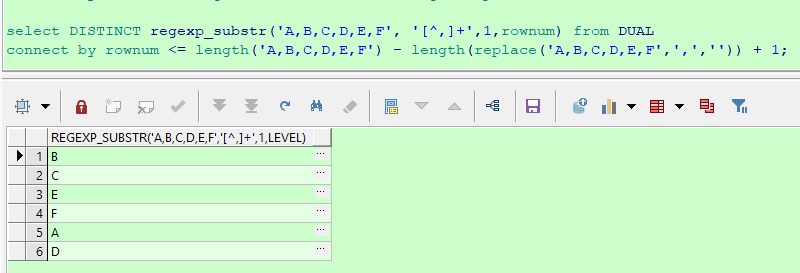
二、生成式人工智能
前面介绍了很多人工智能的应用,接下来部分我们会介绍当前正在进行的生成智能。生成智能和以往的人工智能有什么区别,个人觉得主要区别就在于“度”。在表现上就是以前的人工智能更多是利用既有的数据集分布挖掘和解决在这个数据集下的问题,泛化性比较弱;而生成智能在于抽象力达到一个程度后可以解决很多数据集中本不具备的能力。

(一) 从象征思维说起
象征思维是一种人类认知活动的方式,它是通过符号、形象或概念的表征,来表达和传达某种意义的过程。这种思维方式就像盲人的手指触摸,虽然不能直接看到实物,但是可以通过触摸感知到物体的形状、纹理、重量等特性。
对于盲人来说,他们无法看见色彩、形状等视觉元素,但他们可以理解和感受到音乐的韵律、旋律,甚至能够根据音色分辨出不同的乐器。这就是象征思维的一种表现形式。比如,音乐中的每一个音符就像是一个符号,它们组合在一起就能创造出各种各样的旋律,这些旋律可以表达出快乐、悲伤、激动等各种情绪,这就像是盲人通过听觉去理解和感受世界。
所以,象征思维就是通过对事物进行抽象化的表示,以传达更深层次的意义和含义。它是我们理解世界、沟通交流的重要工具。
象征思维是一种通过象征、符号或隐喻来表示概念、事物或现象的思维方式。在这种思维方式中,我们使用一些具体的符号或事物来代表抽象的概念或思想,以便更好地理解和传达。
生成人工智能(AI),特别是生成智能,是一种能够自主创造内容的人工智能形式。它能够理解和应用象征思维的原则,通过分析大量数据来学习概念、模式和关系。然后,它使用这些信息来生成新的、独特的输出,比如文本、图像或音乐。这就像一个盲人音乐家,他通过触觉和听觉来理解音乐的结构和情感,然后创作出自己的作品。
生成智能的泛化性是指它的能力,不仅能在特定任务上表现出色,还能将所学应用到新的、未见过的情境中。这正如一个人通过触摸和听觉来学习世界,然后能够将这些知识应用到新的环境和情境中,创造出新的理解和解决方案。生成智能通过分析大量不同的数据和情境,学习通用的模式和原则,然后能够在面对新的挑战时灵活应对。
所以如果要让生成人工智能具备泛化生成能力,就需要让人工智能具备抽象能力。那么该如何让人工智能具备抽象能力呢,最直观想到的方法就是对数据压缩(这个在数学上有些理论证明)。
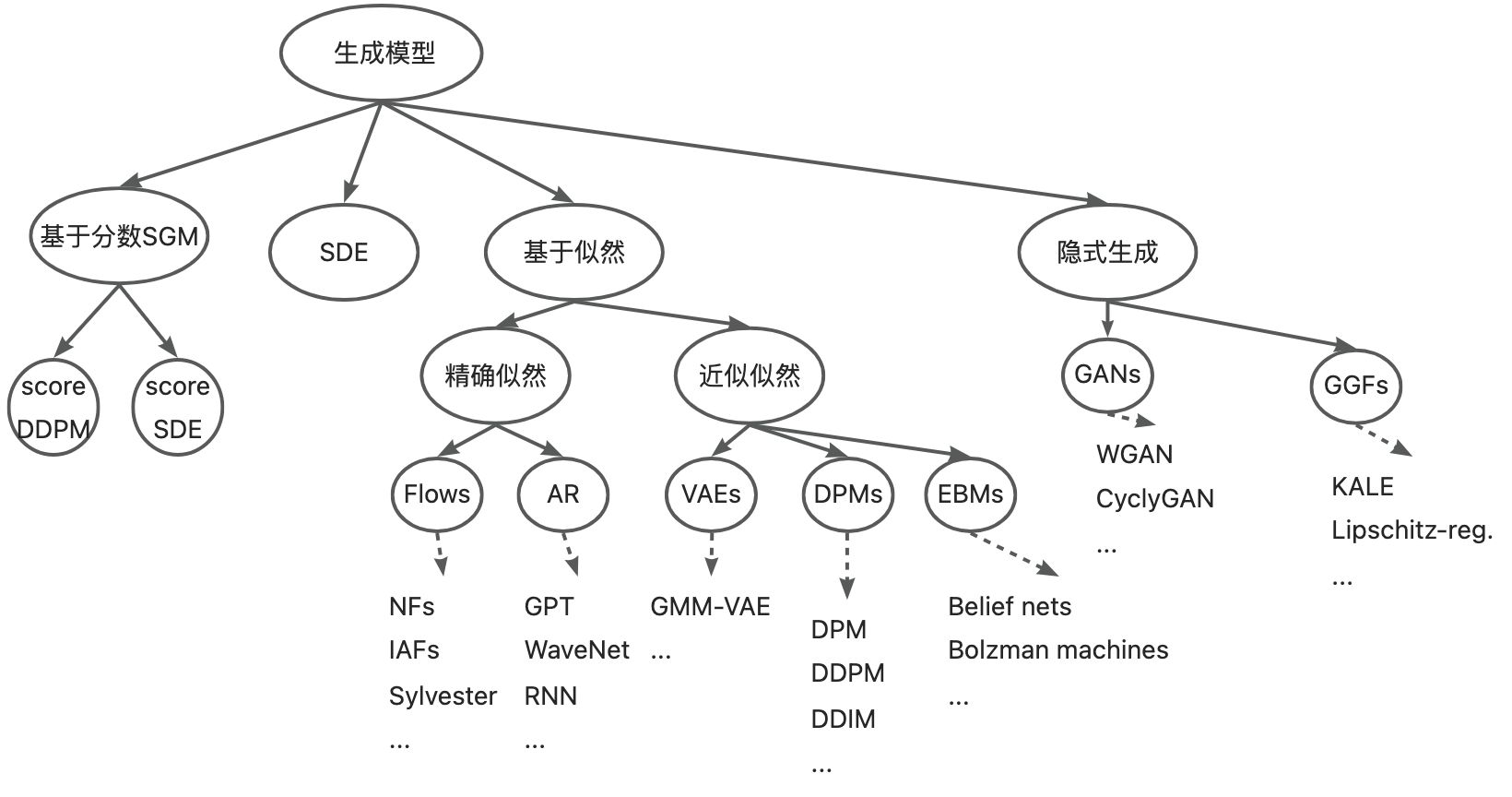
(二) 生成智能常用算法
生成式模型是机器学习和人工智能领域的一项重要技术,它允许模型通过学习数据分布,生成新的数据样本。与基于判别的模型不同,生成式模型的目标是模拟数据的生成过程,以创造真实可信的新数据。 生成式模型在各种应用中都很重要,从图像和视频合成到文本生成再到音乐创作等。它们允许系统不仅能够理解数据,而且能够创造和想象新的内容。
生成式模型是一类机器学习模型,旨在学习数据的概率分布,以便能够生成与训练数据相似的新样本。它们通过估计数据的联合概率分布或条件概率分布来实现这一目标。生成式模型在各种任务中都有广泛的应用,包括图像生成、语音合成、自然语言处理等。
生成式模型可以分为对分布建模和对过程建模两种类型。对分布建模的生成式模型直接学习数据的概率分布,例如朴素贝叶斯、混合高斯模型、隐马尔科夫模型等。这些模型通过最大化数据的似然函数来学习参数,从而能够生成服从相同分布的新样本。
对过程建模的生成式模型则通过学习数据生成的过程来建模。这些模型包括受限玻尔兹曼机、深度信念网络、生成对抗网络(GAN)、变分自编码器(VAE)等。它们通过优化生成器网络的参数,使得生成的样本与真实数据尽可能接近。
生成式模型具有许多优点。首先,它们能够生成具有多样性和真实感的样本,这在许多应用中都是非常有用的。其次,生成式模型可以通过潜在空间的操作来实现对生成样本的控制,例如通过调整潜在变量的值来生成特定风格的图像或文本。此外,生成式模型还可以用于数据增强、异常检测、缺失值填充等任务。
然而,生成式模型也存在一些挑战和限制。首先,训练生成式模型通常需要大量的计算资源和时间。其次,生成式模型可能存在模式崩溃的问题,即在训练过程中只学习到数据分布的一小部分,导致生成的样本缺乏多样性。此外,评估生成式模型的性能也是一个具有挑战性的问题,因为很难直接比较不同模型生成的样本的质量。
1. GPT系列(Generative Pre-Training)
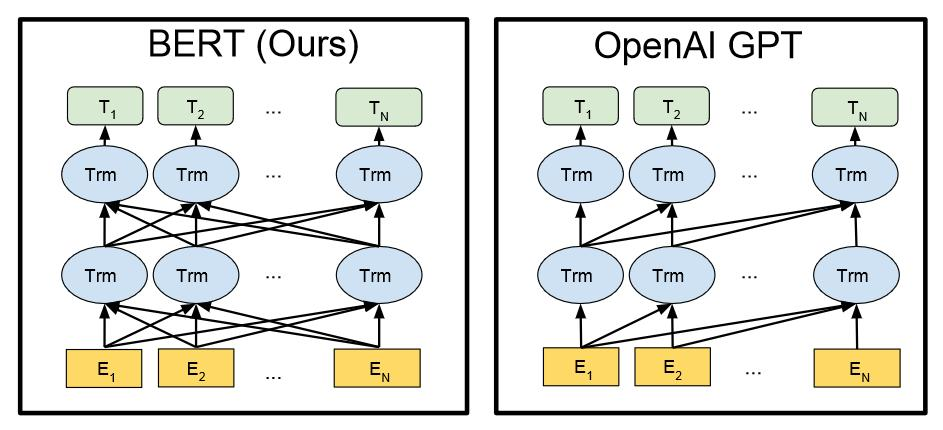
Ge生成式预训练变换器(GPT)系列是由 OpenAI 提出的预训练语言模型,这一系列的模型可以执行非常复杂的 NLP 任务,例如回答问题、生成文章和代码,或者翻译文章内容等。
GPT 采用 Transformer 作为解码器(decoder),Transformer 由 Google Brain 所推出,主要是处理自然语言的顺序输入数据,用于翻译、文本摘要等任务上,而在这里,编码器的意义是通过输入逐一生成出结果,所以才叫做生成式预训练。
当然,这样的模型无法通过一个简单的模型就能够处理完成,模型的训练需要超大的训练语料库、超多的模型参数以及超强的计算资源才能够处理完成,而 GPT 主要是通过大规模的语料库做语言模型的预训练(不需给标签的无监督学习),再通过微调(监督式学习)做迁移学习。

