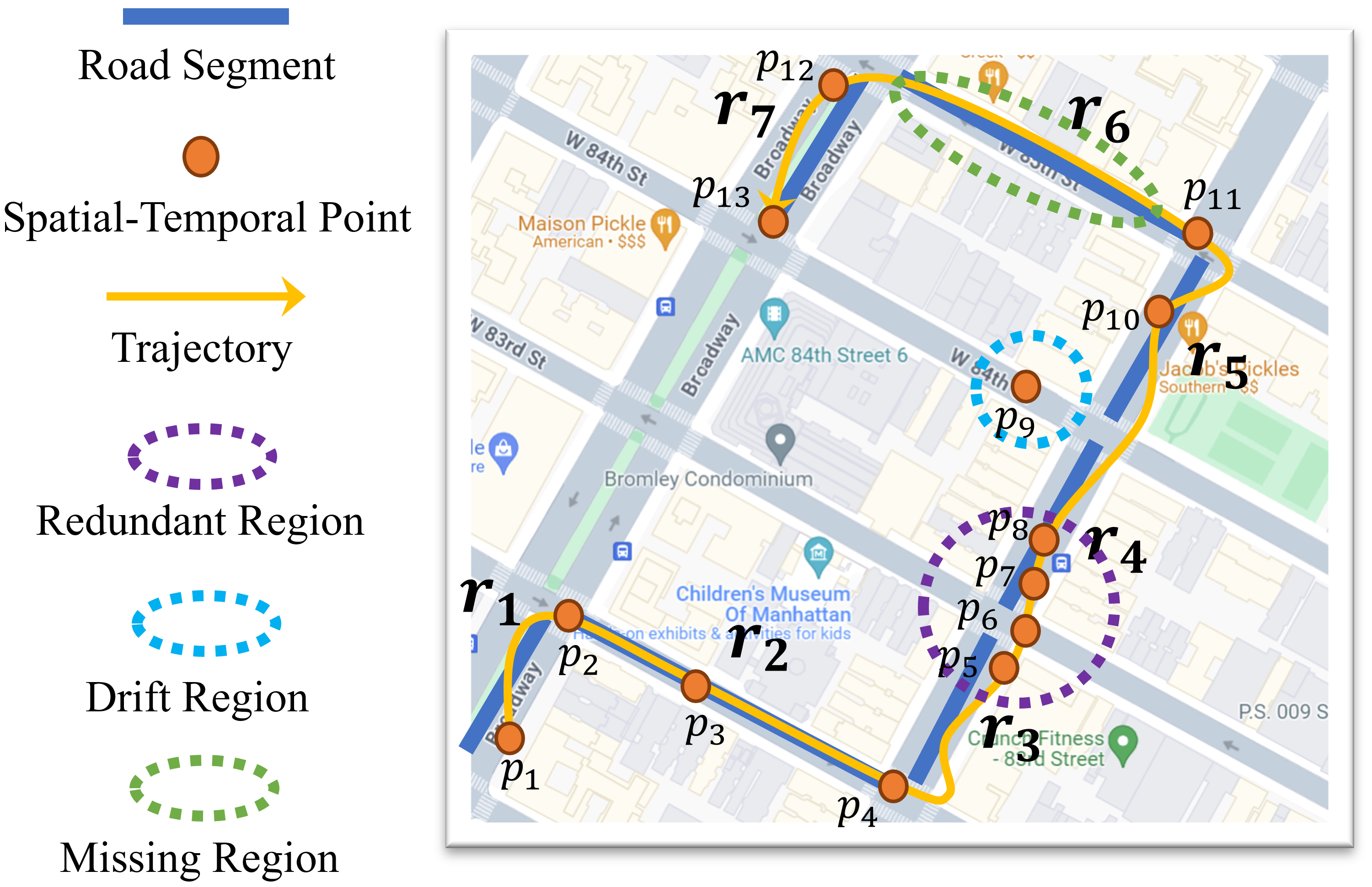
-
存储(storage):
- 数据库存储:轨迹管理系统,向量数据库。
- 索引和查询:传统索引,深度学习方法。

-
分析(analytics):
-
相似性测量:用于衡量轨迹之间相似性的方法(如RSTS [90], TrajCL [94])。
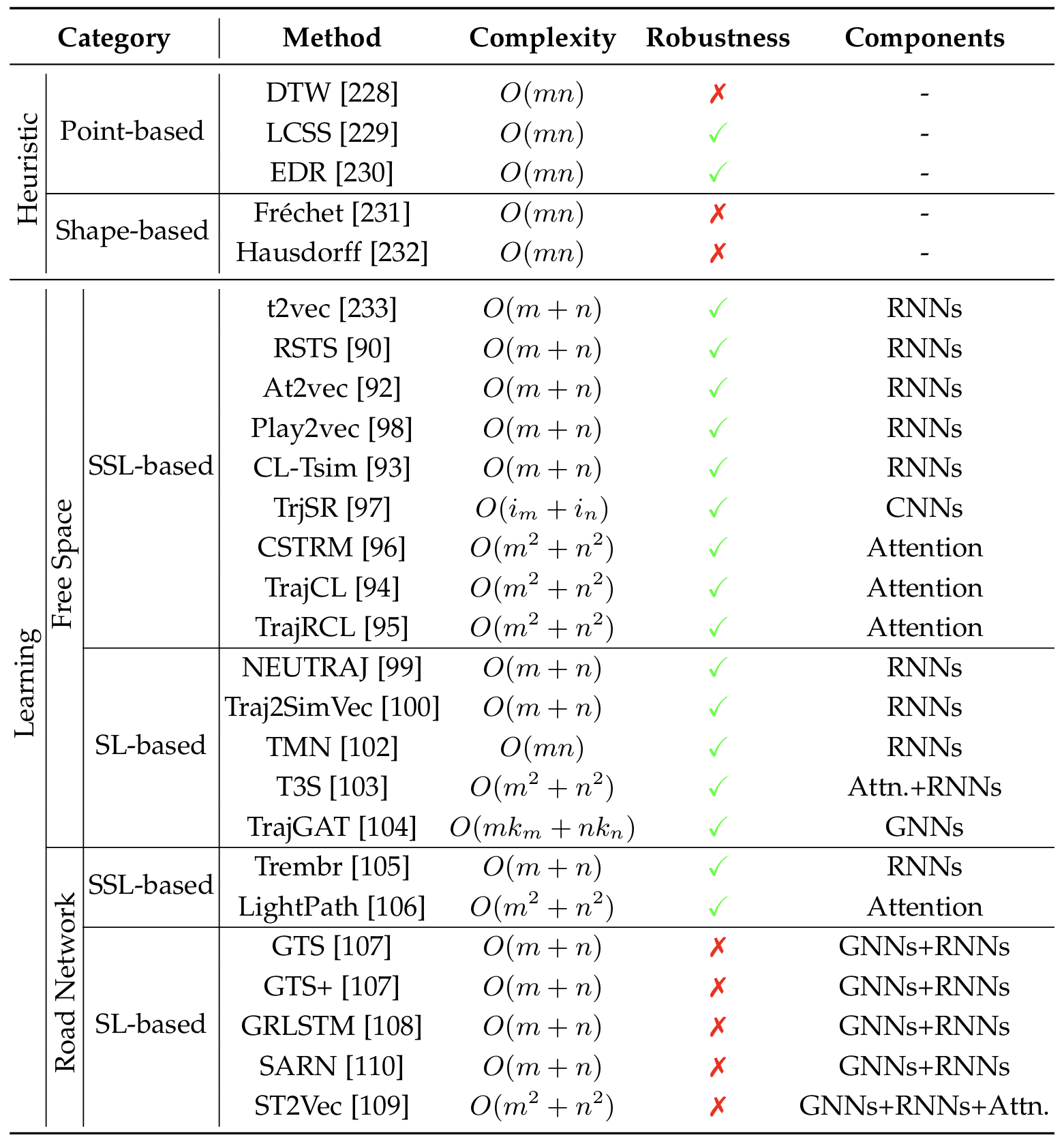
复杂度中, m m m和 n n n分别代表2个轨迹中的点数。 i m i_m im和 i n i_n in代表网格图像(image)的大小. k m k_m km和 k n k_n kn代表路网图结构中的节点数。轨迹嵌入的维数是一个很小的常数,因此它不影响时间复杂度的结果。
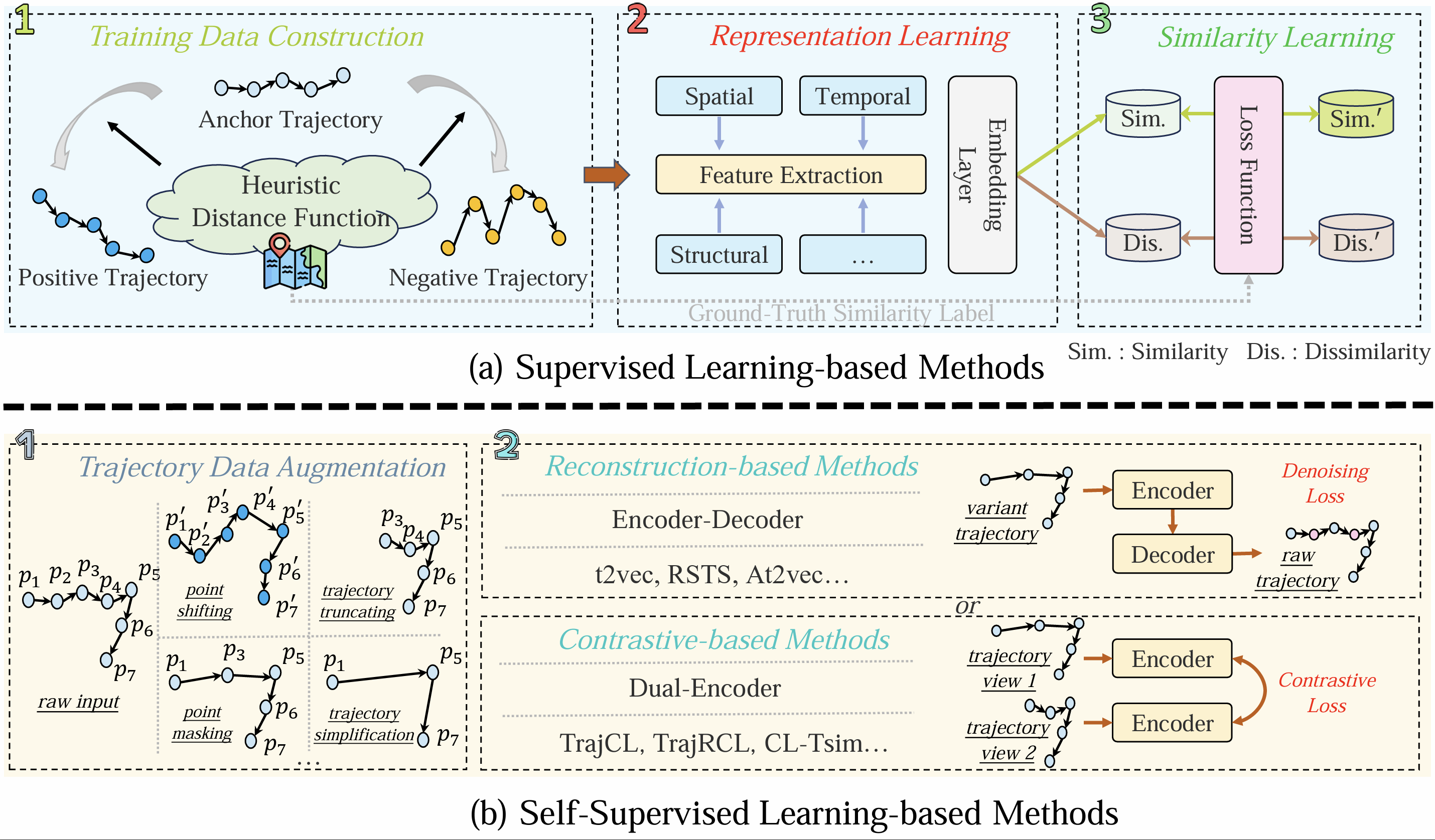
