Redis与数据库的数据一致性
在使用Redis作为应用缓存来提高数据的读性能时,经常会遇到Redis与数据库的数据一致性问题。简单来说,就是同一份数据同时存在于Redis和数据库,如何在数据更新的时候,保证两边数据的一致性。首先,如果期望Redis与数据库保持强一致性,则必须额外引入分布式事务组件,通过一致性协议(如2PC、3PC等)来保证缓存和数据库的一致性。这里讨论的一致性是最终一致性,即Redis中的数据将最终和数据库中的数据保持一致。
Redis缓存模式
Redis缓存模式并没有统一的范式,这里主要是借鉴本地缓存的设计模式,尝试总结出Redis的缓存模式。本地缓存在进行设计时,主要有以下几种常见的模式:cache aside,read through,write through,write around,write back。
在cache aside模式中,对于读请求,客户端应用会优先访问缓存,如果缓存命中,则直接返回数据;如果缓存未命中,则会进一步请求数据库,然后将数据写入缓存。在read through中,缓存负责保持与数据库的一致。当数据未命中时,缓存会主动从数据库中读取该未命中数据,并回写缓存,然后将这部分数据返回给客户端应用。在write through模式中,数据首先写入缓存,然后写入数据库。与read through一样,写入总是通过缓存到达数据库。在write around模式中,数据直接由客户端应用写入数据库,然后让Cache中对应数据无效。在write back模式中,客户端应用将数据写入缓存后,缓存会立即确认,并在延迟一段时间后将数据写回数据库。更多缓存设计模式相关细节可以参考笔者软件系统缓存设计一文。
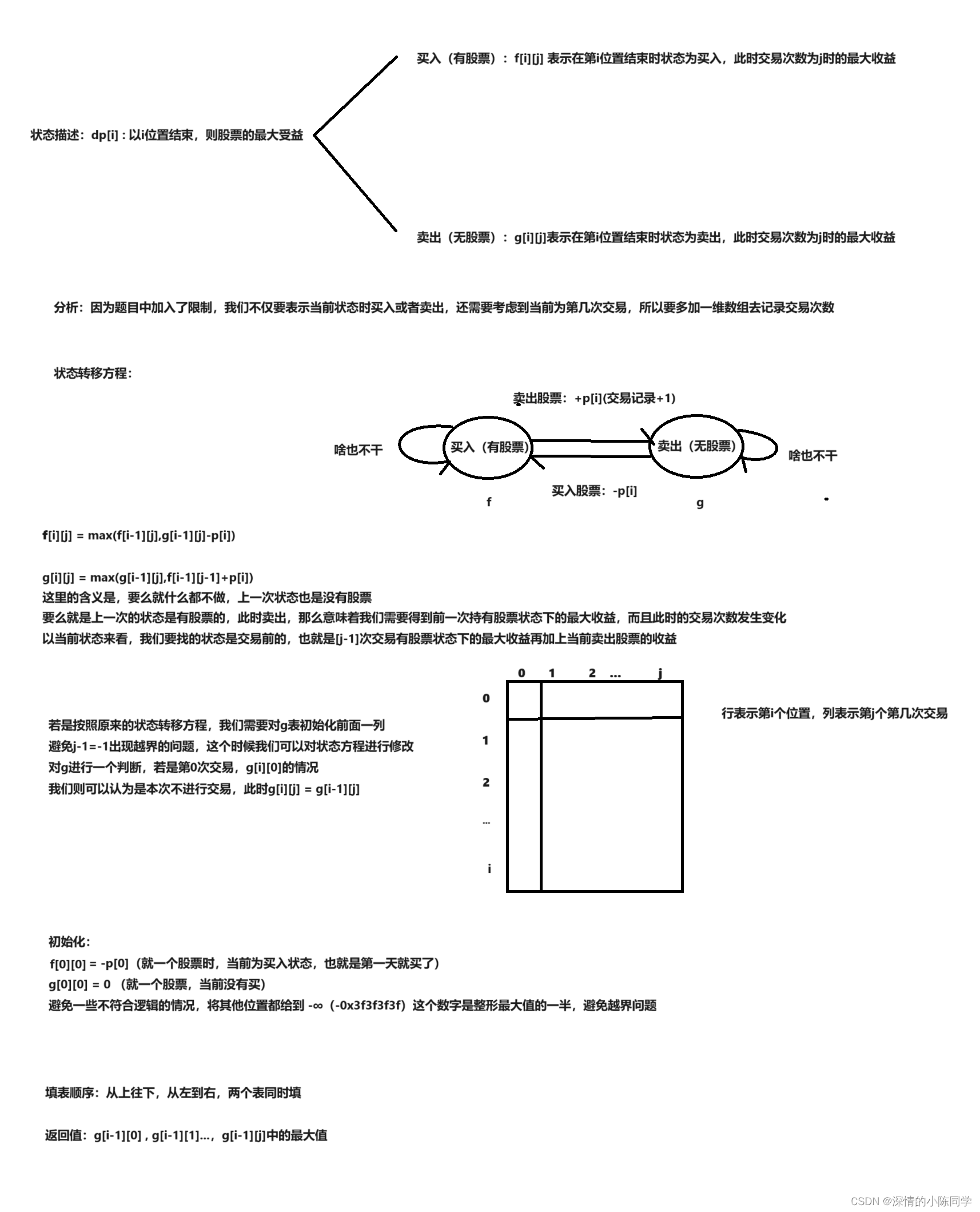
以上五种缓存设计模式,cache aside模式与read through模式主要针对读请求的场景,且在第一次请求数据时,总是会导致缓存未命中,并额外带来将数据加载到缓存的操作。相比cache aside模式是客户端应用从数据库读取缓存未命中数据并将其写入缓存,read through模式是由缓存从数据库读取未命中数据并将其写入到缓存。对于Redis缓存来说,由于Redis缓存和数据库是两个独立的组件,所以Redis缓存不可能使用read through模式,而只能使用cache aside模式。
而write through模式、write around模式与write back模式主要针对写请求的场景,三种模式均需要将数据写入数据库,只是写入的主体或写入的时机不同。对于Redis缓存来说,同样由于Redis缓存和数据库是两个独立的组件,所以Redis缓存不可能使用write through模式或write back模式,而只能使用write around模式,即数据直接由客户端应用写入数据库。至此,Redis缓存的常用设计模式如下:
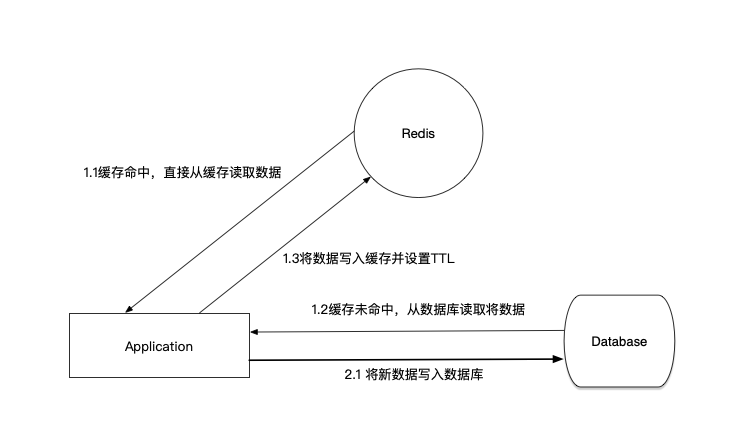
从上图可知,当客户端应用发起读请求时,客户端应用首先尝试从Redis中读取数据,如果缓存中命中数据,则直接从缓存读取数据。如果缓存未命中,则先从数据库读取数据,并将数据写入缓存。当客户端应用发起写请求时,客户端应用直接将新数据写入数据库。同时为保证Redis与Database的最终一致性,在客户端应用将数据写入缓存时,设置一个TTL,避免脏数据一直保存在Redis中。上述过程的伪代码表示如下:
