文章目录
- 翻译环境和运行环境
- 翻译环境
- 预处理
- 编译
- 汇编
- 链接
- 运行环境
翻译环境和运行环境
1,在ANSI C的任何⼀种实现中,存在两个不同的环境。
第1种是翻译环境,在这个环境中源代码被转换为可执⾏的机器指 令(⼆进制指令)。
第2种是执⾏环境,它⽤于实际执⾏代码。
翻译环境
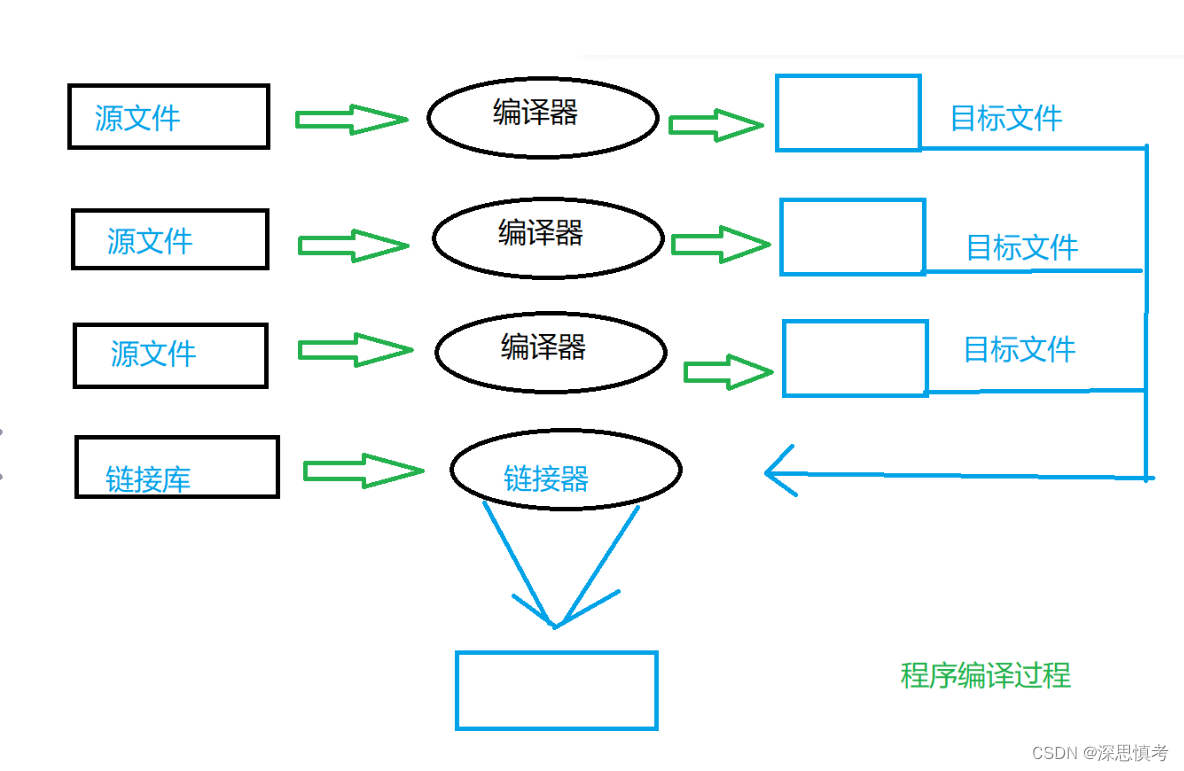
