欢迎关注我的CSDN:https://spike.blog.csdn.net/
本文地址:https://blog.csdn.net/caroline_wendy/article/details/137009993
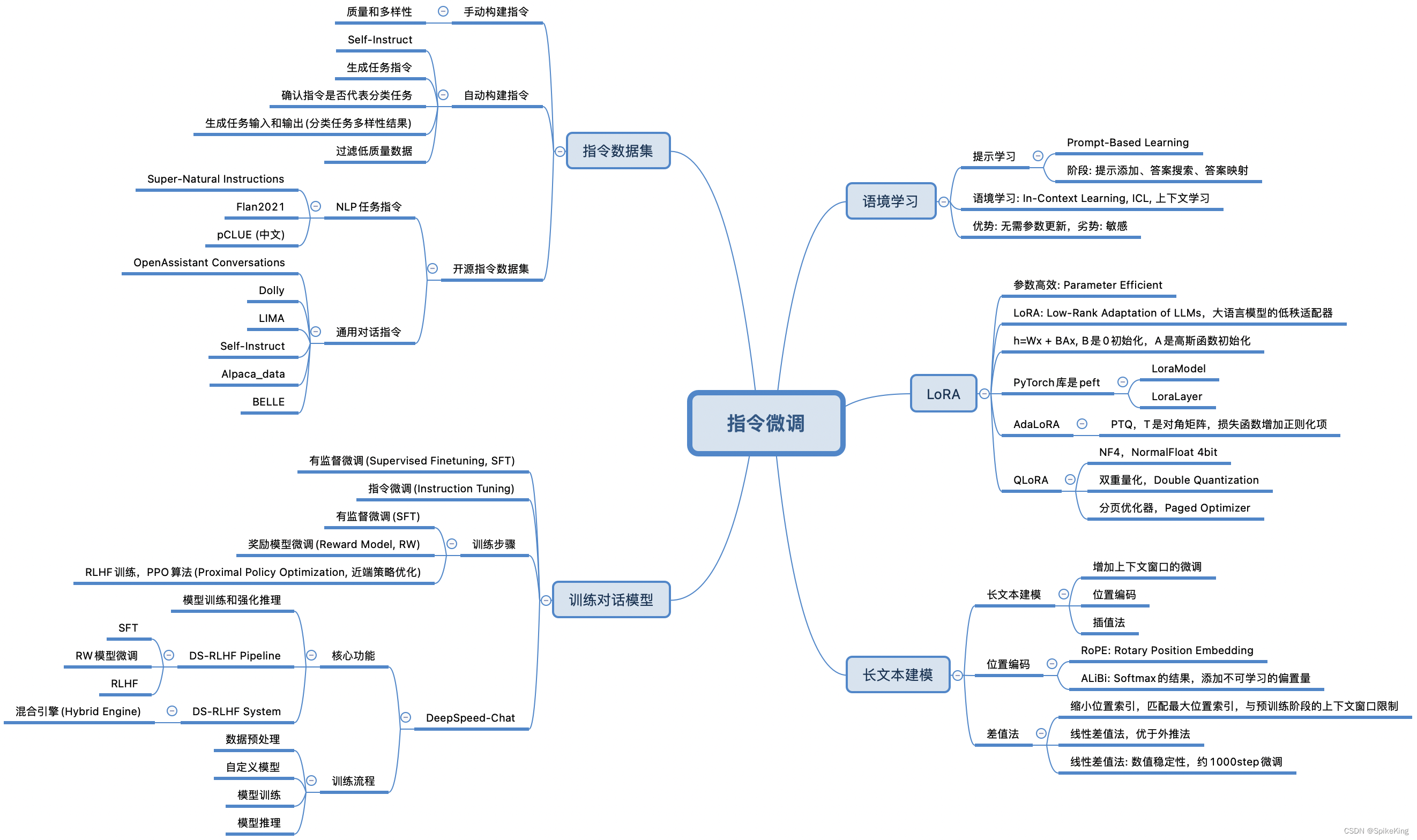
大语言模型的指令微调(Instruction Tuning)是一种优化技术,通过在特定的数据集上进一步训练大型语言模型(LLMs),使其能够更好地理解和遵循人类的指令。这个数据集通常由一系列的指令和相应的期望输出组成。指令微调的目的是提高模型的能力和可控性,使其在执行任务时能够更准确地响应用户的需求。
指令微调通常包含:
- 构建指令格式数据:这些实例包含任务描述、一对输入输出以及示例(可选)。
- 有监督微调(Supervised Finetuning, SFT):在这些指令格式的实例上对大型语言模型进行微调。
- 提高推理能力:通过指令微调,模型能够更好地利用其知识库,回答问题或完成任务。
- 泛化到未见过的任务:经过指令微调的模型能够在新任务上表现得更好,即使这些任务在微调过程中没有被直接训练过。
指令微调的效果是使得大型语言模型在理解复杂问题和执行多样化任务时更加精准和高效。
