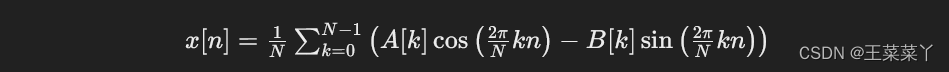无监督图像拼接中的学习逐像素对齐
Jia, Q., Feng, X., Liu, Y., Fan, X., & Latecki, L. J. (2023, October). Learning pixel-wise alignment for unsupervised image stitching. In Proceedings of the 31st ACM International Conference on Multimedia (pp. 1392-1400).
0. 摘要
图像拼接旨在对同一视图中的一对图像进行对齐。对于图像拼接来说,生成具有自然结构的精确对齐是一个挑战,因为在非共面的实际场景中,没有更宽视场图像作为参考。在本文中,我们提出了一个无监督图像拼接框架,突破了单应性估计中的共面约束,实现了在有限重叠区域下的精确像素级对齐。首先,我们通过迭代密集特征匹配结合误差控制策略来生成全局变换,以减轻由大视差引入的差异。其次,我们提出了一个嵌入在大规模特征提取器和相关特征增强模块中的像素级变形网络,以显式学习输入之间的对应关系,并在新颖的约束下生成精确的像素级偏移,这些约束既适用于重叠区域也适用于非重叠区域。值得注意的是,我们利用重叠区域中的像素级偏移来引导非重叠区域的调整,根据内容和结构一致性约束,使得两个区域之间实现自然过渡,并在整个拼接图像中抑制畸变。所提出的方法在性能上达到了最先进的水平,大幅超越了传统和深度学习方法。它还实现了最短的执行时间,并在传统数据集上具有最佳的泛化能力。
1. 引言
图像拼接旨在估计一对图像之间的准确变换并将它们对齐到同一视图中。这是一个经过深入研究的主题,具有广泛的应用,例如智能手机上的全景图[42]、机器人导航[7]和虚拟现实[1, 18]。然而,在各种实际场景中生成高质量的拼接图像仍然具有挑战性,特别是当没有更宽视场图像作为参考时。

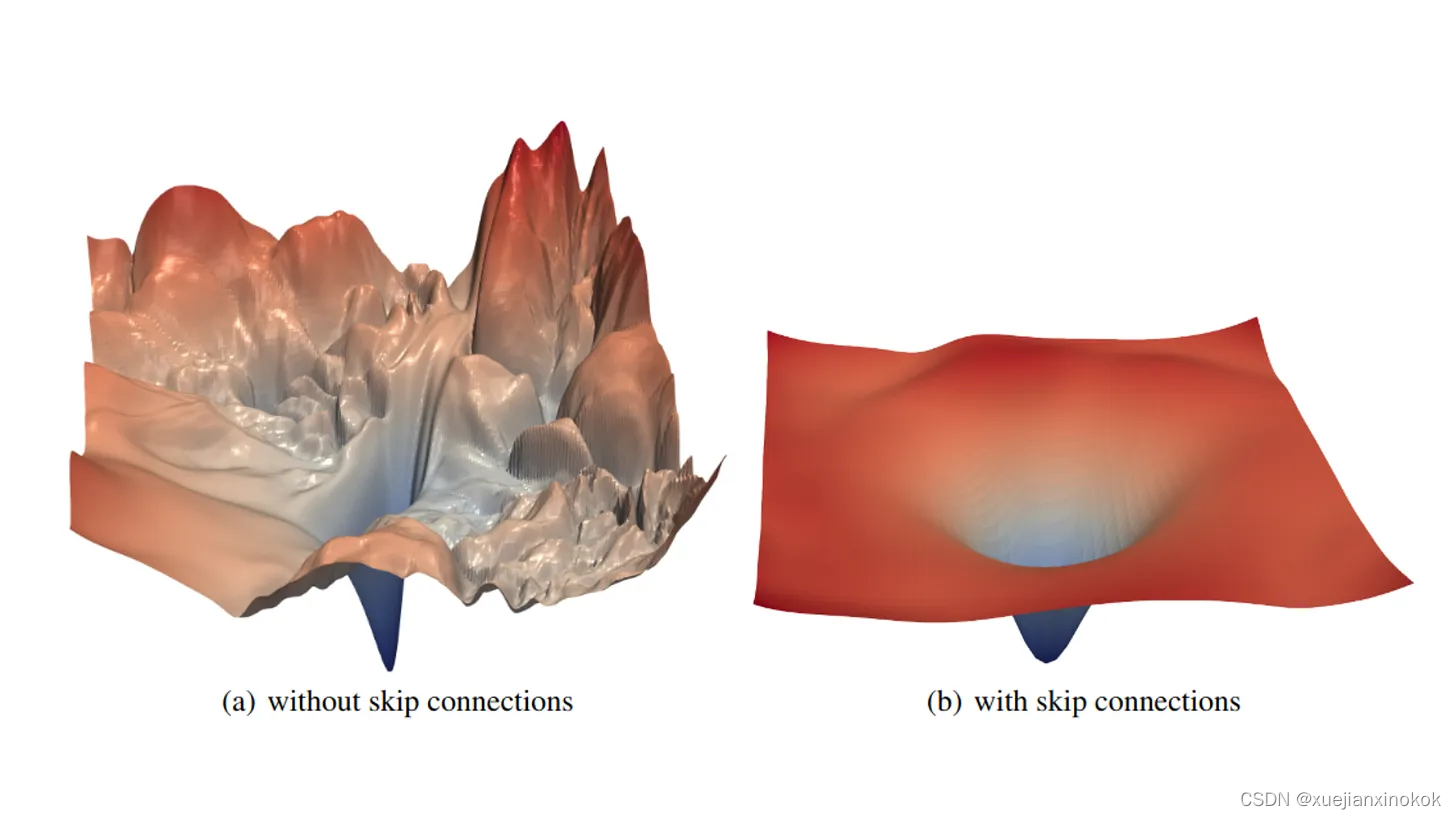
