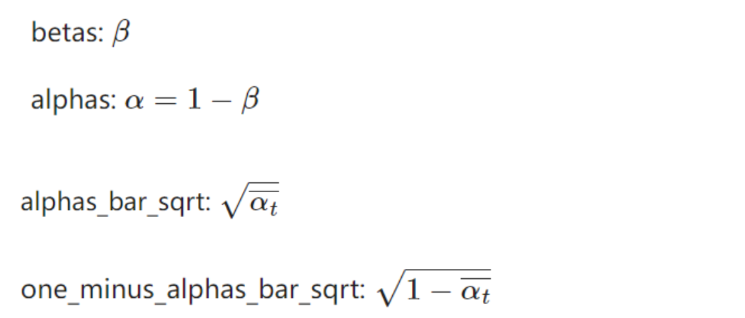TensorRT的两种INT8量化方式: QTA, PTQ
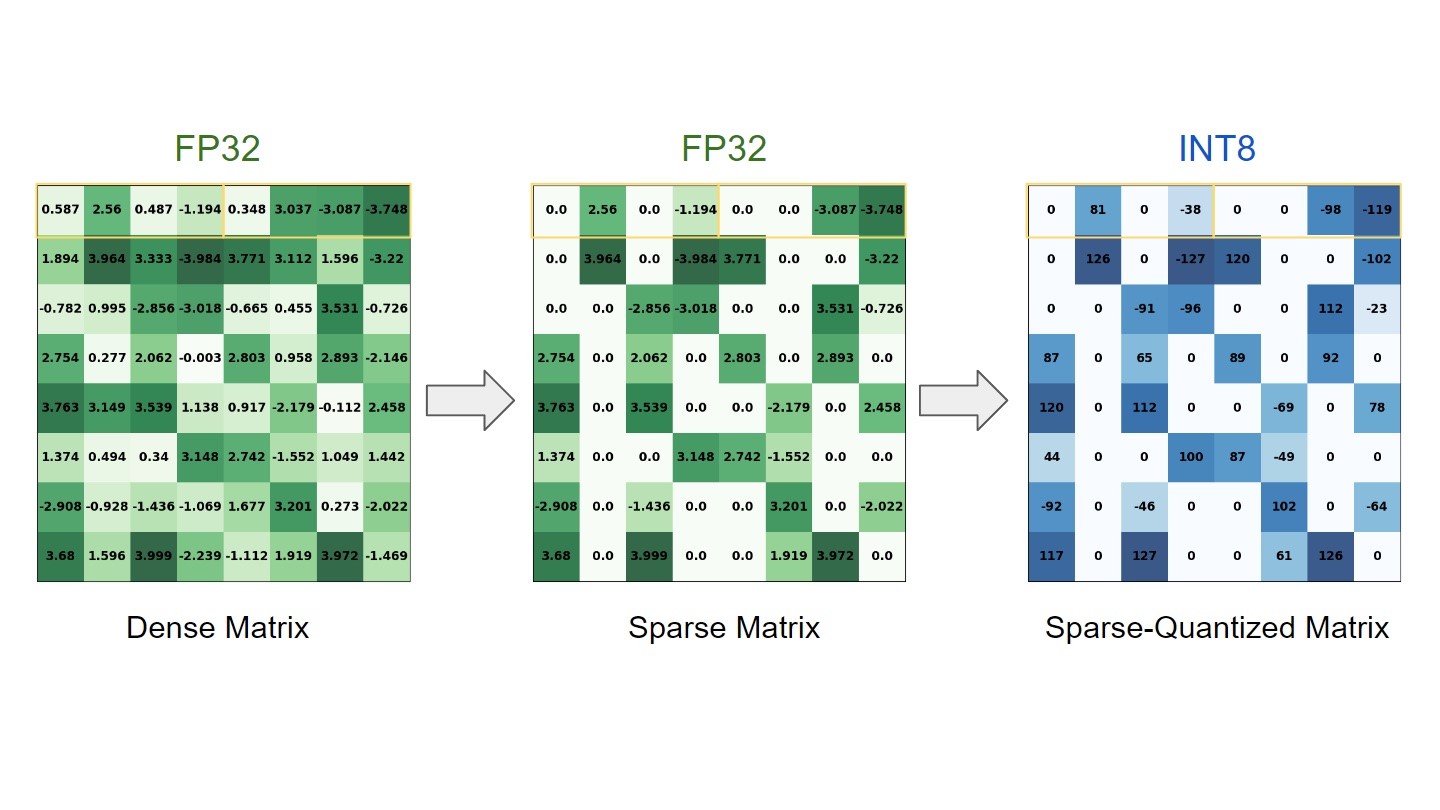
深度学习 (DL) 模型的训练阶段包括学习大量密集的浮点权重矩阵,这导致推理过程中需要进行大量的浮点计算。 研究表明,可以通过强制某些权重为零来跳过其中许多计算,而对最终精度的影响很小。
与此同时,之前的帖子表明较低的精度(例如 INT8)通常足以在推理过程中获得与 FP32 相似的精度。 稀疏性和量化是流行的优化技术,用于解决这些问题,缩短推理时间并减少内存占用。
NVIDIA TensorRT 已经提供量化支持一段时间(从 2.1 版本开始),并且最近在 NVIDIA Ampere 架构 Tensor Cores 中内置了对稀疏性的支持,并在 TensorRT 8.0 中引入。
这篇文章是关于如何使用稀疏性和量化技术使用 TensorRT 加速 DL 模型的分步指南。 尽管已经单独讨论了这些优化中的每一个,但仍然需要展示从训练到使用 TensorRT 部署的端到端工作流,同时考虑这两种优化。
在这篇文章中,我们旨在弥合这一差距并帮助您了解稀疏量化训练工作流程是什么样的,就 TensorRT 加速方面的稀疏性最佳实践提出建议,并展示 ResNet-34 的端到端案例研究.
结构稀疏
NVIDIA 稀疏张量核心使用 2:4 模式,这意味着四个值的每个连续块中的两个必须为零。 换句话说,我们遵循 50% 的细粒度结构化稀疏度配方,由于直接在 Tensor Core 上提供可用支持,因此不会对零值进行任何计算。 这导致在相同的时间内计算更多的工作量。 在这篇文章中,我们将此过程称为修剪。
有关详细信息,请参阅使用 NVIDIA Ampere 架构和 NVIDIA TensorRT 通过稀疏性加速推理。
量化
量化是指将连续的无限值映射到一组有限的离散值(例如,FP32 到 INT8)的过程。 这篇文章中讨论了两种主要的量化技术:
- 训练后量化 (PTQ):使用隐式量化工作流程。 在隐式量化网络中,每个量化张量都有一个关联的标度,用于通过校准对值进行隐式量化和反量化。 然后 TensorRT 检查该层运行速度更快的精度并相应地执行它。
- 量化感知训练 (QAT):使用显式量化工作流程。 显式量化网络利用量化和反量化 (Q/DQ) 节点来明确指示必须量化哪些层。 这意味着您可以更好地控制在 INT8 中运行哪些层。 有关详细信息,请参阅 Q/DQ 层布局建议。
有关量化基础知识、PTQ 和 QAT 量化技术之间的比较、何时选择哪种量化的见解以及 TensorRT 中的量化的更多信息,请参阅使用 NVIDIA TensorRT 的量化感知训练实现 INT8 推理的 FP32 精度。
在 TensorRT 中部署稀疏量化模型的工作流程
在 TensorRT 中部署稀疏量化模型的工作流程,以 PyTorch 作为 DL 框架,有以下步骤:
- 在 PyTorch 中对预训练的密集模型进行稀疏化和微调。
- 通过 PTQ 或 QAT 工作流程量化稀疏化模型。
- 在 TensorRT 中部署获得的稀疏 INT8 引擎。
下图显示了所有三个步骤。 步骤 2 中的一个区别是 Q/DQ 节点存在于通过 QAT 生成的 ONNX 图中,但在通过 PTQ 生成的 ONNX 图中不存在。 有关详细信息,请参阅使用 INT8。
鉴于此,这是 QAT 的完整工作流程:
- 在 PyTorch 中对预训练的密集模型进行稀疏化和微调。
