大数据开发(离线实时音乐数仓)
- 一、数据库与ER建模
- 1、数据库三范式
- 2、ER实体关系模型
- 二、数据仓库与维度建模
- 1、数据仓库(Data Warehouse、DW、DWH)
- 1、关系型数据库很难将这些数据转换成企业真正需要的决策信息,原因如下:
- 2、数据仓库是面向主题的、集成的(非简单的数据堆积)、相对稳定的、反应历史变化的数据集合,数仓中的数据是有组织有结构的存储数据集合,用于对管理决策过程的支持。
- 2、维度建模
- 1、事实表
- 2、维度表
- 3、星型模型、雪花型模型
- 三、数据仓库的分层
- 1、数据仓库分层设计
- 2、数据仓库分层案例
- 四、项目架构.
- 五、数据来源及采集
- 六、数据仓库模型
- 七、Azkaban
- 八、Superset
- 九、第一个业务:歌曲热度与歌手热度排行
- 1、需求
- 2、模型设计
- 3、数据处理流程
- 4、使用 Azkaban 配置任务流
- 4、使用 SuperSet 数据可视化
- 十、第二个业务:机器详细信息统计
- 1、需求
- 2、模型设计
- 3、数据处理流程
- 4、使用 Azkaban 配置任务流
- 5、使用 SuperSet 数据可视化
- 十一、第三个业务:日活跃用户统计
- 1、需求
- 2、 模型设计
- 3、 数据处理流程
- 4、使用 Azkaban 配置任务流
- 5、使用 SuperSet 数据可视化
- 十二、第四个业务:商户营收统计
- 1、需求
- 2、模型设计
- 3、数据处理流程
- 4、使用 Azkaban 配置任务流
- 十三、第五个业务:地区营收日报统计
- 1、需求
- 2、模型设计
- 3、数据处理流程
- 4、使用 Azkaban 配置任务流
- 十四、第六个业务:实时统计所有用户的 pv,uv
- 1、需求
- 2、数据采集接口及数据生产
- 3、数据处理流程
- 十五、 第七个业务:实时统计歌曲热榜
- 1、需求
- 2、数据采集接口及数据生产
- 3、数据处理流程
一、数据库与ER建模
1、数据库三范式
第一范式:原子性,字段不可分
第二范式:唯一性,一个表只能说明一个事物,有主键,非主键字段依赖主键
第三范式:非主键字段不能相互依赖,不存在传递依赖
2、ER实体关系模型
将事物抽象为“实体”、“属性”、“关系”来表示数据关联和事物描述。
一对一关系、一对多关系、多对多关系。
二、数据仓库与维度建模
1、数据仓库(Data Warehouse、DW、DWH)
1、关系型数据库很难将这些数据转换成企业真正需要的决策信息,原因如下:
1、一个企业中可能有很多管理系统平台,企业数据分散在多种互不兼容的系统中。
2、关系型数据库中存储的数据一般是最基本的、日常事务处理的、面向业务操作的数据,
数据一般可以更新状态,删除数据条目等。
3、对于战略决策来说,决策者必须从不同的商业角度观察数据,关系型数据库只是面向
基本的业务操作。
2、数据仓库是面向主题的、集成的(非简单的数据堆积)、相对稳定的、反应历史变化的数据集合,数仓中的数据是有组织有结构的存储数据集合,用于对管理决策过程的支持。
面向主题:主题是指使用数据仓库进行决策时所关心的重点方面,每个主题都对应一个相应的分析领域,一个主题通常与多个信息系统相关。
