Scrapy的入门使用
- Scrapy
- 概述
- 引擎(Engine)
- 调度器(Scheduler)
- 下载器(Downloader)
- Spider
- Item Pipeline
- 基本使用
- 安装scrapy
- 创建项目
- 定义Item数据模型对象
- 创建爬虫(Spider)
- 管道pipeline来保存数据
- 启动爬虫
- 其他
- 解析函数对象
- 实现多请求
- scrapy终端(Scrapy shell)
- 启动终端
- 可用Scrapy对象
- 快捷命令
Scrapy
概述
Scrapy是一个用Python编写的开源网络爬虫框架,专门设计用于快速、高效地提取网站数据。它提供了一整套工具和库,可以帮助开发人员创建和管理网络爬虫,用于抓取特定网站的数据并进行处理。
英文文档:https://docs.scrapy.org/en/latest/
GitHub:https://github.com/scrapy/scrapy
中文文档:https://scrapy-chs.readthedocs.io/zh_CN/latest/
Scrapy是一个基于Python的Web爬虫框架,由多个组件组成,包括了引擎(Engine)、调度器(Scheduler)、下载器(Downloader)、Spider、Item Pipeline等。
引擎(Engine)
引擎是Scrapy的核心组件之一,负责调度和协调各个组件的工作。它接收Spider返回的初始请求,并将其传递给调度器,再由调度器根据一定的策略进行调度,最终将请求发送给下载器进行下载。在下载器将响应内容返回后,引擎将调用Spider的回调函数进行处理,再将处理后的数据交给Item Pipeline进行处理。
调度器(Scheduler)
调度器负责对Spider的请求进行调度,决定请求的顺序和时间。它维护了一个请求队列,并根据一定的调度策略,将请求传递给下载器进行下载。在下载完成后,调度器将下载器返回的响应对象传递给Spider进行处理。
下载器(Downloader)
下载器负责从互联网上下载页面和资源。它接收调度器传递的请求对象,并根据请求中的URL和请求头信息进行下载。下载器可以通过设置代理、Cookies和请求头等信息,模拟浏览器的行为,避免被服务器拒绝访问。在下载完成后,下载器将响应对象返回给调度器。
Spider
Spider是用户编写的爬虫代码,定义了如何爬取和处理页面数据。它通过yield关键字返回请求对象或者Item对象,并可以定义一个或多个回调函数,在下载器返回响应对象后进行解析和处理。Spider可以通过设置start_urls或者start_requests方法返回一个或多个初始请求对象。
Item Pipeline
Item Pipeline负责处理Spider返回的Item对象,可以对数据进行过滤、清理、验证等操作。它将Item对象传递给一系列的管道处理器,每个管道处理器可以对Item对象进行一些处理操作,然后将处理后的Item对象传递给下一个管道处理器。在最后一个管道处理器处理完成后,Item Pipeline将Item对象输出到文件或者数据库中。
基本使用
安装scrapy
pip install scrapy
查看帮助命令
> scrapy --help
Scrapy 2.8.0 - no active project
Usage:
scrapy <command> [options] [args]
Available commands:
bench Run quick benchmark test
fetch Fetch a URL using the Scrapy downloader
genspider Generate new spider using pre-defined templates
runspider Run a self-contained spider (without creating a project)
settings Get settings values
shell Interactive scraping console
startproject Create new project
version Print Scrapy version
view Open URL in browser, as seen by Scrapy
[ more ] More commands available when run from project directory
Use "scrapy <command> -h" to see more info about a command
创建项目
scrapy startproject 项目名称
会在当前目录下创建一个名为project_name的目录,包含了Scrapy项目的基本结构。
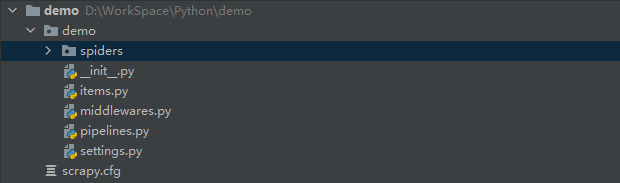
项目目录结构:
scrapy.cfg: 项目的配置文件
demo: 项目的python模块,之后将在此加入代码
demo/spiders/: 爬虫组件目录
demo/items.py: 定义数据模型
demo/middlewares.py: 自定义中间件
demo/pipelines.py: 自定义管道,保存数据
demo/settings.py: 爬虫配置信息
定义Item数据模型对象
Item是保存爬取到的数据的容器。通过创建一个 scrapy.Item 类, 并且定义类型为scrapy.Field的类属性来定义一个Item
定义item即提前规划好哪些字段需要抓,防止在爬取数据过程中写错。
配合注释一起可以清晰的知道要抓取哪些字段,
数据模型对象类定义以后需要在爬虫中导入并且实例化,使用方法和使用字典相同
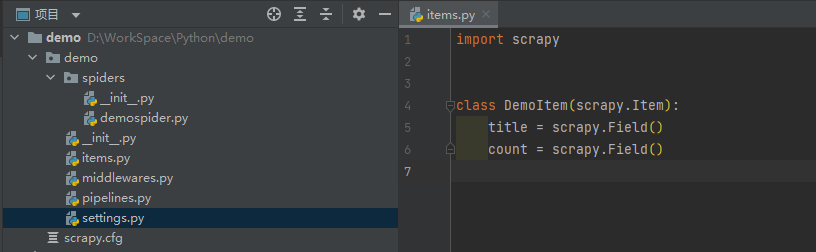
在items.py中定义模型对象,定义要提取的字段:
import scrapy
class DemoItem(scrapy.Item):
# 标题
title = scrapy.Field()
# 数量
count = scrapy.Field()
创建爬虫(Spider)
Spider是编写用于从单个网站(或者一些网站)爬取数据的类。其包含一个用于下载的初始URL,如何跟进网页中的链接以及如何分析页面中的内容, 提取生成 item 的方法。
创建一个Spider,必须继承scrapy.Spider类, 且定义一些属性、方法:
name:
用于区别Spider。 该名字必须是唯一的,不可以为不同的Spider设定相同的名字。
