comfyui的服务器端是用aiohtttp写的,webui是fastapi直接构建的,但是其实comfyui的这种设计思路是很好的,也许我们不需要在后端起一个复杂的前台,但是可以借助json结构化pipeline,然后利用node节点流把整个流程重新映射出来。有些串联的pipeline是比较复杂的,但是串联起来可以实现一些比较好的功能,而这些功能其实可以被放在一个框架中训练,这是很值得思考和算法化的地方。
1.启动
pip install -r requirements.txt2.代码分析
main.py->
comfy->cli_args.py:
server = server.PromptServer(loop)->
-
q = execution.PromptQueue(server)->
init_custom_nodes()->nodes.py->load_custom_node()->load_custom_nodes()
threading.Thread(target=prompt_worker,daemon=True,args=(q,server,)).start()
- prompt_worker()->
- queue_item = q.get() -> self.queue
- item,item_id = queue_item prompt_id = item[1]
- e.execute(item[2],prompt_id,item[3],item[4]) ->
-- with torch.inference_mode() ->
-- for x in prompt: recursive_output_delete_if_changed(prompt,self.old_prompt,self.outputs,x)->
--- inputs = prompt[unique_id]['inputs'] class_type = prompt[unique_id]['class_type'] class_def = nodes.NODE_CLASS_MAPPINGS[class_type] ->
--- input_data_all = get_input_data(inputs,class_def,unique_id,outputs) ->
--- is_changed = map_node_over_list(class_def,input_data_all,"IS_CHANGED") ->
--- results.append(getattr(obj,func)(**slice_dict(input_data_all,i)))
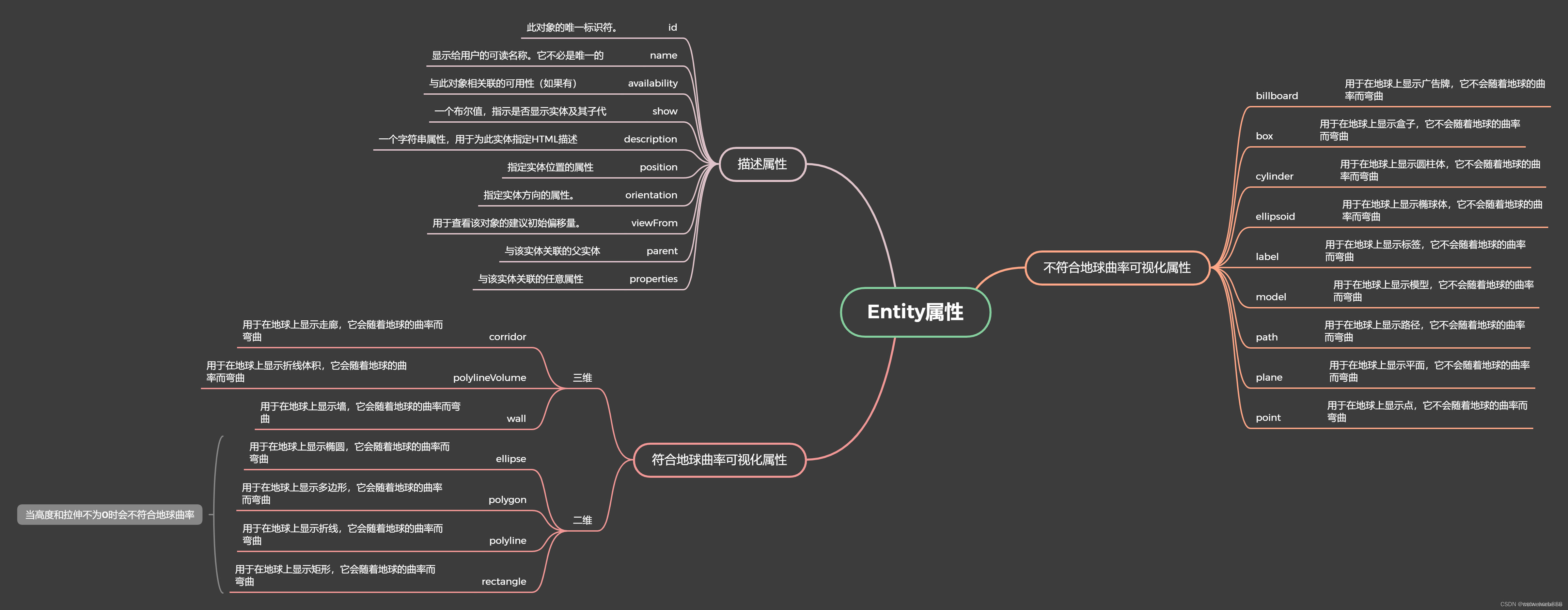
loop.run_until_complete(run(server,address,port,...))comfyui中主要实现node节点的就是getattr(obj,func)方法,实现之后再存入节点中,下次取。
nodes.py 中存了大量的节点,是提前定义的,comfy_extras中也存了很多后来加入的节点,都放在NODE_CLASS_MAPPINGS中。
comfy中实现了具体的方法,当安装外部插件时,新增的后端代码放在custom_nodes中,前端代码放在web中,comfyui中的前端代码都在web/extension/core中,还算是一个前后分开的项目。
具体的节点调用方法,我这里有个简单的工作流,尝试着走完全流程来看下结果:
{
"last_node_id": 9,
"last_link_id": 9,
"nodes": [
{
"id": 7,
"type": "CLIPTextEncode",
"pos": [
413,
389
],
"size": {
"0": 425.27801513671875,
"1": 180.6060791015625
},
"flags": {},
"order": 3,
"mode": 0,
"inputs": [
{
"name": "clip",
"type": "CLIP",
