Python数据分析必备工具——Pandas模块及其应用
- 外部数据的读取
- 文本文件的读取
- 语法
- 示例
- 电子表格的读取
- 语法
- 示例
- 数据库数据的读取与操作
- 语法
- 数据操作
- 数据概述
- 语法
- 数据筛选
- 语法
- 数据清洗
- 数据类型
- 语法
- 示例
- 沉余数据
- 语法
- 示例
- 异常值的识别与处理
- 缺失值的识别与处理
- 语法
- 示例
- 数据汇总
- 透视表功能
- 语法1
- 示例1
- 语法2
- 示例2
- 数据的合并
- 语法
- 示例
- 数据的连接
- 语法
- 示例
外部数据的读取
文本文件的读取
语法
注意,它的参数还有很多,但是最重要的是此八个
pd.read_csv(filepath_or_buffer, sep=‘,', header=‘infer’, names=None, usecols=None,
skiprows=None, skipfooter=None, converters=None, encoding=None)
filepath_or_buffer:指定txt文件或csv文件所在的具体路径;
sep:指定原数据集中各字段之间的分隔符,默认为逗号”,”
header:是否需要将原数据集中的第一行作为表头,默认将第一行用作字段名称 None
names:如果原数据集中没有字段,可以通过该参数在数据读取时给数据框添加具体的表头
usecols:指定需要读取原数据集中的哪些变量名
skiprows:数据读取时,指定需要跳过原数据集开头的行数
skipfooter:数据读取时,指定需要跳过原数据集末尾的行数
converters:用于数据类型的转换(以字典的形式指定)
encoding:如果文件中含有中文,有时需要指定字符编码
thousands: 将千分位符号去掉
示例
Txt文档内容:

# 导入功能包
import pandas as pd
# 读取与处理
title = ['id','year','month','day','gender','occupation','income']
data01 = pd.read_csv(r'C:\Users\HP\Desktop\data\data_test01.txt',
skiprows=2, sep=',', skipfooter=3, converters={'id':str},
encoding='utf-8', thousands='&',
header=None, names=title, usecols=['id','occupation','income'])
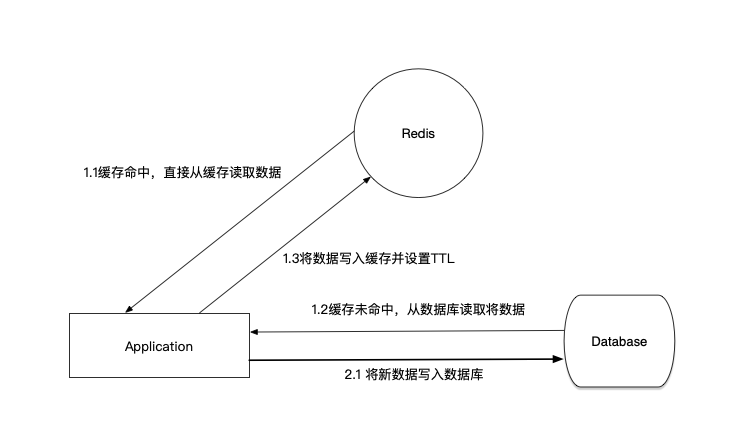
print(data01)
输出:
电子表格的读取
语法
pd.read_excel(io, sheetname=0, header=0, skiprows=None, skip_footer=0,
index_col=None, names=None,
na_values=None, thousands=None, convert_float=True)
io:指定电子表格的具体路径
sheetname:指定需要读取电子表格中的第几个Sheet,既可以传递整数也可以传递具体的Sheet名称
header:是否需要将数据集的第一行用作表头,默认为是需要的
skiprows:读取数据时,指定跳过的开始行数
