数据结构——快速排序的三种方法和非递归实现快速排序(升序)
- 前言
- 快速排序的单趟排序
- hoare法
- 挖坑法
- 前后指针法
- 快速排序的实现
- key基准值的选取
- 快速排序代码
- 快速排序的优化
- 快速排序(非递归)
前言
快速排序是Hoare于1962年提出的一种二叉树结构的交换排序方法,其基本思想为:任取待排序元素序列中
的某元素作为基准值,按照该排序码将待排序集合分割成两子序列,左子序列中所有元素均小于基准值,右
子序列中所有元素均大于基准值,然后最左右子序列重复该过程,直到所有元素都排列在相应位置上为止。
快速排序的单趟排序
hoare法
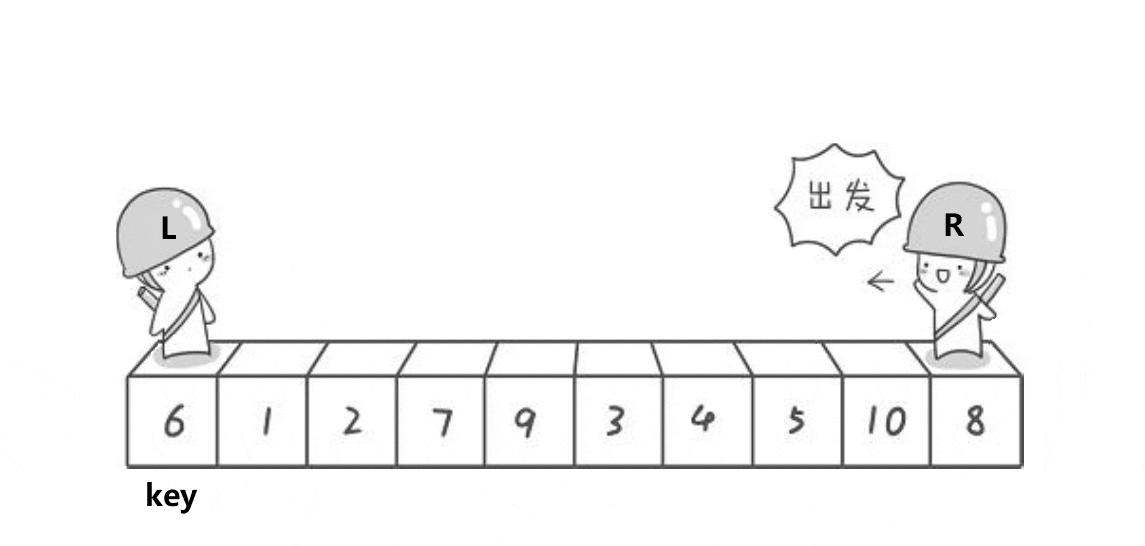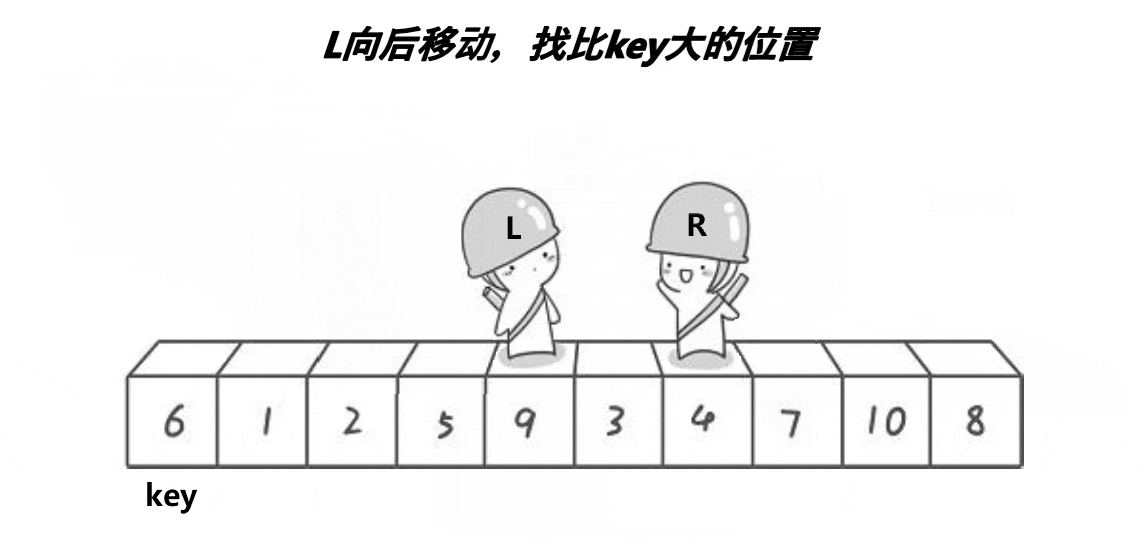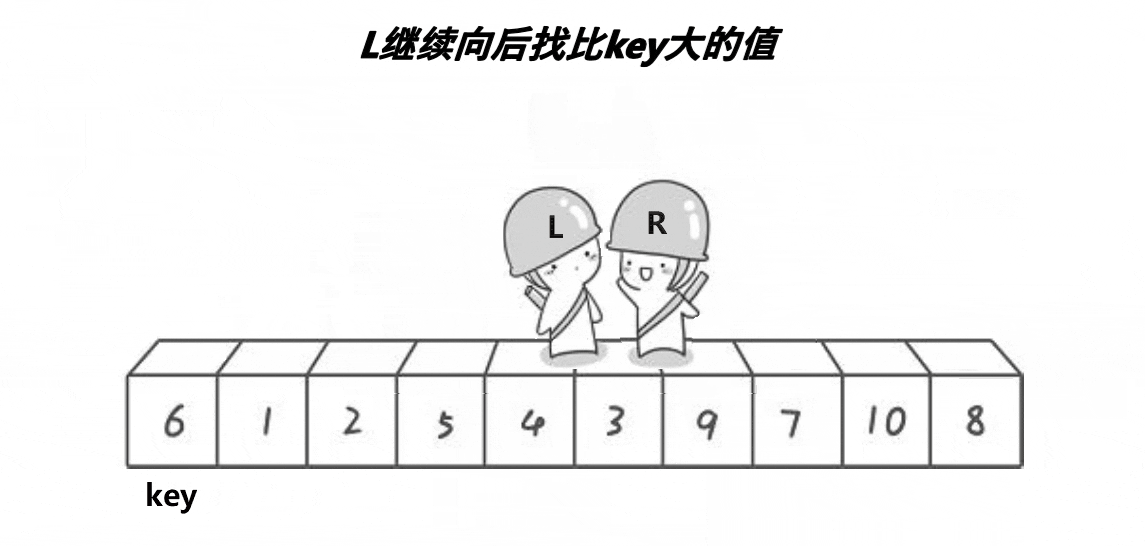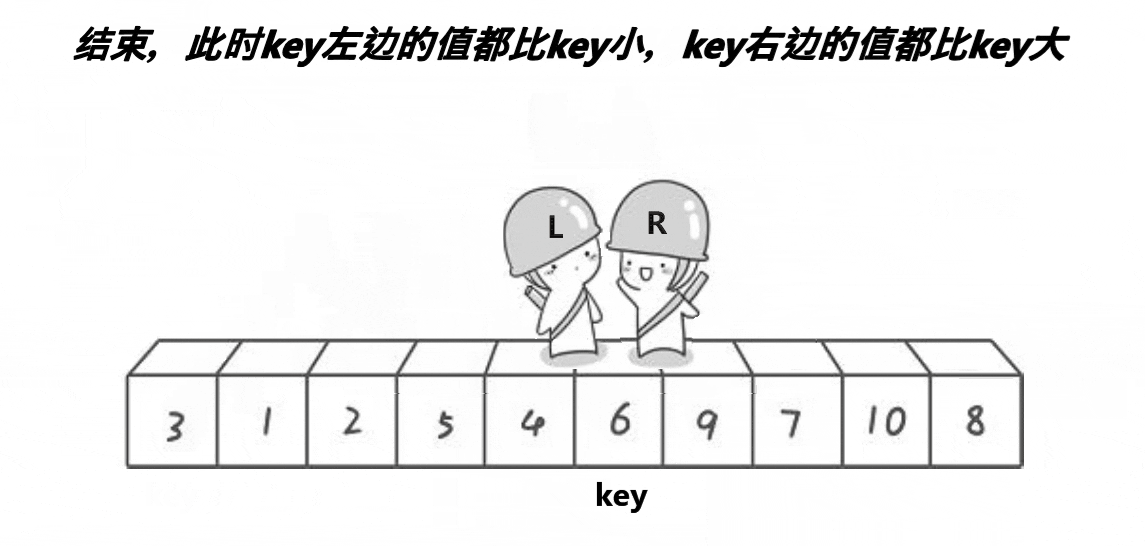
思路:从给定数组中选一个基准值key,然后定义两个下标L和R,分别从数组的两端开始向中间遍历,lL找大,R找小。R找到比key小的数就停下,L找到比key大的数就停下,然后交换两个数的值;接下来继续遍历,直到L和R相遇,按此规律你会发现相遇位置的值一定是小于等于key的,此时交换相遇位置和key的值。最后返回基准值的位置。
详细看下面的动图:
代码:
//单趟排序结束后将key对应得下标keyi返回,方便下一次递归得调用
int PartSort1(int* a, int left, int right)
{
//三数取中选key,这里其实就是在数组中选取了一个较为中间的值作为key然后放在了数组得最左边
