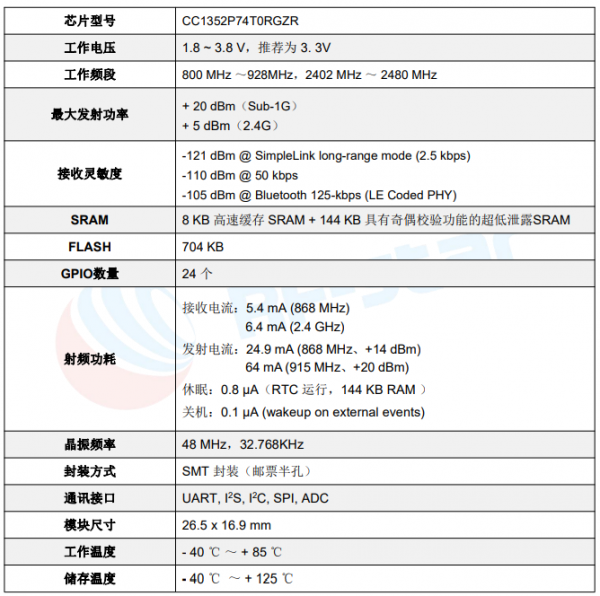
在当今的技术领域,大型语言模型的应用日益广泛,而Qwen1.5作为其中的佼佼者,已经得到了多个推理框架的支持。
原生混合精度推理
from transformers import AutoModelForCausalLM, AutoTokenizer
import torch
# 设置设备为CUDA,如果系统支持的话,并尝试开启FP16计算
device = torch.device("cuda")
model = AutoModelForCausalLM.from_pretrained(
"/root/autodl-tmp/Qwen1___5-14B-Chat",
torch_dtype=torch.float16, # 尝试使用FP16精度
device_map="auto" # 自动映射模型到可用设备
)
tokenizer = AutoTokenizer.from_pretrained("/root/autodl-tmp/Qwen1___5-14B-Chat")
# ... (此处省略了消息处理部分,这部分应保持不变)
# 将模型转换为FP16半精度模式
model.half()
# 注意:通常在转为半精度后,还需要显式地将模型移动到GPU上,但在本例中没有显示调用model.to(device),确保模型已经在CUDA设备上
# 示例提问
prompt = "Give me a short introduction to large language model."
messages = [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": prompt}
]
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
# 将输入文本编码并转换为FP16格式的张量,再将其移到GPU上
model_inputs = tokenizer([text], return_tensors="pt").to(device)
# 使用自动混合精度(AMP)进行推理
with torch.cuda.amp.autocast():
generated_ids = model.generate(
model_inputs.input_ids,
max_length=512,
output_scores=False # 是否返回得分,这里设为False
)
# 提取生成的文本ID
generated_ids = [
output_ids[len(input_ids):] for input_ids, output_ids in zip(model_inputs.input_ids, generated_ids)
]
# 解码生成的文本ID,跳过特殊标记
response = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
print(response)
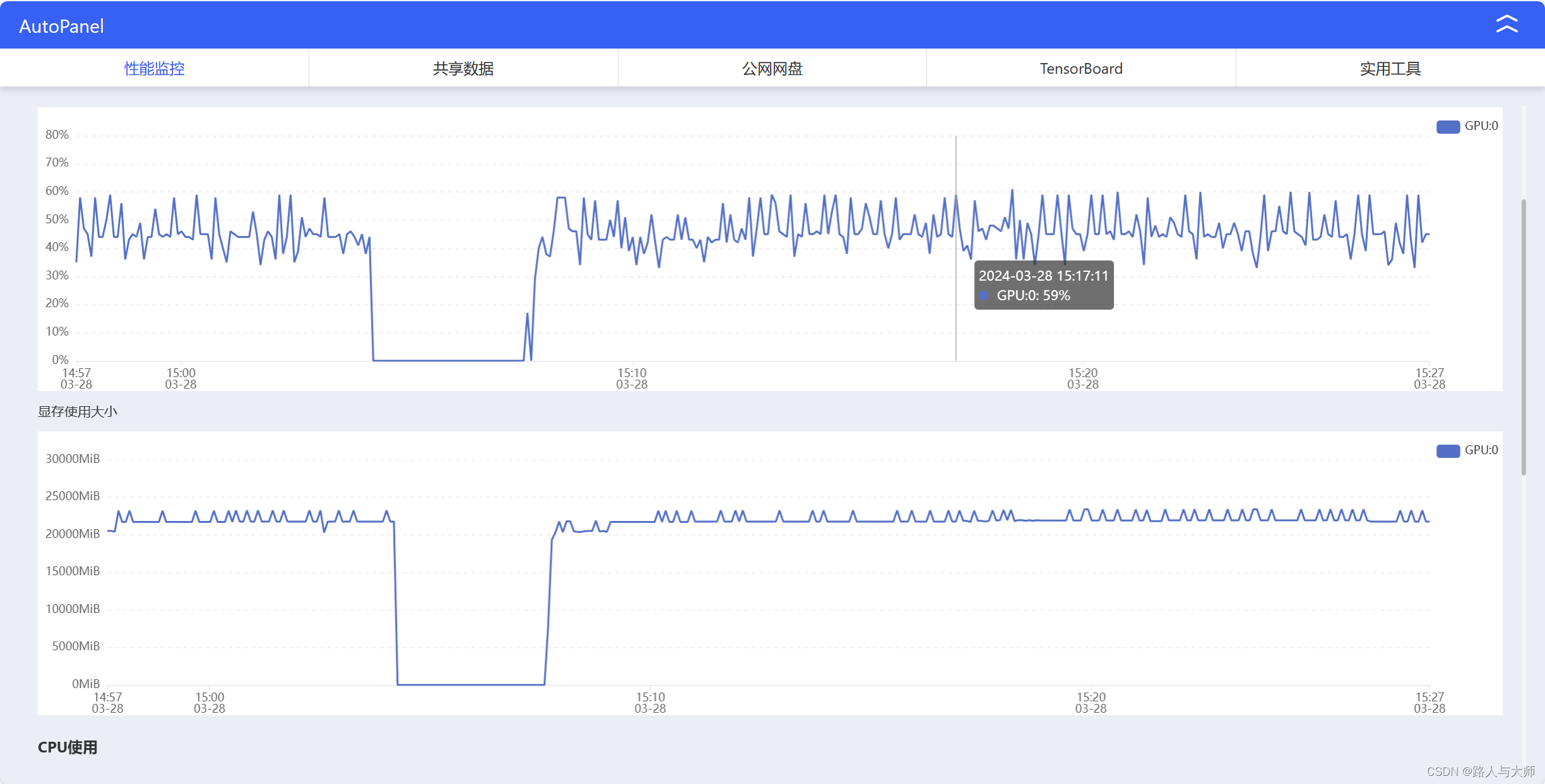
原生混合推理速度及资源占用
速度
资源占用
本文将向大家介绍如何使用vLLM和SGLang这两个框架来部署和使用Qwen1.5。
vLLM部署
首先,我们建议使用vLLM的0.3.0或更高版本来构建与OpenAI兼容的API服务。启动服务器时,选择一个聊天模型,例如Qwen1.5-7B-Chat:
python -m vllm.entrypoints.openai.api_server --served-model-name Qwen1.5-7B-Chat --model Qwen/Qwen1.5-7B-Chat