- 分类任务:将起始和终止token加入到原始序列两端,输入transformer中得到特征向量,最后经过一个全连接得到预测的概率分布;
- 自然语言推理:将前提(premise)和假设(hypothesis)通过分隔符(Delimiter)隔开,两端加上起始和终止token。再依次通过transformer和全连接得到预测结果;
- 语义相似度:输入的两个句子,正向和反向各拼接一次,然后分别输入给transformer,得到的特征向量拼接后再送给全连接得到预测结果;
- 问答和常识推理:将 n个选项的问题抽象化为 n个二分类问题,即每个选项分别和内容进行拼接,然后各送入transformer和全连接中,最后选择置信度最高的作为预测结果。
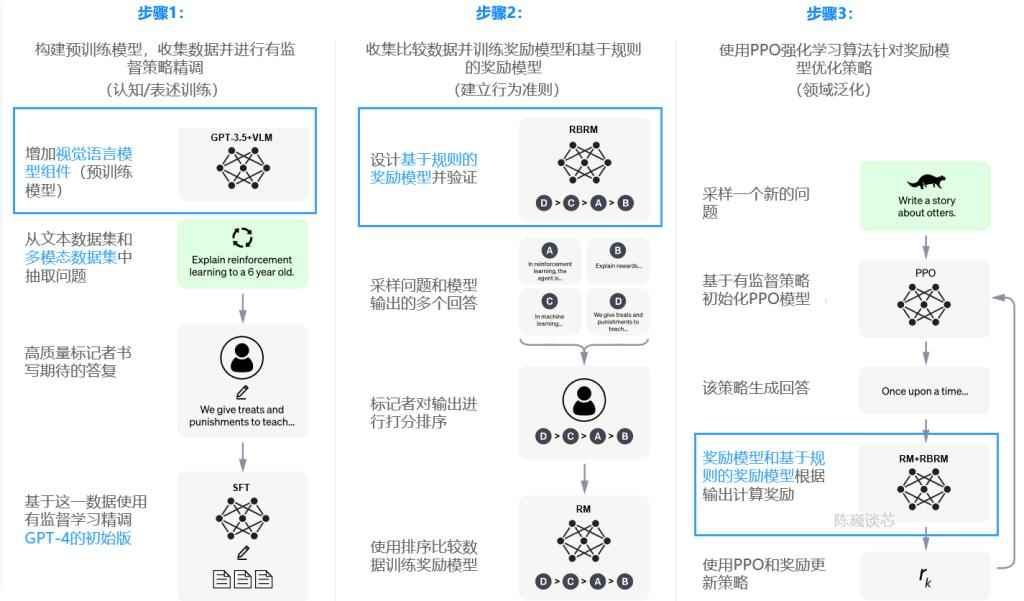
步骤 1。从提示数据集中对提示进行采样,然后人工(或模型)为该采样的提示编写答案。在推广和答案准备就绪后,它将被发送到带有监督学习 (SFT) 的微调 GPT-3。这里的挑战是,让人类为提示准备答案是昂贵的。使用此模型,它可以学习如何根据 SFT 生成答案。
第2步。当给出一个促销时,它首先使用 GPT-3 为给定的促销生成几个答案。例如,如果生成了 4 个答案,则它们将被标记为 A、B、C、D。然后人类只需要对答案进行排名(例如,A>B>C=D)。这样,人类不需要写答案,而只需要对模型生成的答案进行排名。利用这些比较数据,InstructGPT 训练一个奖励模型来比较 4 <prompt, answer>,以便可以在奖励模型 (RM) 中建立排名关系。使用此模型,它可用于比较生成的答案并计算奖励。
第 3 步。现在,他们可以使用 RM 来指导 SFT 模型产生更好的结果,从而获得更高的 RM 奖励。InstructGPT 使用 RM 的输出作为标量奖励,并微调监督策略以优化此奖励。经过训练的模型称为 InstructGPT。
因此,有 3 个数据集:1) SFT 数据集(13k 提示)用于训练 SFT 模型;2)RM数据集(33k提示),带有模型输出的标记器排名,用于训练RM模型;3)PPO数据集(31k提示),没有人类标签作为RLHF微调的输入。
2. Diffusion系列
“一滴蓝色墨水在水容器中扩散。起初,它在一个地方形成一个黑色的斑点。此时,如果您想计算在容器的某个小体积中找到墨水分子的概率,则需要一个概率分布来清晰地模拟墨水开始扩散之前的初始状态。但这种分布很复杂,因此很难采样。
然而,最终墨水扩散到整个水中,使其呈现淡蓝色。这导致分子的概率分布更加简单、更加均匀,可以用简单的数学表达式来描述。非平衡热力学描述了扩散过程中每一步的概率分布。至关重要的是,每个步骤都是可逆的——通过足够小的步骤,您可以从简单的分布回到复杂的分布。”
————墨水扩散物理模型
生成问题抽象成扩散模型
1.生成图是一个复杂概率分布,很难用精确函数表示
2.通过多步加噪来模拟扩散过程,每一步条件概率可以用简单函数表示
3.扩散到稳态,图像像素分布符合高斯分布
4.逆扩散过程,把高斯噪声变成图片


正向扩散:
正向扩散过程通常从一个低分辨率的噪音图像开始,它就像是一个随机像素图案。在每个迭代步骤中,模型都添加一个随机噪音样本,该样本就像一小笔笔触,为图像添加细节。然后,模型使用一个前馈神经网络或类似架构对这些笔触进行处理,以将图像映射到下一个迭代步骤。
在每个迭代步骤中,正向扩散模型都旨在捕获真实世界的某些方面。例如,如果模型被训练用于合成图像,那么它就会学习在迭代过程中添加物体、纹理和细节。它会根据输入的噪音样本,逐步构建一个有意义的图像。正如在雾中逐渐出现清晰图案一样,这个过程会慢慢地塑造图像,直到它达到所需的细节和复杂性水平。
正向扩散可以视为一个逐步精炼的过程,从随机性到有序性。它利用噪音作为创造力和探索性的来源,并通过深度学习模型的指导来添加有意义的细节,从而创造出令人信服的内容。

逆向扩散:
逆向扩散过程与正向扩散恰好相反。它从一个高分辨率、有意义的图像开始,例如真实的世界风景照。目标是通过删除图像信息来重建噪音图像。与正向扩散一样,逆向扩散也采用迭代方法。在每个步骤中,模型都删除一些细节和纹理,从而使图像变得更加抽象和模糊。
逆向扩散被训练用于从复杂图像中提取关键特征。它可以看作是将有意义的图像简化为其基本成分的过程。通过有选择地消除细节,模型学习识别和保留最重要的元素,从而引导图像逐渐接近噪音图像。
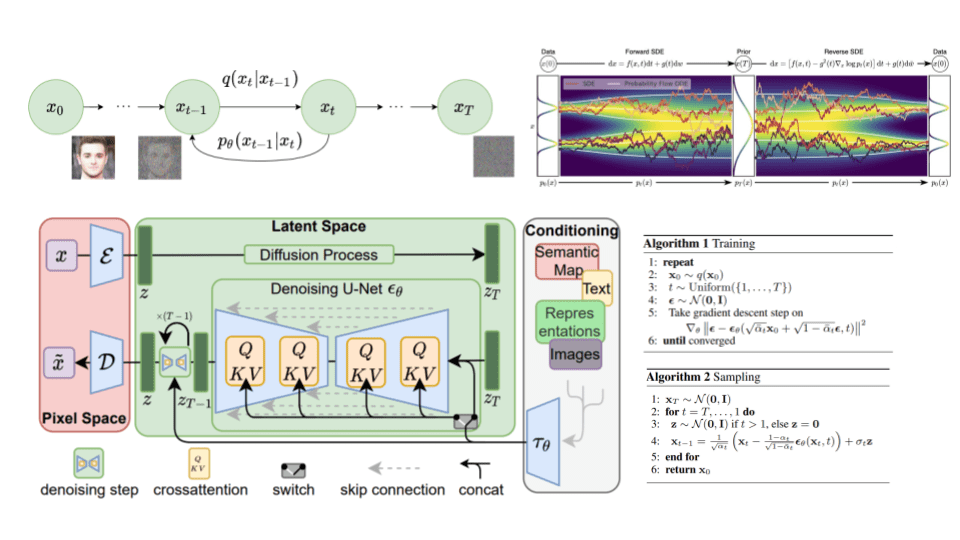