//后面会讲为什么
int keyi = GetMidNum(a, left, right);
if (keyi != left)
{
Swap(&a[keyi], &a[left]);
keyi = left;
}
while (left < right)
{
//key在左边右边先走 最后相遇的位置一定是比key小的或者等于key的
//右边找比key小的
while (left < right && a[right] >= a[keyi])//如果为顺序结构right会一直自减到-1,所以加left < right控制以一下
{
right--;
}
//左边找比key大的
while (left < right && a[left] <= a[keyi])
{
left++;
}
Swap(&a[right], &a[left]);//找到后交换
}
Swap(&a[keyi], &a[left]);//此时left为相遇的位置,相遇的位置小于key然后交换key和相遇的位置的值
//此时key的左边都是比key小的 右边都是比key大的
return left;//此时left为keyi的位置
}
挖坑法
思路:选一个基准值放在最左边,然后将将坑也放在最左边,然后将基准值放在临时变量key中形成坑位a[hole],然后从左右两边向中间遍历,右边先遍历,找到比key小的就停下来,将该数据放在坑的位置,形成新的坑位;然后左边遍历,找到比key大的数就停下来,将该数据放在坑的位置,形成新的坑位。最后将坑的位置返回。
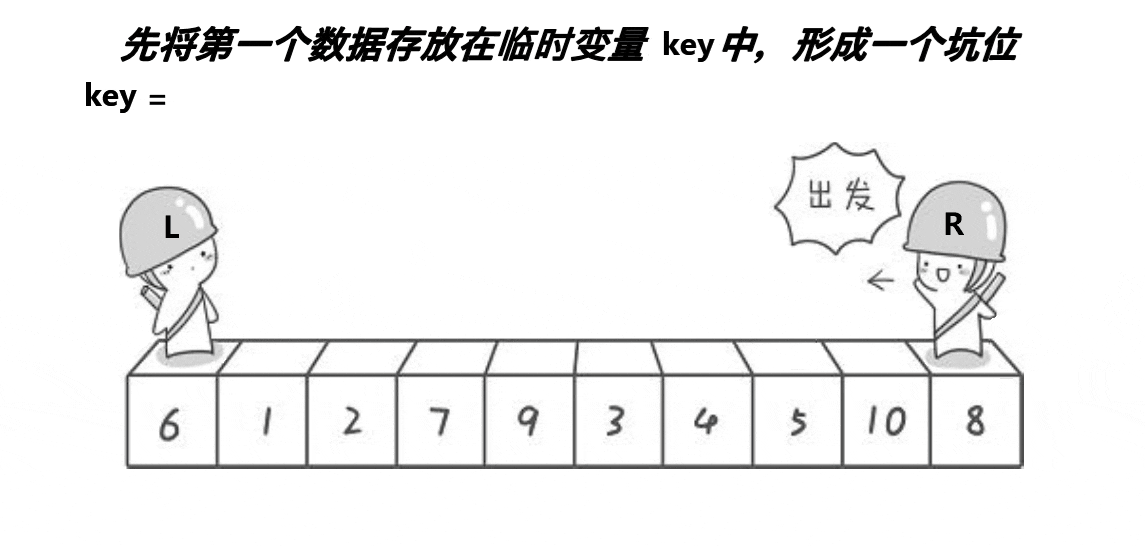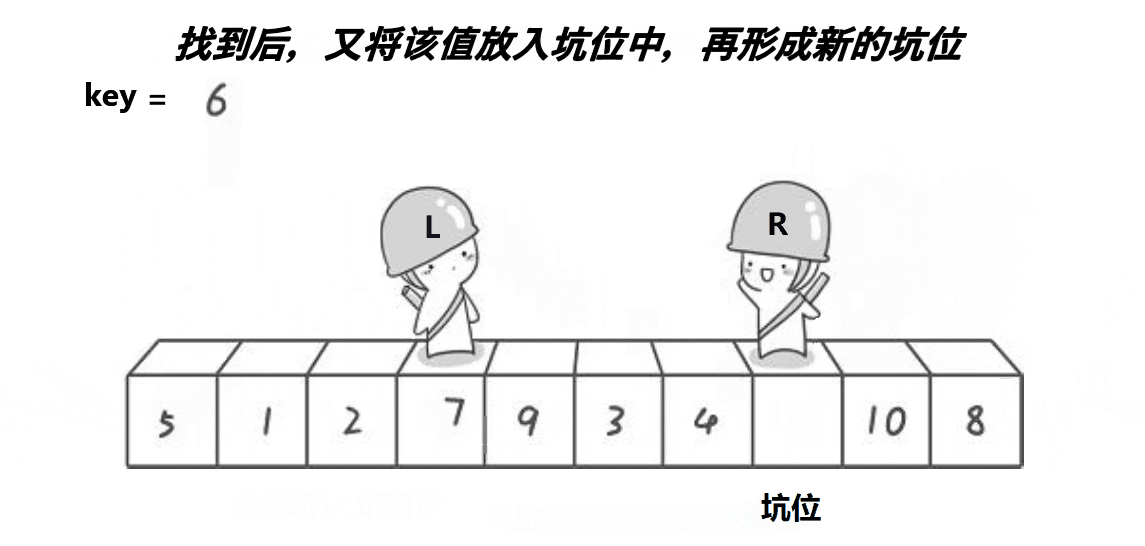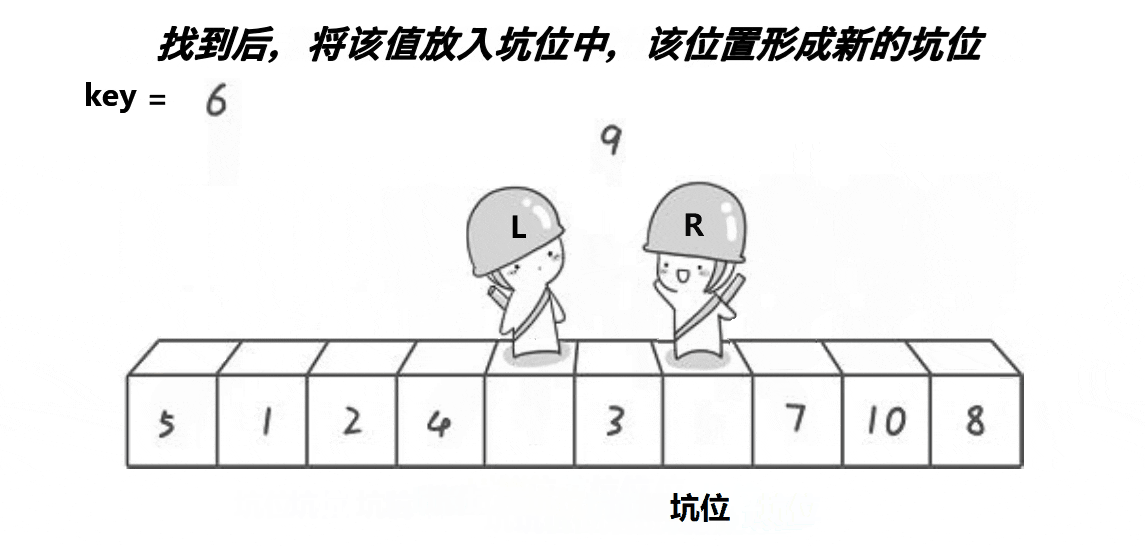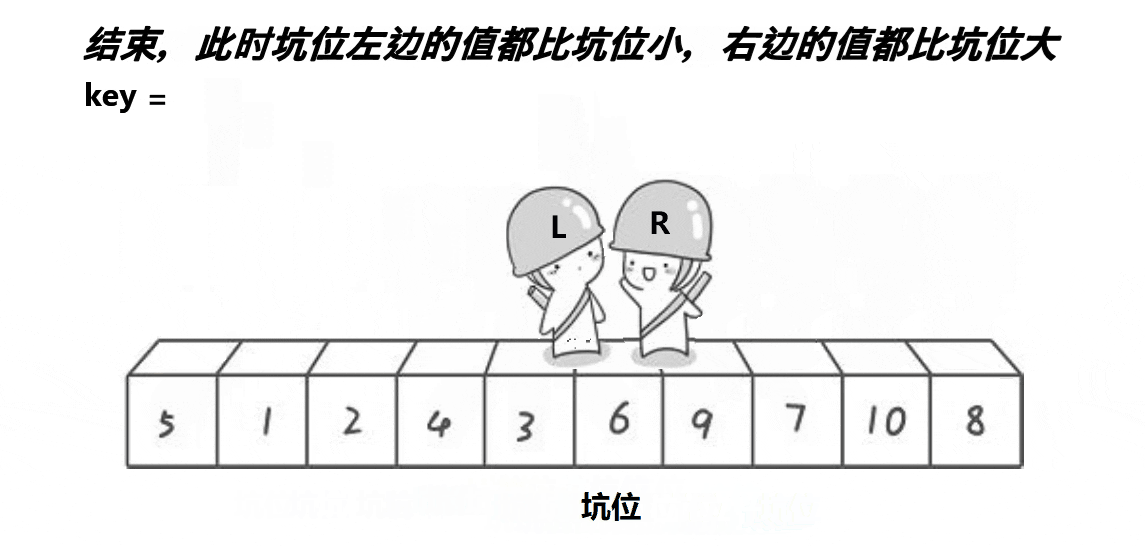
代码实现:
int PartSort2(int* a, int left, int right)//(挖坑法)
{
int keyi = GetMidNum(a, left, right);//三数取中拿到基准值的下标
int key = a[keyi];//将基准值放在key中,形成坑位
//判断基准值是否在左边,若不在放在左边,也就是坑位放在最左边
if (keyi != left)
{
Swap(&a[keyi], &a[left]);//基准值放左边
}
int hole = left;//最初将坑放在左边
while (left < right)
{
while (left<right && a[right] >= key)
{
right--;
}
a[hole] = a[right];
hole = right;//坑的位置移到找到的比key小的那个位置
while (left < right && a[left] <= key)
{
left++;
}
a[hole] = a[left];
hole = left;
}
a[hole] = key;
return hole;
}
前后指针法
思路:从数组中选定一个基准值,放在数组的最左边。定义两个指针prev和cur,prev指向第一个数的位置,cur指向第二个数的位置,然后cur开始向后遍历,如果cur所指向的位置小于key那么,prev和cur同时++(自增1),也就是prev和cur同时向后遍历;如果cur所指向的位