-
聚类分析:对轨迹进行分组的算法(如Trip2Vec [113], E2DTC [116])。
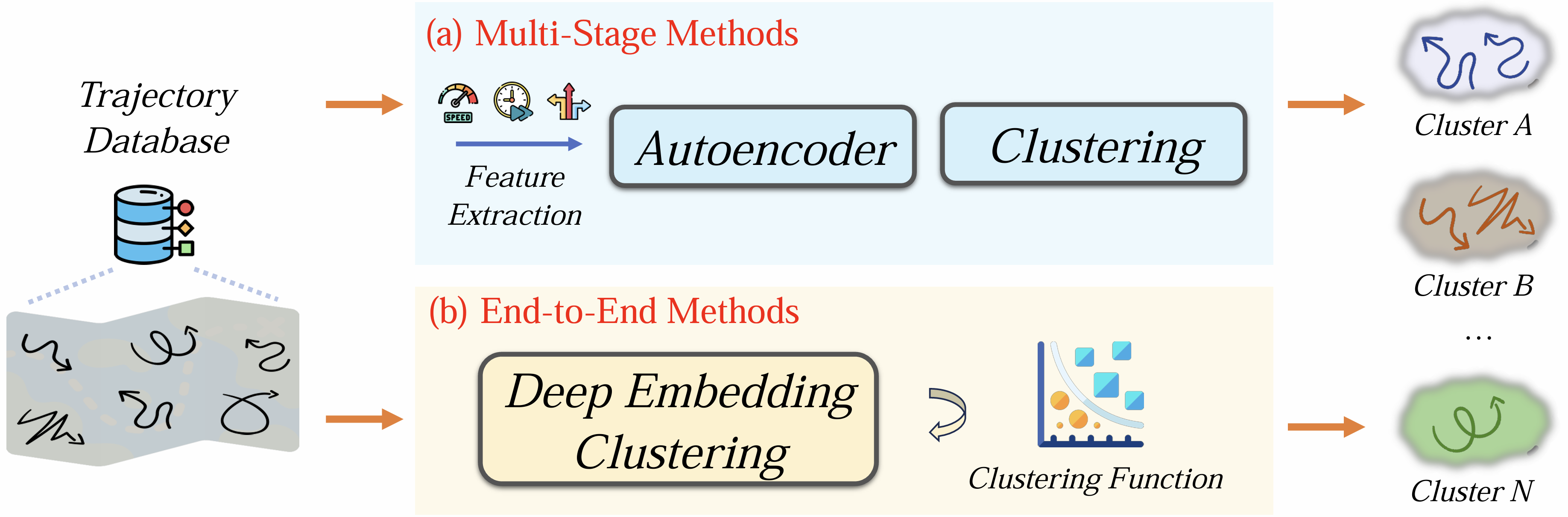
-
-
可视化:轨迹数据的可视化技术(如DeepHL [117], Surveillance [118])。

-
LLM在轨迹数据管理的应用

深度学习无缝地集成了各种管理任务,显著地简化了手动流程并提高了性能。进一步讨论了大型语言模型在轨迹管理领域的潜在关键作用。在预处理方面,LLM可以智能地清理数据,恢复缺失的语义信息。在存储和检索方面,LLM可以自动实现查询接口。对于分析,LLM可以自动识别行为集群和公共模式。在可视化和交互中,LLM可以提供丰富的语义解释,并实现自然交互。总之,通过集成现有的深度学习模型,LLM将为轨迹管理技术带来自动化的解决方案,并提供更多的语义解释信息。

