# 导入LangChain的库
from langchain import *
# 加载数据源
loader = WebBaseLoader()
doc = loader.load("https://xxx.html")
# 分割文档对象
splitter = RecursiveCharacterTextSplitter(max_length=512)
docs = splitter.split(doc)
# 转换文档对象为嵌入,并存储到向量存储器中
embedder = OpenAIEmbeddings()
vector_store = ChromaVectorStore()
for doc in docs:
embedding = embedder.embed(doc.page_content)
vector_store.add(embedding, doc)
# 创建检索器
retriever = VectorStoreRetriever(vector_store, embedder)
# 创建聊天模型
prompt = hub.pull("rlm/rag-prompt")
llm = ChatOpenAI(model_name="gpt-3.5-turbo", temperature=0)
# 创建一个问答应用
def format_docs(docs):
return "\n\n".join(doc.page_content for doc in docs)
rag_chain = (
{"context": retriever | format_docs, "question": RunnablePassthrough()}
| prompt
| llm
| StrOutputParser()
)
# 启动应用
rag_chain.invoke("What is main purpose of xxx.html?")LangChain提供了一种专门的表达式语言,叫做LCEL(LangChain Expression Language),它可以让你用简洁和灵活的语法来定义和操作Chain。
LCEL语法基础
LCEL是一个用于构建复杂链式组件的语言,它支持流式处理、并行化、日志记录等功能。LCEL的基本语法规则是使用|符号将不同的组件连接起来,形成一个链式结构。|符号类似于Unix的管道操作符,它将一个组件的输出作为下一个组件的输入,从而实现数据的传递和处理。
为什么要用LCEL?
LCEL语法的核心思想是:一切皆为对象,一切皆为链。这意味着,LCEL语法中的每一个对象都实现了一个统一的接口:Runnable,它定义了一系列的调用方法(invoke, batch, stream, ainvoke, …)。这样,你可以用同样的方式调用不同类型的对象,无论它们是模型、函数、数据、配置、条件、逻辑等等。而且,你可以将多个对象链接起来,形成一个链式结构,这个结构本身也是一个对象,也可以被调用。这样,你可以将复杂的功能分解成简单的组件,然后用LCEL语法将它们组合起来,形成一个完整的应用。
LCEL语法还提供了一些组合原语,让你可以更灵活地控制链式结构的行为,例如:
- 并行化:你可以使用
parallel原语将多个对象并行执行,提高效率和性能。 - 回退:你可以使用
fallback原语为某个对象指定一个备选对象,当主对象执行失败时,自动切换到备选对象,保证应用的可用性和稳定性。 - 动态配置:你可以使用
config原语为某个对象指定一个配置对象,根据运行时的输入或条件,动态地修改对象的参数或属性,增加应用的灵活性和适应性。
TruLens
TruLens是面向神经网络应用的质量评估工具,它可以帮助你使用反馈函数来客观地评估你的基于LLM(语言模型)的应用的质量和效果。反馈函数可以帮助你以编程的方式评估输入、输出和中间结果的质量,从而加快和扩大实验评估的范围。你可以将它用于各种各样的用例,包括问答、检索增强生成和基于代理的应用。
TruLens的核心思想是,你可以为你的应用定义一些反馈函数,这些函数可以根据你的应用的目标和期望,对你的应用的表现进行打分或分类。例如:
- 定义一个反馈函数来评估你的问答应用的输出是否与问题相关,是否有依据,是否有用。
- 定义一个反馈函数来评估你的检索增强生成应用的输出是否符合语法规则,是否有创造性,是否有逻辑性。
- 定义一个反馈函数来评估你的基于代理的应用的输出是否符合道德标准,是否有友好性,是否有诚实性。
TruLens可以让你在开发和测试你的应用的过程中,实时地收集和分析你的应用的反馈数据,从而帮助你发现和解决你的应用的问题,提高你的应用的质量和效果。你可以使用TruLens提供的易用的用户界面,来查看和比较你的应用的不同版本的反馈数据,从而找出你的应用的优势和劣势,以及改进的方向。
# 导入LangChain和TruLens
from langchain.chains import LLMChain
from langchain.llms import OpenAI
from langchain.prompts import PromptTemplate
from langchain.prompts.chat import ChatPromptTemplate,HumanMessagePromptTemplate
from trulens_eval import TruChain,Feedback, Huggingface, Tru, OpenAI as TruOpenAI
from trulens_eval.feedback.provider.langchain import Langchain
tru = Tru()
# 定义一个问答应用的提示模板
full_prompt = HumanMessagePromptTemplate(
prompt=PromptTemplate(
template=
"Provide a helpful response with relevant background information for the following: {prompt}",
input_variables=["prompt"],
)
)
chat_prompt_template = ChatPromptTemplate.from_messages([full_prompt])
# 创建一个LLMChain对象,使用llm和chat_prompt_template作为参数
llm = OpenAI()
chain = LLMChain(llm=llm, prompt=chat_prompt_template, verbose=True)
