Abstract
我们提出了一个新的 Patch 分布建模框架,在单类学习的设置下,PaDiM 同时检测和定位图像中的异常。PaDiM 利用一个预先训练好的卷积神经网络 (CNN) 进行 patch 嵌入,利用多元高斯分布得到正常类的概率表示。它还利用了 CNN 的不同语义级别之间的相关性来更好地定位异常。PaDiM 在 MVTec AD 和 STC 数据集上的异常检测和定位方面优于当前最先进的方法。为了匹配真实世界的视觉工业检查,我们扩展了评估协议,以评估非对齐数据集上异常定位算法的性能。PaDiM 最先进的性能和低复杂度使其成为许多工业应用的良好候选。
Introduction
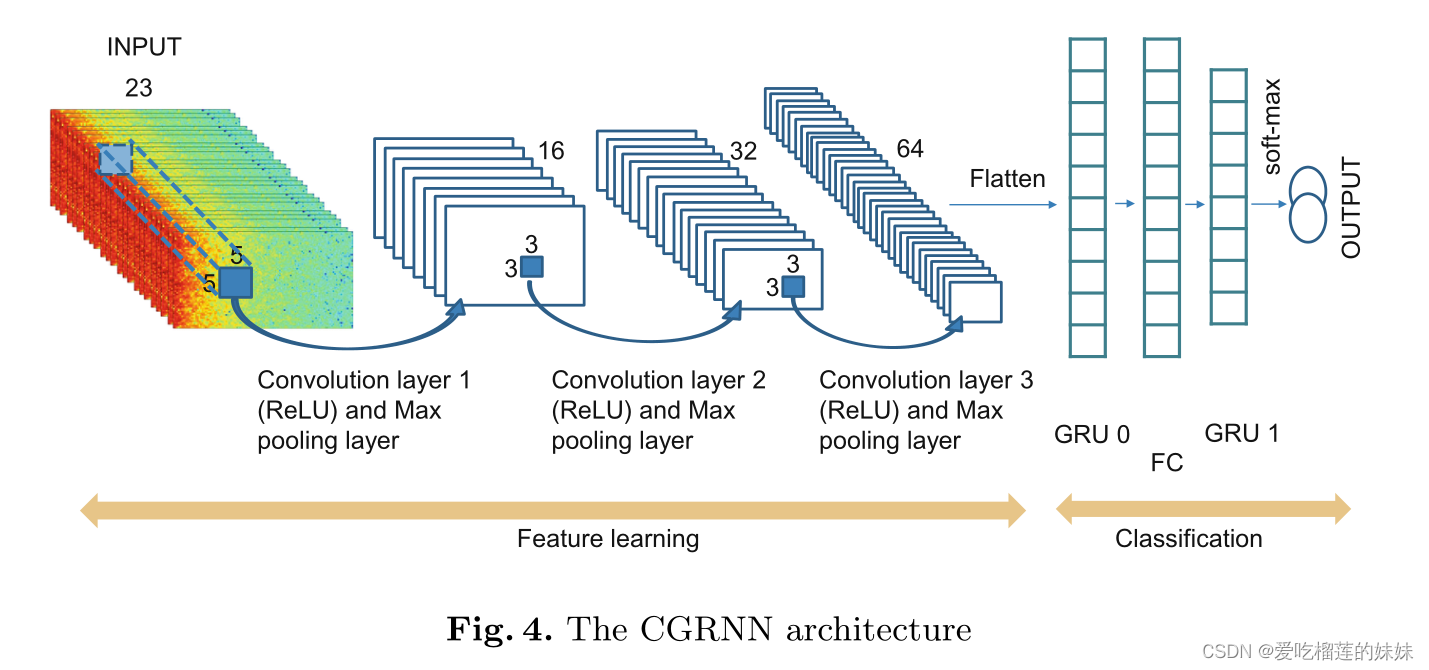
人类能够在一组同质自然图像中检测出异质或意外的模式。这种任务被称为异常检测,并有大量的应用,其中就包括视觉工业检查。然而,异常在生产线上是非常罕见的事件,手动检测很麻烦。因此,异常检测自动化可以通过避免减少操作员注意力持续时间和方便操作员工作来实现持续的质量控制。在本文中,我们主要关注于异常检测,特别是在工业检查的背景下的异常定位。在计算机视觉中,异常检测就是给图像一个异常分数。异常定位是一项更为复杂的任务,它给每个像素或像素的每个补丁分配一个异常值,以输出一个异常图。因此,异常定位产生更精确和可解释的结果。通过我们的方法在 MVTec 异常检测 (MVTec AD) 数据集的图像中进行异常定位的异常图示例如图 1 所示。

图 1 来自 MVTec AD的图像样本。左栏: 晶体管,胶囊和木材类的正常图像。中间一栏: 同类别的图片,用黄色突出显示地面真相异常。右栏: 我们的 PaDiM 模型得到的异常热图。黄色区域表示检测到的异常,而蓝色区域表示正常区域。
异常检测是正常类和异常类之间的一种二元分类。然而,由于我们经常缺少异常的例子,而且异常可能具有意想不到的模式,所以不可能在完全监督下训练模型来完成这项任务。因此,异常检测模型通常在单类学习设置下进行估计,即训练数据集仅包含正常类的图像。在测试时,将与正常训练数据集不同的样本分类为异常样本。
最近,有几种方法被提出将异常定位和检测任务结合在一个类学习设置中。然而,它们要么需要深度神经网络训练,这可能比较麻烦,要么在测试时间,时对整个训练数据集使用 k 近邻 (K-NN) 算法。随着训练数据集的增大,KNN 算法的线性复杂度增加了时间和空间复杂度。这两个可伸缩性问题可能会阻碍异常定位算法在工业环境中的部署。
为了解决上述问题,我们提出了一种新的异常检测和定位方法,命名为 PaDiM,用于 Patch 分布建模。它利用一个预先训练好的卷积神经网络 (CNN) 进行嵌入提取,具有以下两个特性:
- 每个 patch 位置用多元高斯分布来描述;
- PaDiM 考虑了预先训练的 CNN 的不同语义层次之间的相关性