轨迹数据挖掘(Trajectory Data Mining)
-
预测:位置预测(如DeepMove [122], VANext [123])和交通流量预测(如ST-ResNet [127])。
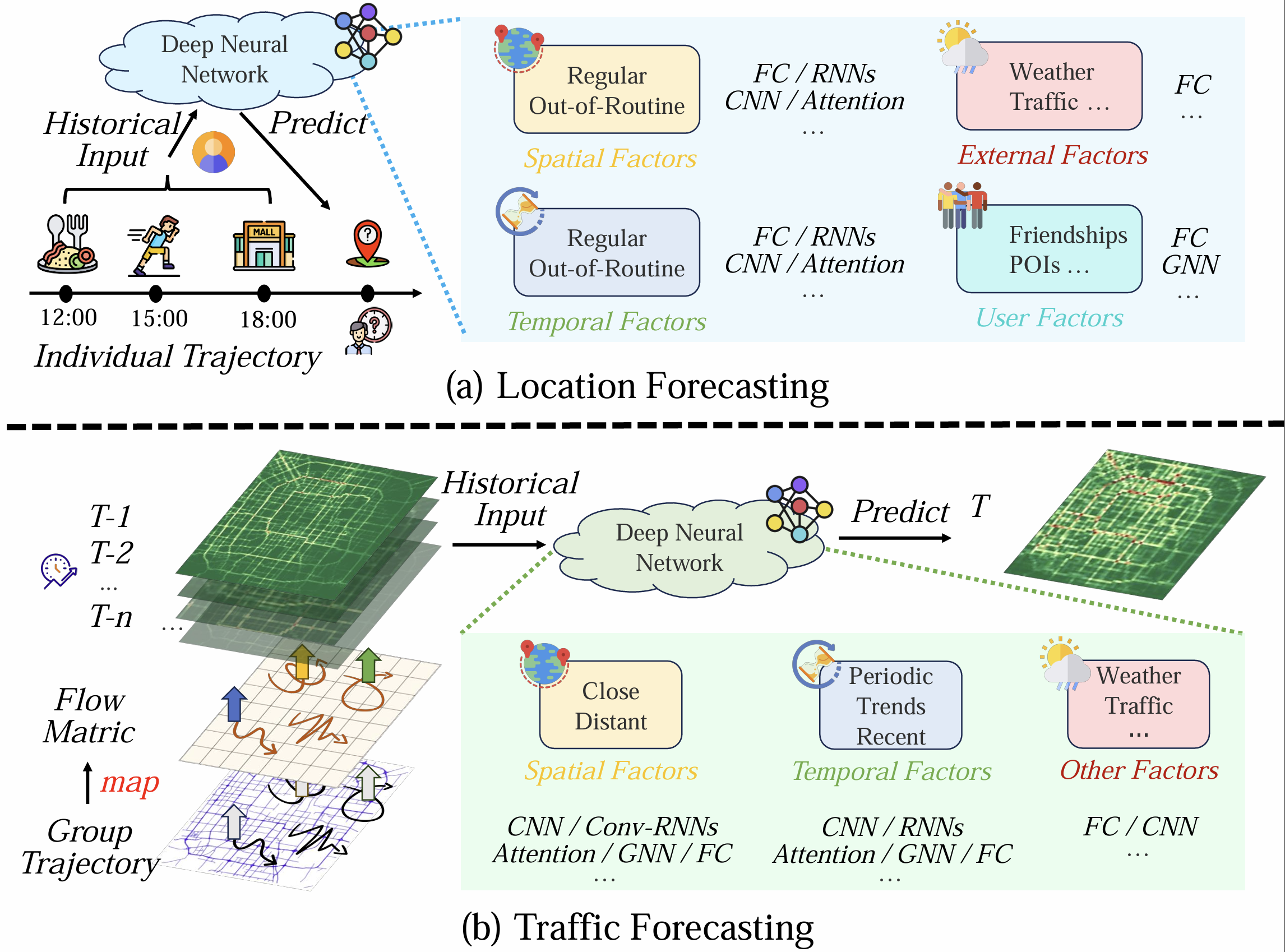
-
推荐:旅行推荐(如HRNR [136], GraphTrip [138])和朋友推荐(如LBSN2Vec [141], TSCI [144])。
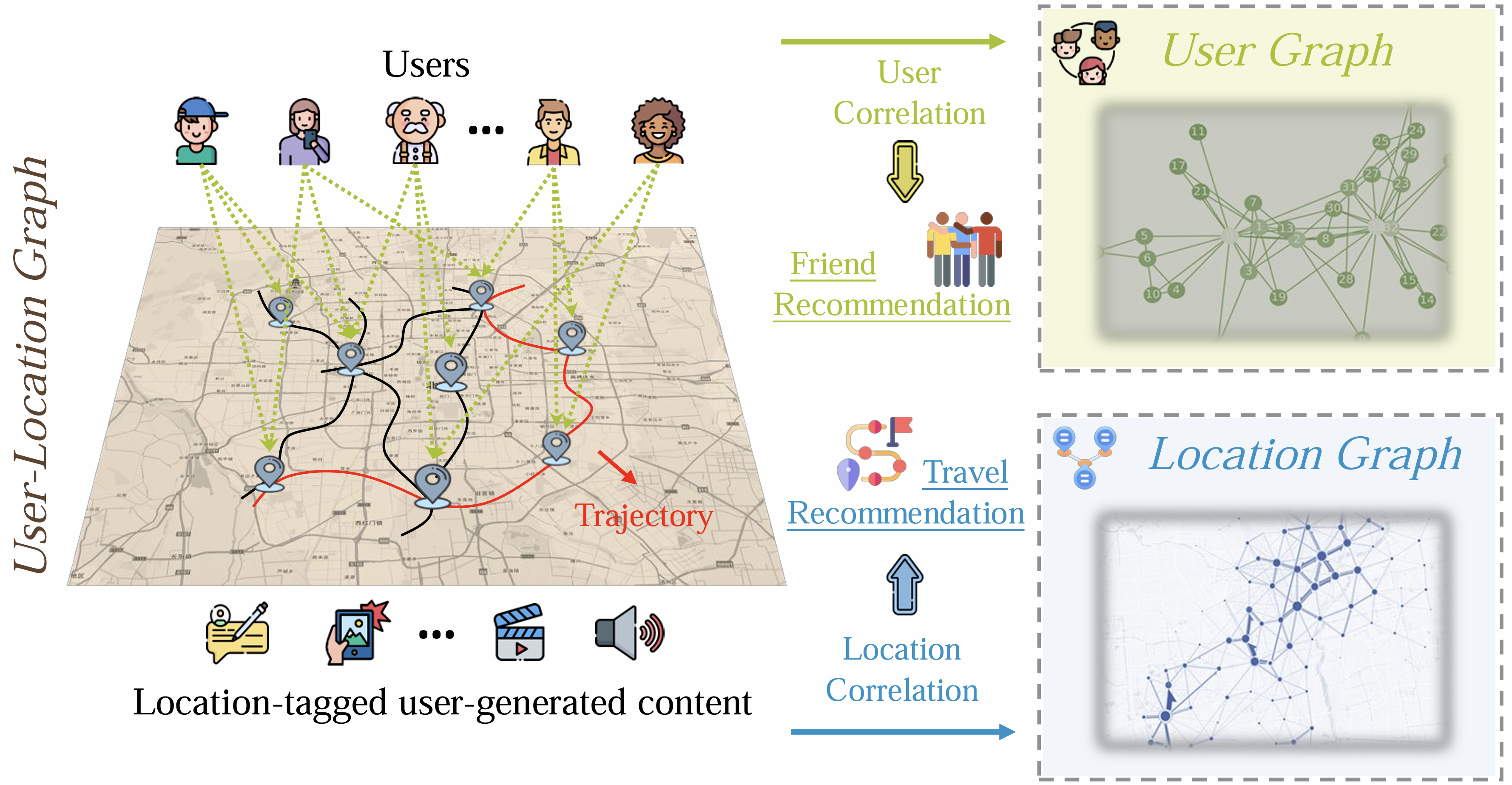
-
分类:对轨迹进行分类的研究(如TrajectoryNet [147], ST-GRU [148])。
TML:Travel Mode Identification,旅行模式识别