start_urls:
包含Spider在启动时进行爬取的url列表。 因此,第一个被获取到的页面将是其中之一。 后续的URL则从初始的URL获取到的数据中提取。
parse() :
parse()是spider的一个方法。 被调用时,每个初始URL完成下载后生成的Response对象将会作为唯一的参数传递给该函数。 该方法负责解析返回的数据(response data),提取数据(生成item)以及生成需要进一步处理的URL的 Request 对象。
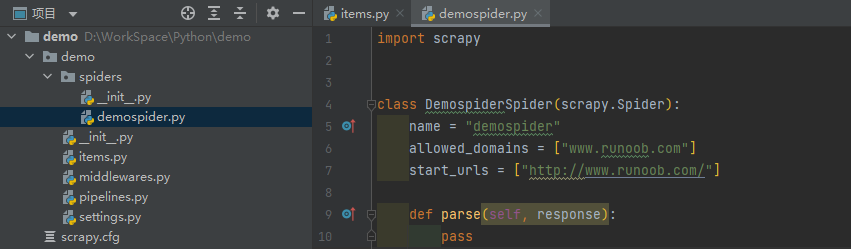
在demo/spiders目录下创建demospider.py文件,需要定义一个Spider类,继承自scrapy.Spider类,并重写start_requests()和parse()方法。
import scrapy
from demo.items import DemoItem
# 继承自爬虫类
class DemospiderSpider(scrapy.Spider):
# 定义爬虫名称
name = "demospider"
# 设置允许爬取的范围
allowed_domains = ["www.runoob.com"]
# 设置开始爬取的请求地址
start_urls = ["https://www.runoob.com/"]
# 实现解析函数,提取数据或者提取URL,并提交给引擎
def parse(self, response):
# scrapy的response对象可以直接进行xpath
list = response.xpath('/html/body/div[4]/div/div[2]/div/h2/text()').extract()
print("--------------------------------")
index = 1
for title in list:
div = "div[" + str(index) + "]"
index = index + 1
count = response.xpath('/html/body/div[4]/div/div[2]/' + div + '/a/h4/text()').extract()
item = DemoItem()
item['title'] = title
item['count'] = len(count)
# 提交数据给引擎
# yield能够传递的对象只能是:BaseItem, Request, dict, None
yield item
使用命令方式可以快速创建一个爬虫编写的基本结构
cd 项目目录
scrapy genspider 爬虫名称 允许域名
>scrapy genspider demospider www.runoob.com
Created spider 'demospider' using template 'basic' in module:
demo.spiders.demospider
管道pipeline来保存数据
数据在被抓取后,被发送到管道,接着进行管道操作,比如:
清理 HTML 数据
验证抓取的数据(检查项目是否包含某些字段)
检查重复项(并删除它们)
将抓取的项目存储在数据库中
在运行爬虫时添加 -o参考可以将数导出
scrapy crawl 爬虫名称 -o 导出文件
在pipelines.py文件中创建DemoPipeline管道类,打印爬虫的parse() 方法提取的数据
class DemoPipeline:
# 爬虫文件中提取数据的方法每yield一次item,就会运行一次
def process_item(self, item, spider):
print("title: {} , count: {}".format(item['title'], item['count']))
return item
完整管道实现如下:
# 1.在pipelines.py中编写管道实现
# 2.定义管道类
class DemoPipeline:
# 3.必须实现process_item(self,item,spider),在管道接收数据对象时回调,用于接收和处理每个数据对象
def process_item(self, item, spider):
print("title: {} , count: {}".format(item['title'], item['count']))
return item
# 4.可选实现
def open_spider(self, spider):
print("爬虫启动时回调,用于初始化操作")
def close_spider(self, spider):
print("爬虫关闭时回调,用于释放操作")
接着在settings.py中开启管道
配置项中键为使用的管道类,参数的值是一个权重,越小越优先执行
ITEM_PIPELINES = {
"demo.pipelines.DemoPipeline":1
}
注意事项:
在管道实现函数中process_item必须有返回值,传递给下一个管道
多管道实现时可以通过类型判断或爬虫名称判断区分存储的数据
启动爬虫
在命令行中,进入目录,并输入以下命令,运行Spider:
scrapy crawl 爬虫名称
scrapy crawl demospider
控制台打印了爬虫提取数据日志与管道保存数据日志,如下所示:
--------------------------------
title: HTML / CSS , count: 9
2023-02-22 14:07:26 [scrapy.core.scraper] DEBUG: Scraped from <200 https://www.runoob.com/>
{'count': 9, 'title': ' HTML / CSS'}
title: JavaScript , count: 18
2023-02-22 14:07:26 [scrapy.core.scraper] DEBUG: Scraped from <200 https://www.runoob.com/>
{'count': 18, 'title': ' JavaScript'}
title: 服务端 , count: 26
2023-02-22 14:07:26 [scrapy.core.scraper] DEBUG: Scraped from <200 https://www.runoob.com/>
其他
解析函数对象
response对象
response响应对象封装从互联网上返回的响应,具有如下常用属性