然后,你可以使用如下所示的聊天API:
curl http://localhost:8000/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "Qwen1.5-7B-Chat",
"messages": [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Tell me something about large language models."}
]
}'
在Python中,可以像这样使用:
from openai import OpenAI
# 设置OpenAI的API密钥和API基础地址以使用vLLM的API服务器。
openai_api_key = "EMPTY"
openai_api_base = "http://localhost:8000/v1"
client = OpenAI(
api_key=openai_api_key,
base_url=openai_api_base,
)
chat_response = client.chat.completions.create(
model="Qwen1.5-7B-Chat",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Tell me something about large language models."},
]
)
print("Chat response:", chat_response)
SGLang部署
请从源代码安装SGLang。与vLLM类似,你需要启动一个服务器并使用与OpenAI兼容的API服务。首先启动服务器:
python -m sglang.launch_server --model-path Qwen/Qwen1.5-7B-Chat --port 30000
在Python中,你可以这样使用:
from sglang import function, system, user, assistant, gen, set_default_backend, RuntimeEndpoint
@function
def multi_turn_question(s, question_1, question_2):
s += system("You are a helpful assistant.")
s += user(question_1)
s += assistant(gen("answer_1", max_tokens=256))
s += user(question_2)
s += assistant(gen("answer_2", max_tokens=256))
set_default_backend(RuntimeEndpoint("http://localhost:30000"))
state = multi_turn_question.run(
question_1="What is the capital of China?",
question_2="List two local attractions.",
)
for m in state.messages():
print(m["role"], ":", m["content"])
print(state["answer_1"])
通过上述步骤,你可以轻松地使用vLLM和SGLang来部署和使用Qwen1.5。无论是进行聊天对话还是复杂的多轮问答,Qwen1.5都能提供高质量的语言模型服务。随着技术的不断进步,我们有理由相信,Qwen1.5将在更多领域大放异彩。