Object readData(String keyStr) {
Object data = readRedis(keyStr);
if (data != null) {
return data;
}
data = readDatabase(keyStr);
writeRedis(keyStr, data, ttl);
return data;
}
boolean writeData(String keyStr, Object data) {
return writeDatabase(keyStr, data);
}
针对写请求场景(新数据写入、已有数据的更新、已有数据的删除),特别是已有数据的更新和已有数据的删除这种情况,因为对于上述模式来说,只是将数据写入数据库,会带来Redis和数据的不一致。因为向Redis写入数据时,设置了TTL,所以一段时间后,Redis中的数据将最终与数据库一致。
总结
如果期望实现Redis缓存中数据与数据库中数据的强一致性,那么需要额外引入分布式事务组件,通过一致性协议(2PC、3PC)来实现实现Redis缓存中数据与数据库中数据的强一致性。但是,分布式事务组件的引入无疑会降低Redis缓存加速查询的初衷。所以很少看到需要Redis缓存中数据与数据库中数据保持强一致性的情况。
既然不强制要求Redis缓存中数据与数据库中数据的强一致性,那么是否可以加快Redis中数据与数据库中数据一致性的收敛速度呢?网络上针对如何加快Redis中数据与数据库中数据一致性的收敛速度,提出了多种解决方案,如:先更新数据库,再更新Redis;先更新数据库,再删除Redis中数据(直接删除Redis、延迟删除Redis);先删除Redis中数据,再更新数据库;先尝试删除Redis中数据,再更新数据库,再尝试删除Redis中数据(双删策略);先写数据库,然后通过binlog或队列,异步更新Redis中数据。笔者认为,以上方案虽然自成一体,但是不免纸上谈兵、画蛇添足,存在过度设计的问题。以上方案的一个公共特征是为了加快Redis中数据与数据库中数据一致性的收敛速度,需要执行多余的Redis写入步骤或引入额外的功能或组件(如数据库的binlog日志、队列等)。且在提升设计复杂度的同时,并没有真正起到加速一致性收敛的效果或收效甚微。且额外的Redis写入操作会加大Redis主从结点间同步负担,带来更多问题。
笔者认为,使用Redis作为缓存,就是已经接受了Redis缓存中数据可能存在脏数据的情况,且用户对数据不一致性的时间可容忍。与其考虑如何加快一致性收敛的速度,倒不如从业务出发,考虑Redis缓存的使用姿势是否合理,如将一些频繁更新且用户敏感的数据保存到Redis缓存就是一种不合理的使用;将数据长期的存储在Redis缓存中,且设置过长的TTL就是将Redis当做数据库使用,而不是缓存。此外,还应考虑将缓存前置,尝试使用客户端应用的本地缓存来提升性能。
参考
https://mp.weixin.qq.com/s/az1D1lKcoU9hiOIJjmjlJQ 4 种策略让 MySQL 和 Redis 数据保持一致
https://mp.weixin.qq.com/s/RL4Bt_UkNcnsBGL_9w37Zg 如何保障 MySQL 和 Redis 的数据一致性?