skip_footer:读取数据时,指定跳过的末尾行数
index_col:指定哪些列用作数据框的行索引(标签)
na_values:指定原始数据中哪些特殊值代表了缺失值
thousands:指定原始数据集中的千分位符
convert_float:默认将所有的数值型字段转换为浮点型字段
converters:通过字典的形式,指定某些列需要转换的形式
示例
注意:openpyxl可能需要手动装一下(高版本的pandas没有)
# 导入功能包
import pandas as pd
# 读取与处理
title = ['id','product','color','size']
data2 = pd.read_excel(r'C:\Users\HP\Desktop\data\data_test02.xlsx',
header=None, names= title, converters={'id':str})
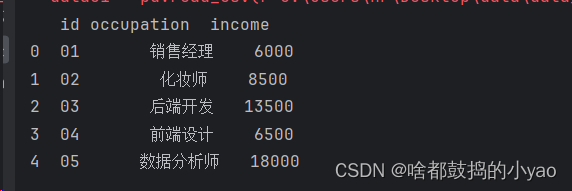
print(data2)
输出:
数据库数据的读取与操作
语法
数据读取:
pymysql.connect(host=None, user=None, password=‘’,
database=None, port=0, charset=‘’)
host:指定需要访问的MySQL服务器(就是IP地址)
user:指定访问MySQL数据库的用户名
password:指定访问MySQL数据库的密码
database:指定访问MySQL数据库的具体库名
port:指定访问MySQL数据库的端口号
charset:指定读取MySQL数据库的字符集,如果数据库表中含有中文,一般可以尝试将该参数设置为“utf8”或“gbk”
pd.read_sql(sql,con)
pd.read_sql_table(table_name,con)
sql:指定SQL查询语句,将根据查询语句的逻辑返回对应的数据框
con:指定数据库与Python之间的连接器,即通过pymysql.connect函数或pymssql.connect构造的连
接器
table_name:指定数据库中某张表的名称,将根据表名称返回对应的数据框
对于更多的操作与运用了解,请见我的其他文章:
Mysql数据库基础:http://t.csdnimg.cn/A2VKy
MySQL操作并用Python进行连接:http://t.csdnimg.cn/DqP8E
Python 与 MySQL 数据库交互(含案例实战2:把金融数据存入数据库中):http://t.csdnimg.cn/tetKn
数据操作
数据概述
语法
df.head():查看数据前5组
df.shape:表示数据规模操作函数
df.columns:变量列表
df.dtypes:变量类型(object表示非数字类型或叫字符型)
df.describe:统计描述(默认对数值型数据做统计表述,如非缺失数据的个数、均值、标准值等)
df.describe(include=‘object’) 对字符型数据进行描述
df.columns:列名称
数据筛选
语法
df.column_name df[‘column_name’]:列的筛选
(如 list1.name或用list1[‘name’]、list1[[‘name’, ‘time’]]进行多个筛选)
df.loc[condition,:]:行的筛选