那翻译环境是怎么将源代码转换为可执⾏的机器指令的呢?这⾥我们就得展开开讲解⼀下翻译环境所做的事情。
其实翻译环境是由编译和链接两个⼤的过程组成的,⽽编译⼜可以分解成:预处理(有些书也叫预编译)、编译、汇编三个过程。
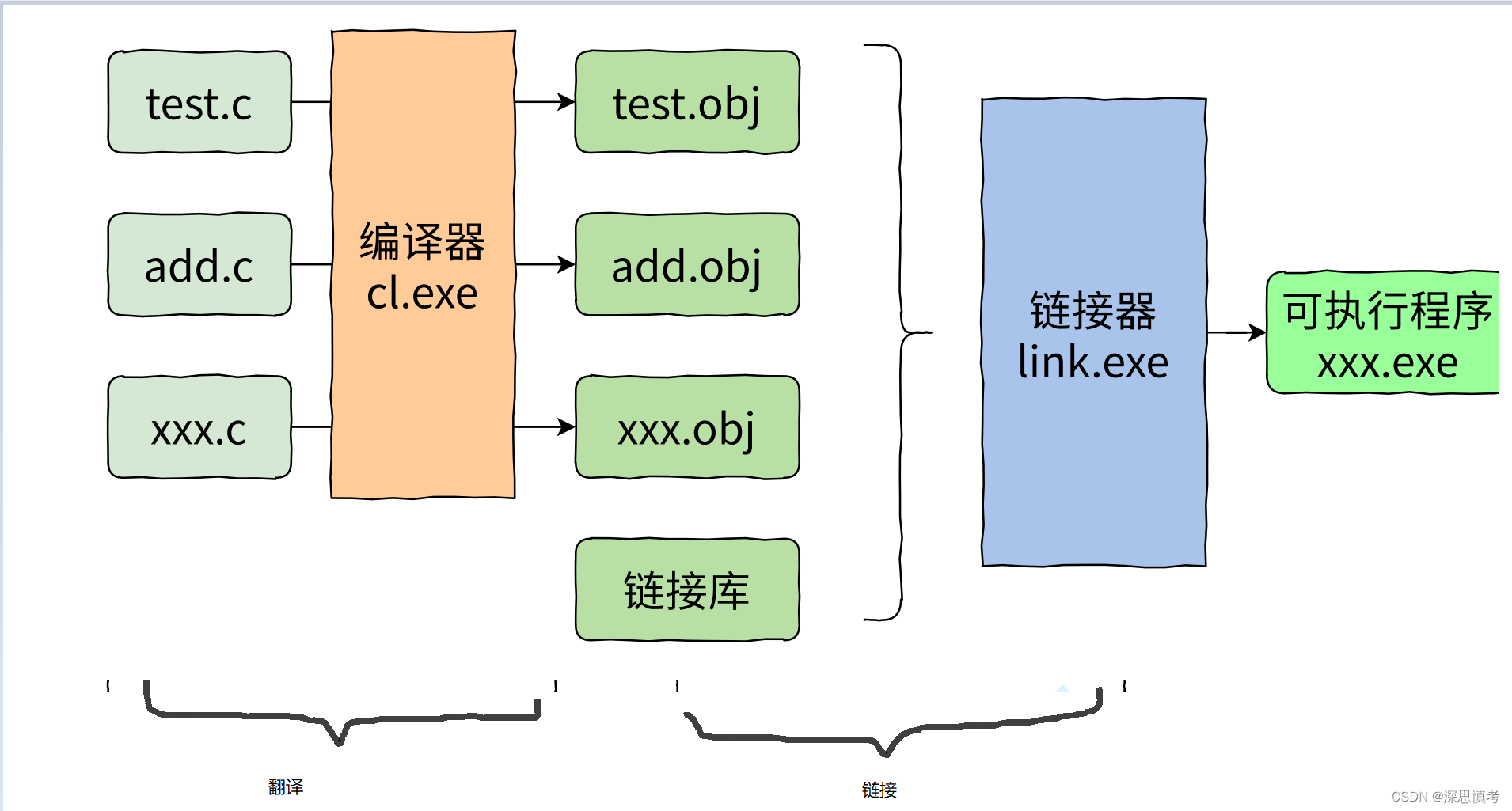
⼀个C语⾔的项⽬中可能有多个 .c ⽂件⼀起构建,那多个 .c ⽂件如何⽣成可执⾏程序呢?