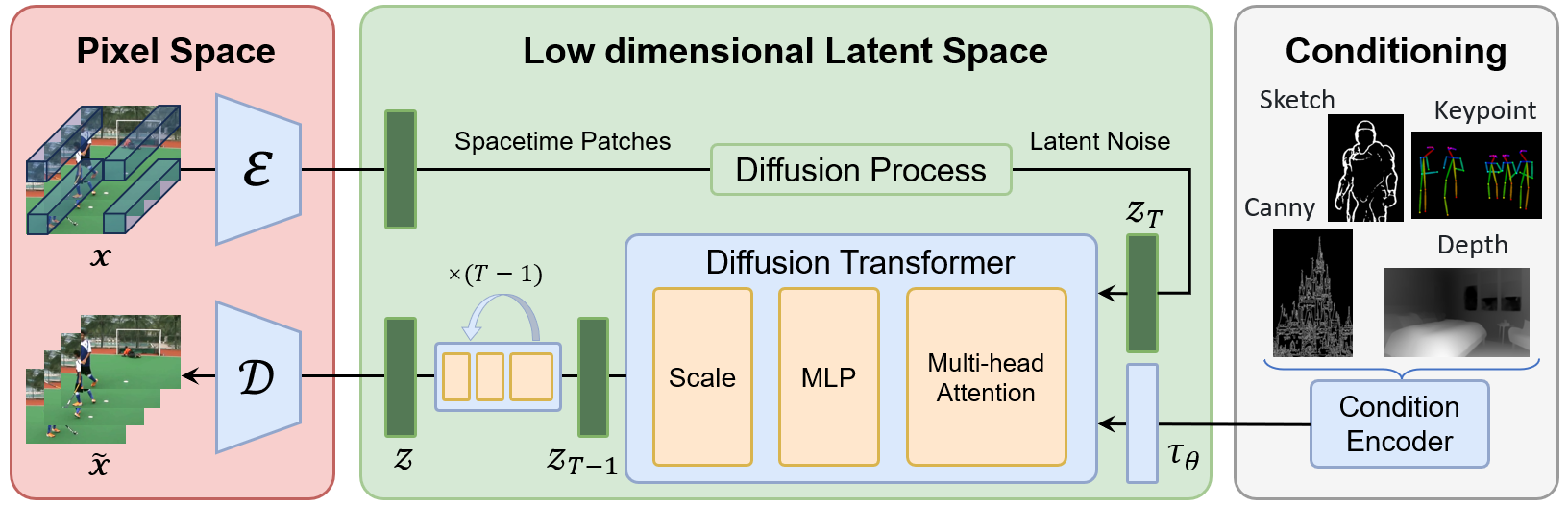
图像通过编码器(Encoder)变成一个潜在向量(Latent Vector),然后通过一个扩散过程(Diffusion Process),该过程涉及到正向和反向步骤,来模拟噪声的添加和去除,最终又通过一个解码器(Decoder)还原成像素空间的生成图像(Generated Image)。
在扩散过程中间部分,有一个去噪U-Net网络(Denoising U-Net),它主要负责预测如何逆向扩散过程以去除噪声。这个网络使用了一个交叉注意力机制(cross-attention),以及其他的机制,如跳跃连接(skip connection)。
在流程图的右侧,有一个条件化(Conditioning)部分,它含有语义地图(Semantic Map)、文本(Text)和表示图像(Representations Images)。这些信息通过文本/图像变换器(Text/Image Transformer)处理,以帮助影响生成的图像内容。
三、聊聊sora

4 个主要(prime)空间,4 个对偶(dual)Token 序列空间
主空间之间的变换(transformation)经典数学描述
对偶空间之间的 transformation 由 transformer 实现
框图是否可交换?
上面的图展示的是目前生成模型涉及到的几个部分,全部可以归结到一个框架里面。主要包括了两个描述空间:主空间和对偶空间,在每个空间里面又设计到:像素域、隐空间域、diffusion映射后高斯噪声域、以及用来对齐标定用的指标域(文本)。
围绕这主空间、对偶空间衍生衍生出了两大类的生成算法,两大空间又较差、通过隐空间的桥接映射构建出很多类算法;针对需不需要做diffusion映射又衍生出很多类算法。当然这些算法都是依托流行假设定则,只是在求解问题过程中对问题建模、对求解过程为了求解的方便做了各种假设。
(一) sora原理介绍
1. 具备什么能力:

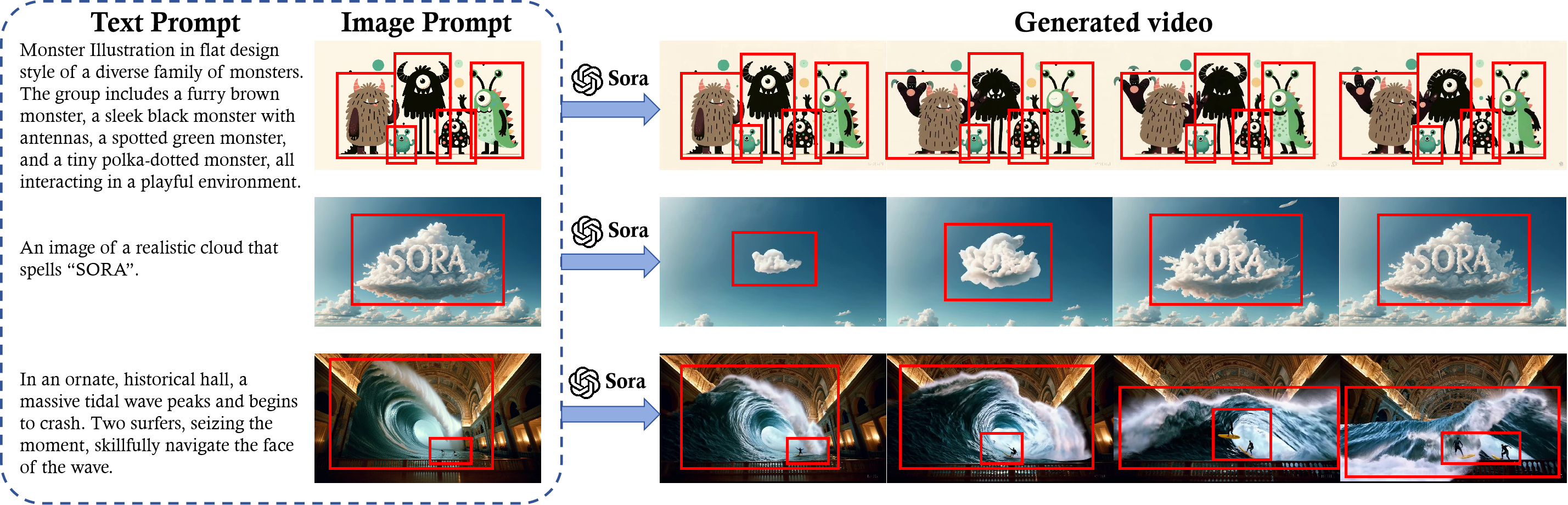
1.视频时长可变
2.视频长宽比可变
3.可以根据给定文本生成视频
4.可以根据给定的图生成视频
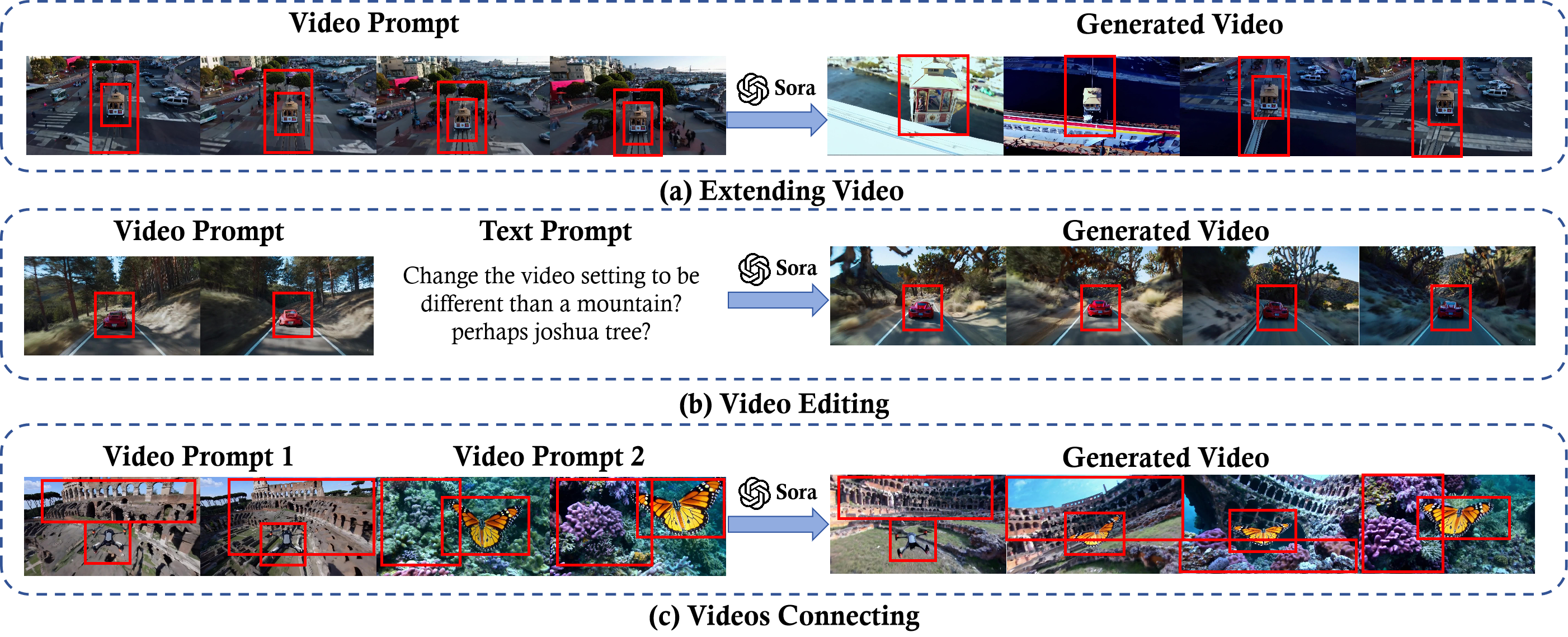
5.可以根据给定视频前向、后向生成视频
6.可以为给定的两段视频生成中间衔接视频
7.可以对视频编辑
8.长时间跨度角色一致
2. 原理和任务设计:sora=GPT+diffusion
从上面sora具备的能力看,是不是感觉有点似曾相识的感觉。是的如果把视频生成转成文本生成,其实sora上面能力不就是和gpt能力一致的吗。下面我来给大家翻译下:
1.视频时长可变==>可以前向生成,基于上下文做续写(文本生成)
2.可以根据指定文本、图生成视频==>根据prompt生成可控文本(incontext learn)
3.可以根据给定视频做生成==>根据给定文本做阅读理解、续写
4.可以对视频编辑==>根据指定文本做修改、摘要抽取、问答
5.可以把两段视频衔接==>对应文本完形填空
6.长时间跨度角色一致==>阅读理解、对话角色跟踪
那么GPT是如何在文本域内解决上面这些问题的呢?
1.token前向生成,把生成问题转成根据给定的数据预测下一时刻分布,就是相邻序列分布映射问题
2.三阶段训练,先学会两个相邻分布映射,然后用sft来搞定时间序列(上下文指令),通过rlhf解决对错不明显的主观对齐
3.通过mask的方式来强迫模型学习抽象
那么sora其实也是一样的套路,只是sora在GPT之后引入了diffusion这个过程,原因是diffusion对于高维生成可控性更好。
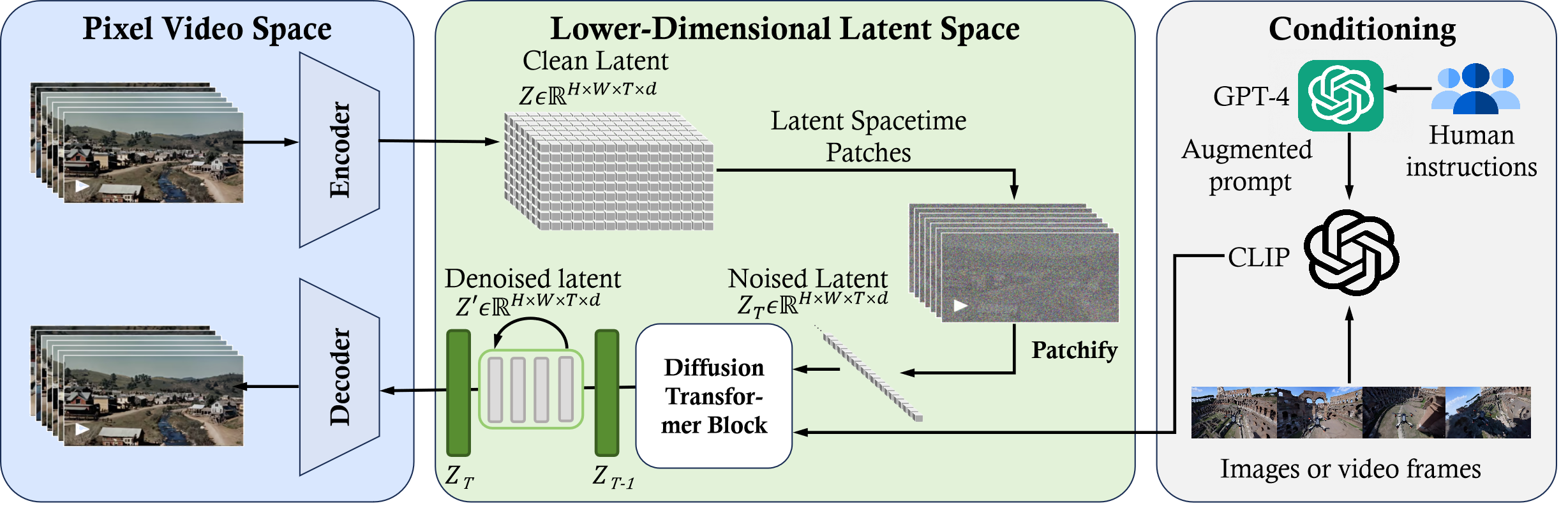
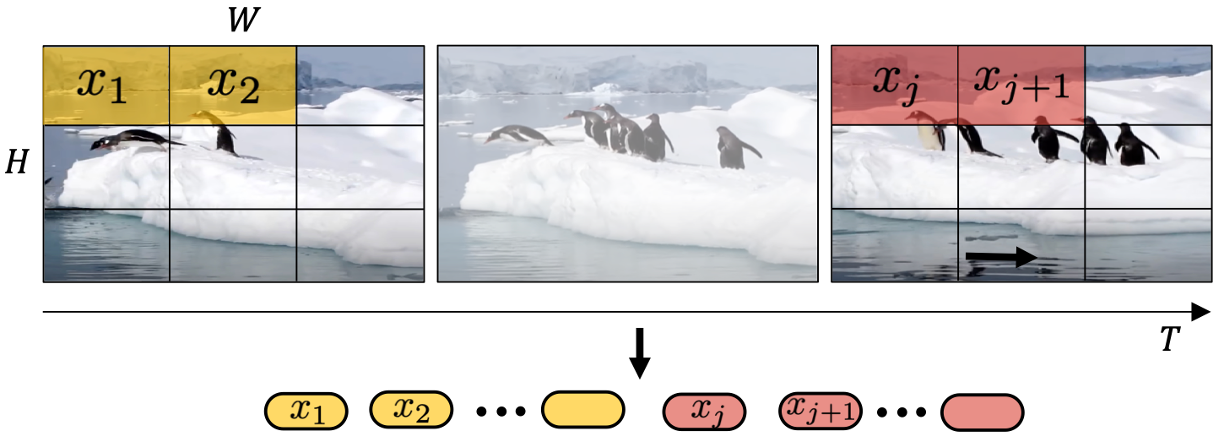
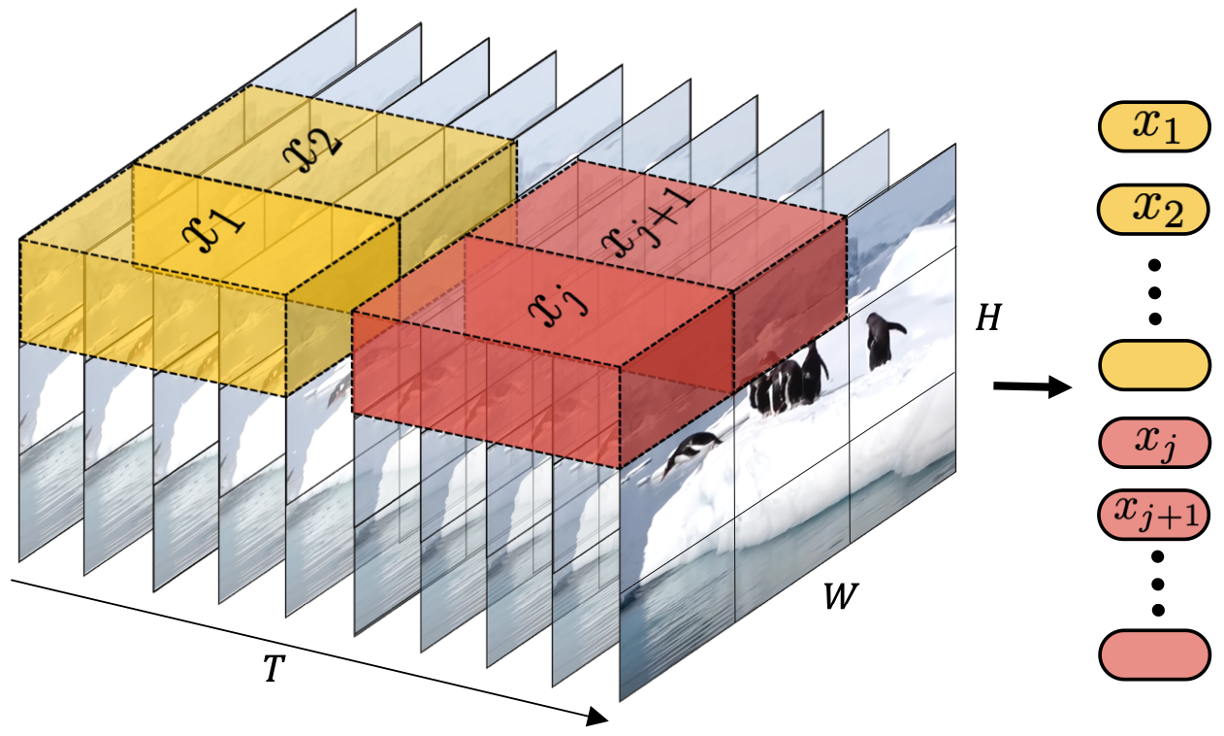