- 在 PyTorch 中量化、校准和微调稀疏模型。
- 将 PyTorch 模型导出到 ONNX。
- 通过 ONNX 生成 TensorRT 引擎。
- 在 TensorRT 中部署获得的 Sparse INT8 引擎。
另一方面,这是 PTQ 的完整工作流程:
- 在 PyTorch 中对预训练的密集模型进行稀疏化和微调。
- 将 PyTorch 模型导出到 ONNX。
- 通过 TensorRT 构建器对稀疏化的 ONNX 模型进行校准和量化,生成 TensorRT 引擎。
- 在 TensorRT 中部署获得的稀疏 INT8 引擎。

案例研究:ResNet-34
本节演示了使用 ResNet-34 的稀疏量化工作流程的案例研究。 有关详细信息,请参阅 /SparsityINT8 GitHub 存储库中的完整代码示例。
要求
以下是完成此案例研究所需的基本配置:
- Python 3.8
- PyTorch 1.11 (also tested with 2.0.0)
- PyTorch vision
- apex sparsity toolkit
- pytorch-quantization toolkit
- TensorRT 8.6
- Polygraphy
- ONNX opset>=13
- NVIDIA Ampere architecture GPU for Tensor Core support
本案例研究需要使用 ImageNet 2012 数据集进行图像分类。 有关下载数据集并将其转换为所需格式的更多信息,请参阅 GitHub 存储库上的自述文件。
稀疏训练、稀疏 QAT 模型微调和稀疏 PTQ 模型校准需要此数据集。 它还用于评估模型。
第 1 步:从密集模型中进行稀疏化和微调
加载预训练的密集模型并增强模型和优化器以进行稀疏训练。 有关详细信息,请参阅 NVIDIA/apex/tree/master/apex/contrib/sparsity 文件夹。
import copy
from torchvision import models
from apex.contrib.sparsity import ASP
# Load dense model
model_dense = models.__dict__["resnet34"](pretrained=True)
# Initialize sparsity mode before starting sparse training
model_sparse = copy.deepcopy(model_dense)
ASP.prune_trained_model(model_sparse, optimizer)
# Re-train model
for e in range(0, epoch):
for i, (image, target) in enumerate(data_loader):
image, target = image.to(device), target.to(device)
output = model_sparse(image)
loss = criterion(output, target)
optimizer.zero_grad()
loss.backward()
optimizer.step()
# Save model
torch.save(model_sparse.state_dict(), "sparse_finetuned.pth")
第 2 步:量化 PyTorch 模型
您可以为此步骤选择两种量化方法:PTQ 或 QAT。