单应性变换[5, 9, 44]是最广泛使用的图像拼接模型,它利用重叠区域中的特征相关性作为约束来估计全局单应性矩阵[30],并将整个目标图像变换到参考图像的视图中(参见图1(a)中的全局变形部分)。大多数现有方法通过假设整个场景是共面的来估计全局单应性,导致拼接结果中的严重错位和伪影[30],如图1(b)的放大区域所示。然而,理论上,单应性变换仅适用于共面场景,而在实践中几乎不存在。因此,传统[3, 12, 20, 21, 25]和深度学习方法[6, 28, 45]都致力于寻找近似解决方案以获得准确的对齐。为了减少非共面对单应性估计的影响,一些工作将图像划分为多个均匀块作为近似共面区域来计算多个单应性变换,例如传统的双单应性变形(DHW)[12]和尽可能投影的多单应性方法(APAP)[43]。然而,基于现有单应性估计的方法至少有三个主要限制:(1)全局或划分的图像块没有共面保证,这只是一个近似解决方案;(2)全局对齐估计整个图像的单个或有限数量的单应性变换,这对于实现像素级准确对齐是不够的,如图1(a)所示;(3)没有真实的拼接结果作为参考,这对于训练深度学习方法是一个挑战。因此,实现每个像素的非均匀对齐至关重要。
相比之下,现有的像素级对齐方法仅适用于几乎完全重叠的图像对,例如医学图像配准[46]或连续视频帧之间的配准[13]。 它们通过从整幅图像中搜索图像对之间的特征相关性来估计整幅图像在低分辨率下的像素级偏移。 与图像配准不同,图像拼接具有有限的重叠区域和大视差,在无监督框架中缺乏对非重叠区域的约束。 因此,现有的图像配准方法不能对非重叠区域产生正确的偏移,并且不能输出整个图像的拼接结果。此外,图像配准采用全局特征匹配策略,容易在图像拼接的有限重叠区域中引入不匹配的特征。
在本文中,我们提出了一个粗到细的无监督图像拼接网络,以实现像素级对齐。首先,我们估计一个全局单应性来处理大规模视点变化,为输入图像对提供统一的对齐。其次,我们探索纹理和几何一致性约束,以在重叠区域内实现非均匀的像素级对齐。此外,我们利用重叠区域来引导非重叠区域在内容和结构上的一致性,以调整整个拼接图像的对齐。我们的方法在拼接图像上展示了有希望的性能,如图1(c)的放大区域所示,呈现更少的伪影和错位。大量的定性和定量结果验证了所提出方法的有效性。我们的贡献是三方面的:
• 我们提出了一个粗到细的无监督图像拼接框架,从均匀变换开始,逐步过渡到各向异性的像素级偏移,首次突破了单一单应性共面约束。