通过这种新的和有效的方法,PaDiM 在 MVTec AD 上优于现有的最先进的异常定位和检测方法。此外,在测试时,它具有较低的时间和空间复杂度,不受工业应用的数据集训练规模的影响。我们还扩展了评估协议,以评估模型在更现实的条件下的性能,即在非对齐数据集上。
Related Work
异常检测和定位方法可分为基于重建的方法和基于嵌入相似度的方法
Reconstruction-based methods
基于重构的方法被广泛应用于异常检测和定位。训练像自动编码器、变分自动编码器或生成对抗网络这样的神经网络体系结构,只重建正常的训练图像。因此,异常图像可以被发现,因为它们没有很好地重建。在图像层面上,最简单的方法是将重构误差作为异常分数,但从潜在空间、中间激活 或一个鉴别器可以更好地识别异常图像。为了定位异常,基于重构的方法可以将像素级重构误差作为异常评分或结构相似度。或者,异常地图可以是由潜在空间生成的视觉注意力地图。尽管基于重建的方法非常直观和可解释,但它们的性能受到限制,因为 AE 有时可以对异常图像 产生良好的重建结果。
Embedding similarity-based methods
基于相似度的嵌入方法利用深度神经网络提取描述整幅图像的有意义向量,用于异常检测,或用于异常定位的图像 Patch。尽管如此,仅执行异常检测的基于相似度的嵌入方法给出了有希望的结果,但往往缺乏可解释性,因为它不可能知道异常图像的哪一部分是导致高异常分数的原因。在这种情况下,异常分数是测试图像的嵌入向量与代表训练数据集正态性的参考向量之间的距离。法向参考可以是包含法向图像嵌入的 nsphere 的中心,高斯分布参数 或整个法向嵌入向量集合。最后一个选项是 SPADE,它在异常定位方面报告的结果最好。然而,在测试时,它在一组正规的嵌入向量上运行 K-NN 算法,因此推理复杂度随数据集训练大小线性增长。这可能会阻碍该方法的工业应用。
Patch Distribution Modeling
Embedding extraction
预训练的 CNN 能够输出用于异常检测的相关特征。因此,我们选择使用一个预训练的 CNN 来生成 patch 嵌入向量,从而避免了繁琐的神经网络优化。在 PaDiM 中嵌入补丁的过程类似于 SPADE中的过程,如图 2 所示。在训练阶段,正常图像的每个 patch 补丁与预先训练的 CNN 激活图中其空间对应的激活向量相关联。
然后将来自不同层的激活向量连接起来,以获得携带来自不同语义级别和分辨率的信息的嵌入向量,从而对细粒度和全局上下文进行编码。由于激活图的分辨率低于输入图像,因此许多像素具有相同的嵌入,然后形成原始图像分辨率中没有重叠的像素块。因此,可以将输入图像划分为 ( i , j ) ∈ [ 1 , W ] × [ 1 , H ] (i,j)∈[1,W]×[1,H] (i,j)∈[1,W]×[1,H]位置的网格,其中WxH是用于生成嵌入的最大激活图的分辨率。最后,该网格中的每个面片位置 ( i , j ) (i,j) (i,j)与如上所述计算的嵌入向量 x i j x_{ij} xij相关联。