(二) sora一些问题
1. 相关性与因果律的矛盾
ChatGPT 将语句分解成 Token,然后用 Transformer 学习 在上下文中 Token 间连接的概率分布。Sora 将视频分解成时空 Token,然后学习上下文中 Token 间连接的概率分布,并且依据这一概率分布生成时空 Token,连接 Token 再解码成短视频。 每个 Token 表达图像或者视频中的一个局部区域,不同局 部区域间的拼接成为问题的关键。Sora 相对独立地学习每 个 Token,将 Token 间的空间关系用训练集中体现的概率 来表达,从而无法精准表达 Token 间时空的因果关系。 这意味着 Transformer 用以表达 Token 之间的统计相关性, 无法精确表达物理因果律。虽然 transformer 可以在一定程度上操纵自然语言,但自然 语言无法准确表达物理定律,而物理定律目前只有偏微分方 程才能精密表达。这反应了基于概率的世界模型的某种局限性。 AGI 需要掌握抽象思维,和数学物理理论体系的符号表达。
2. 局部合理与整体荒谬的矛盾
Sora 相邻 Token 间的拼接做得很合理,但是整体拼接的视 频却可能出现各种悖谬。这意味着局部拼接与整体拓展之间 的鸿沟。 我们观察“幽灵椅子”视频,如果我们将视野限制在屏幕中 间的一个局部区域,则视频非常合理。仔细检测不同 Token 区间直接的连接,也非常连续光滑。但是整个椅子如鬼魅般悬空,这与日常经验中的重力场相悖。意味着 Transformer 学会了 Token 间局部的连接概率,但 是缺乏时空上下文的大范围整体观念。 再如 Sora 生成的“四足蚂蚁”的视频,蚂蚁的动作栩栩如 生,宛如行云流水。局部上非常流畅自然,令人不禁联想或 许在某个星球上存在这种四足蚂蚁。 但是整体上,地球的自然界并没有四足蚂蚁。这里局部的合 理无法保证整体的合理,这里的全局观念来自于生物学的事实。
Sora 生成的“南辕北辙跑步机”视频,如果我们观察每一个 局部区域,看到的视频都是合理的,视频 Token 间的连接 也是自然的. 但是整体视频却是荒谬的,跑步机与跑步者的方向相反。 这个视频的全局观与来自于人体工程学的事实相悖。目前的 Transformer 虽然可以学习局部的上下文,但无法学 习更加全局的上下文,这里的全局可能是物理中的重力场, 也可以是人体工程学,或者生物中的物种分类。 这种全局观点,恰是朱松纯教授提出的 AI 世界中的 “暗物 质思想”。 虽然每个训练样本视频都隐含地表达了全局的观念,但是 Tokenization 的过程却割裂了全局的观念,有限地保留了临 近 Token 间的连接概率,从而导致局部合理,整体荒谬的结果。 现代整体微分几何非常重视整体和局部的矛盾,为此发明了 多种理论工具。比如,我们可以在拓扑流形的局部构造光滑 标架场,但是无法将其全局推广,全局推广的障碍就是纤维丛的示性类。 复流形上,我们可以局部构造亚纯函数,但是整体上无法将 局部的函数拼接成整体的亚纯函数,这种局部推广到整体的 差异用层的上同调理论来精确刻画。很多物理理论都表示成 特定纤维丛的示性类理论,例如拓扑绝缘体理论。 这种局部容易构造,整体推广出现实质性困难的数学理论, 实际上是人类深层次探索自然的智慧结晶。这种整体的拓 扑、几何观点目前还没有推广到 AI 领域。由平均场理论,在粒子系统中,临近粒子之间有相互作用, 远处粒子彼此没有影响,这由关联长度来表达。在特定情形 下,系统的关联长度趋于无穷,则系统处于相变状态 (phase transition)。AI 中的相变,就是 “涌现”。 如果 Transformer 的上下文长度趋于无穷,那么 Transformer 发现了无所不在的自然法则,AI 就出现了智慧 涌现; 在物理中,相变具有共形不变性,这是相变理论的核心观点 之一;在 AI 中,共形不变的意义如何,依然在探索之中。
3. 临界状态的缺失
自然界的绝多数物理过程都是稳恒态与临界态的交替变化。
在稳恒态中,系统参数缓慢变化,容易获取观察数据;由此, Sora 系统学习到的数据流形,绝大多数都是由稳恒态的样 本所构成, 在生成过程中,Sora 非常容易生成稳恒态的视频 片段;
在临界态中(灾变态),系统骤然突变,令人猝不及防,很 难抓拍到观察数据。因此,临界态的数据样本非常稀少,几 乎在训练集中零测度。物理过程中的临界态样本多分布在数 据流形的边界, Sora 生成过程中往往跳过临界态。
但是在人类认知中,最为关键的观察恰恰是概率几乎为零的临界态。
Sora 生成小狗群在嬉笑斗闹,时而相互遮挡,时而散开。在 视频的某一刹那,屏幕中的 3 只小狗突然变成 4 只小狗。
4 只小狗的图片构成一个流形(或者连通分支),3 只小狗的 图片构成另一个分支,在 4 只小狗图片流形的边界处,有个 临界事件:四只小狗彼此遮挡,图片中只能看到 3 只小狗。
Sora 的扩散模型没有识别出流形的边界,而是冲破这边界, 在 3 只小狗图片的流形和 4 只小狗图片的流形间跨越。
正确的做法应该是先识别流形的边界,然后在物理无法跨越 的情形下(如 3 只边 4 只),在边界处返折回原来流形。
Sora 无法生成关键临界态的图像可能有如下原因:
物理过程中的不同稳衡态样本生成数据流形的不同联通分 支,临界态样本在稳恒态流形边界附近,在两个稳衡态流形 边界之间。
Sora 采用的目前最为热门的扩散模型,在计算传输映射的 时候,必然会光滑化数据流形的边界,从而混淆不同的模 式,直接跳过临界态图像的生成。因此视频看上去从一个状 态突然跳跃到另外一个状态,中间最为关键的倾倒过程缺 少,导致物理上的荒谬。
采用丘成桐先生发明的几何变分法求解最优传输映射,可以解决这个关键问题。
一、奇异集合
模式坍塌和模式混淆可以由最优传输映射的正则性来解释. 如果 目标测度的支撑集非凸, 则最优传输映射可能非连续, 在奇异集 合上间断. 由 Brenier 极分解定理, 一般的传输映射是最优传输 映射与保测度同胚的复合. 因此, 在这种情形下, 传输映射也是非 连续的. 深度神经网络只能表达连续映射, 因而无法表示一般的传输映射. 训练过程或者无法收敛, 或者收敛到某个连续的传输 映射, 其目标区域限制在某些模式, 而遗漏其他模式, 这导致了模 式坍塌; 或者收敛到某个连续传输映射, 其像覆盖所有模式, 同时 也覆盖了模式之间的空隙, 这导致模式混淆.
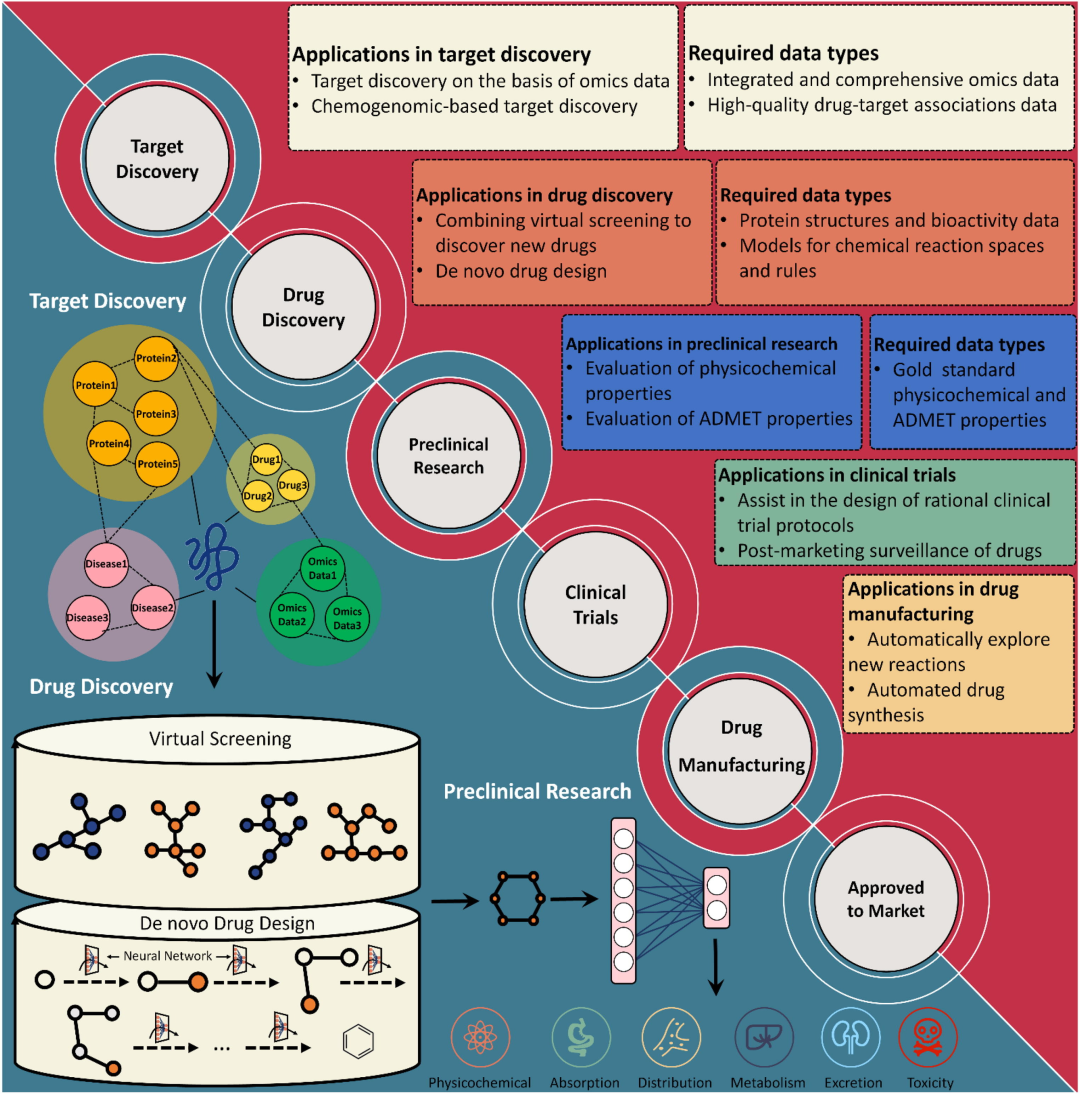
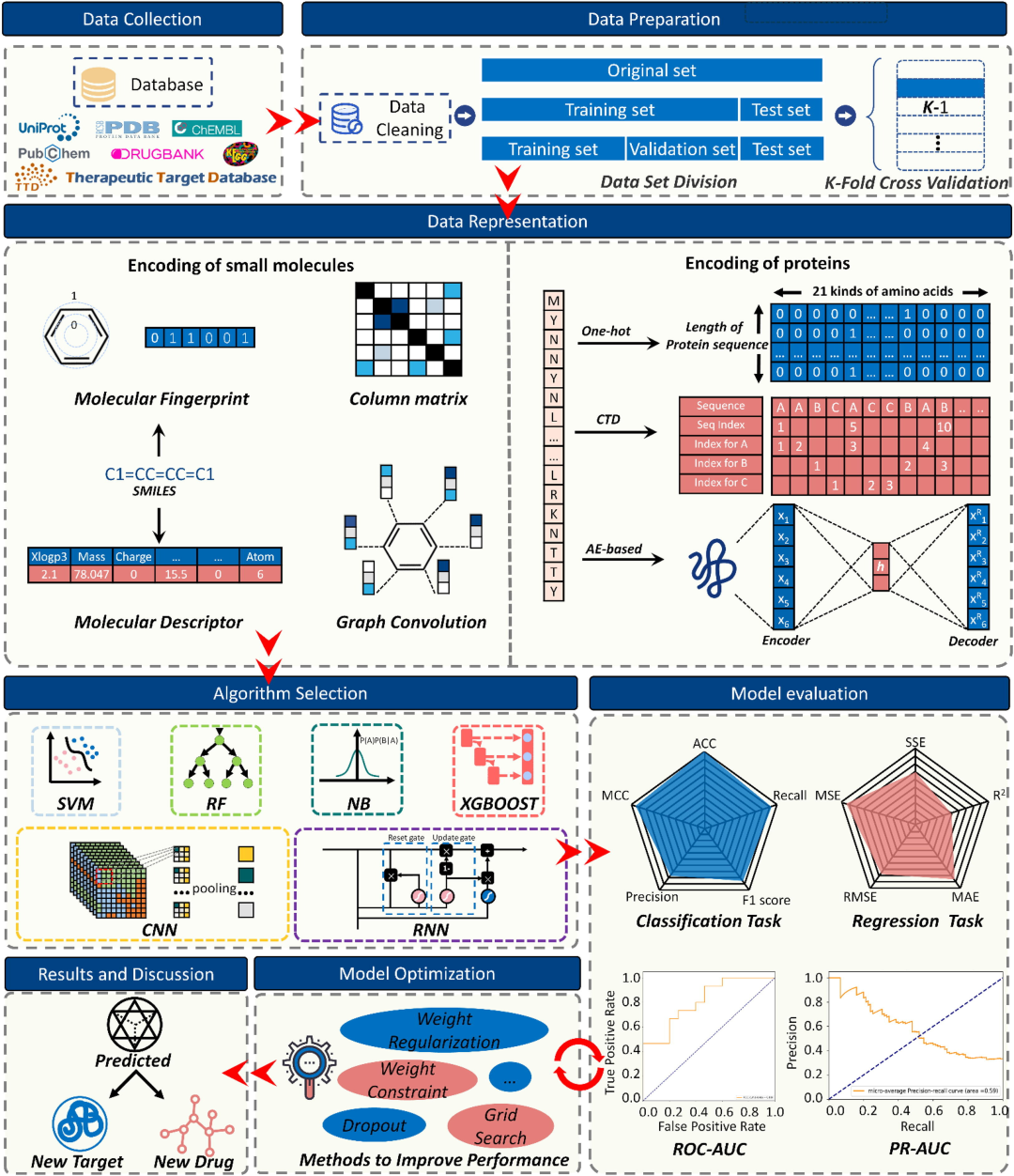
四、人工智能的应用
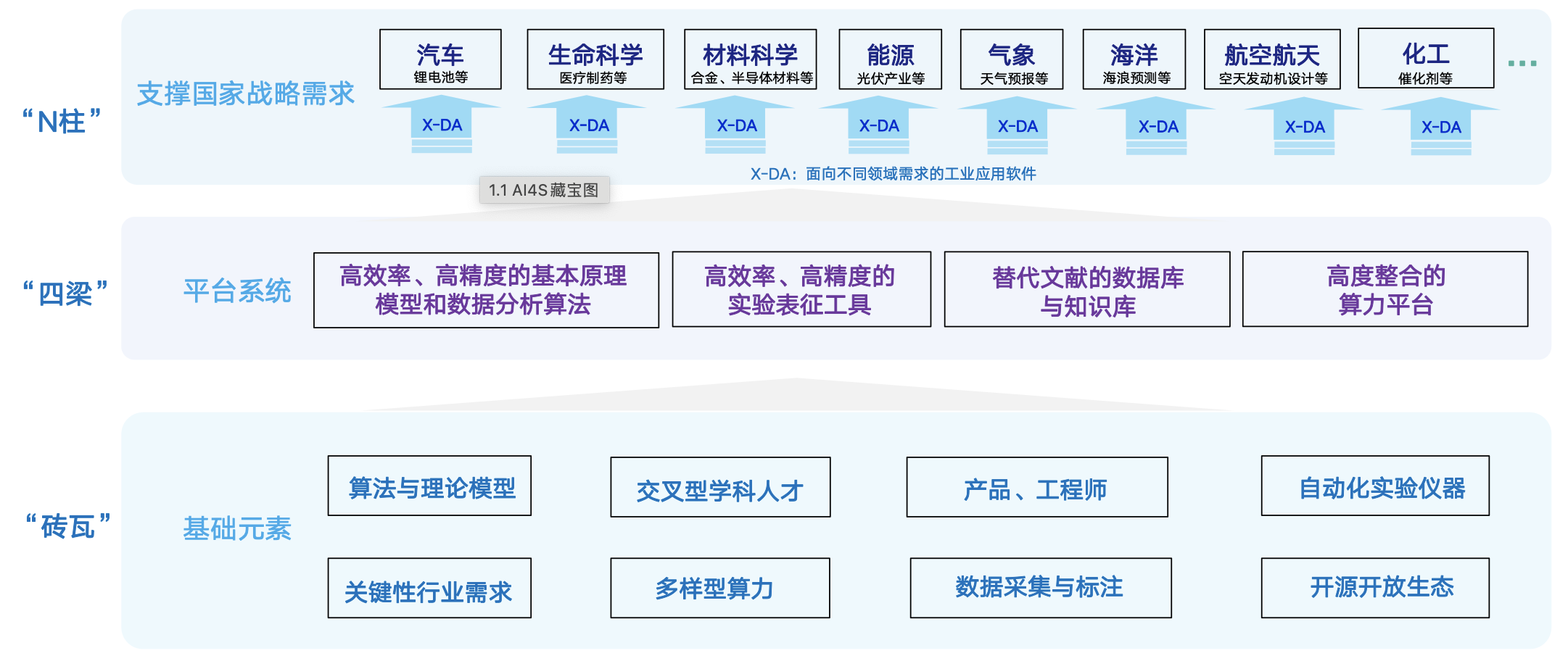
AI4science:材料研发、高分子设计、药物设计、建筑造型、流体力学、仿真、天气预测、动画制作
AI4生产:芯片设计、虚拟仿真、短视频生成、内容生成、卫星图复现、征信、法律、陪伴、公文
AI4生活:chatgpt、mj、小红书
AI产品:智能驾驶、人形机器人、安防、黑灯车间
(一) AI4science(AI助力科学研究)