• 我们设计了一个重叠区域引导的像素级变形网络,具有大规模特征提取器和相关特征增强模块,以捕捉像素级对应关系,通过高分辨率偏移实现准确对齐。
• 我们利用重叠区域的像素级对齐来引导非重叠区域的无监督调整,保持整个拼接图像在有限重叠区域条件下的一致结构和内容。
我们的方法在所有具有视觉优势的拼接结果的挑战性数据集上大幅超越了传统和深度学习的最新方法,并且执行时间最短。特别是,与现有最佳方法[21]相比,平均对齐误差降低了34.42%。第3节和第4节详细阐述了我们的贡献。
2. 相关工作
传统图像拼接方法。传统图像拼接方法通常通过匹配锚点来估计最优的全局变换。SIFT [26] 和 SURF [2] 广泛用于检测和匹配特征点,随后使用随机样本一致性(RANSAC)[10] 来估计图像对的单应性。由于单一单应性变换仅适用于理想的共面场景,一些方法尝试为不同的非共面区域提供自适应的变形方案[3, 12, 20, 25]。然而,对于大视差图像,仍然会出现不希望的畸变。为了减少有限单应性估计引入的畸变和伪影,APAP [43] 估计多个块的单应性,以覆盖不同区域的变形。随后,Liao等人[24]提出了单视图变形(SPW),利用点和线对作为锚点。Jia等人[17]考虑了线-点对(LPC)的局部共面关系,利用匹配线-点对的共面性来对齐图像,同时抑制非重叠区域的畸变。此外,Du等人[8]提出了一种几何结构保持拼接方法(GES-GSP)。然而,参数设置对这些传统方法有严重影响,使它们对视差变化敏感。特别是,传统方法需要高计算复杂度来检测和匹配特征,而在匹配特征数量有限时容易失败。
基于深度学习的图像拼接方法。与传统方法相比,基于深度学习的方法在单应性估计上更具适应性,因为卷积神经网络的强大的表示学习能力可以在低纹理图像中产生密集匹配特征[14, 35]。此外,基于深度学习的单应性估计在合成图像[6, 29, 31]或小视差数据集[45]上取得了有利的结果。然而,合成图像仍然假设整个场景是共面的,这在现实中几乎不存在。