# Initialize Huggingface-based feedback function collection class:
# Define a language match feedback function using HuggingFace.
hugs = Huggingface()
f_lang_match = Feedback(hugs.language_match).on_input_output()
# Question/answer relevance between overall question and answer.
provider = TruOpenAI()
f_qa_relevance = Feedback(provider.relevance).on_input_output()
# 使用TruChain类来包装chain对象,指定反馈函数和应用ID
tru_recorder = TruChain(
chain,
app_id='Chain1_QAApplication',
feedbacks=[f_lang_match,f_qa_relevance])
# 使用with语句来运行chain对象,并记录反馈数据
with tru_recorder as recording:
# 输入一个问题,得到一个回答
chain("What is langchain?")
# 查看反馈数据
tru_record = recording.records[0]
# 打印反馈数据
print("tru_record:",tru_record)
# 启动tru展示控制台
tru.run_dashboard()为了评估RAG的质量和效果,可以使用TruLens提供的RAG三角形(RAG Triad)的评估方法。RAG三角形是由三个评估指标组成的,分别是:
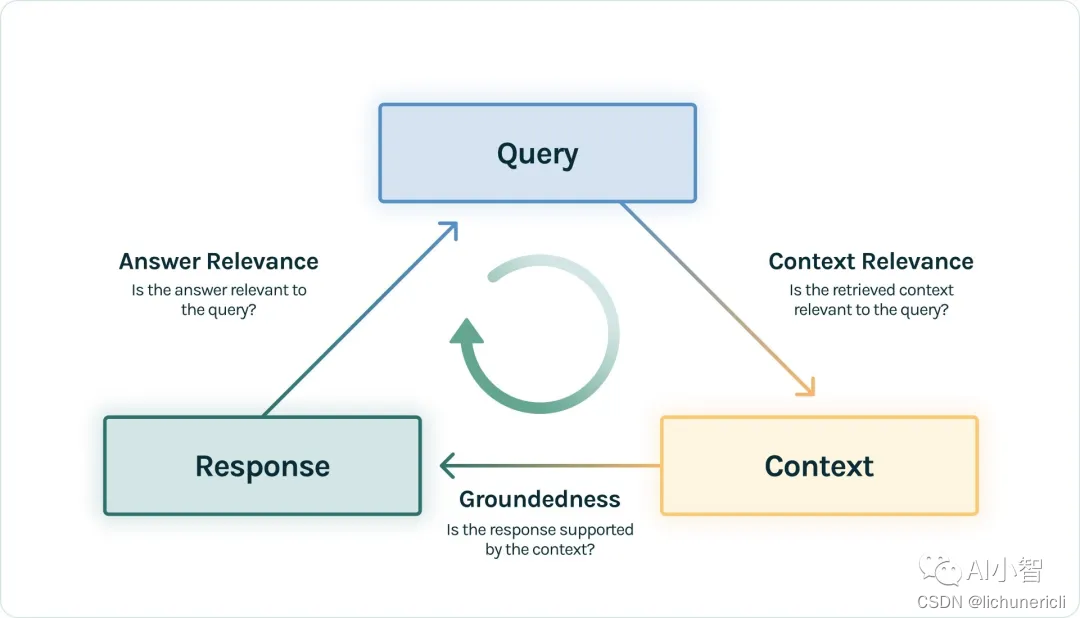
- 上下文相关性(Context Relevance):评估输入和检索出的文档之间的相关性,以及文档之间的一致性。上下文相关性越高,说明检索系统越能找到与输入匹配的知识和信息,从而为LLM提供更好的上下文。
- 有根据性(Groundedness):评估输出和检索出的文档之间的一致性,以及输出的可信度。有根据性越高,说明LLM越能利用检索出的文档来生成有依据的输出,从而避免产生幻觉或错误。
- 答案相关性(Answer Relevance):评估输出和输入之间的相关性,以及输出的有用性。答案相关性越高,说明LLM越能理解输入的意图和需求,从而生成有用的输出,满足用户的目的。
RAG三角形的评估方法可以让我们从不同的角度来检验RAG的质量和效果,从而发现和改进RAG的问题。我们可以使用TruLens来实现RAG三角形的评估方法,具体步骤如下:
- 在LangChain中,创建一个RAG对象,使用RAGPromptTemplate作为提示模板,指定检索系统和知识库的参数。
- 在TruLens中,创建一个TruChain对象,包装RAG对象,指定反馈函数和应用ID。反馈函数可以使用TruLens提供的f_context_relevance, f_groundness, f_answer_relevance,也可以自定义。
- 使用with语句来运行RAG对象,并记录反馈数据。输入一个问题,得到一个回答,以及检索出的文档。
- 查看和分析反馈数据,根据RAG三角形的评估指标,评价RAG的表现。
下面是一个简单的示例,展示了如何在LangChain中使用TruLens来评估一个RAG问答应用:
# 导入LangChain和TruLens
from IPython.display import JSON
# Imports main tools:
from trulens_eval import TruChain, Feedback, Huggingface, Tru
from trulens_eval.schema import FeedbackResult
tru = Tru()
tru.reset_database()
# Imports from langchain to build app
import bs4
from langchain import hub
from langchain.chat_models import ChatOpenAI
from langchain.document_loaders import WebBaseLoader
from langchain.embeddings import OpenAIEmbeddings
from langchain.schema import StrOutputParser
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.vectorstores import Chroma
from langchain_core.runnables import RunnablePassthrough
from trulens_eval.feedback.provider import OpenAI
import numpy as np