TUL:Trajectory-User Linking
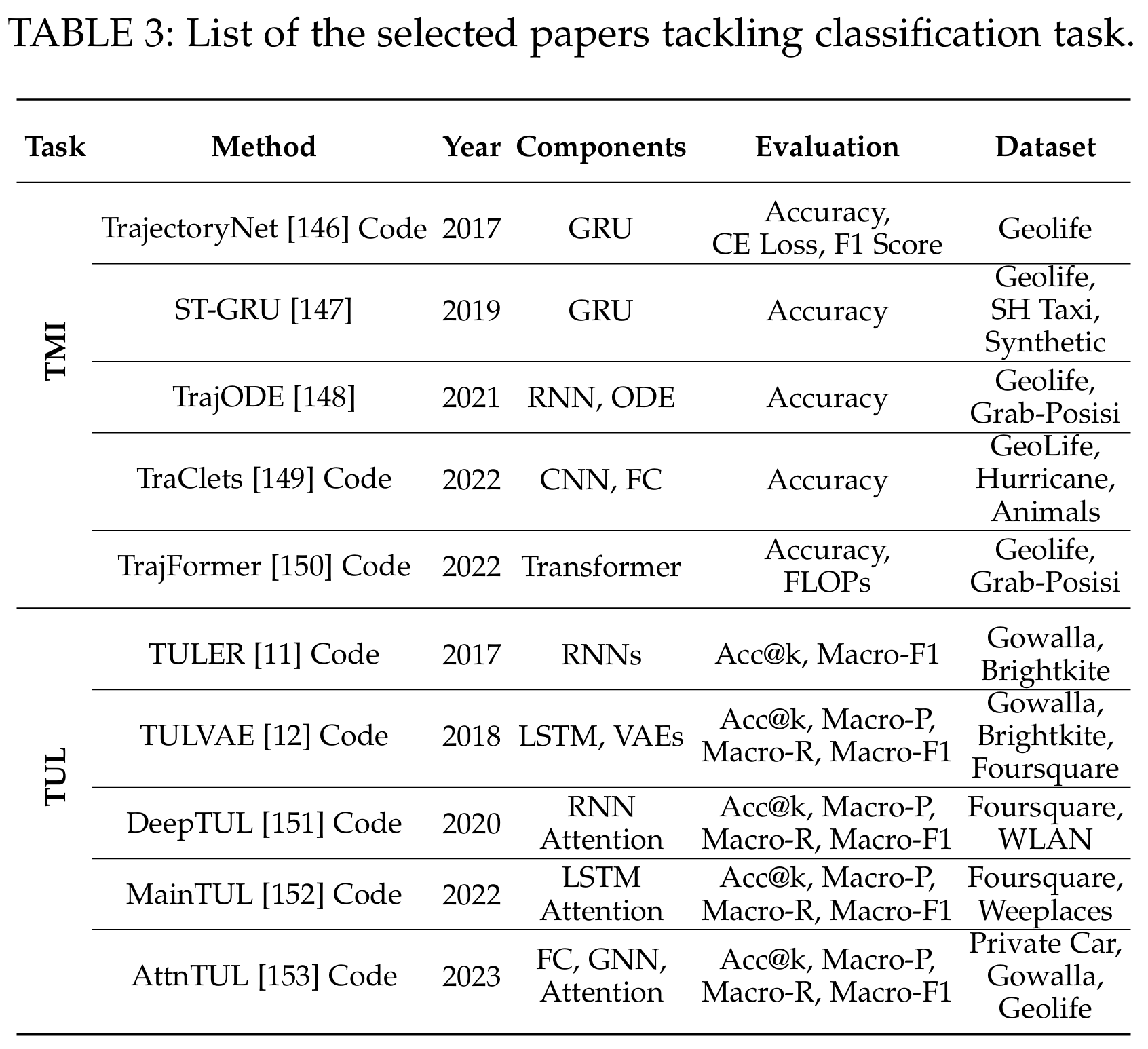
-
行程时间估计:估计旅行时间的方法(如DeepTTE [160], WDR [165])。
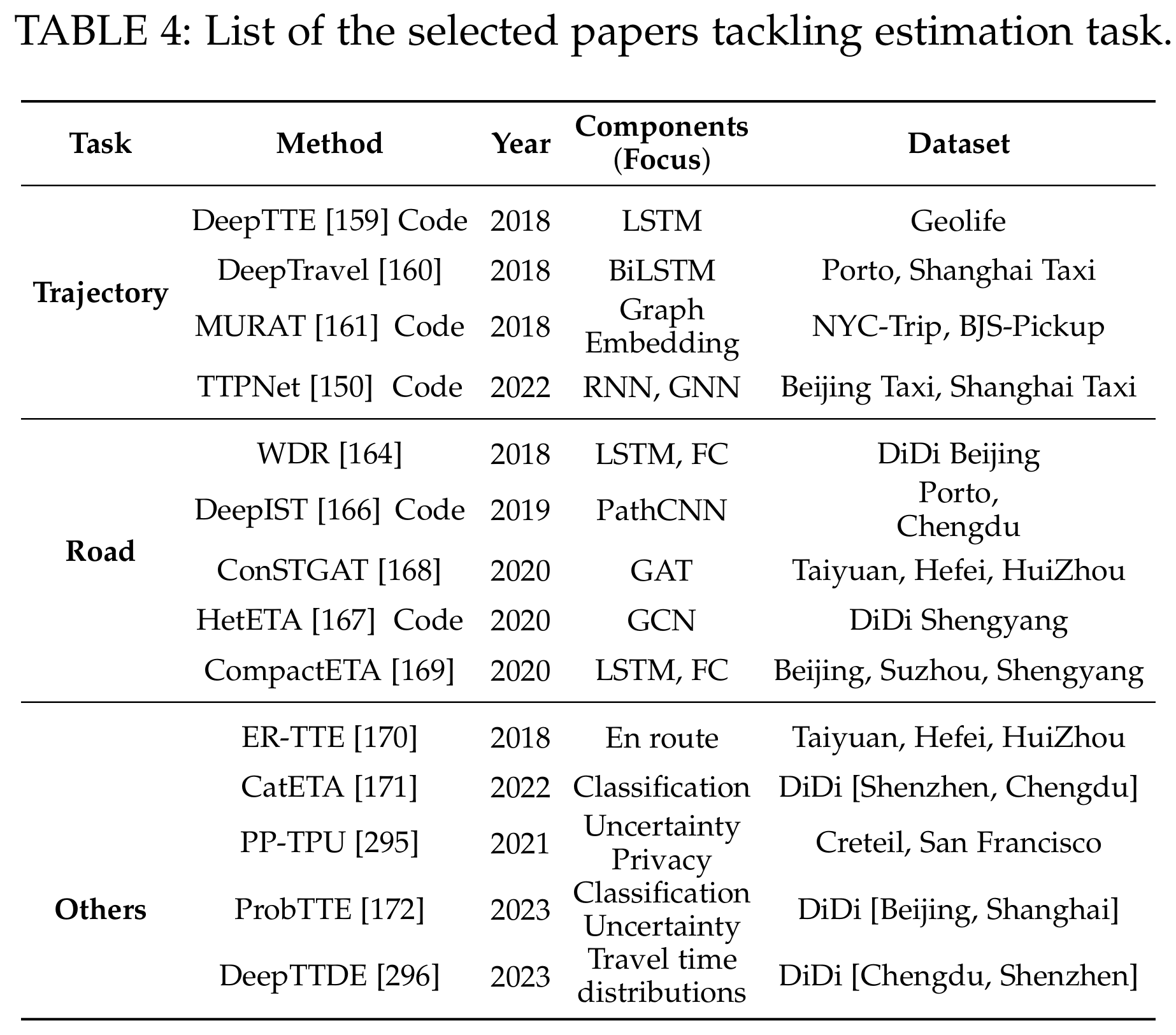
-
异常检测:检测异常轨迹的方法(如ATD-RNN [174], DB-TOD [177])。

-
移动性生成:生成合成轨迹数据的研究(如DeltaGAN [188], TrajGen [189])。
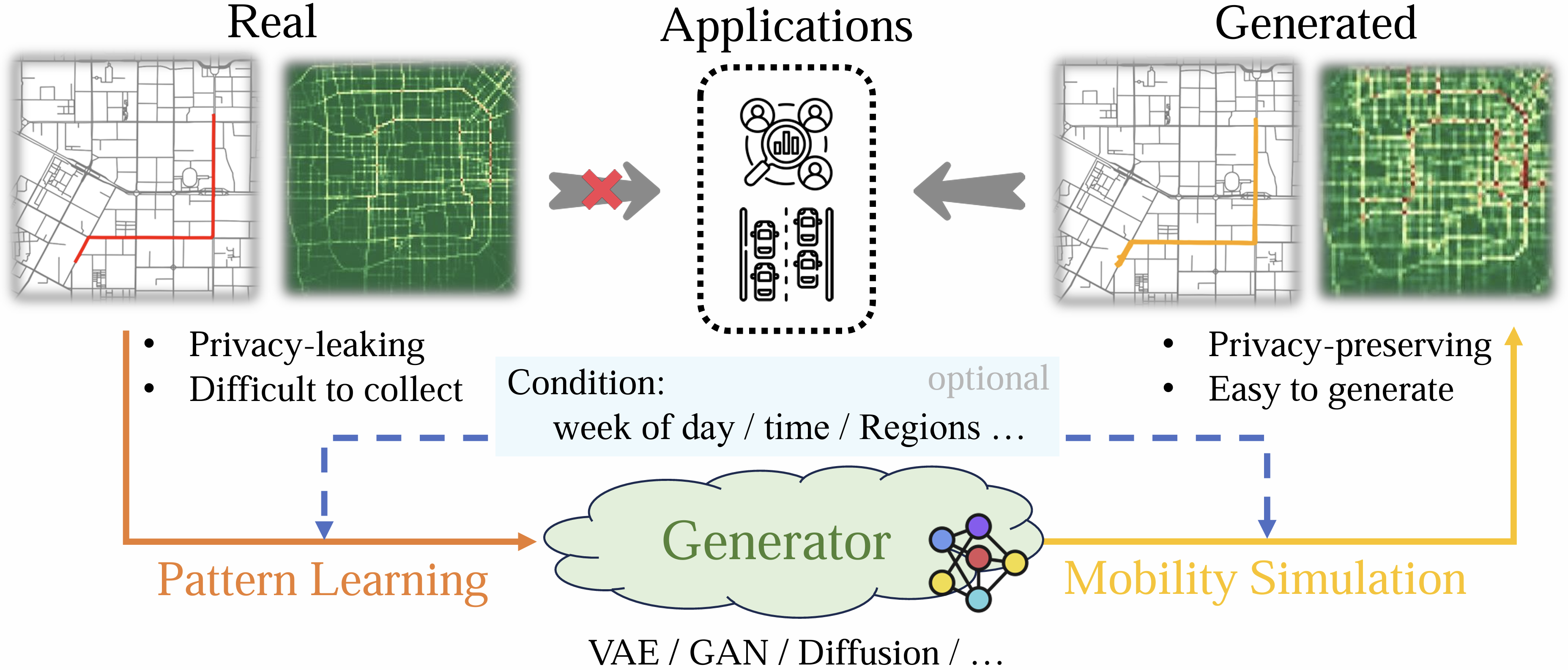
-
LLM在轨迹数据挖掘的应用

