目录
前言
背景介绍:
思想:
原理:
KNN算法关键问题
一、构建KNN算法
总结:
博主介绍:✌专注于前后端、机器学习、人工智能应用领域开发的优质创作者、秉着互联网精神开源贡献精神,答疑解惑、坚持优质作品共享。本人是掘金/腾讯云/阿里云等平台优质作者、擅长前后端项目开发和毕业项目实战,深受全网粉丝喜爱与支持✌有需要可以联系作者我哦!
🍅文末三连哦🍅
👇🏻 精彩专栏推荐订阅👇🏻 不然下次找不到哟
前言
背景介绍:
K近邻算法最早由美国的科学家 Thomas Cover 和 Peter Hart 在 1967 年提出,并且在之后的几十年中得到了广泛的研究和应用。KNN 算法是一种基于实例的学习方法,它不像其他算法一样需要对数据进行假设或者参数拟合,而是直接利用已知的数据样本进行预测。
思想:
KNN 算法的思想是基于特征空间中的样本点之间的距离来进行分类。它假设相似的样本在特征空间中具有相似的类别,即距离较近的样本更可能属于同一类别。KNN 算法通过找到样本点周围的 K 个最近邻样本,根据它们的类别进行投票或者加权投票来确定新样本所属的类别。
原理:
-
距离度量: KNN 算法通常使用欧氏距离、曼哈顿距离、闵可夫斯基距离等方法来度量样本点之间的距离。
这里简要介绍一下三种常见的距离度量:
欧氏距离(Euclidean Distance):是最常见的距离度量方法,表示两个点之间的直线距离。
公式:
其中,
和
是两个点的特征向量,
是特征的维度。
曼哈顿距离(Manhattan Distance):表示两个点在各个坐标轴上的绝对距离之和。
公式:
闵可夫斯基距离(Minkowski Distance):是欧氏距离和曼哈顿距离的一种泛化形式,可以表示为两点在各个坐标轴上的距离的
次方。
公式:
其中,是一个正整数
时,就是曼哈顿距离;当
时,就是欧氏距离。
-
K个最近邻: 对于给定的新样本,找到离它最近的 K 个训练样本。
-
投票决策: 对于分类问题,根据 K 个最近邻样本的类别进行投票,将新样本归为票数最多的类别。对于回归问题,可以计算 K 个最近邻样本的平均值来预测新样本的输出。
KNN算法关键问题
距离度量方法: KNN 算法需要计算样本之间的距离,常见的距离度量方法包括欧氏距离、曼哈顿距离、闵可夫斯基距离等。
邻居选择规则: 在给定一个新样本时,需要选择它的 K 个最近邻样本。通常采用的方法是基于距离的排序,选择距离最近的 K 个样本。
类别判定规则: 对于分类问题,KNN 采用多数表决的方式确定新样本的类别,即根据 K 个最近邻样本中所属类别的频率来决定新样本的类别。对于回归问题,通常采用平均值的方式来预测新样本的输出。
K 值选择: K 值的选择对 KNN 算法的性能影响较大。较小的 K 值可能会使模型过拟合,而较大的 K 值可能会使模型欠拟合。因此,需要通过交叉验证等方法来选择合适的 K 值。
特征标准化: 在使用 KNN 算法之前,通常需要对特征进行标准化处理,以确保不同特征的尺度相同,避免某些特征对距离计算的影响过大。
算法复杂度分析: KNN 算法的时间复杂度主要取决于样本数量和特征维度,因为需要计算新样本与所有训练样本的距离。因此,KNN 算法在处理大规模数据集时可能会效率较低。
应用领域: KNN 算法广泛应用于分类和回归问题,特别是在图像识别、推荐系统、医疗诊断等领域有着重要的应用价值。
一、构建KNN算法
基于Python 实现 K 近邻算法,包括了数据准备、距离度量、邻居选择、类别判定规则和模型评估等操作步骤:
我们首先定义了一个 KNN 类,其中包括了初始化方法、训练方法(fit)、预测方法(predict)和评估方法(evaluate)。然后,我们使用一个简单的示例数据集进行了演示。在示例用法中,我们首先准备了训练集和测试集数据,然后初始化了 KNN 模型并进行了训练,接着使用测试集进行了预测,并计算了模型的准确率。
import numpy as np
from collections import Counter
class KNN:
def __init__(self, k=3):
self.k = k
def fit(self, X_train, y_train):
self.X_train = X_train
self.y_train = y_train
def predict(self, X_test):
predictions = []
for x in X_test:
# 计算测试样本与所有训练样本的距离
distances = [np.linalg.norm(x - x_train) for x_train in self.X_train]
# 找到距离最近的 K 个邻居的索引
nearest_neighbors_indices = np.argsort(distances)[:self.k]
# 获取这 K 个邻居的类别
nearest_neighbors_labels = [self.y_train[i] for i in nearest_neighbors_indices]
# 对 K 个邻居的类别进行多数表决,确定测试样本的类别
most_common_label = Counter(nearest_neighbors_labels).most_common(1)[0][0]
predictions.append(most_common_label)
return predictions
def evaluate(self, X_test, y_test):
predictions = self.predict(X_test)
accuracy = np.mean(predictions == y_test)
return accuracy
# 示例用法
if __name__ == "__main__":
# 准备数据集
X_train = np.array([[1, 2], [2, 3], [3, 4], [4, 5]])
y_train = np.array([0, 0, 1, 1])
X_test = np.array([[2, 2], [3, 3]])
# 初始化和训练模型
knn = KNN(k=2)
knn.fit(X_train, y_train)
# 预测和评估模型
predictions = knn.predict(X_test)
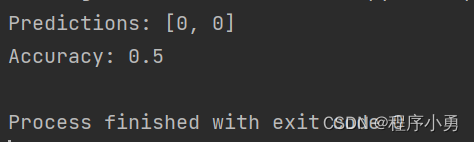
print("Predictions:", predictions)
accuracy = knn.evaluate(X_test, np.array([0, 1]))
print("Accuracy:", accuracy)
执行结果:
总结:
KNN 算法是一种简单有效的分类和回归算法,算法的核心思想是“近朱者赤,近墨者黑”,即认为与新样本距离较近的训练样本更可能具有相同的类别或者输出。它的基本假设是“相似的样本在特征空间中具有相似的类别”。因此,KNN 算法不需要对数据进行假设或者参数拟合,而是直接利用已有的数据进行预测。它没有显式地对数据进行假设或参数拟合,因此在处理复杂、非线性的问题时具有一定的优势。然而,KNN 算法的计算复杂度较高,特别是在处理大规模数据集时,因为需要计算样本之间的距离。此外,KNN 算法对异常值和噪声敏感,需要进行适当的数据预处理和参数调节。






![[flask]异常抛出和捕获异常](https://img-blog.csdnimg.cn/direct/b52f1ea9c6344737bec4786a080362be.png)