(如 list1.loc[list1.name == ‘小王’, :] 挑选name列中所以名字叫小王的行;
list1.loc[(list1.name == ‘小王’) & (list1.time>150), :]挑选name列中所以名字叫小王的且时间大于150的行)
df.loc[condition,:column_list]:行列的筛选
(如 list1.loc[(list1.name == ‘小王’) & (list1.time>150), [‘name’, ‘time’]]挑选name列中所以名字叫小王的且时间大于150的行,且只输出name和time列)
数据清洗
数据类型
语法
数据类型的更改(如int float str):
pd.to_datetime:更改为日期类型
df.column.astype:更改为设定数据类型
示例
import pandas as pd
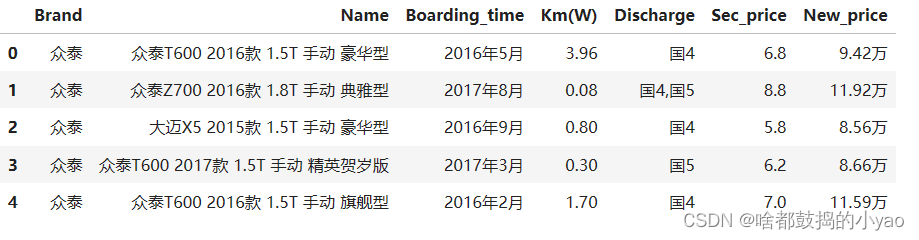
sec_car = pd.read_csv(r'D:\pythonProject\data\sec_cars.csv')
sec_car.head()
# 数据类型
sec_car.dtypes
输出:
注意:要加上上面示例的第一段代码
# 将年月文本类型进行修改并将其进行更改
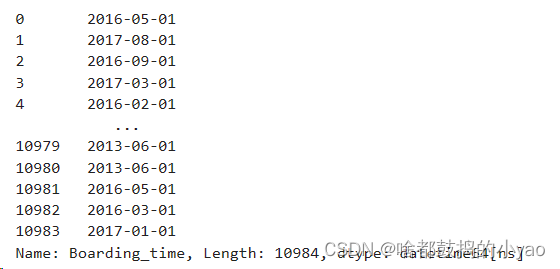
sec_car.Boarding_time = pd.to_datetime(sec_car.Boarding_time, format='%Y年%m月')
# 将价格修改为浮点型(首先要先将万去掉)
# 如果要对变量中的某一列的内容进行处理,要先str一下
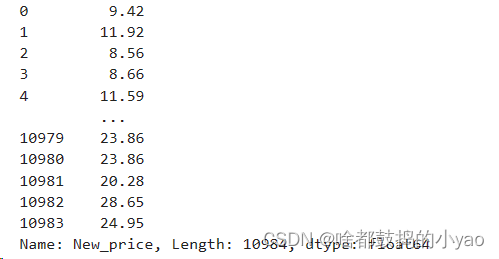
sec_car.New_price = sec_car.New_price.str[:-1].astype(float)
输出:
沉余数据
语法
沉余数据的识别与处理:
df.duplicated:查看哪些行或者设定列是重复的,会返回true
df.drop_duplicates:删除重复内容的操作
示例
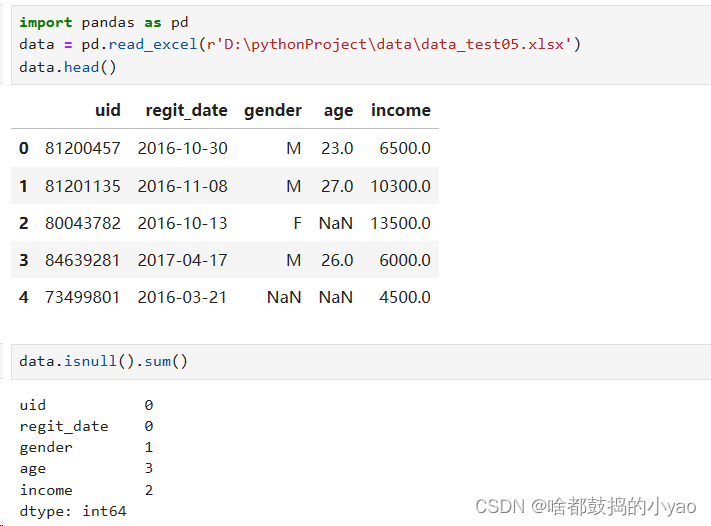
import pandas as pd
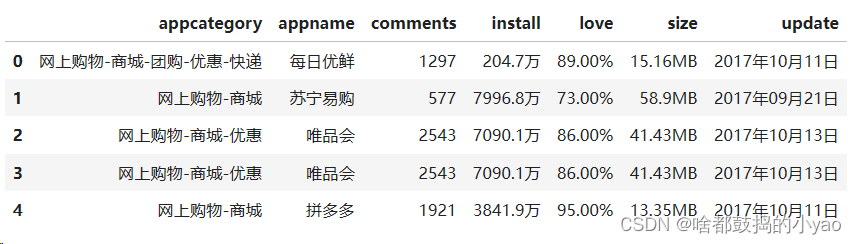
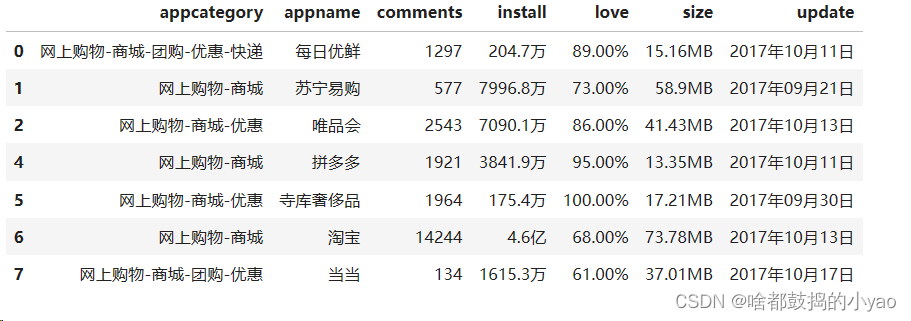
data= pd.read_excel(r'D:\pythonProject\data\data_test04.xlsx')
data.head()
# 检查数据是否存在冗余(也就是重复,改行完全重复)
data.duplicated()
# 只检查对于appname的是否存在重复
# data.duplicated(subset='appname')
# 删除重复内容的操作
data.drop_duplicates()
# 若inplace设置为true会将原表进行改变
# data.drop_duplicates(inplace = True)
输出:

异常值的识别与处理
Z得分法;分位数法;距离法等方法
Z得分法(要求数据大概为正态分布):
简单来说,就是统计学里面的,找n倍的标准差之内的数为符合,其余为异常。