置大于key的话,cur向后遍历,prev不遍历,直到cur找到比key小的数,然后向后遍历一位,再交换此时cur和prev所指向位置的数,也就是保证prev在遍历的时候,遍历过的位置都是比key小的数,所以遍历结束后prev所指向的位置以及prev遍历过的位置(prev的左边)都是比key小的值,接下来交换key和prev所指向的数即可,并返回交换后key的下标。动图:
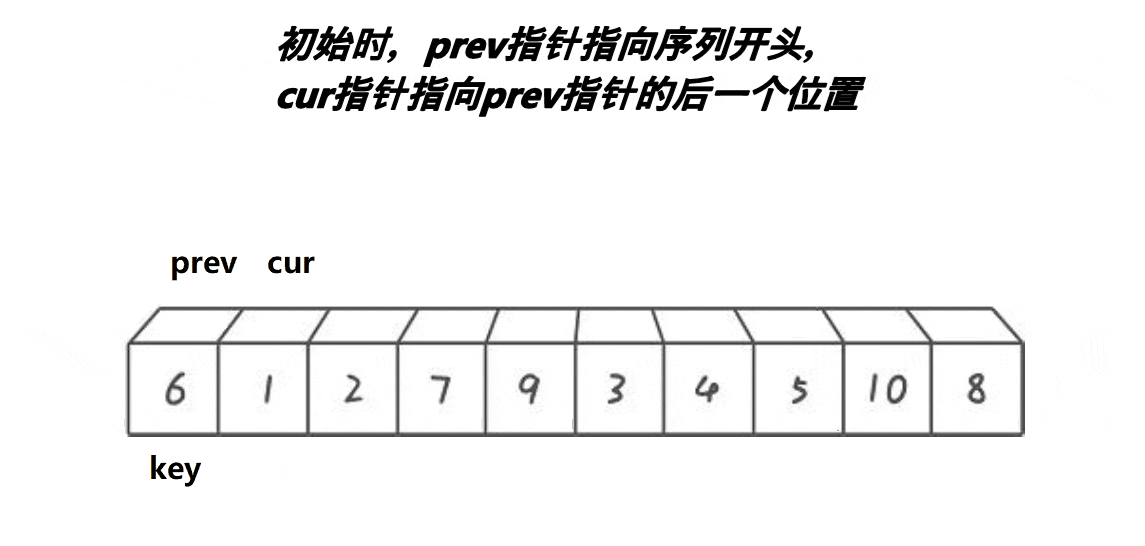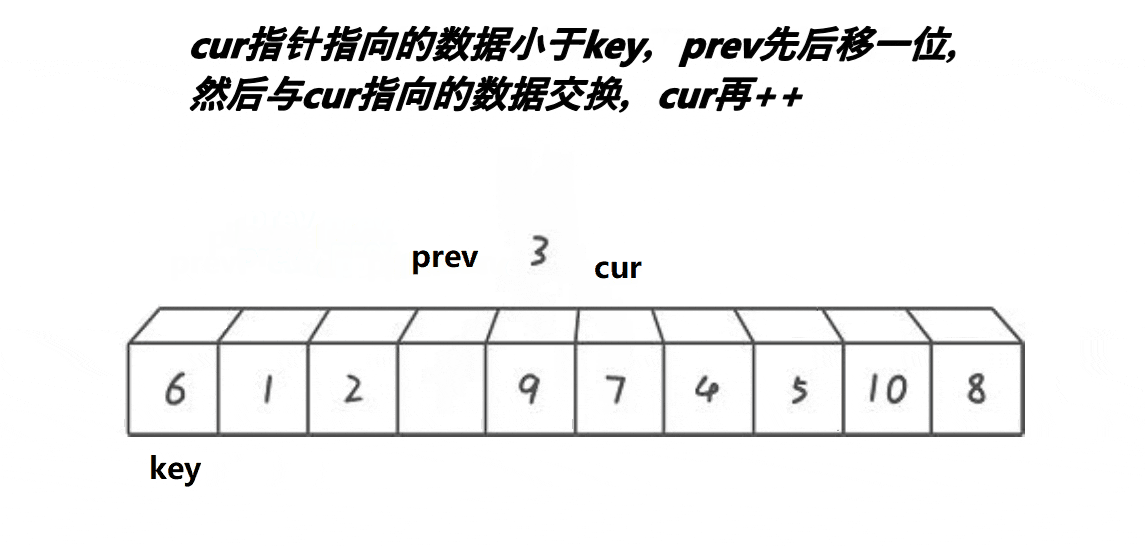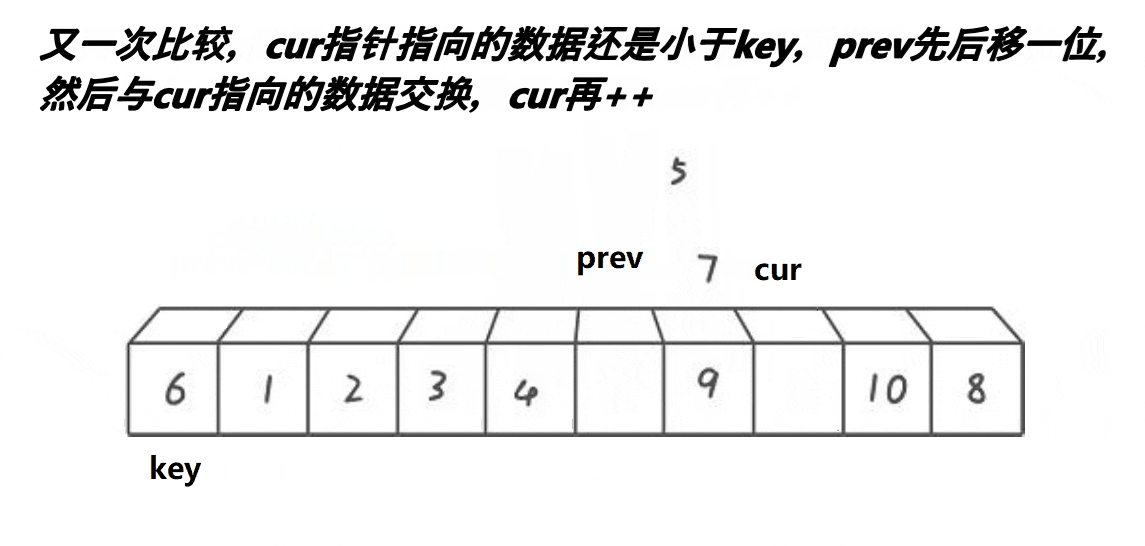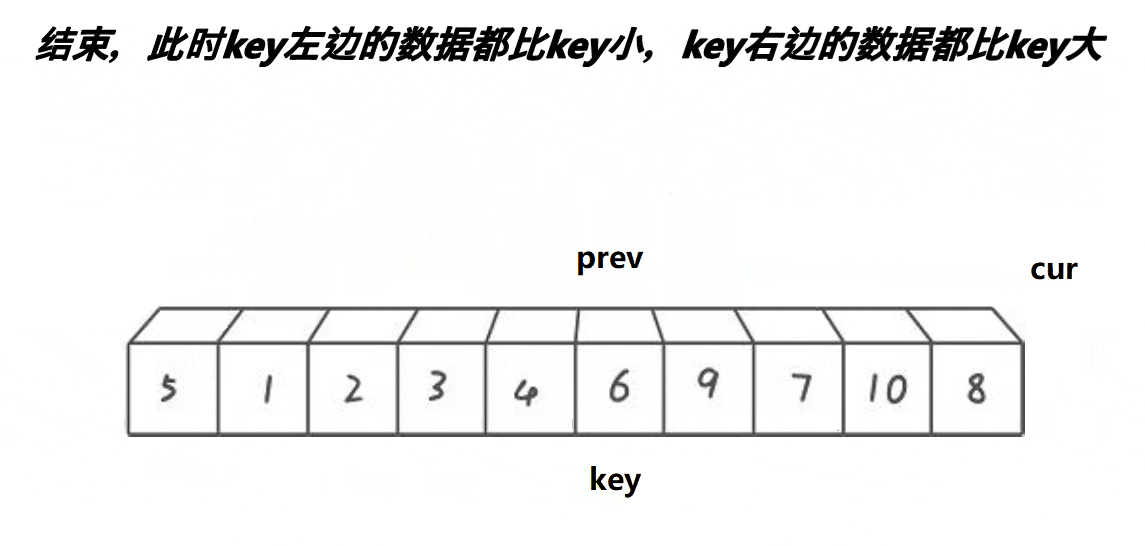
代码实现:
int PartSort3(int* a, int left, int right)//(前后指针法 下标法)
{
int keyi = GetMidNum(a, left, right);
if (keyi != left)
{
Swap(&a[keyi], &a[left]);
keyi = left;
}
int prev = left;
int cur = prev + 1;
while (cur <= right)
{
if (a[cur] < a[keyi] && ++prev != cur)//cur找到比a[keyi]小的值的时候,prev++,若prev和cur在同一位置那么就不需要交换
{
Swap(&a[cur], &a[prev]);//上面判断条件中prev++过了
}
cur++;//两中情况cur都需要++
}