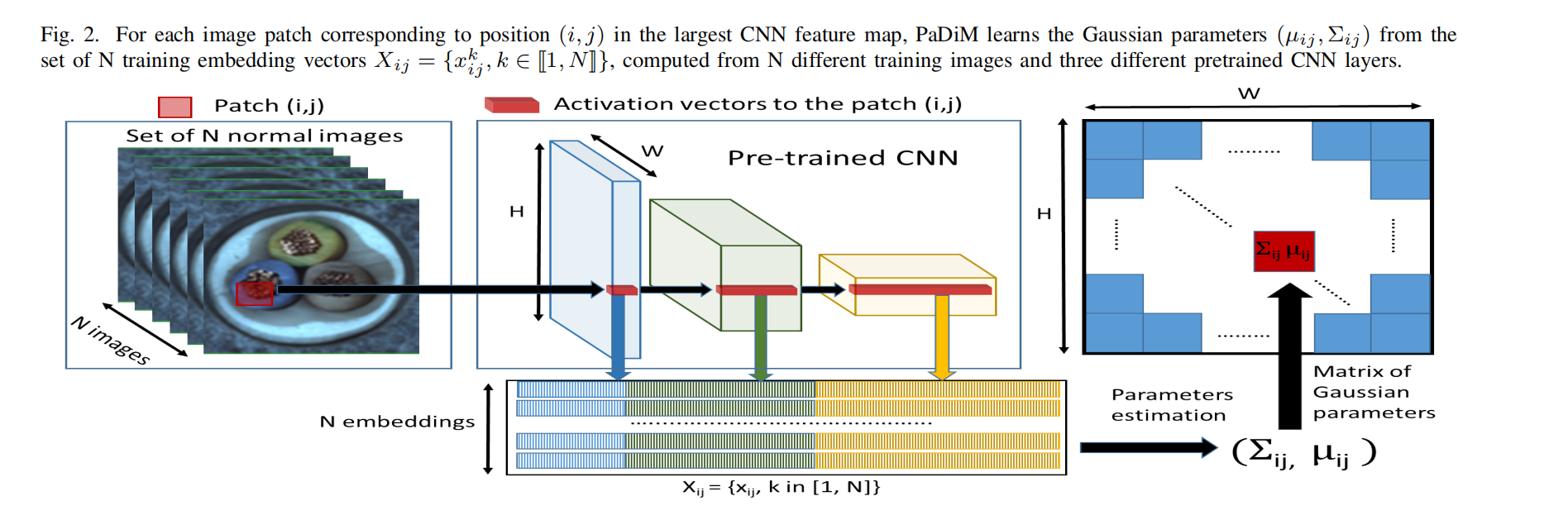
生成的 patch 嵌入向量可能携带冗余信息,因此我们实验研究减小其大小的可能性 (章节 V -A)。我们注意到,随机选择几个维度比经典的主成分分析(PCA) 算法更有效。这种简单的随机维数减少显著降低了我们的模型的复杂性,训练和测试时间,同时保持最先进的性能。最后,使用测试图像的 patch 嵌入向量,借助下一小节中描述的正常类的参数来输出异常图。
Learning of the normality
为了学习位置
(
i
,
j
)
(i, j)
(i,j) 处的正常图像特征,我们首先从 N 幅正常训练图像中计算在
(
i
,
j
)
(i, j)
(i,j)处的 patch 嵌入向量集合,
X
i
j
=
x
i
j
k
,
k
∈
[
1
,
N
]
X_{ij}= {x^k_{ij}, k∈[1,N]}
Xij=xijk,k∈[1,N],如图 2 所示。将集合所携带的信息进行汇总,我们假设由多元高斯分布
N
(
µ
i
j
,
Σ
i
j
)
N(µ_{ij}, Σ_{ij})
N(µij,Σij)产生的
X
i
j
X_{ij}
Xij,其中
µ
i
j
µ_{ij}
µij 是样本均值,
∑
i
j
∑_{ij}
∑ij 样本协方差估计如下:
μ
i
j
=
1
N
∑
k
N
x
i
j
k
Σ
i
j
=
1
N
−
1
∑
k
N
(
x
i
j
k
−
μ
i
j
)
(
x
i
j
k
−
μ
i
j
)
T
+
ε
I
\mu_{i j}=\frac{1}{N} \sum_{k}^{N} x_{i j}^{k} \\ \Sigma_{i j}=\frac{1}{N-1} \sum_{k}^{N}\left(x_{i j}^{k}-\mu_{i j}\right)\left(x_{i j}^{k}-\mu_{i j}\right)^{T} +εI
μij=N1k∑NxijkΣij=N−11k∑N(xijk−μij)(xijk−μij)T+εI
其中正则化项
ε
I
εI
εI 使样本协方差矩阵
Σ
i
j
Σij
Σij满秩且可逆。最后,通过高斯参数矩阵将每个可能的 patch 位置与如图 2 所示的多元高斯分布相关联。
我们的 Patch 嵌入向量携带来自不同语义层次的信息。因此,每一个估计的多元高斯分布 N ( µ i j , Σ i j ) N(µ_{i j}, Σ_{i j}) N(µij,Σij)也捕获了不同层次的信息,并且 Σ i j Σij Σij包含了层次间的相关性。我们通过实验表明 (V -A 节),对预先训练的 CNN 的不同语义级别之间的关系进行建模有助于提高异常定位的性能。
Inference : computation of the anomaly map