由于没有真实的拼接图像作为真值,一些方法采用内部或外部约束来减少大视差真实场景中的畸变和伪影。外部约束与相机的固定相对位置有关,广泛应用于自动驾驶[19, 40]和视频监控[22]。内部约束指的是图像对之间的特征相关性。基于此,提出了一个无监督图像拼接框架(UDIS)[30],该框架采用DLT产生全局单应性,然而,这些现有方法仍在共面假设下运行,这导致了由于统一对齐而产生的伪影和畸变。与它们不同,我们提出的无监督图像对齐框架通过估计像素级偏移来解决问题,为现实中的非共面场景提供了各向异性的准确对齐。
图像配准。图像配准主要应用于具有大面积重叠的两个图像的非刚性对齐。图像变形被视为物体的运动,通过计算每个像素的瞬时速度场来估计配准的位移场[15]。在[13, 34, 39, 46]中,提出了光流来以监督方式对齐视频相邻帧。然而,密集位移场的估计在大视差情况下容易失败[37]。因此,由于重叠区域的巨大差异以及非重叠区域缺乏约束,无法将密集流场应用于图像拼接。与以前的方法相比,我们利用重叠区域的对齐来引导非重叠区域的对齐,为整个拼接图像提供了一致的结构和纹理。
3. 像素级图像拼接
我们提出的图像拼接流程如图2所示。首先,给定一对目标图像和参考图像
,我们通过迭代方式估计全局单应性
来进行统一的预对齐,以减少大视差的影响(第3.1节)。在预对齐的图像
的基础上,我们设计了一个非均匀对齐网络,该网络探索图像特征的相关性并生成像素级对齐图像
(第3.2节)。为了实现整个拼接图像的结构和纹理一致性,我们通过加权掩码为重叠区域和非重叠区域提出了一系列约束(第3.3节)。最后,我们在U-Net结构上引入空间和通道注意力机制[11]作为混合模块,以调整来自不同视点的图像的亮度和颜色。
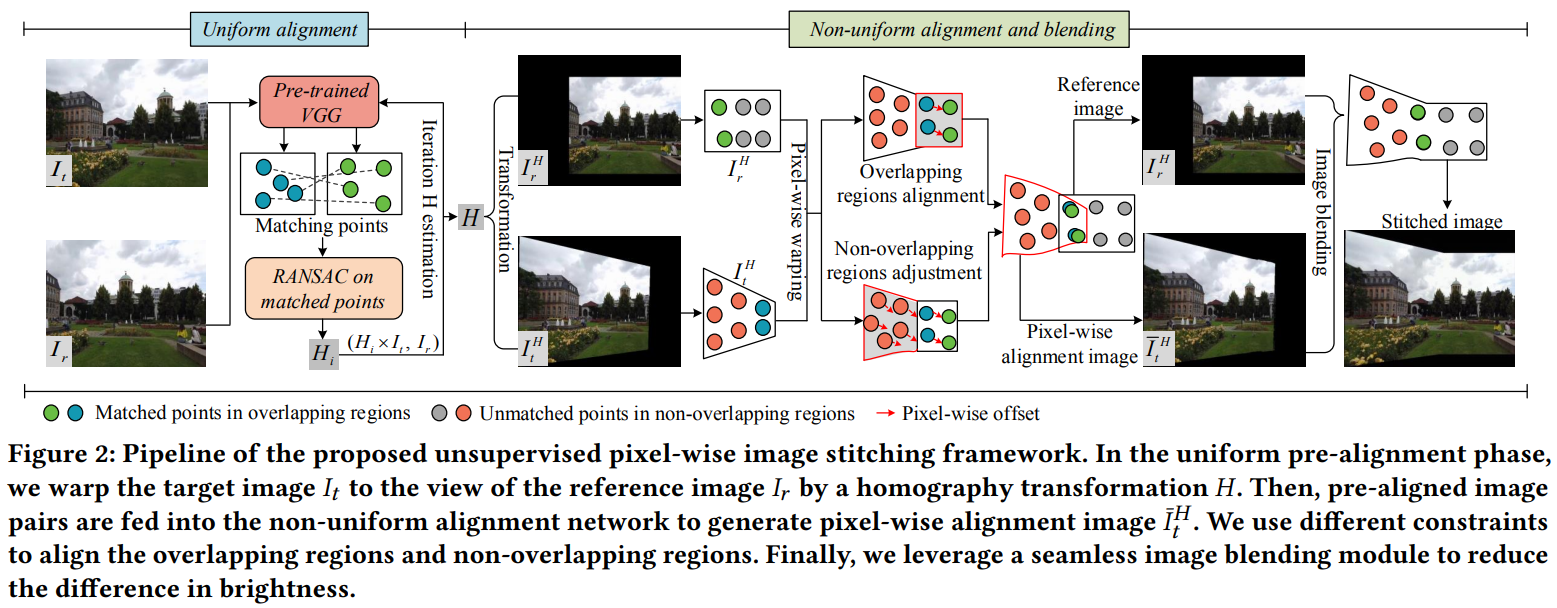
3.1 通过单应性进行统一的预对齐
我们利用预训练的VGG模型[36]来提取和匹配不同层中的密集特征[9],并定义了一个结合RANSAC的错误评估指标,以迭代执行特征匹配和全局单应性估计,如图2中的统一对齐所示。为了保留原始图像的线性和纹理结构,我们使用相似性变换矩阵来控制单应性变换过程中的畸变。我们通过目标图像在变形前后的四个对应角点来估计相似性矩阵。我们通过计算单应性变换
与其最佳拟合相似性变换
的偏差来衡量畸变。设
为目标图像的四个角点,