我们来详细了解下AI在科学研究中的几大应用场景:
1. 材料研发:

- 新材料预测:AI可以模拟评估新材料的物理化学属性,如机械性能、导电性、热稳定性等。AI模型可以分析材料微观结构与宏观性能之间的关系,协助科研人员更快地发现有潜力的新材料。
- 复合材料设计:AI协助设计复合材料的结构和成分,以获得理想的性能。例如,可优化航空材料的重量与强度比,提高飞机的能效。
使用模型:GAN(生成对抗网络)、VAE(变分自动编码器)等深度学习模型。
如何使用:在材料研发和高分子设计中,这些模型可模拟材料或分子结构与属性之间的关系。例如,以分子为输入,预测其化学、物理属性;或以特定属性为目标,设计分子结构。深度学习模型可从大量材料数据中发现规律,协助科研人员高效筛选有潜力的新材料或新分子。
机器学习Machine Leaning凭借其强大的预测性能,已广泛应用于材料科学各领域,如
(a)高效材料特性预测的代用模型开发。
(b)适应性 设计和主动学习的迭代框架。
(c)使用变异自动编码器VAE和生成对抗网络GAN的生成性材料设计。
(d)通过将实验设计算法与自动机器人 平台结合,实现ML自主材料合成。
(e)使用基于ML的力场来解决一系列的原子学材料模拟问题。
(f)深度学习用于原子尺度材料成像数据 的精确表征。
(g)使用自然语言处理和ML从科学文本中自动提取科学知识和见解。机器学习不仅能够对材性能进行预测,同时挖掘边界条件 等信息,也有助于推进对相关机理的认识。
美国加州大学伯克利分校Gerbrand Ceder教授小组开发了将第一性原理计算与信息学(数据挖掘) 相结合来预测晶体结构的方法。