from trulens_eval.app import App
from trulens_eval.feedback import Groundedness
# 加载文件
loader = WebBaseLoader(
web_paths=("https://lilianweng.github.io/posts/2023-06-23-agent/",),
bs_kwargs=dict(
parse_only=bs4.SoupStrainer(
class_=("post-content", "post-title", "post-header")
)
),
)
docs = loader.load()
# 分词
text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=200)
splits = text_splitter.split_documents(docs)
# 存入到向量数据库
vectorstore = Chroma.from_documents(documents=splits, embedding=OpenAIEmbeddings(
))
# 定义一个RAG Chain
retriever = vectorstore.as_retriever()
prompt = hub.pull("rlm/rag-prompt")
llm = ChatOpenAI(model_name="gpt-3.5-turbo", temperature=0)
def format_docs(docs):
return "\n\n".join(doc.page_content for doc in docs)
rag_chain = (
{"context": retriever | format_docs, "question": RunnablePassthrough()}
| prompt
| llm
| StrOutputParser()
)
# 使用TruChain类来包装rag对象,指定反馈函数和应用ID
# Initialize provider class
provider = OpenAI()
# select context to be used in feedback. the location of context is app specific.
context = App.select_context(rag_chain)
grounded = Groundedness(groundedness_provider=provider)
# f_context_relevance, f_groundness, f_answer_relevance 定义反馈函数
# Define a groundedness feedback function
f_groundedness = (
Feedback(grounded.groundedness_measure_with_cot_reasons)
.on(context.collect()) # collect context chunks into a list
.on_output()
.aggregate(grounded.grounded_statements_aggregator)
)
# Question/answer relevance between overall question and answer.
f_qa_relevance = Feedback(provider.relevance).on_input_output()
# Question/statement relevance between question and each context chunk.
f_context_relevance = (
Feedback(provider.qs_relevance)
.on_input()
.on(context)
.aggregate(np.mean)
)
# 使用with语句来运行rag对象,并记录反馈数据
tru_recorder = TruChain(rag_chain,
app_id='Chain1_ChatApplication',
feedbacks=[f_qa_relevance, f_context_relevance, f_groundedness])
with tru_recorder as recording:
# 输入一个问题,得到一个回答,以及检索出的文档
llm_response = rag_chain.invoke("What is Task Decomposition?")
# 查看反馈数据
rec = recording.get() # use .get if only one record
# 打印反馈数据
print(rec)
# 启动tru展示控制台
tru.run_dashboard()











![2024年上半年数学建模竞赛一览表(附赠12场竞赛的优秀论文+格式要求)[电工、妈杯、数维、五一等12场]](https://img-blog.csdnimg.cn/direct/a93da4818a12484ebbf5c071c7eb64c8.png)