response.url:当前响应的url地址
response.request.url:当前响应对应的请求的url地址
response.headers:响应头
response.requests.headers:当前响应的请求头
response.body:响应体,也就是html代码,byte类型
response.status:响应状态码
Selector对象
Selector对象封装数据操作的对象
xpath:可以使用 xpath 提取数据,返回 SelectorList 对象
css:可以使用 css 样式选择器提取数据,返回 SelectorList 对象
extract:从selector对象中提取内容
SelectorList对象
返回 Selector 对象的合集
extract_first :取列表中第一个元素的内容,如果元素不存在返回 None
extract :提取列表中selector对象中所有内容
提交数据给引擎
使用关键词 yield,在爬虫组件的解析函数中提交数据给引擎
提交数据类型:BaseItem、Request、dict、None
def parse(self,response):
...
item = {}
item["data"] = "数据"
yield item
实现多请求
构造Request对象,继续发送请求,从而实现多请求
scrapy.Request构建方式
scrapy.Request(url[,callback,method="GET",headers,body,cookies,meta,dont_filter=False])
注意:中括号里的参数为可选参数,具体意思如下:
callback: 表示当前的url的响应交给哪个函数去处理
method:指定POST或GET请求
headers:接收一个字典,其中不包括cookies
cookies:接收一个字典,专门放置cookies
body:接收json字符串,为POST的数据,发送payload_post请求时使用
meta: 实现数据在不同的解析函数中传递,meta默认带有部分数据,比如下载延迟,请求深度等
dont_filter: 默认会过滤请求的url地址,即请求过的url地址不会继续被请求,对需要重复请求的url地址可以把它设置为Ture
meta的作用:meta可以实现数据在不同的解析函数中的传递
meta参数的使用
利用meta参数在不同的解析函数中传递数据
def parse(self,response):
...
yield scrapy.Request(detail_url, callback=self.parse_detail,meta={"item":item})
...
def parse_detail(self,response):
# 获取传入的item
item = resposne.meta["item"]
使用关键词 yield,提交请求给引擎
# 实现解析函数,提取数据或者提取URL,并提交给引擎
def parse(self, response):
for title in response.xpath('//title').getall():
item = DemoItem()
item['title'] = title
yield item
for href in response.xpath('//a/@href').getall():
yield scrapy.Request(response.urljoin(href), self.parse)
scrapy终端(Scrapy shell)
Scrapy终端是一个交互终端,在未启动spider的情况下尝试及调试爬取代码,如用来测试XPath或CSS表达式
启动终端
scrapy shell
scrapy shell 爬取地址
scrapy shell www.runoob.com
可用Scrapy对象
Scrapy终端根据下载的页面会自动创建一些方便使用的对象
[s] Available Scrapy objects:
[s] scrapy scrapy module (contains scrapy.Request, scrapy.Selector, etc)
[s] crawler <scrapy.crawler.Crawler object at 0x00000114BB2603A0>
[s] item {}
[s] request <GET http://www.runoob.com>
[s] response <200 https://www.runoob.com/>
[s] settings <scrapy.settings.Settings object at 0x00000114BB260940>
[s] spider <DemospiderSpider 'demospider' at 0x114bb6f6dc0>
[s] Useful shortcuts:
[s] fetch(url[, redirect=True]) Fetch URL and update local objects (by default, redirects are followed)
[s] fetch(req) Fetch a scrapy.Request and update local objects
[s] shelp() Shell help (print this help)
[s] view(response) View response in a browser
快捷命令
shelp() - 打印可用对象及快捷命令的帮助列表
fetch(request_or_url) - 根据给定的请求(request)或URL获取一个新的response,并更新相关的对象
view(response) - 在本机的浏览器打开给定的response
>>> fetch(request)
2023-02-22 15:52:11 [scrapy.downloadermiddlewares.redirect] DEBUG: Redirecting (302) to <GET https://www.runoob.com/> from <GET http://www.runoob.com>
2023-02-22 15:52:11 [scrapy.core.engine] DEBUG: Crawled (200) <GET https://www.runoob.com/> (referer: None)
>>> view(response)
True