面对新材料研发领域日趋激烈的同质化竞争,AI技术在材料研发过程中带来的诸多底层创新无疑也展现出了巨大的价值。伴随着新材料产业巨 大的增长潜能和人工智能产业的快速发展,AI企业正加快布局新材料产业。2020年初创型AI企业中,布局制造业占比达23%,成为全行业最高。 蓬勃发展的初创企业正在为AI材料科学行业带来全新的视角和分析工具,例如中国基于“多尺度物理模型+AI+高性能计算”新一代分子模拟平 台的深势科技,基于跨尺度模拟的迈高科技等新兴公司,都在尝试利用人工智能技术解答材料科学中最本质的问题,从而赋能新材料的研发。
全球领先的材料企业正积极采用AI技术变革材料研发模式,缩短材料发现到应用的时间。材料研发制造企业选择自建内部开发平台,如英特尔 和丰田等公司建立内部人工智能中心;或是与AI供应商或其他材料信息科技企业合作,如波音公司与Citrine Informatics合作开发数据驱动的研 发项目,以研发航空新材料。目前国内活跃的材料企业与AI企业合作的案例相对较少,如果与AI企业合作的材料企业数量能过快速提升,将会 使得整个行业变得非常活跃,届时将有更多的材料企业参与进来,从而使AI材料研发进入到快速增长期。
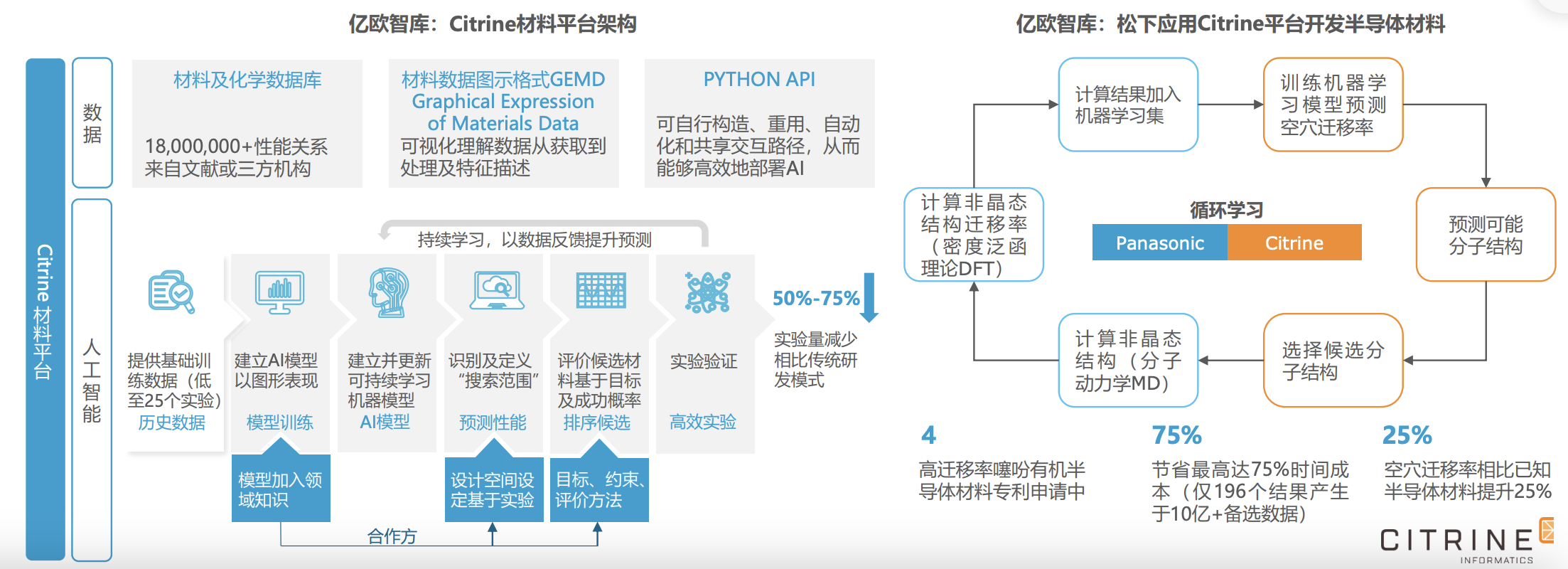
Citrine利用材料平台构建人工智能,以推动更高效的发现、优化、制造和应 用材料。该平台通过各种来源吸纳结构性和非结构性材料数据,并利用人工智能引擎来识别数据中的重要信息,从而助力材料企业的研发与制 造。Citrine服务于先进材料研发企业,如3M、BASF、Showa Denko、LANXESS、AGC等;科研机构,如加州大学伯克利分校;政府机构, 如美国能源部等,涵盖汽车、航空、消费品、电池和电子等领域。
2. 高分子设计:
- 功能高分子设计:AI可根据特定应用场景,设计具有目标功能的高分子材料。例如,可设计具有亲水性的高分子以提高生物相容性,或设计具有特定颜色的高分子用于激光器件。
- 高分子合成路线预测:高分子合成往往步骤复杂、成本较高。AI通过学习已知合成路线,可为研究员提供更简便、经济的合成路线图,加速实验室实验。
3. 药物设计:

- 药物分子筛选:AI模拟药物分子与靶标蛋白质的交互,从海量分子中快速筛选出有潜力的药物分子。这有助于减少药物研发过程中的无用工序,提高药效、安全性。
- 药物副作用预测:AI可分析药物分子结构,预测其可能带来的副作用,为临床试验提供参考,保障用药安全。


4. 建筑造型:
- 建筑设计辅助:AI根据功能需求、美学原则、气候条件等,生成建筑造型灵感,为建筑师提供设计思路。AI还可模拟建筑的能耗、日照等,优化建筑设计。
例如,谷歌曾推出AI建筑设计工具"AutoDraw",可根据建筑师的手绘草图,实时生成计算机辅助设计(CAD)图纸。
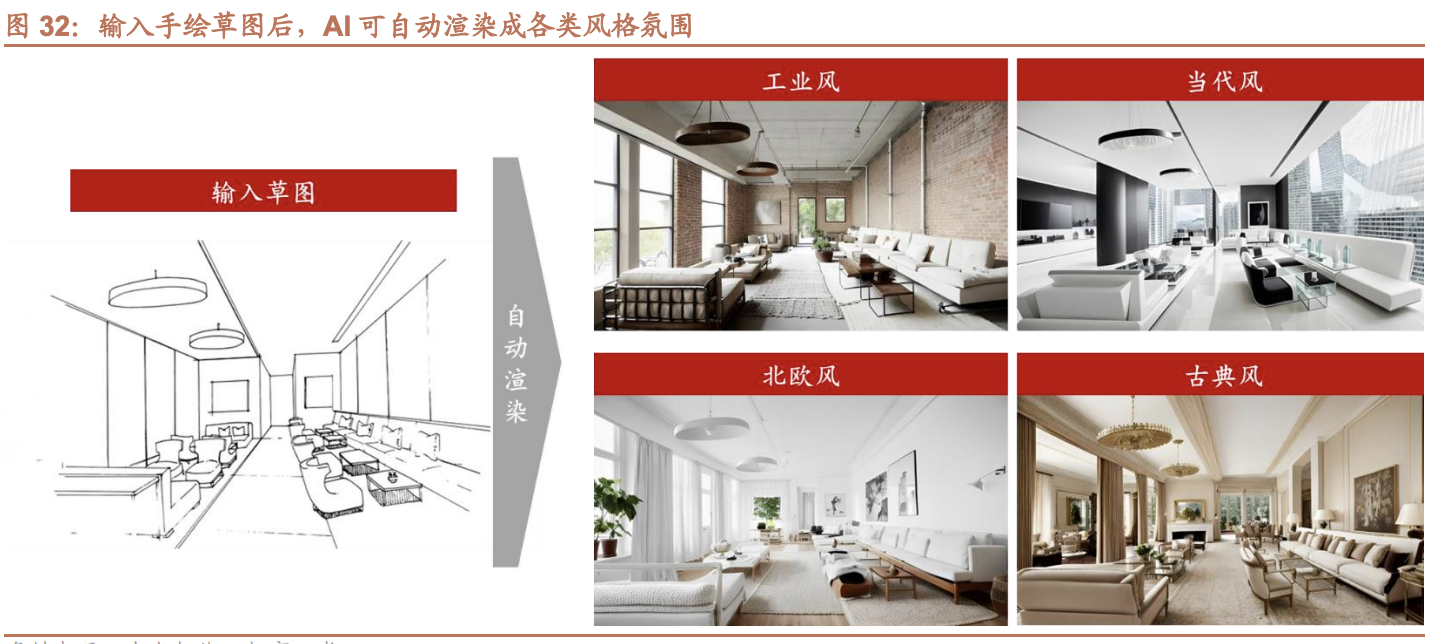

AI 设计师或能突破“人”的局限性。进一步推演,生成式 AI 使得未来的建筑设 计师的工作内容出现了强有力的竞争者—— (1)认知局限性:由于个人思想的局限性和认知的主观性,设计师所设计的成 果在一定程度上具有一些强烈或者是风格明显的主观色彩;人很难设计出自己认 知之外的东西,也很难触达自己的知识和想象力以外的设计。而人工智能则可以 在一定程度上规避掉设计师作为个人认知的局限性,应用模型进行分析,生成满 足项目要求的设计成果,也可为设计师提供丰富的思考和灵感。 (2)复杂度局限性:由于建筑设计领域的目标函数十分复杂,在面对目标函数 模糊等复杂设计问题时,人类设计师很难克服其自身能力的有限性。人类设计师 或许无法用现有的简单规则来概括解释复杂的逻辑,但人工智能却可以在经历设 计大数据的训练后,生成人类建筑设计师无法描述的设计案例。
5. 流体力学:
- 流体模拟与优化:AI模拟流体在不同场景下的行为,如空气围绕翼面的流动、流体经过水轮机等,优化航空、航海和流体机械的设计。AI可帮助设计更具效率的翼型、船 hull,提高能效。
6. 仿真:
- 生物医学仿真:AI可模拟细胞行为、组织生长、器官发育等,协助生命科学研究,减少对动物实验的依赖。例如,可模拟癌症细胞的生长、扩散,研究肿瘤治疗方法。
- 物理系统仿真:AI模拟粒子间相互作用、电磁场等物理现象,协助物理科研人员设计实验、验证理论模型。
7. 天气预测:
- 天气预报增强:通过学习大量气象数据,AI可提高天气预报的准确性。AI模型可以捕捉复杂的多尺度气象模式,改善极端天气事件预报、提高预警效率。
8. 动画制作:
- 动画故事创作:AI可协助动画师创作故事情节、设计角色,为动画制作提供创意启发。AI还可根据故事大纲生成初步动画,加快制作进程。
- 动画渲染:AI可模拟复杂光源效果、环境反射等,提升动画的渲染质量,使动画制作更具现实感。
(二) AI4生产(AI赋能生产制造)