"link": 5
}
],
"outputs": [
{
"name": "CONDITIONING",
"type": "CONDITIONING",
"links": [
6
],
"slot_index": 0
}
],
"properties": {
"Node name for S&R": "CLIPTextEncode"
},
"widgets_values": [
"text, watermark"
]
},
{
"id": 5,
"type": "EmptyLatentImage",
"pos": [
473,
609
],
"size": {
"0": 315,
"1": 106
},
"flags": {},
"order": 0,
"mode": 0,
"outputs": [
{
"name": "LATENT",
"type": "LATENT",
"links": [
2
],
"slot_index": 0
}
],
"properties": {
"Node name for S&R": "EmptyLatentImage"
},
"widgets_values": [
512,
512,
2
]
},
{
"id": 8,
"type": "VAEDecode",
"pos": [
1209,
188
],
"size": {
"0": 210,
"1": 46
},
"flags": {},
"order": 5,
"mode": 0,
"inputs": [
{
"name": "samples",
"type": "LATENT",
"link": 7
},
{
"name": "vae",
"type": "VAE",
"link": 8
}
],
"outputs": [
{
"name": "IMAGE",
"type": "IMAGE",
"links": [
9
],
"slot_index": 0
}
],
"properties": {
"Node name for S&R": "VAEDecode"
}
},
{
"id": 3,
"type": "KSampler",
"pos": [
863,
186
],
"size": {
"0": 315,
"1": 262
},
"flags": {},
"order": 4,
"mode": 0,
"inputs": [
{
"name": "model",
"type": "MODEL",
"link": 1
},
{
"name": "positive",
"type": "CONDITIONING",
"link": 4
},
{
"name": "negative",
"type": "CONDITIONING",
"link": 6
},
{
"name": "latent_image",
"type": "LATENT",
"link": 2
}
],
"outputs": [
{
"name": "LATENT",
"type": "LATENT",
"links": [
7
],
"slot_index": 0
}
],
"properties": {
"Node name for S&R": "KSampler"
},
"widgets_values": [
710912628627374,
"randomize",
20,
8,
"dpmpp_3m_sde_gpu",
"normal",
1
]
},
{
"id": 6,
"type": "CLIPTextEncode",
"pos": [
415,
186
],
"size": {
"0": 422.84503173828125,
"1": 164.31304931640625
},
"flags": {},
"order": 2,
"mode": 0,
"inputs": [
{
"name": "clip",
"type": "CLIP",
"link": 3
}
],
"outputs": [
{
"name": "CONDITIONING",
"type": "CONDITIONING",
"links": [