。误差指标
通过公式(1)计算:
其中,是
次迭代中估计的单应性矩阵。当
小于阈值(我们论文中为0.01)时,迭代停止,对于大多数图像对,通常在三次迭代内停止。预对齐是一个有效的过程,可以减少图像对的视差,使得后续的像素级变形更加准确。
3.2 非均匀对齐以实现像素级偏移
基于第3.1节,设计了各向异性对齐网络来细化整个图像的像素级偏移,如图3所示。我们的输入图像包括整个预对齐图像,以及重叠区域的图像
。首先,我们使用特征提取器
来获取输入图像的特征。随后,使用相关特征增强模块
来增加重叠区域的权重,增强后的特征输入到相关性计算模块
中以计算特征相关性。最后,像素级偏移估计模块输出最终的对齐结果。下面,我们将详细阐述每个模块的设计。
特征提取器。为了获得高分辨率的像素级偏移,我们设计了三个级联的卷积层来输出大尺度的特征图。我们使用残差块和卷积核来增加卷积过程中的感受野[34]。
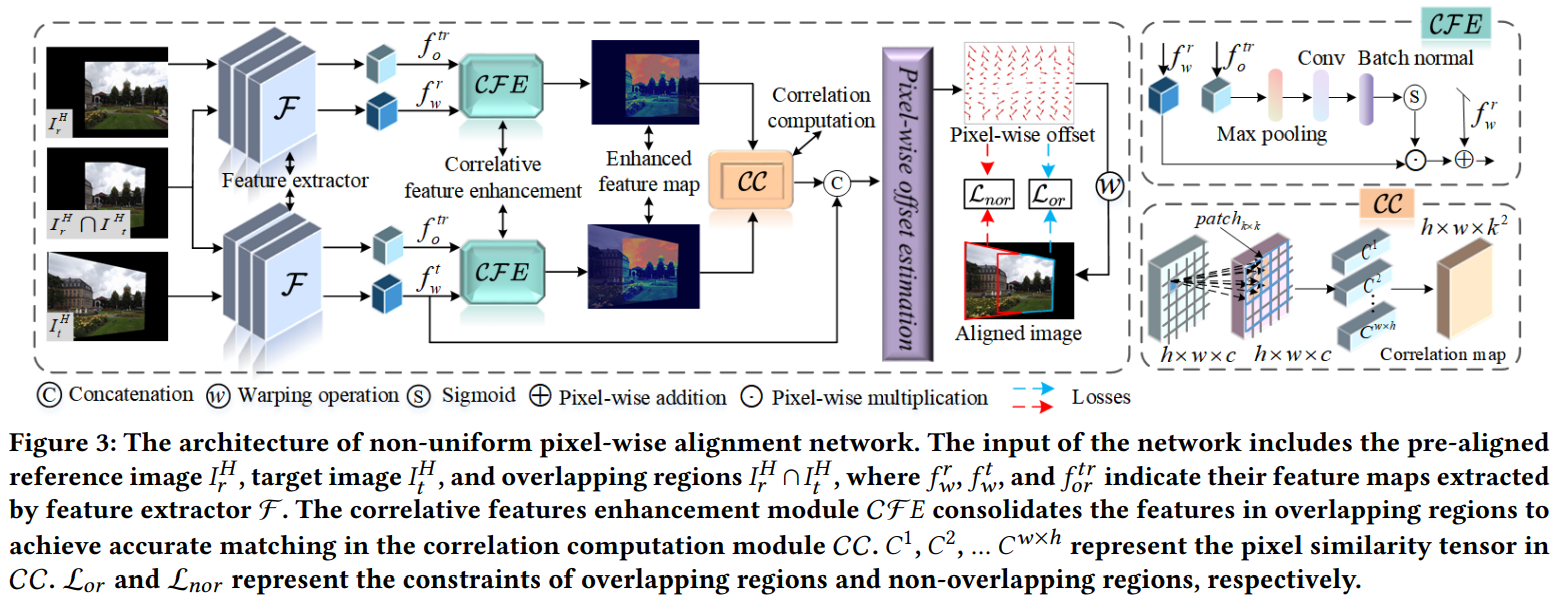
相关特征增强()。该模块旨在增强重叠区域的特征,因为匹配特征仅存在于重叠区域,匹配精度直接影响偏移估计的精度。图3右上角展示了
的结构。该过程是由注意力引导的,以增加对重叠区域的关注。首先,通过最大池化、卷积、批量归一化和sigmoid层将重叠特征
转换为概率图。然后,概率图通过点积加强整个图像特征
的重叠区域。最后,增强的特征通过像素级加法与原始特征
结合,以恢复非重叠特征。公式(2)展示了整个过程。
其中,表示经过sigmoid层后的特征,
表示像素乘法,
是像素级加法。
也遵循相同的过程来产生相关增强特征
。
相关性计算(CC)。增强后的特征输入到相关性计算模块中,以捕捉特征的相似性,如图3右下角所示。为了减少不匹配特征的影响,我们对提取的特征进行
归一化,以获得更好的匹配特征区分度。通过余弦相似性[33],将
中的每个像素与在
中
的正方形邻域中的像素进行比较,生成相似性张量
。余弦相似性
定义为:
其中分别表示
特征图在位置
上的像素。通过这种方式,我们获得了一个最终的
的相似性张量,用于
中的所有像素,
代表特征图的大小。
像素级偏移估计和混合。我们将相似性张量和目标图像的特征作为输入来估计像素级偏移。我们使用Conv+BN+ReLU卷积块和上采样操作来生成与输入图像大小相同的密集位移场