1. 芯片设计:
利用机器学习算法,生成式 AI 能够实现设计流程的自动化,有助于快速进行原型验证和探索设计空间。它可以优化设计、改进 PPA 并加快产品上市。此外,生成式 AI 有助于推动创新,助力设计人员打造新颖独特的定制解决方案,满足多样化的需求。
用于芯片、系统和产品设计的生成式 AI 是一个大型语言模型组合,用于衔接人类的语言沟通和技术设计,强化学习用于在设计上进行优化和操作时决策的自动化,迁移学习则用于将过去的解决方案应用到新的项目当中。
- 集成电路布局:AI可根据芯片的功能和性能要求,建议芯片尺寸、晶体管布局等,提高芯片设计效率,加速芯片研发。
- 芯片性能优化:AI模拟不同芯片结构的性能,为芯片设计提供数据支持,协助工程师优化芯片架构。
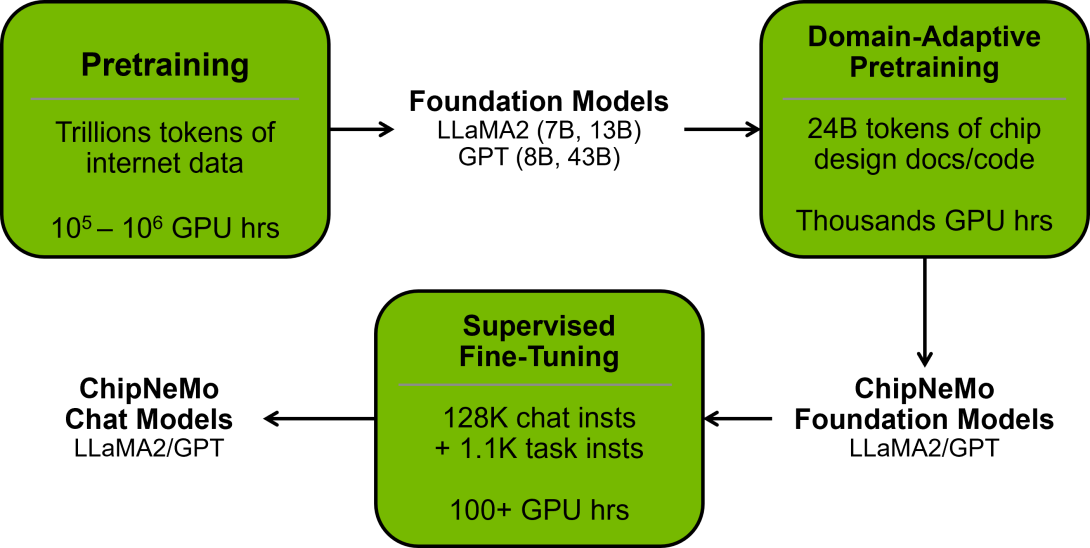
芯片设计到最后其实就是在做硬件代码开发,所以芯片设计转化成硬件代码生成问题。
2. 虚拟仿真:
- 产品测试优化:在虚拟环境中,AI可模拟产品在真实世界中的表现,进行性能测试和优化。例如,汽车制造商可利用AI模拟车辆碰撞,测试和完善安全设计。
- 工业流程优化:AI可模拟工业生产过程,优化流程、提高效率。例如,AI可模拟机器人装配流程,减少装配时间、改善装配精度。
3. 短视频生成:
- 自动化视频制作:AI根据文本脚本或语音旁白,自动生成短视频内容。它可以将文字或语音转化为视频画面,还可添加特效、插入虚拟人物。
- AI合成主播:AI可将真实主播的视频和音频进行分析、合成,生成虚拟主播,用于各种新闻报道、直播场景。

4. 内容生成:
- 自动化内容创作:AI可自动生成各种形式的内容,如文章、产品评论、旅游攻略等。它可以根据目标用户、主题要求生成定制化内容,提高用户粘性、提升网站流量。
- 创意内容生成:AI还可协助创作者产生创意,为作家、广告创意人员提供灵感,助力内容的创新。

5. 卫星图复现:
- 高分辨率卫星图像处理:AI可复现高分辨率卫星图,提高图像质量、填补云盖等。复现后的卫星图可用于城市规划、环境监测、灾害评估等。
6. 征信:
- 信用评分:AI可分析用户的借贷记录、消费行为等,为金融机构提供信用评分,协助贷款审批、风控模型建立。
- 欺诈检测:AI可监测金融交易中的异常行为,协助识别信用卡欺诈、保险欺诈等,降低金融机构的风险损失。

7. 法律:
- 法律研究助理:AI可协助法律工作者快速检索法律案例、法规,提高法律研究效率。AI还可分析合同、法律文件,帮助识别漏洞、风险。
- 知识产权审查:AI可协助审查专利申请、商标注册的合法性,提高知识产权审查效率。
- 人工智能生成内容在法律和合规领域的应用:
- 法律文书起草:人工智能生成内容可以辅助律师进行法律文书的起草工作。通过学习历史案例、分析法律文件等,AIGC可以生成质量较高的法律文件草稿,大大提高了起草效率和准确性。
- 合规报告生成:在合规领域,人工智能生成内容可以帮助企业生成合规报告。通过分析海量的数据和法规要求,AIGC可以快速生成符合要求的合规报告,减少了人工操作的时间和工作量。
- 合同起草与审核:在商业交易中,AIGC可以帮助律师和企业起草合同,并且通过自然语言处理技术对已有合同进行审核。通过学习法律知识和相关案例,AIGC可以提供辅助决策的意见并辅助修改合同,保证合同的准确性和法律合规性。
- 法律咨询与知识管理:通过AIGC技术,可以开发智能法律咨询系统,为公众提供在线法律咨询服务。这些系统可以回答用户的法律问题,提供相关法律知识和案例,辅助用户理解和应对法律问题。
- 法律数据挖掘:人工智能生成内容可以帮助律师和法官从大量的法律文本中挖掘出有用的信息和线索。通过自然语言处理和机器学习技术,AIGC可以分析和梳理法律文件中的信息,提供法律专业人士更好的信息检索和决策支持。
8. 陪伴:
- 虚拟助手:AI可提供陪伴、聊天,伴随用户阅读、运动、游戏,给用户带来舒适、放松的体验。虚拟人物可根据用户喜好提供定制化服务。
- 虚拟好友:AI控制的虚拟人物可与用户进行互动游戏、分享生活经验,丰富用户的社交生活。
9. 公文写作:
- 自动化公文生成:AI可根据会议内容、政府政策等自动生成公文、工作报告、简报等。AI的文字处理能力可为公职人员减负,提高办公效率。
- 政策制定辅助:AI可分析历史政策文件,为政府决策提供数据支持、政策建议,提高决策的科学性。

(三) AI4生活(AI改善生活体验)
1. ChatGPT 等对话式AI:
除了回答问题外,ChatGPT还可以进行有创意的对话、帮助用户完成任务。例如,它可以协助用户策划旅行路线、指导用户烹饪美食、提供健身建议等。
2. MJ 等虚拟人:

虚拟人可以提供更具临场感、互动感的体验。除了基本的聊天互动外,虚拟人还可以进行歌舞表演、健身指导、教育讲解等。虚拟人在元宇宙中可提供更丰富的虚拟体验。
3. 小红书等内容推荐:
除了推荐产品、内容外,AI在小红书上还可协助进行美妆教程制作、图片视频处理。AI可以根据用户喜好,提供美妆、时尚穿搭建议,提高用户的体验感。
(四) AI产品(AI赋能实体产品)
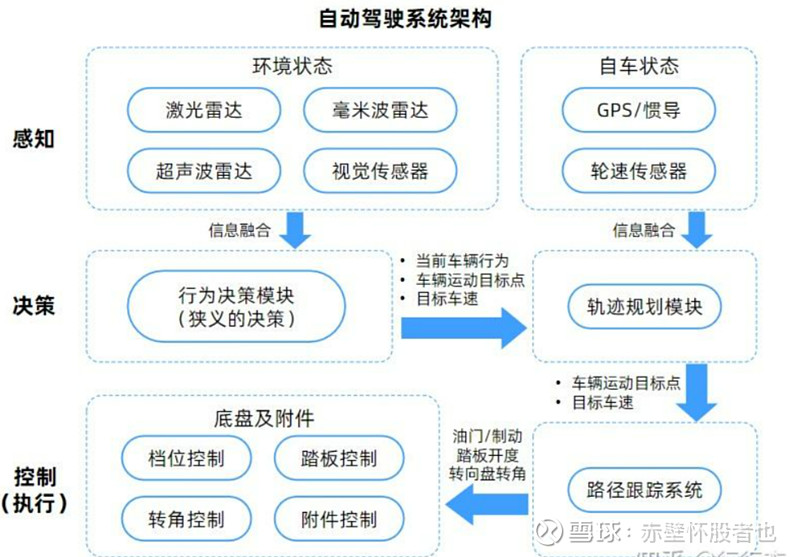
1. 智能驾驶:
除了基本的ADAS(高级驾驶员辅助系统)外,AI在自动驾驶领域有以下应用:
- 环境感知:AI可实时感知车辆周围环境,识别道路标线、交通标志、行人、车辆等。
- 行为预测:AI可以预测行人的行走路线、车辆的行驶方向,提高自动驾驶的安全性。
- 决策规划:AI规划车辆行驶路线,进行实时优化,确保车辆安全、高效行驶。
2. 人形机器人:
人形机器人具有更人性化的交互能力:
- 自然语言处理:人形机器人可理解、回应用户的口语指令,进行流畅的语言交互。
- 动作控制:人形机器人可随意活动四肢,进行复杂动作,甚至可以进行舞蹈、瑜伽表演。
- 情感交互:部分人形机器人可以识别、表达情感,与用户建立情感联系。
3. 安防:
除了人脸识别外,AI在安防领域还有以下应用:
- 异常行为检测:AI可监测人群中异常的行为,如扒手、打架等,协助安保人员及时处置。
- 消防安全:AI可分析烟雾、火焰等,实现火灾的早发现、早预警。
- 监控识别:AI可协助分析监控画面,提高安防系统的识别效率和准确性。
4. 黑灯车间:
黑灯车间是通过物联网和AI技术实现的智能化车间:
- 设备监测与预警:AI可实时监测车间内设备运行状况,及早发现设备故障、报警,提高生产效率。
- 生产流程优化:AI可模拟优化生产工艺,提高产品良率、降低能耗。
- 智能仓储:AI可优化库存管理、货物搬运路线,提高仓储效率。
五、下一个浪潮
(一) 跳出缸中脑——虚实结合
(二) 智能驾驶例子
(三) 智能机器人例子
六、 AI对我们的影响
如何和AI共生
如何利用好AI
如何教育