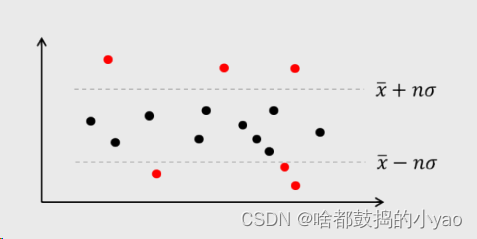
分位数法(不为正太分布时我们用):
在其Q3+/-nIQR的之上或之下,判定为异常
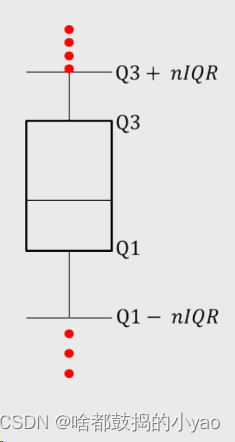
Q1:25%,下四分位数;Q2:中位数(中间的那根线);Q3:75%,上四分位数;IQR=中间数据50%的幅度;n=1.5;
对于距离法,我们还没将K均值这个算法,所以在这里面不详细介绍,后面会详细说明。
缺失值的识别与处理
语法
df.isnull:返回一个同样的表格,查看哪些数据位置是空缺的(返回true此位置空缺和false)
df.isnull().any():返回哪个变量存在缺失(any表示多个or条件的综合)
df.isnull().sum():将能查看缺失值数量是多少
df.fillna:填充法(value=?)(但原始表格无变化,若要改变,需要添加inplace=True参数)
df.dropna:直接删除空缺数据(同样原始表格无变化,若要改变,需要添加inplace=True参数)
示例
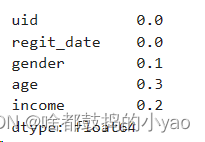
# 我们可以利用除以行数来确定缺失比例是多少
data.isnull().sum() / data.shape[0]
输出:
# 利用指定数值替换mode是众数、mean是平均值、median是中位数
data.fillna(value={'gender': data.gender.mode()[0], 'age': data.age.mean(), 'income': data.income.median()})
# 若有相同的众数出现,他是按列表的形式排序的,我们取第一位也就是索引0
# 直接删除空缺数据
data.dropna()
输出:
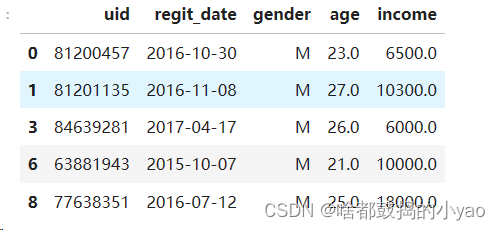
数据汇总
在Excel中,是利用透视表进行汇总。
在SQL中,是分组统计。
透视表功能
语法1
pd.pivot_table(data, values=None, index=None, columns=None, aggfunc=‘mean’,
fill_value=None, margins=False, dropna=True, margins_name=‘All’)
data:指定需要构造透视表的数据集
values:指定需要拉入“数值”框的字段列表
index:指定需要拉入“行标签”框的字段列表
columns:指定需要拉入“列标签”框的字段列表
aggfunc:指定数值的统计函数,默认为统计均值,也可以指定numpy模块中的其他统计函数
fill_value:指定一个标量,用于填充缺失值
margins:bool类型参数,是否需要显示行或列的总计值,默认为False
dropna:bool类型参数,是否需要删除整列为缺失的字段,默认为True
margins_name:指定行或列的总计名称,默认为All
示例1
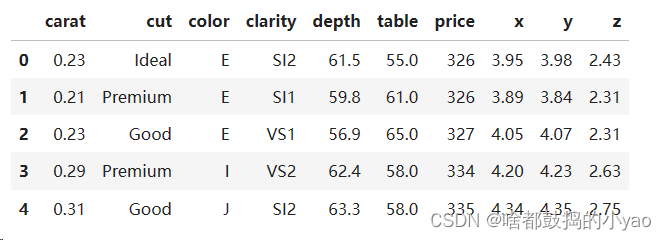
import pandas as pd
diamonds = pd.read_csv(r'D:\pythonProject\data\diamonds.csv')