4
],
"slot_index": 0
}
],
"properties": {
"Node name for S&R": "CLIPTextEncode"
},
"widgets_values": [
"beautiful scenery nature glass bottle landscape, , purple galaxy bottle,"
]
},
{
"id": 9,
"type": "SaveImage",
"pos": [
1451,
189
],
"size": [
210,
270
],
"flags": {},
"order": 6,
"mode": 0,
"inputs": [
{
"name": "images",
"type": "IMAGE",
"link": 9
}
],
"properties": {},
"widgets_values": [
"ComfyUI"
]
},
{
"id": 4,
"type": "CheckpointLoaderSimple",
"pos": [
26,
474
],
"size": {
"0": 315,
"1": 98
},
"flags": {},
"order": 1,
"mode": 0,
"outputs": [
{
"name": "MODEL",
"type": "MODEL",
"links": [
1
],
"slot_index": 0
},
{
"name": "CLIP",
"type": "CLIP",
"links": [
3,
5
],
"slot_index": 1
},
{
"name": "VAE",
"type": "VAE",
"links": [
8
],
"slot_index": 2
}
],
"properties": {
"Node name for S&R": "CheckpointLoaderSimple"
},
"widgets_values": [
"revAnimated_v122.safetensors"
]
}
],
"links": [
[
1,
4,
0,
3,
0,
"MODEL"
],
[
2,
5,
0,
3,
3,
"LATENT"
],
[
3,
4,
1,
6,
0,
"CLIP"
],
[
4,
6,
0,
3,
1,
"CONDITIONING"
],
[
5,
4,
1,
7,
0,
"CLIP"
],
[
6,
7,
0,
3,
2,
"CONDITIONING"
],
[
7,
3,
0,
8,
0,
"LATENT"
],
[
8,
4,
2,
8,
1,
"VAE"
],
[
9,
8,
0,
9,
0,
"IMAGE"
]
],
"groups": [],
"config": {},
"extra": {},
"version": 0.4
}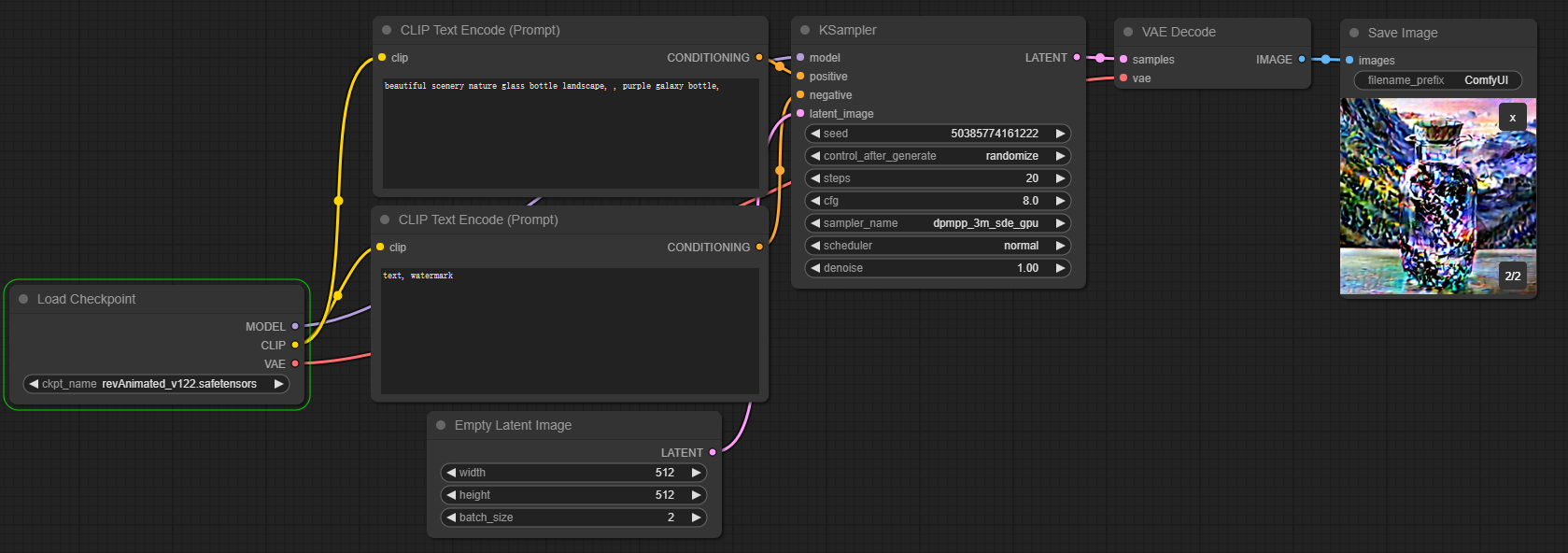
Load Checkpoint->CheckpointLoaderSimple
input_data_all:{'ckpt_name': ['revAnimated_v122.safetensors']}
obj:<nodes.CheckpointLoaderSimple object at 0x7f3f9b3af640>
func:load_checkpoint
nodes.py->CheckpointLoaderSimple.load_checkpoint()
- RETURN_TYPES=("MODEL","CLIP","VAE")=右边的节点;FUNCTION="load_checkpoint"节点中的方法
- INPUT_TYPES=要输入的节点
- out = comfy.sd.load_checkpoint_guess_config(ckpt_path,...)->
-- sd = comfy.utils.load_torch_file(ckpt_path)
-- model = model_config.get_model(sd,"model.diffusion_model.")
