介绍
2024年3月28日,阿里团队推出了Qwen系列的首个MoE模型,Qwen1.5-MoE-A2.7B。它仅拥有27亿个激活参数,但其性能却能与当前最先进的70亿参数模型,如Mistral 7B和Qwen1.5-7B相媲美。相较于包含65亿个Non-Embedding参数的Qwen1.5-7B,Qwen1.5-MoE-A2.7B只有20亿个Non-Embedding参数,约为原模型大小的三分之一。此外,相比Qwen1.5-7B,Qwen1.5-MoE-A2.7B的训练成本降低了75%,推理速度则提升了1.74倍。
模型结构
Qwen1.5-MoE模型中采用了特别设计的MoE架构。如Mixtral等方法所示,每个transformer block中的MoE层会配备8个expert,并采用top-2门控策略进行routing。这种配置还存在很大的优化空间。阿里团队还这一架构进行了多项改进:
- Finegrained experts
- 初始化
- 新的routing机制
DeepSeek-MoE和DBRX已经证明了finegrained experts的有效性。从FFN层过渡到MoE层时,般只是简单地复制多次FFN来实现多个expert。而finegrained experts的目标是在不增加参数数量的前提下生成更多expert。为了实现这一点,将单个FFN分割成几个部分,每个部分作为一个独立的expert。阿里团队设计了具有总共64个expert的的MoE,对比其他配置,这个实现能达到效果和效率的最优。
性能
对于base模型,在MMLU、GSM8K和HumanEval评估了其语言理解、数学和代码能力。此外,为了评估其多语言能力,按照Qwen1.5的评测方法在数学、理解、考试和翻译等多个领域的多语言基准测试中进行了测试,并在"Multilingual"列中给出了综合得分。对于chat模型,没有使用传统的基准测试,而是使用MT-Bench进行了测试。
在这个比较分析中,阿里将Qwen1.5-MoE-A2.7B与最好的7B模型,比如Mistral-7B(base模型为v0.1,chat模型为v0.2)、Gemma-7B以及Qwen1.5-7B进行了对比。此外,还将其与具有相似参数数量的MoE模型DeepSeekMoE 16B进行了比较。结果如下表所示:
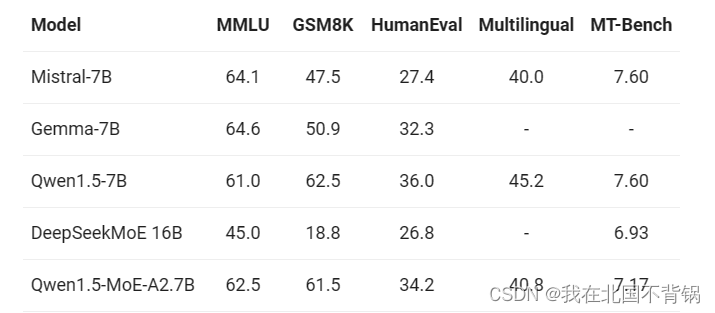
Qwen1.5-MoE-A2.7B在与最佳的7B模型相比取得了非常接近的性能。
使用Qwen1.5-MoE
由于Hugging Face最新版本尚未包含qwen2_moe(代码已合并,等待新版本发布),我们需要从源代码安装transformers,而不是通过pip或conda进行安装:
git clone https://github.com/huggingface/transformers
cd transformers
pip install -e .
接下来的步骤就像使用Qwen1.5、Mistral、Llama等一样简单。如果要使用量化模型,只需将模型名称Qwen1.5-MoE-A2.7B-Chat替换为Qwen1.5-MoE-A2.7B-Chat-GPTQ-Int4(暂时不支持AWQ)。
from transformers import AutoModelForCausalLM, AutoTokenizer
model = AutoModelForCausalLM.from_pretrained(
"Qwen/Qwen1.5-MoE-A2.7B-Chat-GPTQ-Int4",
device_map="auto"
)
tokenizer = AutoTokenizer.from_pretrained("Qwen/Qwen1.5-MoE-A2.7B-Chat")
prompt = "Give me a short introduction to large language model."
messages = [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": prompt}
]
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
model_inputs = tokenizer([text], return_tensors="pt").to(model.device)
generated_ids = model.generate(
model_inputs.input_ids,
max_new_tokens=512
)
generated_ids = [
output_ids[len(input_ids):] for input_ids, output_ids in zip(model_inputs.input_ids, generated_ids)
]
response = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
要使用vLLM模型,需要从源代码安装vLLM:
git clone https://github.com/wenyujin333/vllm.git
cd vllm
git checkout add_qwen_moe
pip install -e .
下面是如何使用vLLM构建一个与模型兼容的OpenAI-API接口:
python -m vllm.entrypoints.openai.api_server --model Qwen/Qwen1.5-MoE-A2.7B-Chat
curl http://localhost:8000/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "Qwen/Qwen1.5-MoE-A2.7B-Chat",
"messages": [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Tell me something about large language models."}
]
}'
后续继续更新对第三方框架的支持,将包括llama.cpp、MLX等。