# 查看表格
# diamonds.head()
# 查看不同颜色的钻石的平均价格
pd.pivot_table(diamonds, index = 'color', values='price', aggfunc='mean')
输出:

import pandas as pd
diamonds = pd.read_csv(r'D:\pythonProject\data\diamonds.csv')
# 查看表格
# diamonds.head()
# 查看不同颜色的钻石的平均价格
# pd.pivot_table(diamonds, index = 'color', values='price', aggfunc='mean')
# 查看不同颜色不同纯度的数量
pd.pivot_table(diamonds, index = 'color', columns='clarity', values='price', aggfunc='size')
输出:
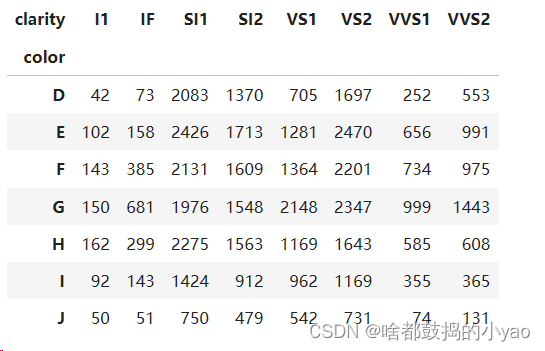
同样我们可以使用对于SQL操作的方法:
语法2
groupby:用于汇总前,设定被分组的变量
aggregate:可基于groupby的结果做进一步的统计汇总
注意:在aggregate阶段,需以字典的形式传递参数,用于选择被统计的变量和对应的统计方法
示例2
import numpy as np
# 通过groupby方法,指定 颜色和切割 分组变量
grouped = diamonds.groupby(by = ['color','cut'])
# 对分组变量进行统计汇总(颜色为数量,重量求最小值,价格求平均值,宽度求最大值
result = grouped.aggregate({'color':np.size, 'carat':np.min, 'price':np.mean, 'table':np.max})
# 调整变量名的顺序
result = pd.DataFrame(result, columns=['color','carat','price','table'])
# 数据集重命名(若要改变原表格记得要加上inplace=True)
result.rename(columns={'color':'counts','carat':'min_weight','price':'avg_price','table':'max_face_width'},inplace=True)
result
输出:
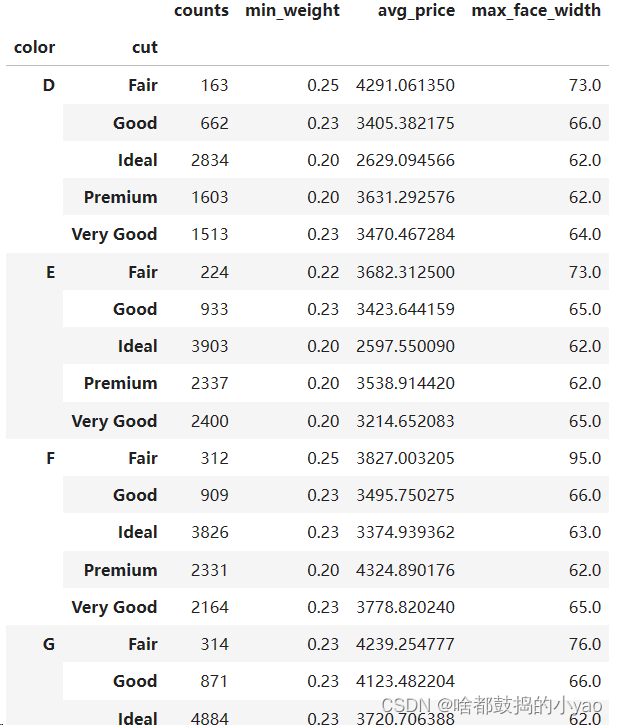
数据的合并
语法
用于合并的函数:
pd.concat(objs, axis=0, join=‘outer’, join_axes=None, ignore_index=False, keys=None)
objs:指定需要合并的对象,可以是序列、数据框或面板数据构成的列表
axis:指定数据合并的轴,默认为0,表示合并多个数据的行,如果为1,就表示合并多个数据的列
join:指定合并的方式,默认为outer,表示合并所有数据,如果改为inner,表示合并公共部分的数据
join_axes:合并数据后,指定保留的数据轴
ignore_index:bool类型的参数,表示是否忽略原数据集的索引,默认为False,如果设为True,就表示
忽略原索引并生成新索引
keys:为合并后的数据添加新索引,用于区分各个数据部分
示例
列合并:
import pandas as pd