- 多个.c⽂件单独经过编译器,编译处理⽣成对应的⽬标⽂件。
- 注:在Windows环境下的⽬标⽂件的后缀是 .obj ,Linux环境下⽬标⽂件的后缀是 .o
- 多个⽬标⽂件和链接库⼀起经过链接器处理⽣成最终的可执⾏程序。
- 链接库是指运⾏时库(它是⽀持程序运⾏的基本函数集合)或者第三⽅库。
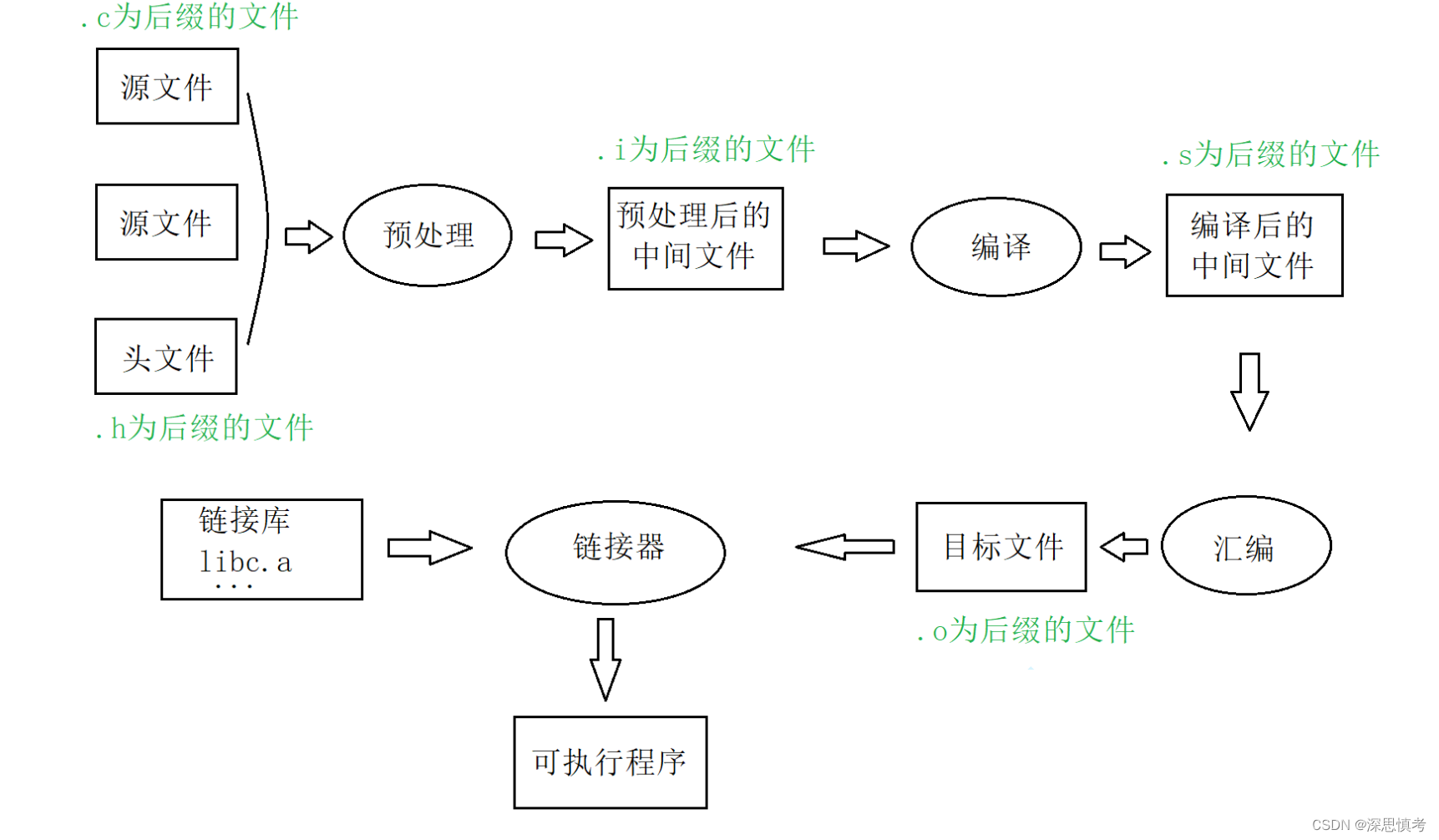
预处理
在C语言中,预处理阶段是编译过程中的第一步,主要是通过预处理器对源代码进行处理,包括宏替换、头文件包含、条件编译等操作。下面详细解释一下预处理阶段的几个重要概念和操作:
-
头文件包含(Include Directives):
#include 指令:用于包含其他文件的内容,分为尖括号包含系统头文件(如#include <stdio.h>)和双引号包含用户定义的头文件(如#include “myheader.h”)。 -
宏替换(Macro Replacement):
宏定义:使用#define指令定义一个宏,如#define PI 3.14159。
宏替换:预处理器会在编译前将代码中出现的宏名称替换为对应的值,比如将代码中的PI替换为3.14159。 -
条件编译(Conditional Compilation):
条件编译指令:如#if、#ifdef、#ifndef、#elif、#else、#endif等,用于根据条件选择性地编译代码块。 -
其他预处理指令:
#undef:取消已定义的宏。
#ifdef 和 #ifndef:判断某个宏是否已经定义。
#error:在预处理时生成一个错误信息。
#pragma:向编译器发出特定指令。
