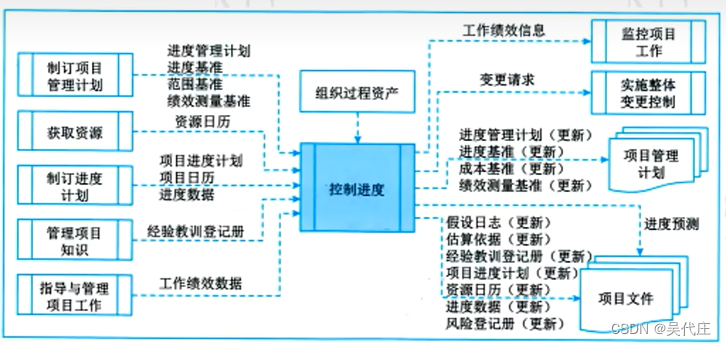
Zookeeper的核心是原子广播,这个机制保证了各个Server之间的同步。实现这个机制的协议叫做Zab协议。Zab协议有两种模式,它们分别是恢复模式(选主)和广播模式(同步)。当服务启动或者在领导者崩溃后,Zab就进入了恢复模式,当领导者被选举出来,且大多数Server完成了和leader的状态同步以后,恢复模式就结束了。状态同步保证了leader和Server具有相同的系统状态。leader选举是保证分布式数据一致性的关键。
出现选举主要是两种场景:初始化、leader不可用。
当zk集群中的一台服务器出现以下两种情况之一时,就会开始leader选举:
1: 服务器初始化启动。
2: 服务器运行期间无法和leader保持连接。
而当一台机器进入leader选举流程时,当前集群也可能处于以下两种状态:
1: 集群中本来就已经存在一个leader。
2: 集群中确实不存在leader。
首先第一种情况,通常是集群中某一台机器启动比较晚,在它启动之前,集群已经正常工作,即已经存在一台leader服务器。当该机器试图去选举leader时,会被告知当前服务器的leader信息,它仅仅需要和leader机器建立连接,并进行状态同步即可。
重点是leader不可用了,此时的选主制度。投票信息中包含两个最基本的信息。
sid : 即server id,用来标识该机器在集群中的机器序号。
zxid : 即zookeeper事务id号。
ZooKeeper状态的每一次改变, 都对应着一个递增的Transaction id,,该id称为zxid.,由于zxid的递增性质, 如果zxid1小于zxid2,,那么zxid1肯定先于zxid2发生。创建任意节点,或者更新任意节点的数据, 或者删除任意节点,都会导致Zookeeper状态发生改变,从而导致zxid的值增加。
以(sid,zxid)的形式来标识一次投票信息。
例如:如果当前服务器要推举sid为1,zxid为8的服务器成为leader,那么投票信息可以表示为(1,8)
集群中的每台机器发出自己的投票后,也会接受来自集群中其他机器的投票。每台机器都会根据一定的规则,来处理收到的其他机器的投票,以此来决定是否需要变更自己的投票。
规则如下 :
1: 初始阶段,都会给自己投票。
2: 当接收到来自其他服务器的投票时,都需要将别人的投票和自己的投票进行pk,规则如下:
优先检查zxid。zxid比较大的服务器优先作为leader。如果zxid相同的话,就比较sid,sid比较大的服务器作为leader。
所有服务启动时候的选举流程:
三台服务器 server1、server2、server3:
- server1 启动,一台机器不会选举。
- server2 启动,server1 和 server2 的状态改为 looking,广播投票
- server3 启动,状态改为 looking,加入广播投票。
- 初识状态,互不认识,大家都认为自己是王者,投票也投自己为 Leader。
- 投票信息说明,票信息本来为五元组,这里为了逻辑清晰,简化下表达。
初识 zxid = 0,sid 是每个节点的名字,这个 sid 在 zoo.cfg 中配置,不会重复。

1: 初始 zxid=0,server1 投票(1,0),server2 投票(2,0),server3 投票(3,0)
2: server1 收到 投票(2,0)时,会先验证投票的合法性,然后自己的票进行 pk,pk 的逻辑是先比较 zxid,server1(zxid=server2(zxid)=0,zxid 相等再比较 sid,server1(sid)<server2(sid),pk 结果为 server2 的投票获胜。server1 更新自己的投票为 (2,0),server1重新投票。
3: TODO 这里最终是 2 还是 3,需要做实验确定。
4: server2 收到 server1 投票,会先验证投票的合法性,然后 pk,自己的票获胜,server 不用更新自己的票,pk 后,重新在发送一次投票。
5: 统计投票,pk 后会统计投票,如果半数以上的节点投出相同的票,确定选出了 Leader。
6: 选举结束,被选中节点的状态由 LOOKING 变成 LEADING,其他参加选举的节点由 LOOKING变成 FOLLOWING。如果有 Observer 节点,如果 Observer 不参与选举,所以选举前后它的状态一直是 OBSERVING,没有变化。
简单地说:
开始投票 ->节点状态变成 LOOKING -> 每个节点选自己-> 收到票进行 PK -> sid 大的获胜 -> 更新选票 -> 再次投票 -> 统计选票,选票过半数选举结果 -> 节点状态更新为自己的角色状态。