# 构造数据集df1和df2
df1 = pd.DataFrame({'name':['张三','李四','王二'], 'age':[21,25,22], 'gender':['男','女','男']})
df2 = pd.DataFrame({'name':['丁一','赵五'], 'age':[23,22], 'gender':['女','女']})
print(df1)
print(df2)
# 数据集的纵向合并
pd.concat([df1,df2] , keys = ['df1','df2']).reset_index()
输出:

import pandas as pd
# 构造数据集df1和df2
df1 = pd.DataFrame({'name':['张三','李四','王二'], 'age':[21,25,22], 'gender':['男','女','男']})
df2 = pd.DataFrame({'name':['丁一','赵五'], 'age':[23,22], 'gender':['女','女']})
# print(df1)
# print(df2)
# 数据集的纵向合并
# pd.concat([df1,df2] , keys = ['df1','df2']).reset_index()
# 合并把没用的列删除,需要添加操作drop
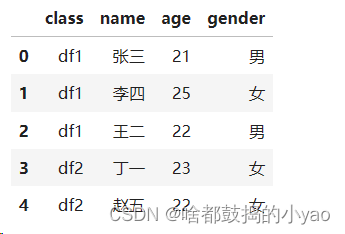
pd.concat([df1,df2] , keys = ['df1','df2']).reset_index().drop(labels='level_1', axis=1)
输出:
import pandas as pd
# 构造数据集df1和df2
df1 = pd.DataFrame({'name':['张三','李四','王二'], 'age':[21,25,22], 'gender':['男','女','男']})
df2 = pd.DataFrame({'name':['丁一','赵五'], 'age':[23,22], 'gender':['女','女']})
# print(df1)
# print(df2)
# 数据集的纵向合并
# pd.concat([df1,df2] , keys = ['df1','df2']).reset_index()
# 合并把没用的列删除,需要添加操作drop
# pd.concat([df1,df2] , keys = ['df1','df2']).reset_index().drop(labels='level_1', axis=1)
# 将变量名进行修正 rename,columns指的是列
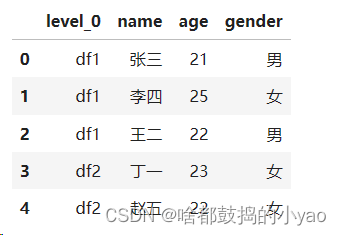
pd.concat([df1,df2] , keys = ['df1','df2']).reset_index().drop(labels='level_1', axis=1).rename(columns={'level_0':'class'})
输出:
行合并:
import pandas as pd
# 构造数据集df1和df2
df1 = pd.DataFrame({'name':['张三','李四','王二'], 'age':[21,25,22], 'gender':['男','女','男']})