预处理器工作流程:
1,将源文件中的头文件包含进来。
2,对源文件进行宏替换。
3,处理条件编译指令,根据条件编译部分代码。
4,生成一个经过预处理的中间文件,后缀为.i,供后续编译阶段使用。
5,删除所有的注释
6, 添加⾏号和⽂件名标识,⽅便后续编译器⽣成调试信息等
经过预处理后的.i⽂件中不再包含宏定义,因为宏已经被展开。并且包含的头⽂件都被插⼊到.i⽂件
中。所以当我们无法知道宏定义或者头⽂件是否包含正确的时候,可以查看预处理后的.i⽂件来确认。
编译
-
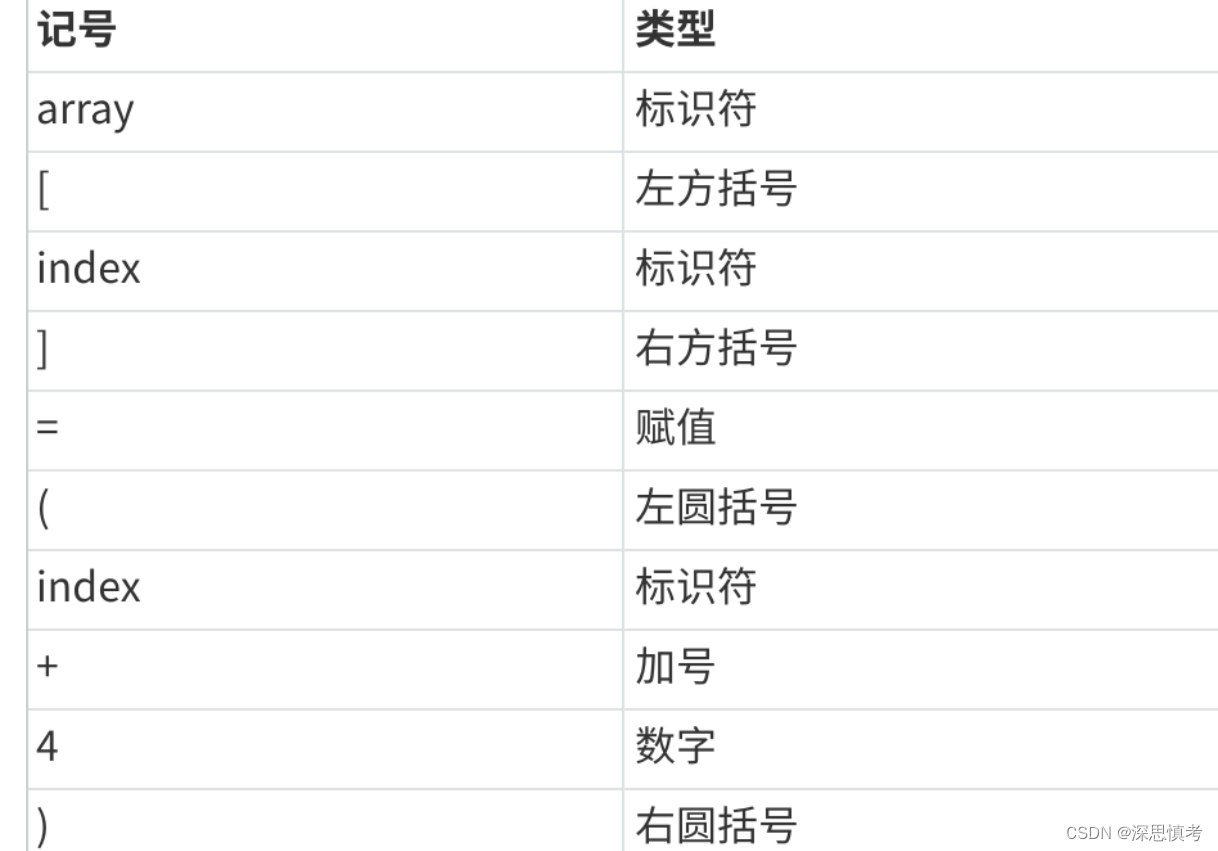
词法分析(Lexical Analysis):
目的:
将源代码按照词法规则分割成单词(Token)序列。工作内容:
识别关键字、标识符、常量、运算符等单词,并生成对应的标记(Token)。生成标记流(Token Stream)作为下一步的输入。
-
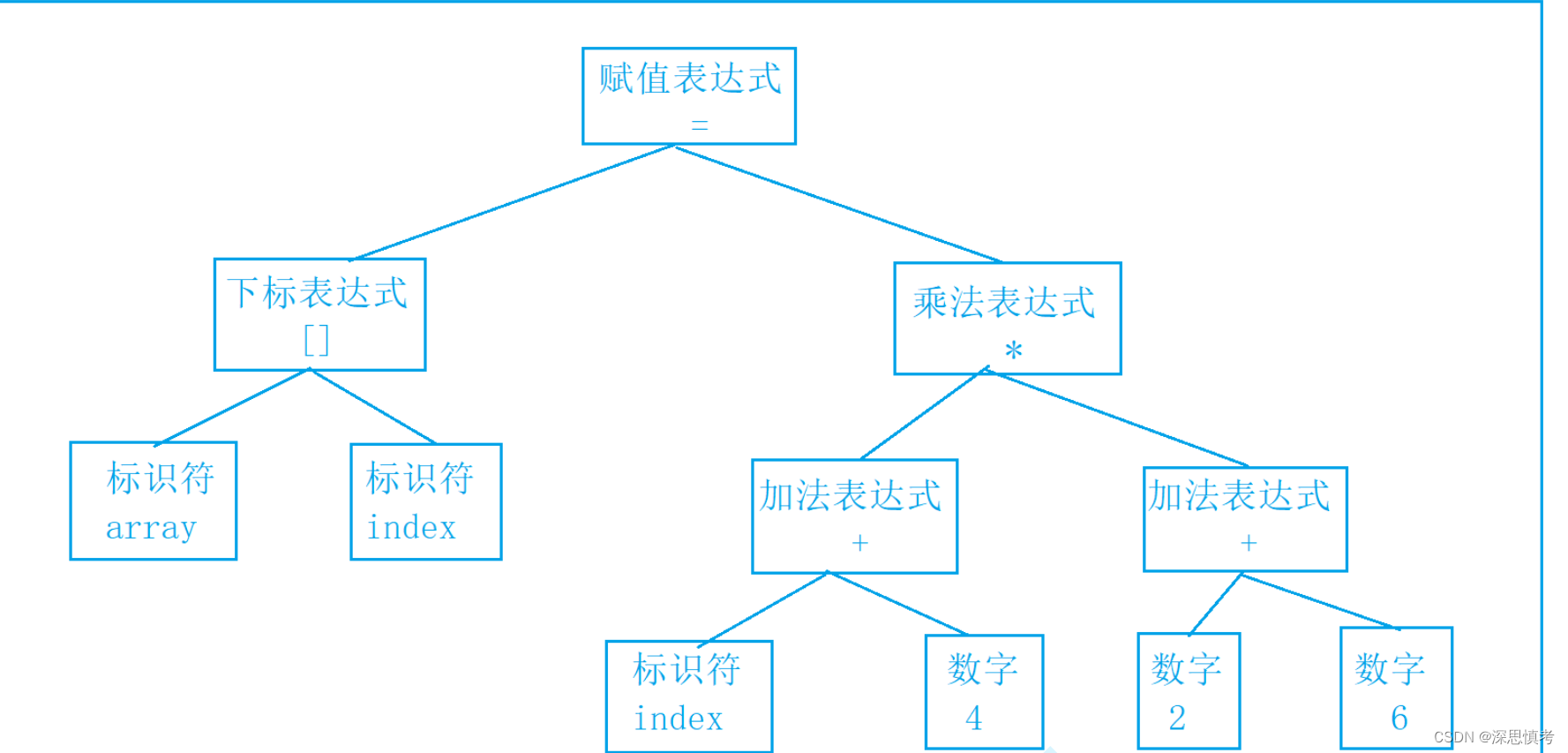
语法分析(Syntax Analysis):
目的:
将标记流转换成抽象语法树(Abstract Syntax Tree,AST)或语法分析树。工作内容:
根据语法规则检查标记流是否符合语言语法规范。
构建抽象语法树,表示源代码的结构和语法。
-
语义分析(Semantic Analysis):
目的:
进行语义检查,确保程序的语义正确。工作内容:
检查类型匹配、变量的定义和使用是否正确。
解析表达式,计算常量表达式的值。
检查函数调用、返回值等语义正确性。

-
中间代码生成(Intermediate Code Generation):