在过去的十年中,深度学习模型已被广泛应用于轨迹数据挖掘任务,并广泛应用于智能城市和智能交通系统等项目的开发。此外,还进一步讨论了大型语言模型在未来轨迹挖掘领域的潜在关键用途。对于基本的挖掘任务,如预测、分类、异常检测和生成,有一种方法涉及到对未解锁的LLM的能力进行微调。此外,这些任务可能会转换到零镜头执行技术,如语言提示。在旅行推荐等决策任务中,LLM可以作为中央情报机构(central intelligence agent(agent应该还是智能体吧,但是连起来翻译确实成了中央情报机构)),与其他模型一起提供个性化的决策。

应用
:轨迹数据在个人服务(如旅行助手)和商业平台(如站点选择和物流分配)中的应用。
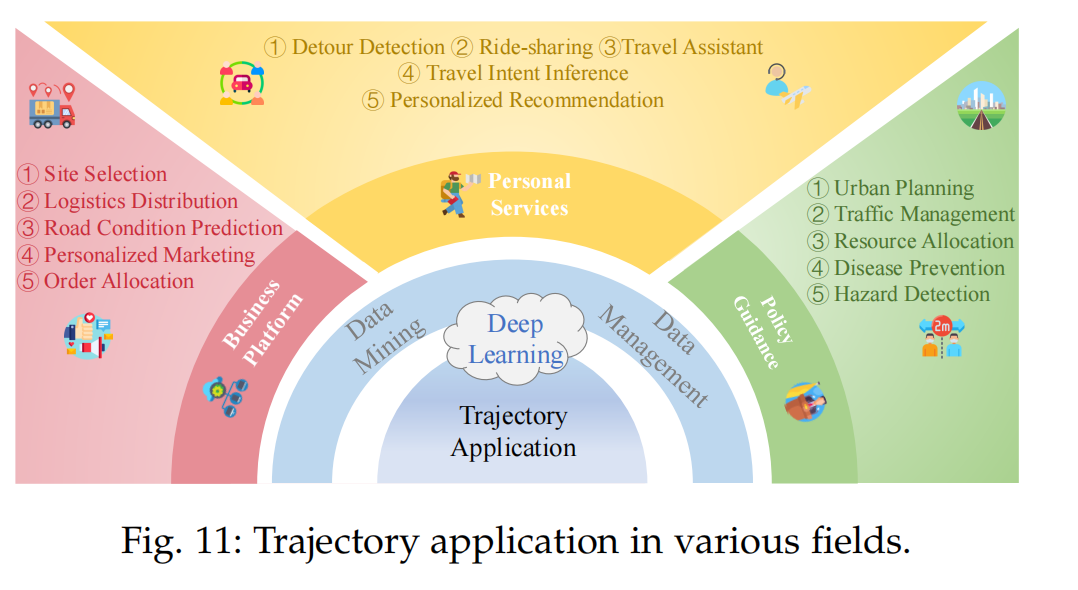
资源
公开可用的轨迹数据集(如GeoLife [32], T-Drive [197])和工具(如SUMO [201], PyTrack [203])。