受“Modeling the distribution of normal data in pre-trained deep features for anomaly detection”与“A simple unified framework for detecting out-of-distribution samples and adversarial attacks”的启发,我们使用马氏距离 M ( x i j ) M(xij) M(xij)给测试图像位置 ( i , j ) (i, j) (i,j) 的 patch 一个异常分数。 M ( x i j ) M(x_{i j}) M(xij)可以解释为嵌入 x i j x_{i j} xij 的测试 patch 与学习分布 N ( µ i j , Σ i j ) N(µ_{i j}, Σ_{i j}) N(µij,Σij)之间的距离,其中 M ( x i j ) M(x_{i j}) M(xij)的计算公式如下:
M ( x i j ) = ( x i j − μ i j ) T Σ i j − 1 ( x i j − μ i j ) (7) \mathcal{M}\left(x_{i j}\right)=\sqrt{\left(x_{i j}-\mu_{i j}\right)^{T} \Sigma_{i j}^{-1}\left(x_{i j}-\mu_{i j}\right)} \\ \tag{7} M(xij)=(xij−μij)TΣij−1(xij−μij)(7)
因此,可以计算出构成异常图的马氏距离矩阵:
M
=
(
M
(
x
i
j
)
)
1
<
i
<
W
,
1
<
j
<
H
M=(M(x_{ij}))_{1<i<W,1<j<H}
M=(M(xij))1<i<W,1<j<H
最终整幅图像的异常得分为异常图 M 的最大值。
最后,在测试时,我们的方法不存在基于 K-NN 的方法的可伸缩性问题,因为我们不需要计算和排序大量的距离值来得到一个 Patch 的异常分数。
Experiments
Datasets and metrics
Datasets
我们首先在 MVTec AD上评估我们的模型,该模型旨在单类学习设置中,测试用于工业质量控制的异常定位算法。它包含 15 个类,大约 240 张图像。原始图像的分辨率在 700x700 到 1024x1024 之间。有 10 个对象和 5 个纹理类。对象总是在数据集中以相同的方式居中对齐,如图 1 中晶体管和胶囊类所示。除了原始数据集, 来评估性能异常定位模型在一个更现实的背景下, 我们创建一个 MVTec AD 的修改版本, 称为 RdMVTec AD, 我们应用随机旋转 (-10 + 10) 和随机作物 (从 256 x256 224 x224) 对训练集和测试集。MVTec AD 的这个修改版本可以更好地描述用于质量控制的异常定位的真实用例,其中感兴趣的对象并不总是在图像中居中和对齐。