# 如果df2数据集中的“姓名变量为Name”
df2 = pd.DataFrame({'Name':['丁一','赵五'], 'age':[23,22], 'gender':['女','女']})
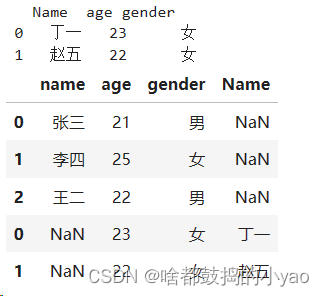
print(df2)
# 数据集的纵向合并(相同变量名则直接合并,没有的话会创建新的)
# concat行合并,数据源的变量名称完全相同(变量名顺序没要求)
pd.concat([df1,df2])
输出:
数据的连接
语法
pd.merge(left, right, how=‘inner’, on=None, left_on=None, right_on=None, left_index=False, right_index=False, sort=False, suffixes=(‘_x’, ‘_y’))
left:指定需要连接的主
right:指定需要连接的辅表
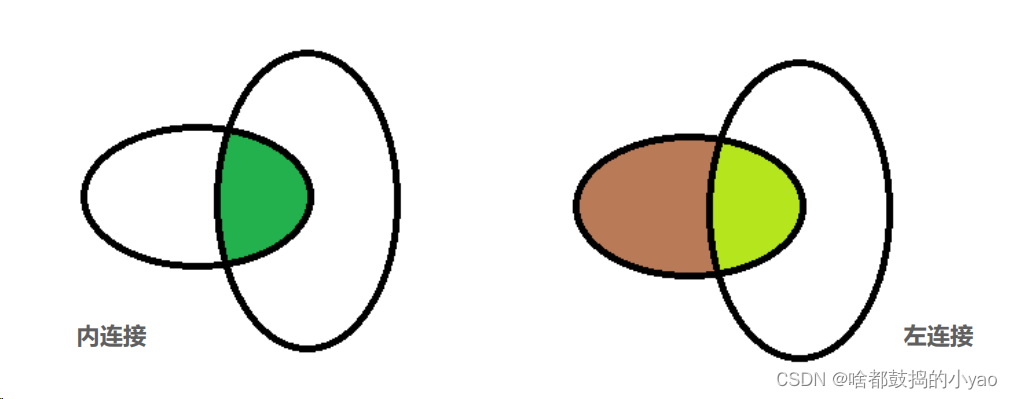
how:指定连接方式,默认为inner内连,还有其他选项,如左连left、右连right和外连outer
on:指定连接两张表的共同字段
left_on:指定主表中需要连接的共同字段
right_on:指定辅表中需要连接的共同字段
left_index:bool类型参数,是否将主表中的行索引用作表连接的共同字段,默认为False
right_index:bool类型参数,是否将辅表中的行索引用作表连接的共同字段,默认为False
sort:bool类型参数,是否对连接后的数据按照共同字段排序,默认为False
suffixes:如果数据连接的结果中存在重叠的变量名,则使用各自的前缀进行区分
示例
# 构造数据集
df3 = pd.DataFrame({'id':[1,2,3,4,5], 'name':['张三','李四','王二','丁一','赵五'], 'age':[27,24,25,23,25],'gender':['男','男','男','女','女']})
df4 = pd.DataFrame({'Id':[1,2,2,4,4,4,5], 'score':[83,81,87,75,86,74,88], 'kemu':['科目1','科目1','科目2','科目1','科目2','科目3','科目1']})
df5 = pd.DataFrame({'id':[1,3,5], 'name':['张三','王二','赵五'], 'income':[13500,18000,15000]})
print(df3)
print(df4)
print(df5)
输出:

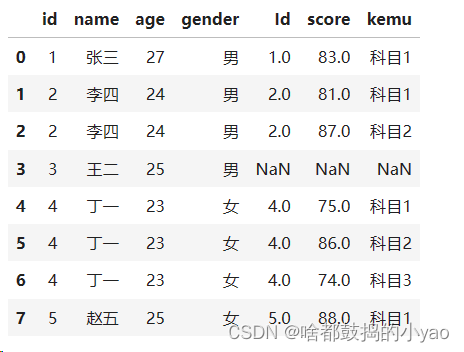
# 三表的数据连接,先两两相连
# 首先df3和df4连接
merge1 = pd.merge(left = df3, right = df4, how = 'left', left_on='id', right_on='Id')
print(merge1)
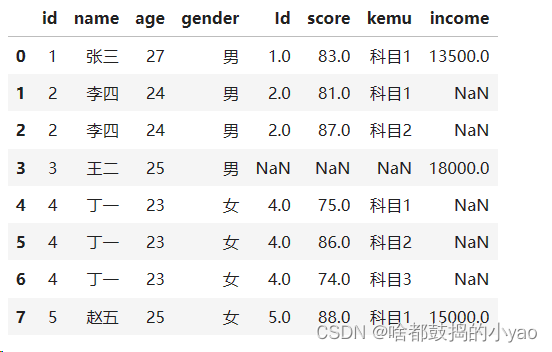
# 再将连接结果与df5连接
merge2 = pd.merge(left = merge1, right = df5, how = 'left')
print(merge2)