PTQ 通过 TensorRT 校准
此选项将 PyTorch 模型导出到 ONNX 并通过 TensorRT Python API 对其进行校准。 这会生成校准缓存和准备部署的 TensorRT 引擎。
将稀疏 PyTorch 模型导出到 ONNX:
dummy_input = torch.randn(batch_size, 3, 224, 224, device="cuda")
torch.onnx.export(model_sparse, dummy_input, "sparse_finetuned.onnx", opset_version=13, do_constant_folding=True)
使用校准数据集校准在上一步中导出的 ONNX 模型。 以下代码示例假定 ONNX 模型具有静态输入形状和批量大小。
from infer_engine import infer
from polygraphy.backend.trt import Calibrator, CreateConfig, EngineFromNetwork, NetworkFromOnnxPath, TrtRunner, SaveEngine
from polygraphy.logger import G_LOGGER
# Data loader argument to `Calibrator`
def calib_data(val_batches, input_name):
for iteration, (images, labels) in enumerate(val_batches):
yield {input_name: images.numpy()}
# Set path to ONNX model
onnx_path = "sparse_finetuned.onnx"
# Set calibrator
calibration_cache_path = onnx_path.replace(".onnx", "_calibration.cache")
calibrator = Calibrator(
data_loader=calib_data(data_loader_calib, args.onnx_input_name),
cache=calibration_cache_path
)
# Build engine from ONNX model by enabling INT8 and sparsity weights, and providing the calibrator
build_engine = EngineFromNetwork(
NetworkFromOnnxPath(onnx_path),
config=CreateConfig(
int8=True,
calibrator=calibrator,
sparse_weights=True
)
)
# Trigger engine saving
engine_path = onnx_path.replace(".onnx", ".engine")
build_engine = SaveEngine(build_engine, path=engine_path)
# Calibrate engine (activated by the runner)
with G_LOGGER.verbosity(G_LOGGER.VERBOSE), TrtRunner(build_engine) as runner:
print("Calibrated engine!")