1. 语境学习
在大型语言模型中,**提示学习(Prompt-Based Learning)和语境学习(In-Context Learning, ICL)**是两种提高模型性能的方法。
提示学习,通过设计特定的提示(Prompt),引导模型生成预期的回答或完成特定的任务。这种方法依赖于模型的预训练知识和生成能力,通过提供上下文信息或关键词提示,激发模型的补全能力。例如,给定一个句子的一部分,让模型完成整个句子。这种方法,主要关注模型的生成能力,和如何利用已有的知识来理解和回应提示。
语境学习,使得模型能够在不进行额外训练的情况下,通过观察一些 输入-输出 示例来学习如何执行新的任务。ICL的关键思想是从类比中学习。例如,如果需要让模型进行文本分类,可以提供几个正确分类的样例,模型就能依据这些样例进行分类。ICL不需要参数更新,并直接对预先训练好的语言模型进行预测。这种方法的优势在于,可以快速适应新任务,而无需对模型权重进行调整。
这两种方法都在提高大型语言模型在特定任务上的表现方面发挥着重要作用,但是,应用和原理有所不同。提示学习,更多地关注于如何设计有效的提示来引导模型的回答,而语境学习,则关注于模型如何利用上下文中的示例来快速适应新任务。
语境学习(In-Context Learning, ICL),如下:

2. LoRA

LoRA算法,全称为Low-Rank Adaptation,是大型语言模型的高效参数微调方法。核心思想是通过低秩矩阵分解,来近似模型权重的更新,从而在不显著增加参数量的情况下,实现对模型的微调。
具体来说,LoRA算法在预训练的语言模型中增加两个小的矩阵A和B。在微调过程中,固定原始模型的权重不变,只更新这两个矩阵。通过这种方式,LoRA算法能够在保持模型性能的同时,显著减少微调所需的参数量和计算资源。
LoRA算法的步骤包括:
- 选择微调的模型层:通常选择对模型性能影响较大的层,如自注意力层的权重。
- 初始化A和B矩阵:A矩阵通常使用随机高斯分布初始化,B矩阵使用零矩阵初始化。
- 训练A和B矩阵:在训练过程中,只对这两个矩阵进行更新,而不改变原始模型的权重。
- 合并权重:训练完成后,将B矩阵与A矩阵相乘,得到的结果与原始模型的权重合并,作为微调后的模型参数。
LoRA算法的优点在于,能够有效地减少微调所需的资源,同时保持或甚至提高模型的性能。这使得在资源有限的情况下,也能对大型语言模型进行有效的微调。特别适用于那些参数量巨大的模型,如GPT-3等。此外,LoRA微调对于低秩矩阵的秩数和目标模块的选择比较敏感,这可能会影响模型的性能和稳定性。因此,在实际应用中,需要仔细选择这些参数以达到最佳的微调效果。
