爬虫的五个步骤:
1)需求分析,找到需求相关的网址
2)获取网址的返回信息(urllib,requests)
3)定位需要的信息所在位置(re正则表达式,XPATH, CSS selector)
4)内容的存储 (open,pymysql,pymongo)
第一步,观察http的包,使用requests的包,get,post
包头中重要的信息描述:
1)cookie:能够存储一些服务器端的信息,与session共同完成身份标志的工作。
2)user-agent:标签
3)referer:从那个页面跳转过来的。
开始第一个爬虫案例吧,
import requests
url='http://www.baidu.com'
response=requests.get(url)
print(response.text)
#返回内容遇到乱码,是encoding的问题
response.encoding='utf-8'
print(response.text)运行结果如下图所示,第一个print显示乱码,加入encoding之后再print正常显示
 #返回html信息的二进制(bytes)类型,response.content
#返回html信息的二进制(bytes)类型,response.content
print(response.content)
输出如下内容: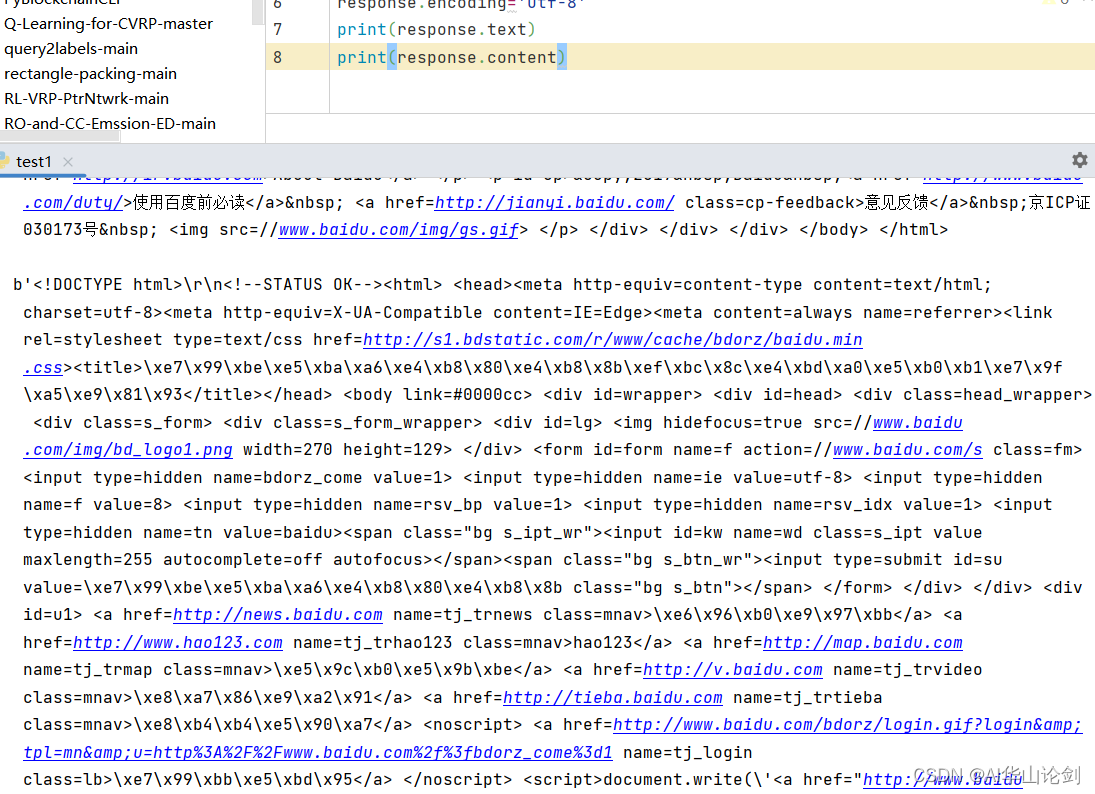 最后一步保存到文件系统
最后一步保存到文件系统
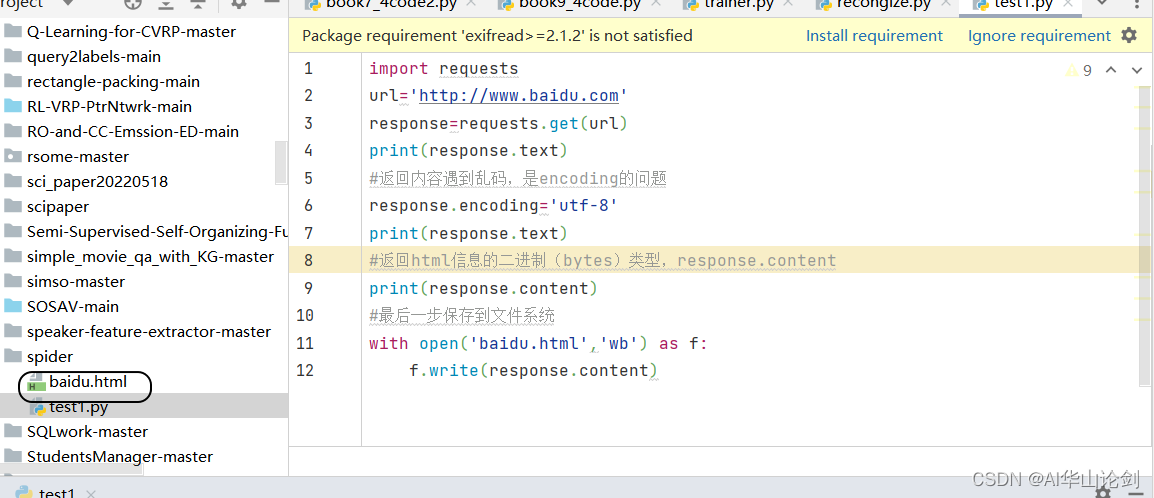
得到所想要的网站html文件。
完整代码如下:
import requests
url='http://www.baidu.com'
response=requests.get(url)
print(response.text)
#返回内容遇到乱码,是encoding的问题
response.encoding='utf-8'
print(response.text)
#返回html信息的二进制(bytes)类型,response.content
print(response.content)
#最后一步保存到文件系统
with open('baidu.html','wb') as f:
f.write(response.content)