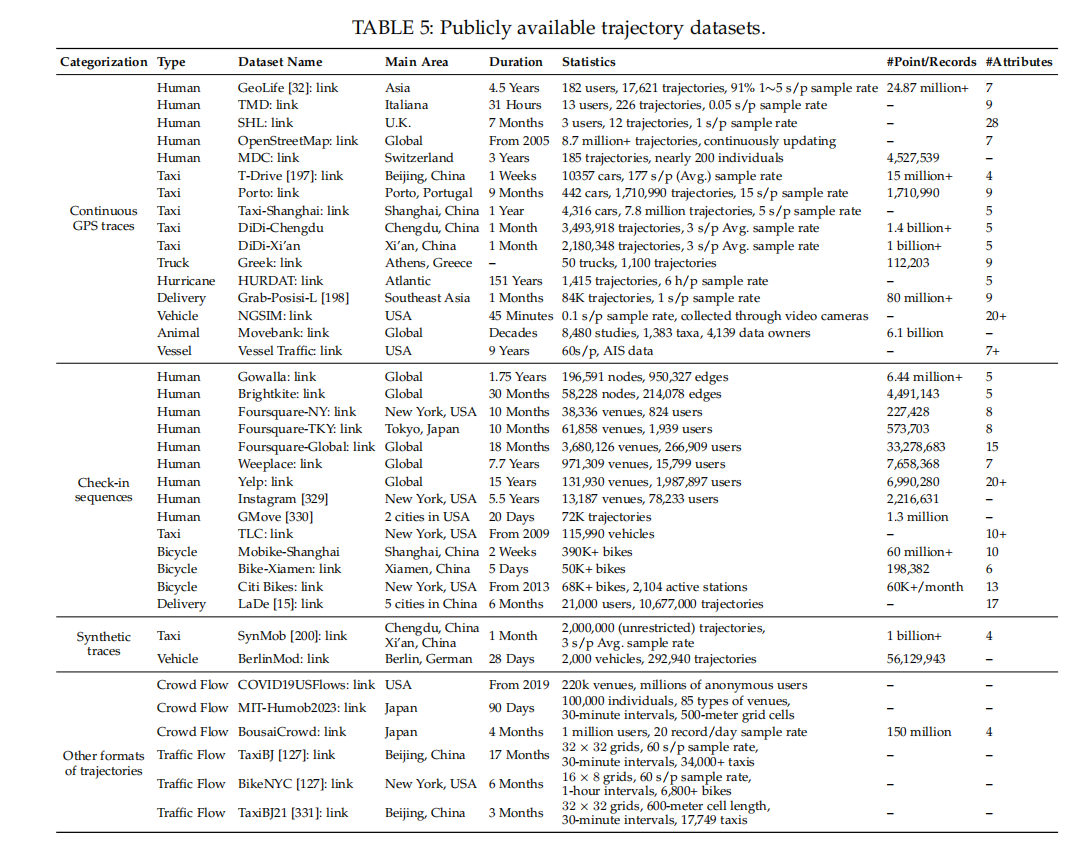
这些研究涵盖了从基础的数据处理任务到复杂的分析和挖掘任务,以及实际应用和资源的各个方面。论文还讨论了大型语言模型(LLMs)在轨迹数据挖掘中的潜在应用,这是该领域的一个新兴研究方向。
Q: 论文如何解决这个问题?
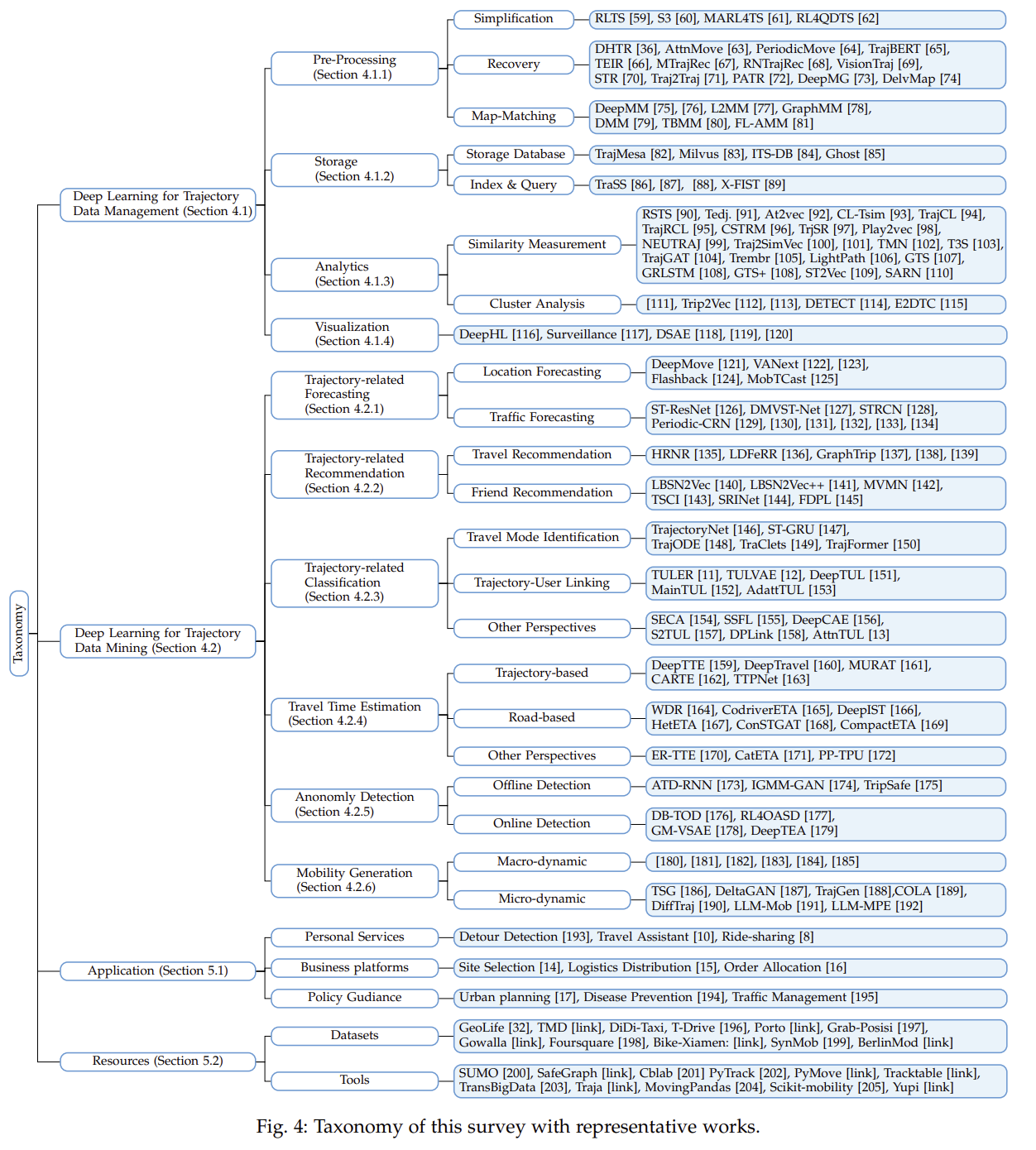
A: 这篇论文通过以下几个步骤来解决轨迹数据管理和挖掘的问题:
- 综述和分类:首先,论文对深度学习在轨迹计算(DL4Traj)领域的发展历程和最新进展进行了全面的综述。它定义了轨迹数据,并提供了深度学习模型的简要概述。
- 系统探索:论文系统地探索了深度学习在轨迹管理(包括预处理、存储、分析和可视化)和轨迹挖掘(包括预测、推荐、分类、行程时间估计、异常检测和移动性生成)中的应用。
- 应用场景总结:论文总结了深度学习技术在个人服务、商业平台和政策指导等不同领域的应用场景。
- 资源整理:论文整理了相关的公共数据集和工具,并通过DL4Traj项目提供了一个持续更新的资源库,以支持社区的研究人员、工程师和城市规划者。
- 挑战与未来方向:论文概述了当前DL4Traj研究中的挑战,并提出了未来可能的研究方向,特别是在大型语言模型(LLMs)的潜力方面。
- 贡献与创新:论文提出了第一个系统的调查,提供了统一的结构化分类法,并且是首次全面回顾深度学习在轨迹计算领域的最新发展。
通过这些步骤,论文不仅提供了一个结构化的理解框架,还为未来的研究和应用提供了指导和资源,推动了轨迹数据管理和挖掘领域的发展。
Q: 论文做了哪些实验?
