首先认识邻接表,两种写法一种原始写法相当复杂,一种二维vector写法稍简单,邻接表,意思就是,该节点的下一个节点有哪些.
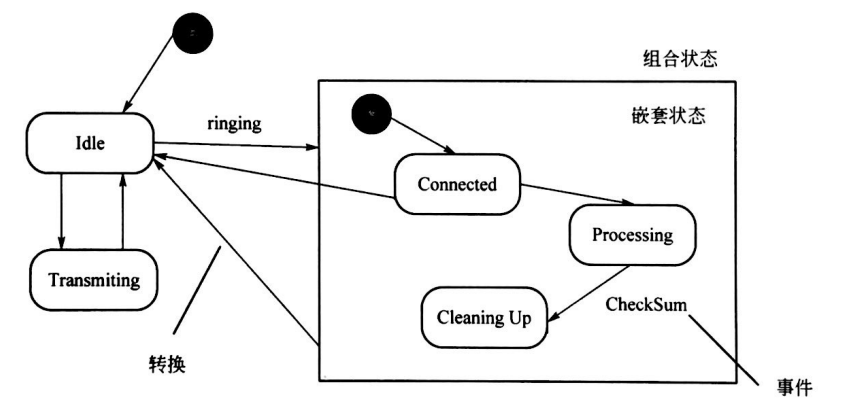
首先来看原始写法,记住下面这张图

可以看到这就是原始的邻接表,我们需要三个数组,终点数组e[],上一条边的索引位置fr[],和辅助数组h[],h[i]表示上一条i为起点的边的索引,所以我们先从h数组开始讲起,首先在没有任何边的情况下,h中所有的值都需要设置为-1(这里是重点,我没有写出来,你在创建h的时候,要将h的所有值都设为-1),表示没有上一条i为起点的边的索引可记录,然后我们来讲一下在add_edge函数中我们要怎么写.
int e[M],fr[M],h[N],cnt=0;
void add_edge(int u,int v){
e[cnt]=v;
fr[cnt]=h[u]
h[u]=cnt;
cnt++;
}首先将终点赋值给e,将上一条以u为起点的边的索引赋值给fr,此时最后一条以u为起点的边的索引就是当前边cnt,所以把h[u]=cnt,然后cnt++,新开一条空边.
那么该如何遍历呢.
//选择一个起点t
for(int i=h[t];i!=-1;i=fr[i]){
}以上是第一种写法,接下来看第二种写法,非常简单,
std::vector<std::vector<int>>adj(n + 1);
//添加边,i表示以节点i为起点的边
adj[i].push_back(x);
//遍历,选择一个起点t
for (int i = 0; i < adj[t].size(); i++) {
int j = adj[t][i];
d[j]--;
if (d[j] == 0)q.push(j);
}效果相同,但我感觉简单的会有些许弊端,暂时不知道是不是这样,使用时谨慎选择.
接下来我们来讲拓扑排序,首先要知道一个概念,入度和出度,入度就是指向该节点的边有多少条,出度就是指出去的边有多少条,拓扑排序中我们要使用入度这个概念,并用一个d[]数组来存储它,在拓扑排序中,我使用了第二种邻接表书写方式.
首先拓扑排序的题目中肯定会告诉你由某个节点指向另一个节点的边,我们以一道题目为例子【模板】拓扑排序 / 家谱树 - 洛谷
在这个题目中,我们在存边的同时要对入度进行操作从i指向x,所以x的入度要++
for (int i = 1; i <= n; i++) {
int x;
while (std::cin >> x && x != 0) {
adj[i].push_back(x);
d[x]++;
}
}拓扑排序第二步,找到入度为0的所有节点并放入队列中
std::queue<int>q;
for (int i = 1; i <= n; i++) {
if (!d[i]) {
q.push(i);
}
}拓扑排序第三步,使用bfs找出答案,首先我们拿出入度为0的节点,并将他们放到ans当中,以t作为起始节点,遍历它的邻接节点,同时将入度--,如果它的入度也为0了,就把它放到队列中.最后得到一个ans数组,如果数组大小为n说明排序成功了.
while (!q.empty()) {
int t = q.front();
q.pop();
ans.push_back(t);
for (int i = 0; i < adj[t].size(); i++) {
int j = adj[t][i];
d[j]--;
if (d[j] == 0)q.push(j);
}
}