LoRA算法结构,如下:

3. 长文本建模

大语言模型的长文本建模是一个挑战,因为需要模型能够处理和理解大量的文本数据。为了解决这个问题,研究人员开发了一些方法来增强模型的长文本处理能力。
-
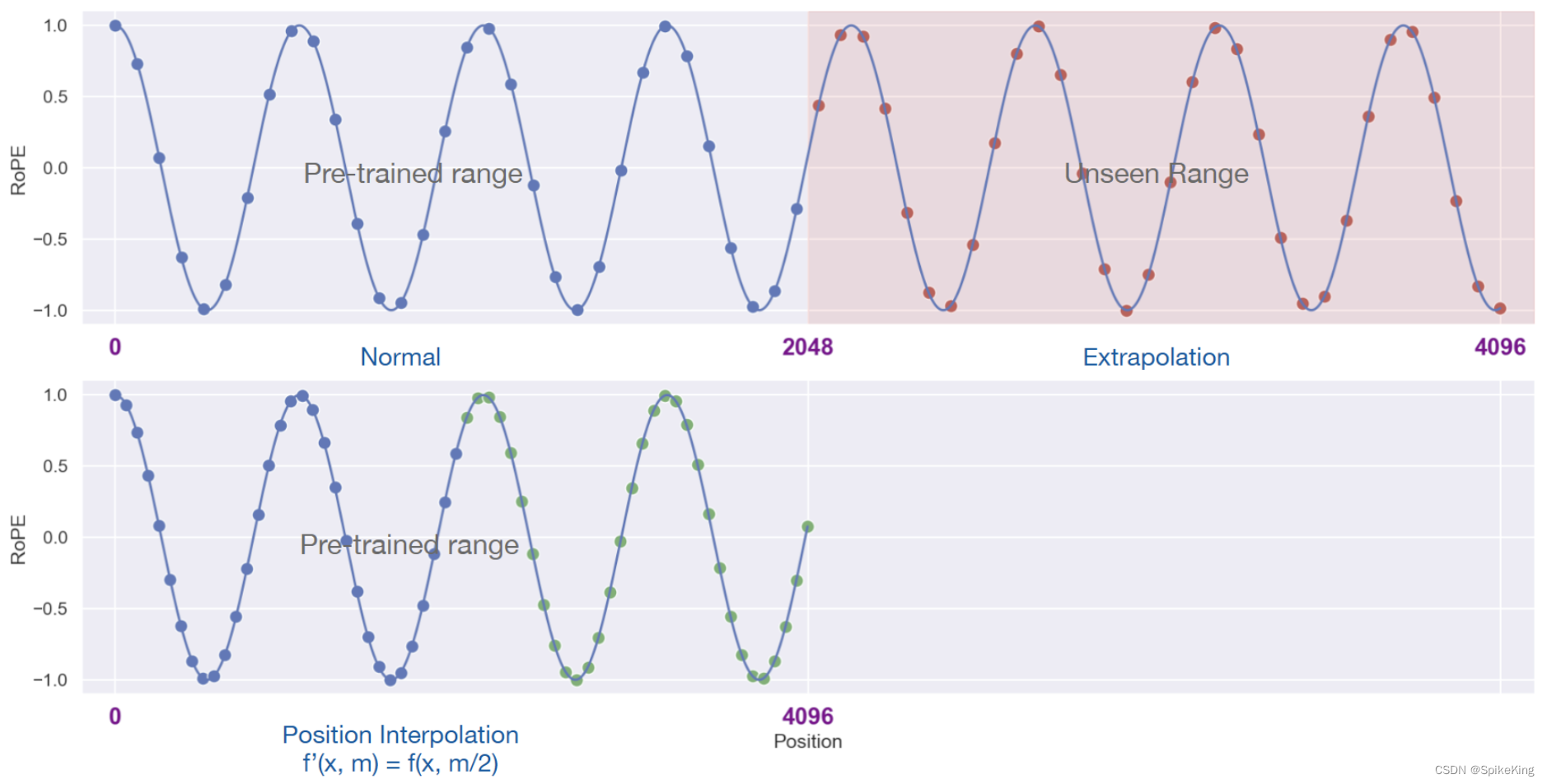
具有外推能力的位置编码(Extrapolative Position Encoding),允许模型处理比在训练期间遇到的更长的文本序列。这种编码方式,通常基于模型在训练时学习到的位置模式,然后,将这些模式应用到更长的序列上,从而,使模型能够外推并处理超出其原始训练范围的文本长度。
-
插值法压缩位置编码(Interpolative Position Encoding Compression),通过在已知的位置编码之间,进行插值来创建新的位置编码,从而使模型能够处理更长的文本序列,而不需要显著增加计算复杂性或模型大小。这种方法通过线性地缩小输入位置索引来匹配原始上下文窗口的大小,而不是外推超过训练的上下文长度,这有助于避免可能导致注意力机制崩溃的高注意力分数。