Swap(&a[prev], &a[keyi]);//key和prev的值交换
return prev;
}
快速排序的实现
函数形参分别为待排序数组a,待排序数组的最左边数的下标left,待排序数组的最右边数的下标right。
void QuickSort(int* a, int left, int right);
不管是哪种方法都是用递归来实现的,就用hoare法来举例分析吧。
第一趟排序完后,key的左边全为比key小的数,右边全为比key大的数。接下来把数组分为key左(即下标区间为[left,key-1]的数组)和key右(下标区间为[key+1,right]的数组)两组分别进行单趟排序,然后不断递归,当递归到数组中只有一个值的时候,也就是left>=right的时候,这时候直接返回即可。
d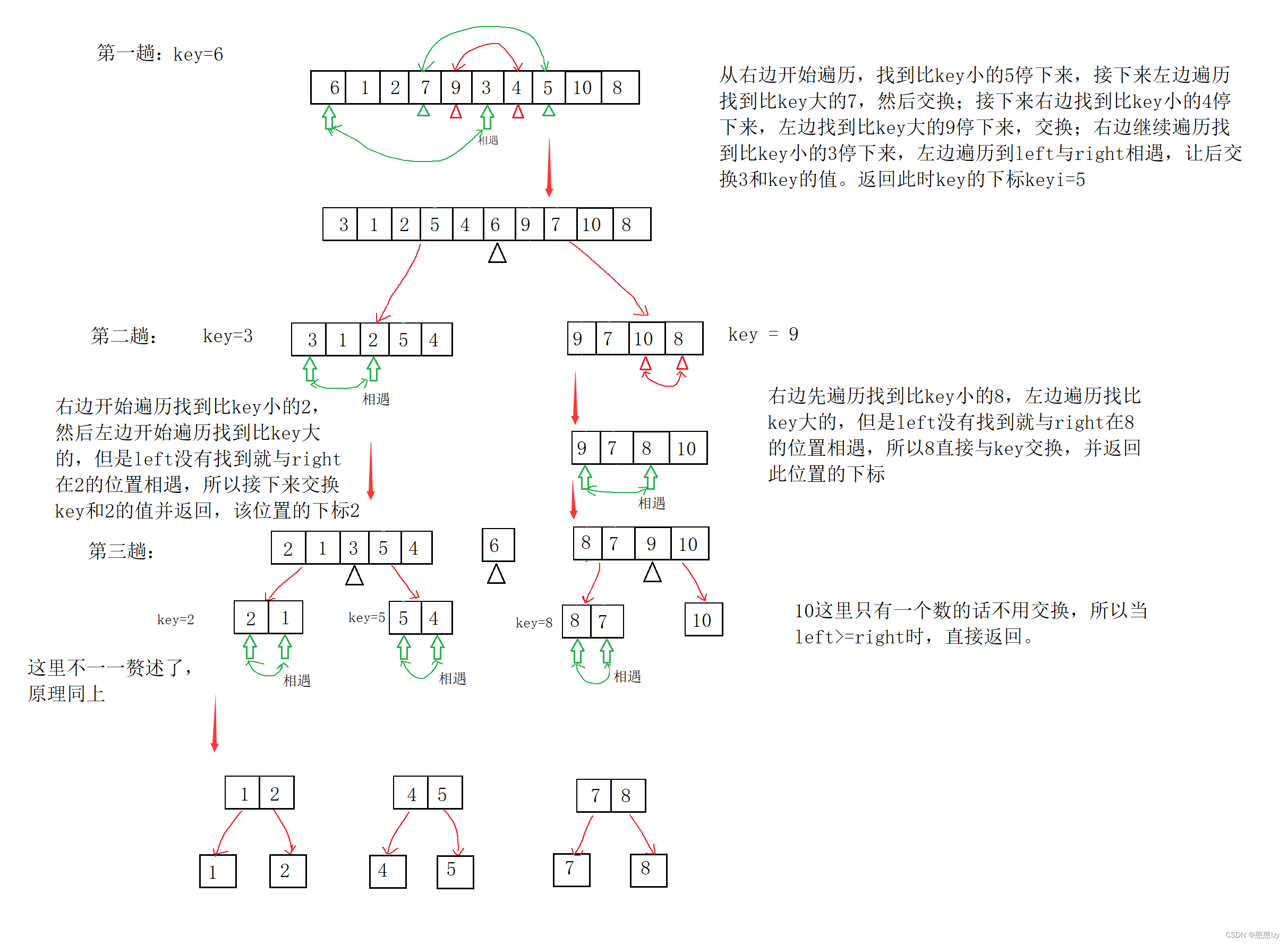
key基准值的选取
一般我们会取最左边的数为基准值,这样容易理解但是,这样有时候会使递归深度很大,所以我们会选取较为中间的数来当基准值,用三数取中法来解决该问题。
递归深度对比图:
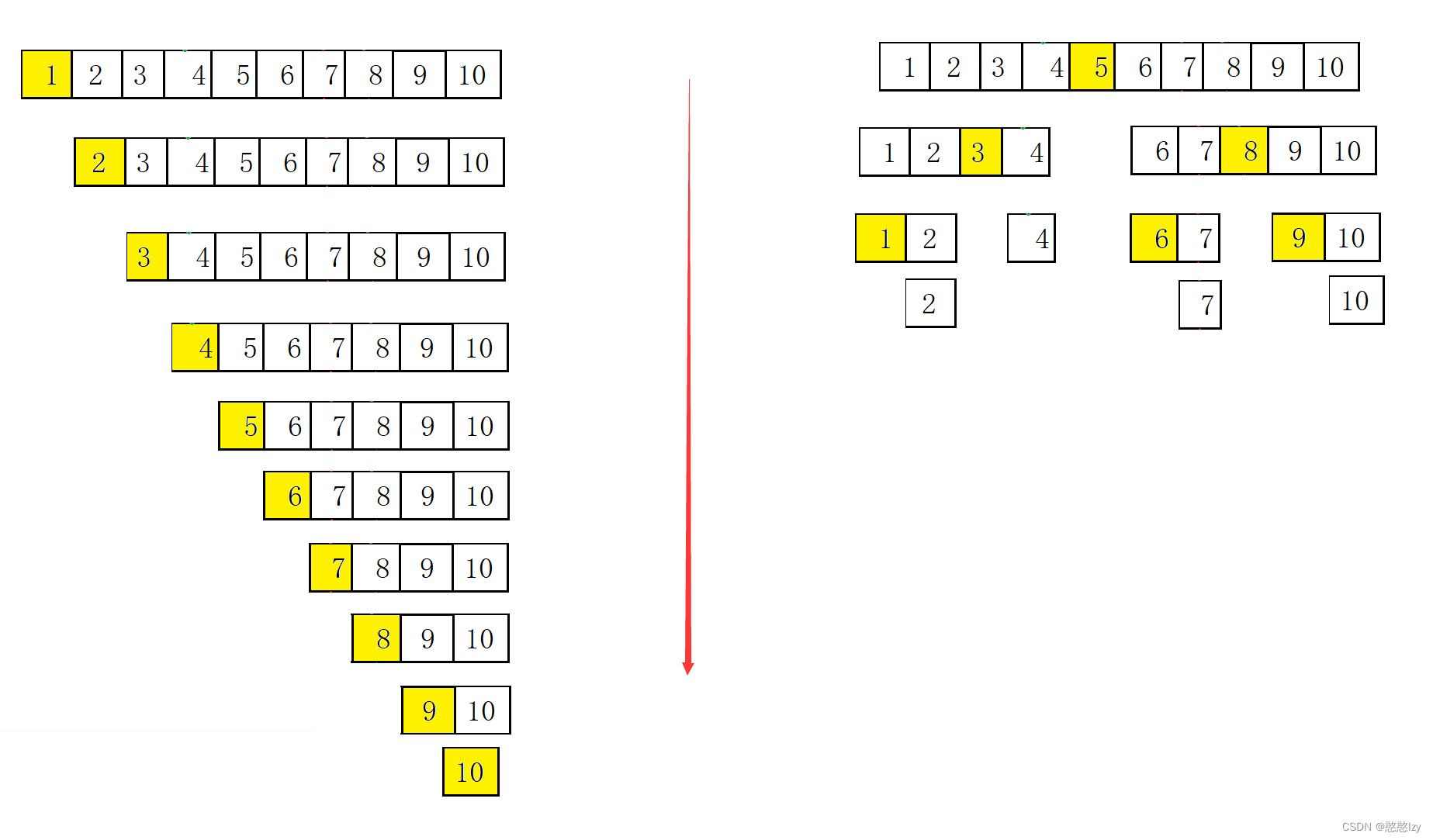
三数取中法:选取数组最左边最右边和中间这三个数,然后返回三数中间大小的下标。
代码实现:
int GetMidNum(int* a, int left, int right)//三个数取中间值 返回中间值的下标
{
int midi = (left + right) / 2;
if (a[left] < a[midi])
{
if (a[midi] < a[right])
{
return midi;//a[left[<a[midi]<a[right]
}