A: 这篇论文是一个综述性质的研究,它并没有进行实验或者提供新的数据集和模型。相反,它专注于对现有文献的全面回顾和分类,旨在提供一个深度学习在轨迹数据管理和挖掘领域应用的系统性概述。具体来说,论文的工作包括:
- 定义和术语:明确了轨迹数据和相关处理任务的定义,为后续讨论提供了共同的理解基础。
- 技术回顾:回顾了传统的轨迹处理技术,并讨论了它们面临的挑战,如计算复杂性、有限的可扩展性和对现实世界复杂性的适应性。
- 深度学习模型:介绍了深度学习模型的基本概念,包括常用的神经网络架构和学习范式。
- 应用分类:将深度学习在轨迹管理(如预处理、存储、分析和可视化)和轨迹挖掘(如预测、推荐、分类等)中的应用进行了分类和总结。
- 资源和工具:整理了公开可用的轨迹数据集和分析工具,并通过项目页面提供资源链接。
- 挑战与未来方向:讨论了当前研究的挑战,并提出了未来可能的研究方向。
- 贡献总结:总结了论文的主要贡献,包括首次系统性调查、统一的分类法、资源收集以及未来方向的提出。
因此,这篇论文的主要贡献在于提供了一个全面的文献回顾和概念框架,而不是通过实验来验证新的假设或模型。
Q: 有什么可以进一步探索的点?
A: 论文提出了几个未来研究方向和可以进一步探索的点,包括但不限于:
- 从预测到规划:将深度学习应用于更复杂的规划任务,如动态交通优化和流动控制,而不仅仅是预测。
- 解决分布偏移:研究如何处理训练数据和测试数据之间的分布偏移问题,以便模型能够更好地泛化到新场景。
- 多模态数据融合:探索如何有效地融合来自不同源(如视觉、传感器、文本等)的数据,以更全面地捕捉人类移动性。
- 基础模型和大型语言模型:研究如何利用基础模型和大型语言模型来提高轨迹数据挖掘任务的性能。
- 可解释性:提高深度学习模型的可解释性,以便更好地理解模型的决策过程和关键影响因素。
- 隐私和安全:探索如何在保护用户隐私的同时,有效利用轨迹数据,例如通过匿名化技术和生成合成数据。
- 实时和在线学习:研究实时和在线学习算法,以便模型能够快速适应新的数据和环境变化。
- 跨区域和跨时间的泛化能力:提高模型在不同地区和时间段的泛化能力,特别是在城市规模的轨迹数据上。
- 多任务学习和元学习:探索多任务学习和元学习在轨迹数据挖掘中的应用,以提高模型的效率和适应性。
- 数据集和基准测试:构建更大规模、更多样化的公开轨迹数据集,并开发标准化的基准测试来评估不同方法的性能。
这些方向不仅为研究人员提供了新的研究机会,而且对于推动智能交通系统、位置服务和城市规划等领域的实际应用具有重要意义。
Q: 总结一下论文的主要内容
A: 这篇论文《Deep Learning for Trajectory Data Management and Mining: A Survey and Beyond》主要内容可以总结如下:
- 背景与动机:论文介绍了轨迹计算的重要性,包括轨迹数据管理和挖掘,并讨论了传统方法在处理这类数据时面临的挑战,如计算复杂性、可扩展性和适应性问题。
- 深度学习模型:论文概述了深度学习模型的基础知识,包括常用的神经网络架构和学习范式,为后续讨论在轨迹数据处理中的应用提供基础。
- 轨迹数据管理:论文系统地探讨了深度学习在轨迹预处理、存储、分析和可视化等方面的应用,介绍了各种方法和技术,如轨迹简化、地图匹配等。
- 轨迹数据挖掘:论文详细阐述了深度学习在轨迹挖掘任务中的应用,包括轨迹相关预测、推荐、分类、行程时间估计、异常检测和移动性生成等。
- 应用场景:论文总结了深度学习在轨迹计算中的应用场景,如个人服务、商业平台和政策指导,强调了其在实际中的价值。
- 公共数据集和工具:论文提供了公共数据集和工具的列表,并通过DL4Traj项目提供了一个资源库,以支持研究和实践社区。
- 挑战与未来方向:论文讨论了当前研究的挑战,并提出了未来可能的研究方向,特别是在大型语言模型(LLMs)的潜力方面。
- 贡献:论文作为第一个系统性调查,提供了统一的分类法和全面的资源收集,为读者提供了深入理解轨迹计算领域的材料。
总体而言,这篇论文提供了一个全面的视角,展示了深度学习在轨迹数据管理和挖掘领域的最新进展,为研究人员和从业者提供了一个结构化的理解框架,并为未来的研究和应用提供了指导。
. 挑战与未来方向:论文讨论了当前研究的挑战,并提出了未来可能的研究方向,特别是在大型语言模型(LLMs)的潜力方面。
8. 贡献:论文作为第一个系统性调查,提供了统一的分类法和全面的资源收集,为读者提供了深入理解轨迹计算领域的材料。
总体而言,这篇论文提供了一个全面的视角,展示了深度学习在轨迹数据管理和挖掘领域的最新进展,为研究人员和从业者提供了一个结构化的理解框架,并为未来的研究和应用提供了指导。
🌟【紧跟前沿】“时空探索之旅”与你一起探索时空奥秘!🚀
欢迎大家关注时空探索之旅