为了进一步评估,我们还在上海理工大学 (STC) 数据集 [8] 上测试了 PaDiM,该数据集模拟了静态摄像头的视频监控。它包含 274 515 个训练和 42883 个测试帧,分为 13 个场景。原始图像的分辨率是 856x480。训练视频是由正常序列组成的,而测试视频则有异常情况,比如行人区出现车辆或人们打斗。
Metrics
为了评估定位性能,我们计算了两个阈值无关的指标。我们使用接收机工作特征曲线 (AUROC) 下的面积,其中真正的阳性率是正确分类为异常的像素的百分比。由于 AUROC 偏向于大的异常,我们也使用了每个区域重叠分数(PRO-score)。它包括为每个连接组件绘制一个正确分类的像素率的平均值曲线,该曲线是假阳性率在 0 到 0.3 之间的函数。PRO-score 是这条曲线的标准化积分。高的 PRO-score 意味着大的和小的异常都很好地定位。
Experimental setups
我们用不同的主干训练 PaDiM,ResNet18(R18),Wide ResNet-50-2(WR50)和 EfficientNet-B5,都是在 ImageNet上预先训练的。当主干为 ResNet 时,从前三层提取 Patch 嵌入向量,以组合来自不同语义层次的信息,同时保持足够高的分辨率来完成定位任务。按照这个思想,如果使用 EfficientNet-B5,我们从第 7 层 (第 2 级别)、第 20 层(第 4 级别) 和第 26 层 (第 5 级别) 提取 Patch 嵌入向量。我们还应用了随机降维(RD)(参见第 III-A 节和 V-A 节)。我们的模型名称指明了主干和所使用的降维方法(如果有的话)。例如,PaDiM-R18-RD100 是具有 ResNet18 主干的 PaDiM 模型,使用 100 个随机选择的维度用于 Patch 嵌入向量。默认情况下,我们使用 ε = 0.01 ε=0.01 ε=0.01 在方程式 1 中。
我们以 Wide ResNet-50-2(WR50)为主干,复制了原始出版物中描述的模型 SPADE。对于 Spade 和 PaDim,我们采用与中相同的前置处理。我们将图像从 MVTec AD 调整为 256x256,并将其居中裁剪为 224x224。对于来自 STC 的图像,我们仅使用 256x256 调整大小。我们使用双三次插值调整图像和定位图的大小,并像中那样对参数为σ=4 的异常图使用高斯滤波器。
我们还将我们自己的 VAE 实现为基于重建的基线,使用 ResNet18 作为编码器,并使用 8x8 卷积潜变量实现。它在每个 MVTec AD 类上使用以下数据扩充操作进行训练:随机旋转 (−2◦,+2◦),292x292 调整大小,随机裁剪到 282x282,最后中心裁剪到 256x256。该训练使用 ADAM 优化器在 100 个时段内执行,初始学习率为 1 0 − 4 10^{−4} 10−4,批大小为 32 个图像。用于定位的异常图对应于用于重建的像素 L2 误差。