else if (a[right] < a[left])
{
return left;//a[right]<a[left]<a[midi]
}
else//a[right]>=a[left] && a[right]<=a[midi]
{
return right;//a[left]<a[right]<a[midi]
}
}
else// a[left] >= a[midi]
{
if (a[midi] > a[right])
{
return midi;//a[left[<a[midi]<a[right]
}
else if (a[right] > a[left])
{
return left;//a[right]<a[left]<a[midi]
}
else//a[right]>=a[left] && a[right]<=a[midi]
{
return right;//a[left]<a[right]<a[midi]
}
}
}
快速排序代码
void QuickSort(int* a, int left, int right)//快速排序
{
if (left >= right)
return ;
int begin = left;
int end = right;
//int keyi = PartSort1(a, begin, end);//hoare法
//int keyi = PartSort2(a, begin, end);//挖坑法
int keyi = PartSort3(a, begin, end);//前后指针法
QuickSort(a, begin, keyi - 1);
QuickSort(a, keyi + 1, end);
}
快速排序的优化
当快排递归到待排数组是一些短数组的时候,由于短数组的个数很多,再加上这些短数组都需要递归到数组中只有一个数的情况才可以返回,这时候会不断的创建函数栈帧,然后导致时间复杂度降低。因为这些待排的短数组都是一个接近于有序的的数组,用直接插入来优化更为合适。
代码实现:
void QuickSort(int* a, int left, int right)//快速排序
{
if (left >= right)
return ;
int begin = left;
int end = right;
if (end - begin + 1 < 10)
{
InsertSort(a, end - begin + 1);
return;
}
//int keyi = PartSort1(a, begin, end);//hoare法
int keyi = PartSort2(a, begin, end);//挖坑法
//int keyi = PartSort3(a, begin, end);//前后指针法
QuickSort(a, begin, keyi - 1);
QuickSort(a, keyi + 1, end);
快速排序(非递归)
任何一个递归程序在执行的时候,都是操作系统底层开辟了一个栈,每执行一个函数调用,那么就将当前函数的栈帧压栈,如果当前函数内部存在递归调用,那么就继续压入新的该函数代表的栈帧,直到某个函数内部没有再进行递归调用,该函数计算完毕后,将其出栈,并将计算结果返回给下一层栈帧。所以我们可以尝试着自己手搓一个栈,来实现函数的非递归调用。
要点1:我们要明白函数栈桢中存放的是什么,存放的是数组区间
要点2:数组区间只有一个值或者不存在值得时候不入栈