总的来说,这些方法都旨在提高大型语言模型处理长文本的能力,无论是通过外推还是插值,都是为了让模型能够更好地理解和生成长文本内容。对于一些需要长文本理解的应用场景,如文档摘要、阅读理解等,尤其重要。一般而言,插值法的效果优于外推法。
外推法(Extrapolation)与插值法(Interpolation)的对比,如图:
4. 指令数据集
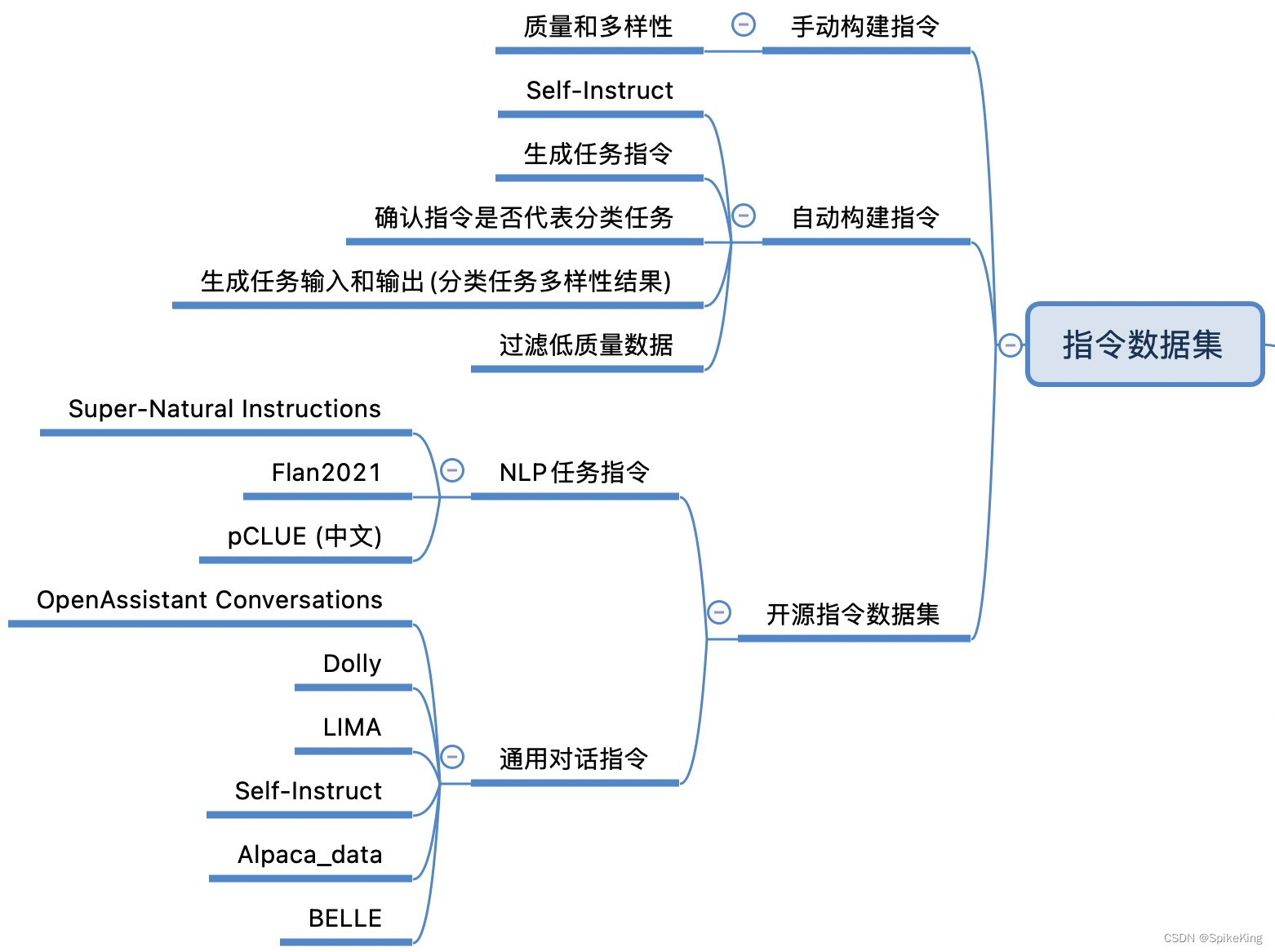
大语言模型中的指令微调数据集是一组特别设计的数据,用于训练和优化模型,使其更好地理解和遵循人类的指令。这些数据集通常包含一系列的指令和相应的期望输出,目的是提高模型在执行任务时的准确性和可控性。
指令微调数据集的构建过程通常包括:
- 定义任务和指令:明确模型需要执行的任务,并且,为每个任务创建清晰的指令。
- 收集或生成输出:对于每个指令,提供或生成一个或多个正确的输出作为模型的训练目标。
- 质量控制:确保数据集中的指令和输出是高质量的,能够准确反映任务的需求。
在实际应用中,指令微调数据集可能包括各种类型的任务,如文本分类、问答、文本生成等。这些数据集可以是公开的,也可以是私有的,取决于模型的训练需求和目标。一些已知的指令微调数据集包括:
- Natural Instructions:这是一个包含多种自然语言处理任务的数据集,旨在提高模型的泛化能力。
- P3(Public Pool of Prompts):由多个英语NLP数据集构建的数据集,包含多样化的任务和提示。
- xP3(Cross-lingual Public Pool of Prompts):一个多语言指令数据集,包含不同自然语言任务的数据。
这些数据集,帮助模型学习如何根据给定的指令生成正确的输出,从而在实际应用中更好地服务于用户的需求,对于提升大语言模型的指令遵循能力至关重要。
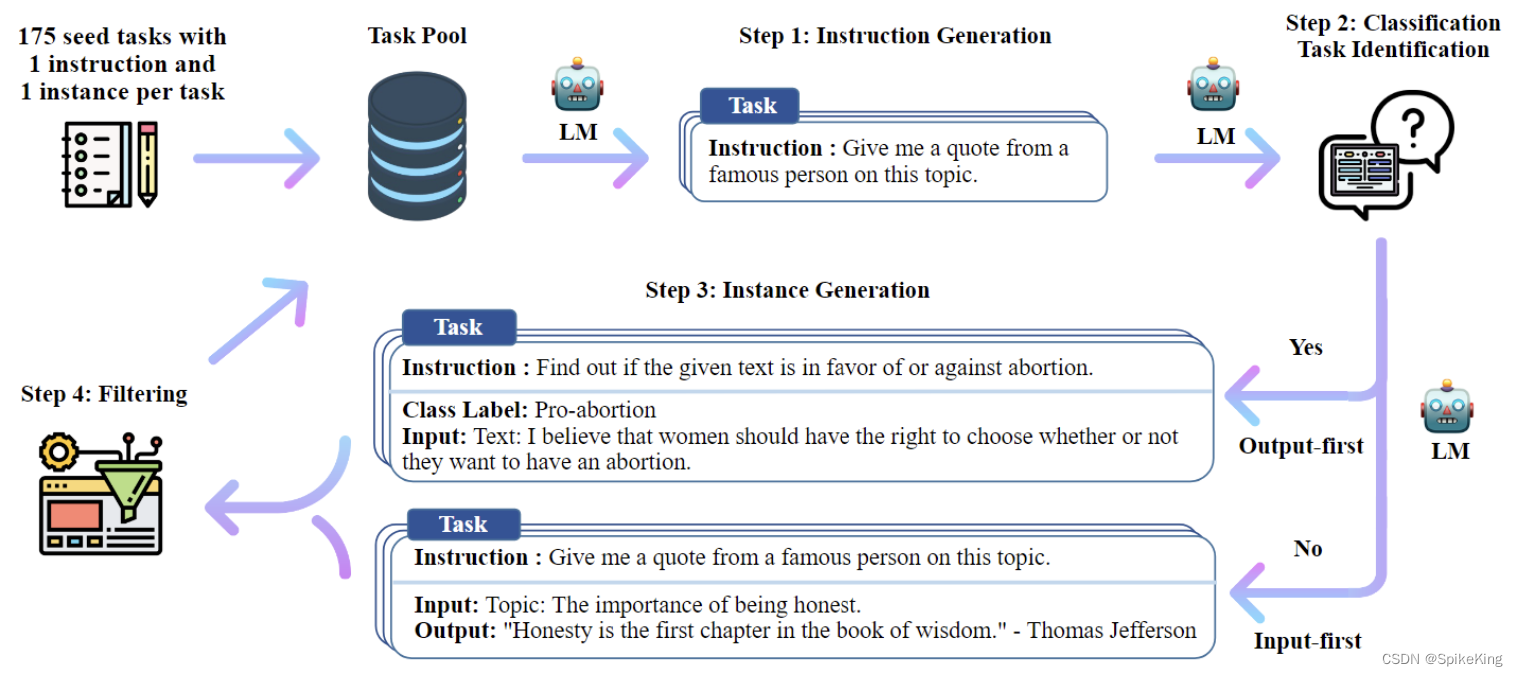
自动构建(Self-Instruct)指令的过程,如下:
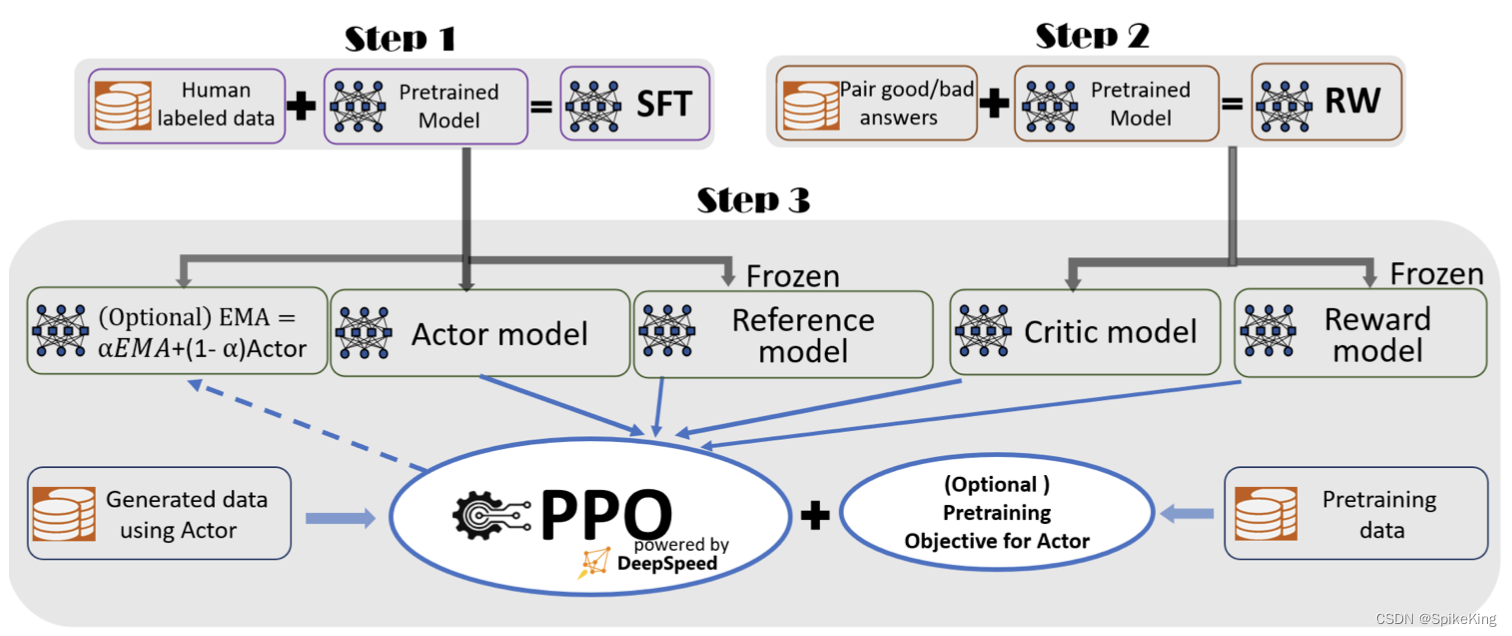
5. 训练对话模型
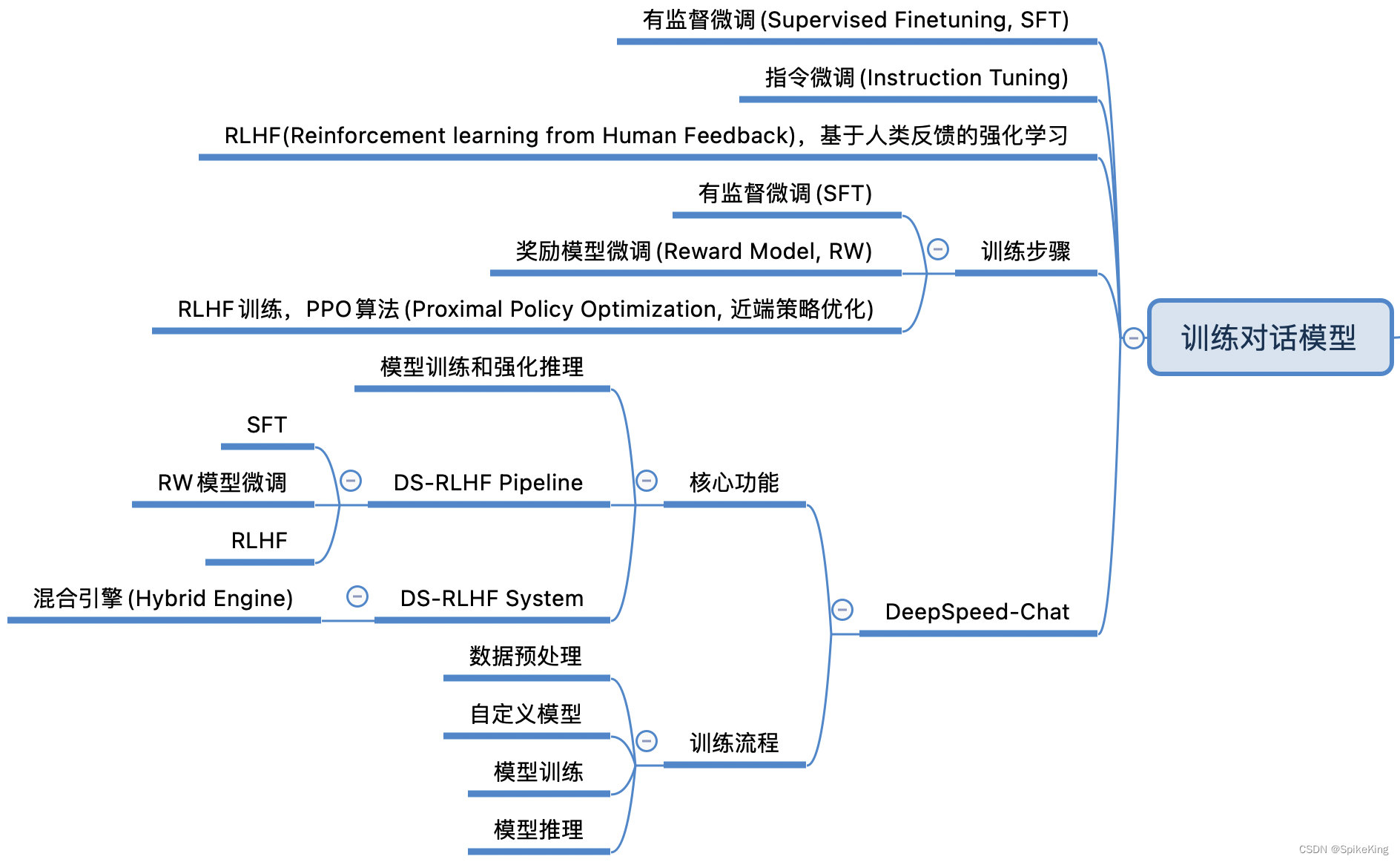
在大型语言模型中,训练对话模型通常涉及以下几个关键步骤:
-
预训练(Pretraining):
首先,模型在大规模的数据集上进行预训练,以学习语言的基本结构和语义信息。这一阶段是为了让模型掌握通用的语言理解能力。 -
有监督微调(Supervised Finetuning, SFT):
在预训练的基础上,模型会使用有标注的特定任务数据进行进一步的微调。这一步骤旨在使模型具备遵循指令的能力,从而更好地适应特定的对话任务。 -
奖励模型微调:
奖励模型微调是在有监督微调之后的步骤,涉及到使用人类标注员的反馈来训练一个奖励模型。这个模型能够评估不同的回答,并指导主模型生成更符合人类偏好的回答。 -
基于人类反馈的强化学习(RLHF):
最后,模型会通过RLHF进一步微调。在这个过程中,使用人类反馈来创建奖励信号,然后利用这些信号通过强化学习算法来改进模型的行为。这有助于模型在复杂的对话任务中表现得更好。
这些步骤共同构成了一个迭代的训练过程,旨在不断提升模型在特定对话任务中的性能和准确性。每个步骤都是基于前一个步骤的结果进行的,以确保模型能够有效地适应并执行其被训练的任务。
DeepSpeed-Chat 的训练对话模型,如下:




![[寿司力扣DP对于应用]712. 两个字符串的最小ASCII删除和【详细图解】](https://img-blog.csdnimg.cn/direct/c170f043b2f84215877b2eb59d98c3d8.png)