目的:
将抽象语法树转换成中间代码表示。工作内容:
生成一种中间表示形式,如三地址码、四元式等。
将高级语言的结构转换成更加容易进行优化的形式。 -
优化(Optimization):
目的:
对中间代码进行优化,提高程序的执行效率。工作内容:
利用各种优化技术,如常量传播、死代码删除、循环优化等,提高程序性能。
生成更加高效的中间代码表示,以便后续的代码生成阶段使用。 -
代码生成(Code Generation):
目的:
将优化后的中间代码转换成目标机器代码。工作内容:
根据目标机器的特性和指令集,将中间代码转换为机器指令。
处理寄存器分配、指令选择等问题,生成最终的目标代码。
汇编
当将C语言代码转换为汇编语言时,主要涉及到编译器将高级语言代码翻译成等效的汇编语言代码。以下是详细介绍汇编语言的步骤:
- 指令表示:
汇编语言使用助记符(Mnemonics)来代表特定的机器指令,如mov用于数据传送、add用于加法运算等。 - 寄存器:
计算机有一组寄存器用于存储数据和执行操作,如通用寄存器(如eax、ebx)、数据寄存器(如edx)、地址寄存器(如esi、edi)等。 - 内存访问:
使用不同的寻址模式(如立即数偏移、寄存器间接寻址)来访问内存中的数据。 - 控制流:
汇编语言提供了跳转指令(如jmp)和条件跳转指令(如je、jne)来控制程序的执行流程。 - 过程调用:
使用call来调用函数,使用ret返回函数调用,需要处理函数参数传递和局部变量存储。 - 栈操作:
使用栈来保存函数调用过程中的返回地址、参数以及局部变量,通过push和pop指令来操作栈。 - 数据处理:
汇编语言提供了各种指令来进行数据处理,如移位指令、逻辑运算指令、算术运算指令等。 - 标志寄存器:
标志寄存器记录了运算结果的信息,如进位标志、零标志、符号标志等,影响程序的条件跳转。
9.宏指令:
汇编语言支持宏定义,可以简化重复代码的书写,提高代码的可读性和维护性。
链接
链接是将多个目标文件(包括库文件)组合成一个可执行文件或动态链接库的过程。以下是链接过程的详细步骤:
- 符号解析(Symbol Resolution):
目的:解析所有目标文件中的符号引用,确定它们对应的实际地址或存储位置。
工作内容:
遍历所有目标文件,收集每个符号(如函数名、全局变量名)的定义和引用信息。
解析外部符号引用,确定这些符号最终在哪个目标文件或库文件中定义。
2.重定位(Relocation):
目的:修正目标文件中的相对地址,使其能正确地映射到最终的内存地址。
工作内容:
根据符号解析的结果,对所有涉及到的地址进行调整,确保它们能正确地指向符号的实际位置。
生成包含所有修正地址的重定位表,以便在加载时进行修正。 - 地址空间分配(Address Allocation):
目的:为目标文件中的变量和函数分配内存地址。
工作内容:
确定每个全局变量和函数在内存中的起始地址。
处理重复定义和冲突,确保分配的地址不会发生重叠或冲突。 - 符号重命名(Symbol Renaming):
目的:避免不同目标文件中的符号名字冲突。
工作内容:
对于静态链接,可以对不同目标文件中的相同符号进行重命名,以避免冲突。
对于动态链接,通常使用全局符号表(Global Symbol Table)来管理符号名字,确保唯一性。 - 生成可执行文件或动态链接库(Executable/Dynamic Link Library Generation):