。像素级偏移
将
转换为像素级对齐图像
。
为了保持重叠区域和非重叠区域的亮度和颜色的一致性,我们使用混合模块来生成清晰自然的拼接图像。由于图像混合涉及整个拼接图像的局部和全局特征,我们在卷积层中引入空间和通道注意力机制来整合局部和全局特征,从而发展了U-Net结构。由于图像混合与我们的主要贡献无关,我们在手稿中概述了该模块。
3.3 损失函数
我们的目标是设计约束条件,以精确对齐重叠区域,同时平滑过渡重叠区域到非重叠区域。联合训练重叠区域和非重叠区域
的总损失函数设计为:
重叠区域的目标损失。对于理想的对齐,重叠区域应该完美契合。重叠区域的损失由三个约束组成:匹配一致性
,纹理一致性
和几何循环一致性
,定义为:
其中,是超参数,表示不同损失的权重。每个损失项都在像素级别定义,并在下面详细描述,以像素
在
和对应的像素
在
为例。
匹配一致性约束。为了获得稳健的匹配特征,我们通过对相关性计算块执行sigmoid回归来生成匹配概率图。是从
到
的预测匹配概率,
反之。理想情况下,
的匹配概率对于匹配像素对是一致的。因此,我们鼓励这种循环一致的匹配接近1,
定义为:
其中,表示像素级乘法。由于重叠区域中的像素对对齐有不同的贡献,我们将
作为
的像素级权重。
纹理一致性约束。在变形过程中,目标图像应该接近预对齐的参考图像。因此,我们引入结构相似性(SSIM)约束[34, 41]来全面评估重叠区域关于亮度、对比度和结构的纹理相似性。我们将损失定义为:
其中,表示变形操作,
表示从
的估计像素偏移。我们对所有像素求和并取平均值作为损失。
几何循环一致性约束。为了限制之间的密集位移,我们可以通过交换输入中它们的位置从参考图像到目标图像获得位移场
。然后,我们使用
将像素
在
中变形到目标图像视点。理想情况下,如果估计的像素偏移准确,
应该与
在
中重合,公式如下:
非重叠区域的目标损失。重叠区域在图像对之间有内在的约束,而非重叠区域没有参考。为此,我们提出利用重叠区域的位移场来引导非重叠区域平滑过渡。此外,我们使用内容一致性来保持变形过程中非重叠区域的自然性。总损失定义为:
其中,分别表示结构与内容约束。