-- model.load_model_weights()
-- vae = VAE(sd=vae_sd)
-- clip = CLIP(clip_target, embedding_directory=embedding_directory)
-- m, u = clip.load_sd(clip_sd, full_model=True)
-- model_patcher = comfy.model_patcher.ModelPatcher()
[(<comfy.model_patcher.ModelPatcher object at 0x7f35fc07dab0>, <comfy.sd.CLIP object at 0x7f35fc1937f0>, <comfy.sd.VAE object at 0x7f35ffd36320>)]
CLIP Text Encode(Prompt)->CLIPTextEncode
input_data_all:{'text': ['beautiful scenery nature glass bottle landscape, , purple galaxy bottle,'], 'clip': [<comfy.sd.CLIP object at 0x7f35fc1937f0>]}
obj:<nodes.CLIPTextEncode object at 0x7f35fc193760>
func:"encode"
nodes.py->CLIPTextEncode.encode()
- RETURN_TYPES=("CONDITIONING") FUNCTION="encode" INPUT_TYPES {"required":{"text":("STRING",{"multiline":True}),"clip":("CLIP",)}}
- tokens = clip.tokenize(text)
-- comfyui.comfy.sd.CLIP.tokenize->
-- self.tokenizer.tokenize_with_weights(text,return_word_ids)
--- comfyui.comfy.sd1_clip.SD1Tokenizer.tokenize_with_weights(text,..)
- cond,pooled = clip.encode_from_tokens(tokens,return_pooled=True)
cond:1x77x768 pooled:1x768
Empty Latent Image->EmptyLatentImage
input_data_all:{'width': [512], 'height': [512], 'batch_size': [2]}
obj:<nodes.EmptyLatentImage object at 0x7f36006d7640>
func:"generat"
nodes.py->EmptyLatentImage.generate
- latent = torch.zeros([batch_size, 4, height // 8, width // 8], device=self.device)
({"samples":latent})
KSampler->Ksampler
input_data_all:'seed': [50385774161222], 'steps': [20], 'cfg': [8.0], 'sampler_name': ['dpmpp_3m_sde_gpu'], 'scheduler': ['normal'], 'denoise': [1.0], 'model': [<comfy.model_patcher.ModelPatcher object at 0x7f35fc07dab0>], 'positive':....
obj:<nodes.KSampler object at 0x7f35fc193b20>
func:sample
nodes.py->Ksampler.sample
- common_ksampler(...)->
-- latent_image = latent['sample']
-- noise = comfy.sample.prepare_noise(latent_image, seed, batch_inds)
-- samples = comfy.sample.sample(model, noise, steps, cfg, sampler_name, scheduler, positive, negative, ....)
--- real_model, positive_copy, negative_copy, noise_mask, models = prepare_sampling(model, noise.shape, positive, negative, noise_mask)
--- sampler = comfy.samplers.KSampler(real_model, steps=steps, device=model.load_device, sampler=sampler_name, scheduler=scheduler, denoise=denoise, model_options=model.model_options)
--- samples = sampler.sample(noise, ....)
....