目的:将经过符号解析、重定位等处理后的目标文件转换为最终的可执行文件或动态链接库。
工作内容:
将已经修改过的目标文件内容按照特定的格式组合成可执行文件或动态链接库。
对于可执行文件,可能还需要添加一些运行时所需的信息,如程序入口点等。 - 符号表生成(Symbol Table Generation):
目的:生成最终可执行文件或动态链接库中的符号表,记录符号名字和对应的地址信息。
工作内容:
生成包含所有符号信息的符号表,以便在加载时进行符号解析和重定位。
运行环境
1,程序必须载⼊内存中。在有操作系统的环境中:⼀般这个由操作系统完成。在独⽴的环境中,程序的载⼊必须由⼿⼯安排,也可能是通过可执⾏代码置⼊只读内存来完成。
2, 程序的执⾏便开始。接着便调⽤main函数。
3,开始执⾏程序代码。这个时候程序将使⽤⼀个运⾏时堆栈(stack),存储函数的局部变量和返回地址。程序同时也可以使⽤静态(static)内存,存储于静态内存中的变量在程序的整个执⾏过程⼀直保留他们的值。
4,终⽌程序。正常终⽌main函数;也有可能是意外终⽌。

![2024年上半年数学建模竞赛一览表(附赠12场竞赛的优秀论文+格式要求)[电工、妈杯、数维、五一等12场]](https://img-blog.csdnimg.cn/direct/a93da4818a12484ebbf5c071c7eb64c8.png)

](https://img-blog.csdnimg.cn/direct/c51b58cd91ee40b6af409cafb44b0301.jpeg#pic_center)