# Infer PTQ engine and evaluate its accuracy
log_file = engine_path.split("/")[-1].replace(".engine", "_accuracy.txt")
infer(
engine_path,
data_loader_test,
batch_size=args.batch_size,
log_file=log_file
)
QAT 通过 pytorch-quantization 工具包
此选项使用 pytorch-quantization 工具包在稀疏 PyTorch 模型中添加 Q/DQ 节点,对其进行校准,并对其进行微调几个 epoch。 然后将微调后的模型导出到 ONNX 并转换为 TensorRT 引擎进行部署。
为确保已计算的稀疏浮点权重不会被覆盖,确保 QAT 权重也将结构化为稀疏,您必须再次准备模型进行剪枝。
在加载微调的稀疏权重之前初始化 QAT 模型和优化器以进行修剪。 稀疏掩码重新计算也必须禁用,因为它们已经在步骤 1 中计算过。这需要一个自定义函数,该函数是对 APEX 工具包的 prune_trained_model 函数的轻微修改。 修改在代码示例中突出显示:
from apex.contrib.sparsity import ASP
def prune_trained_model_custom(model, optimizer, compute_sparse_masks=False):
asp = ASP()
asp.init_model_for_pruning(model, mask_calculator="m4n2_1d", verbosity=2, whitelist=[torch.nn.Linear, torch.nn.Conv2d], allow_recompute_mask=False)
asp.init_optimizer_for_pruning(optimizer)
if compute_sparse_masks:
asp.compute_sparse_masks()
为了优化 Q/DQ 节点放置,您必须修改模型的定义以量化残差分支,如 pytorch-quantization 工具包示例所示。 例如,对于ResNet,需要在残差分支中添加Q/DQ节点的修改突出显示如下:
from pytorch_quantization import nn as quant_nn
class BasicBlock(nn.Module):
def __init__(self, ..., quantize: bool = False) -> None:
super().__init__()
...
if self._quantize:
self.residual_quantizer = quant_nn.TensorQuantizer(quant_nn.QuantConv2d.default_quant_desc_input)
def forward(self, x: Tensor) -> Tensor:
identity = x
...
if self._quantize:
out += self.residual_quantizer(identity)
else:
out += identity
out = self.relu(out)
return out
必须对 Bottleneck 类重复相同的修改,并且必须通过 ResNet、_resnet 和 resnet34 函数传播量化 bool 参数。 完成这些修改后,使用 quantize=True 实例化模型。 有关详细信息,请参阅 resnet.py 中的第 734 行。
通过 QAT 量化稀疏模型的第一步是在模型中启用量化和剪枝。 第二步是加载微调的稀疏检查点,对其进行校准,然后最后对该模型进行一些 epoch 的微调。 有关 collect_stats 和 compute_amax 函数的更多信息,请参阅 calibrate_quant_resnet50.ipynb。
# Add Q/DQ nodes to the dense model
from pytorch_quantization import quant_modules
quant_modules.initialize()
model_qat = models.__dict__["resnet34"](pretrained=True, quantize=True)
# Initialize sparsity mode before starting Sparse-QAT fine-tuning
prune_trained_model_custom(model_qat, optimizer, compute_sparse_masks=False)
# Load Sparse weights
load_dict = torch.load("sparse_finetuned.pth")
model_qat.load_state_dict(load_dict["model_state_dict"])
# Calibrate model
collect_stats(model_qat, data_loader_calib, num_batches=len(data_loader_calib))
compute_amax(model_qat, method="entropy”)
# Fine-tune model
for e in range(0, epoch):
for i, (image, target) in enumerate(data_loader):
image, target = image.to(device), target.to(device)
output = model_qat(image)
...