思路:首先将数组得左右下标压入栈中,这里注意顺序,栈得性质得后入先出,所以先将right压入栈中,在将left压入栈中,接下来相当于创建了函数栈桢,然后开始调用函数,因为递归函数中是不断得调用同一个函数,但是函数栈桢中得数组区间不同,所以接下来要通过循环来反复调用单趟排序,并且在循环中重复定义数组区间得值,调用完单趟排序后将子区间压栈,要判断一下数组区间至少有两个元素。
代码实现:
void QuickSortNonR(int* a, int left, int right)//非递归
{
ST st;
STInit(&st);//初始化
STPush(&st, right);//先插入right,栈是后入先出
STPush(&st, left);
while (!STEmpty(&st))
{
//每次循环重置数组区间
int begin = STTop(&st);
STPop(&st);
int end = STTop(&st);
STPop(&st);
int keyi = PartSort3(a, begin, end);
//先排序后半部分,栈是后入先出
if (keyi + 1 < end)//数组区间有一个数或者没有数不压栈
{
//排序完该区间后将子区间压入栈当中去
STPush(&st, end);
STPush(&st, keyi+1);
}
if (begin < keyi - 1)
{
STPush(&st, keyi-1);
STPush(&st, begin);
}
}
STDestory(&st);
}
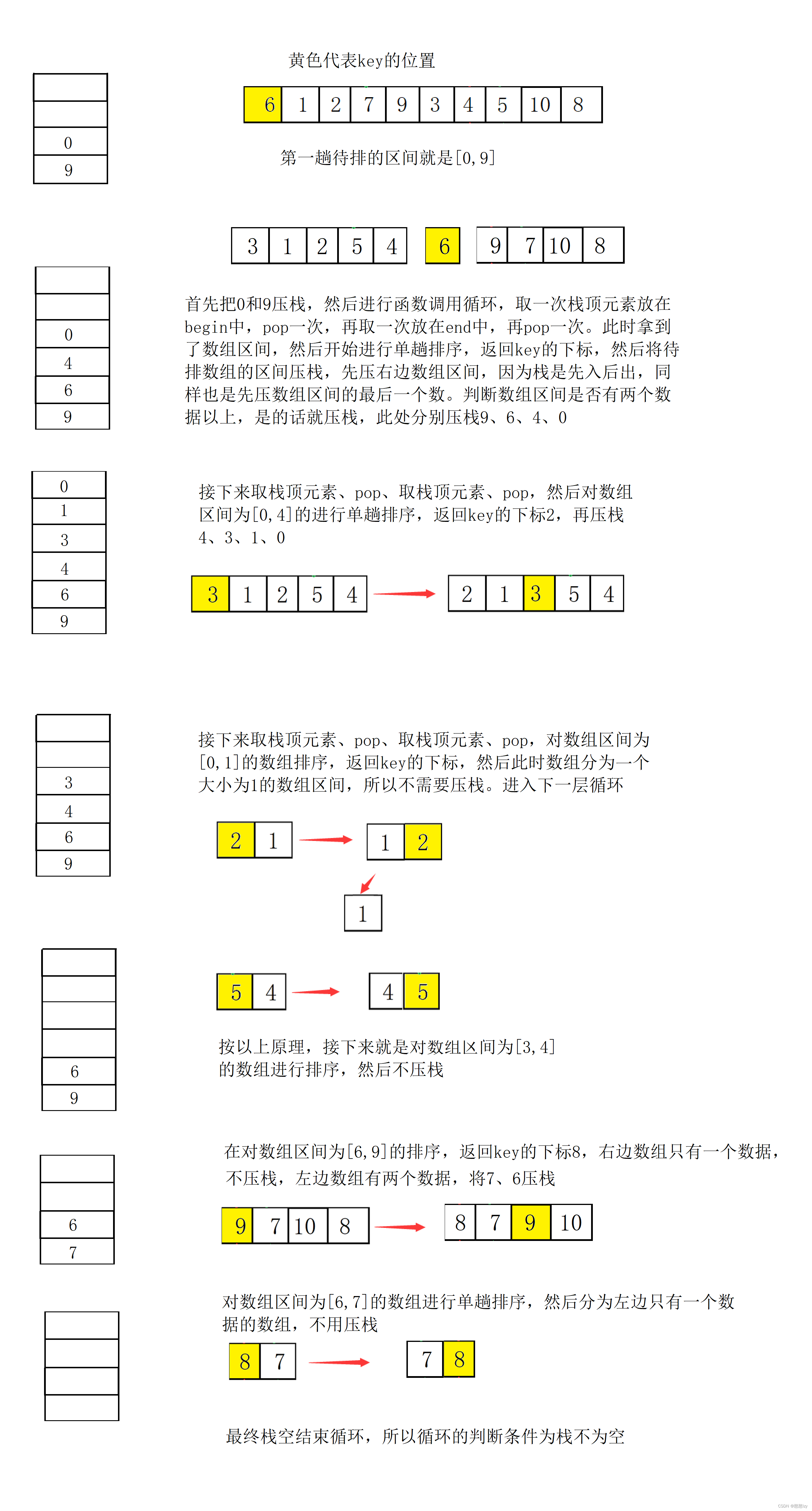
大致图解:
这里没有考虑到三数取中选key,选取最左边的数为基准值进行的单趟排序