# Save model
torch.save(model_qat.state_dict(), "quant_finetuned.pth")
要准备部署 TensorRT 引擎,您必须将稀疏量化 PyTorch 模型导出到 ONNX。 TensorRT 期望 QAT ONNX 模型指示哪些层应该通过一组 QuantizeLinear 和 DequantizeLinear ONNX 操作进行量化。 在将量化的 PyTorch 模型导出到 ONNX 时,通过启用伪量化来满足此要求。
from pytorch_quantization import nn as quant_nn
quant_nn.TensorQuantizer.use_fb_fake_quant = True
dummy_input = torch.randn(batch_size, 3, 224, 224, device="cuda")
torch.onnx.export(model_qat, dummy_input, "quant_finetuned.onnx", opset_version=13, do_constant_folding=True)
最后,构建 TensorRT 引擎:
$ trtexec --onnx=quant_finetuned.onnx --int8 --sparsity=enable --saveEngine=quant_finetuned.engine --skipInference
第三步:部署TensorRT引擎
$ trtexec --loadEngine=quant_finetuned.engine -v
结果
以下是在配备 TensorRT 8.6-GA (8.6.1.6) 的 NVIDIA A40 GPU 上针对 ResNet-34 密集量化和稀疏量化模型在分类精度和运行时方面的性能测量。 要重现这些结果,请遵循上一节中描述的工作流程。
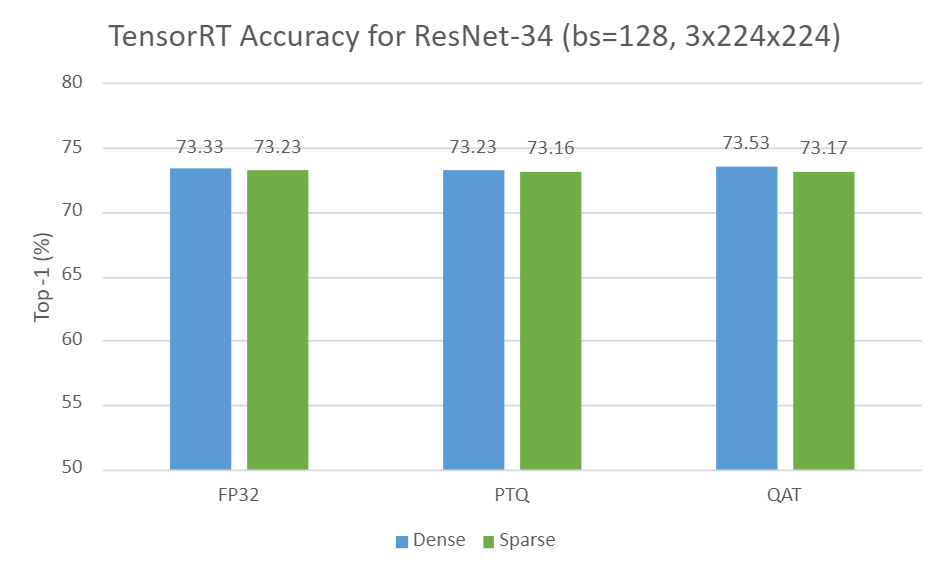
下图显示了 TensorRT 中 ResNet-34 在三种设置下的密集精度与稀疏精度的比较:
- FP32 中的密集与稀疏
- INT8 中的密集 PTQ 与稀疏 PTQ
- INT8 中的密集 QAT 与稀疏 QAT
如您所见,与所有设置的密集变体相比,稀疏变体在很大程度上可以保持准确性。


![[2021]Zookeeper getAcl命令未授权访问漏洞概述与解决](https://img-blog.csdnimg.cn/20210414200901464.png)