数据集成:在对原有分散的数据库数据抽取、清理的基础上经过系统加工、汇总和整理得到的,必须消除源数据中的不一致性,以保证数据仓库内的信息是关于整个企业的一致的全局信息,这个过程中会有 ETL 操作,以保证数据的一致性、完整性、有效性、精确性。
相对稳定:数据操作主要是数据查询。
反映历史变化:记录企业从过去某一时点(如开始应用数据仓库的时点)到当前的各个阶段的信息。
2、维度建模
实体-关系(ER)建模遵循第三范式,以消除数据冗余为目标的设计技术。维度建模是面向分析,为了提高查询性能可以增加数据冗余,反规范化的设计技术。
1、事实表
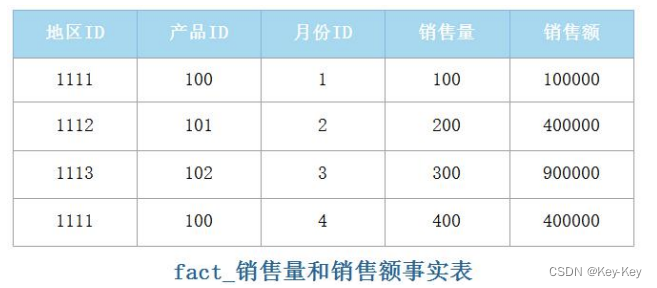
1、事实表中每个列通常要么是键值列,要么是度量列。在以上事实表的示例中,“地区 ID”、“产品 ID”、“月份 ID”为键值列,“销售量”、“销售额”为度量列,所谓度量列就是列的数据可度量,度量列一般为可统计的数值列。
2、事实表中一般会使用一个代号或者整数来代表维度成员,而不使用描述性的名称。
3、在事实表中使用代号或者整数键值时,维度成员的名称需要放在另一种表中,也就是维度表。
4、在数据仓库中,事实表的前缀为“fact”。
2、维度表
维度表包含了维度的每个成员的特定名称。
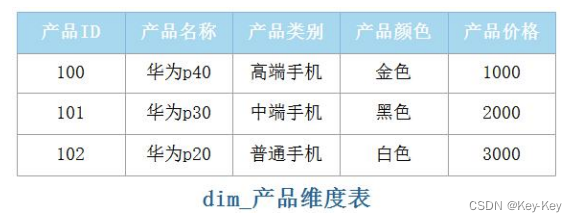
1、“产品名称”是产品维度表中的一个属性,维度表中可以包含很多属性列。
2、维度表中的键属性必须为维度的每个成员包含一个对应的唯一值。
3、在维度表中“产品 ID”类似关系型数据库中的主键,在事实表中“产品 ID”类似关系型数据库中的外键。
4、在数据仓库中,维度表的前缀为"dim"
3、星型模型、雪花型模型
星型模型:所有的维度表都由连接键连接到事实表
雪花型模型:有一个或多个维表没有直接连接到事实表上,而是通过其他维表连接到事实表上
对于雪花模型,一般符合三范式设计;而星型模型,维度表设计不符合三范式设计,利用冗余牺牲空间来避免模型过于复杂,提高易用性和分析效率。
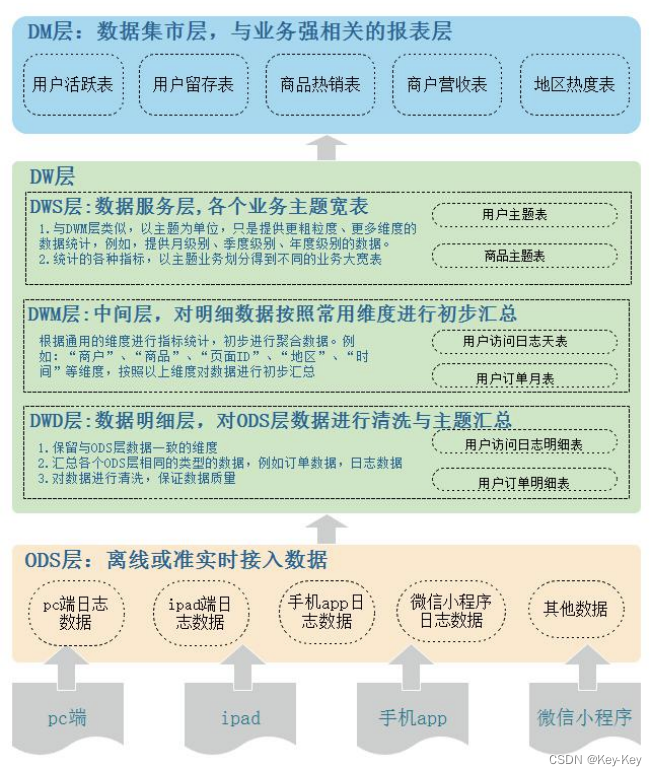
三、数据仓库的分层
1、数据仓库分层设计

ODS(Operational Data Store)层 - 操作数据层
为了考虑后续可能需要追溯数据问题,因此对于这一层就不建议做过多的数据清洗工作,原封不动地接入原始数据即可。
DW(Data Warehouse)层 - 数据仓库层
将从 ODS 层中获得的数据按照主题建立各种数据模型,每一个主题对应一个宏观的分析领域,数据仓库层排除对决策无用的数据,提供特定主题的简明视图。DW 层又细分为 DWD(Data Warehouse Detail)层、DWM(Data Warehouse Middle)层和 DWS(Data Warehouse Service)层。
数据明细层:DWD(Data Warehouse Detail)
提供更干净的数据,退化维度。
数据中间层:DWM(Data Warehouse Middle)
对通用的维度进行聚合操作,算出相应的统计指标,方便复用。
数据服务层:DWS(Data Warehouse Service)
按照主题划分,如订单、用户等,生成字段比较多的宽表。
DM(Data Mart)层 - 数据集市层
整合汇总成分析某一个主题域的报表数据。
2、数据仓库分层案例
四、项目架构.
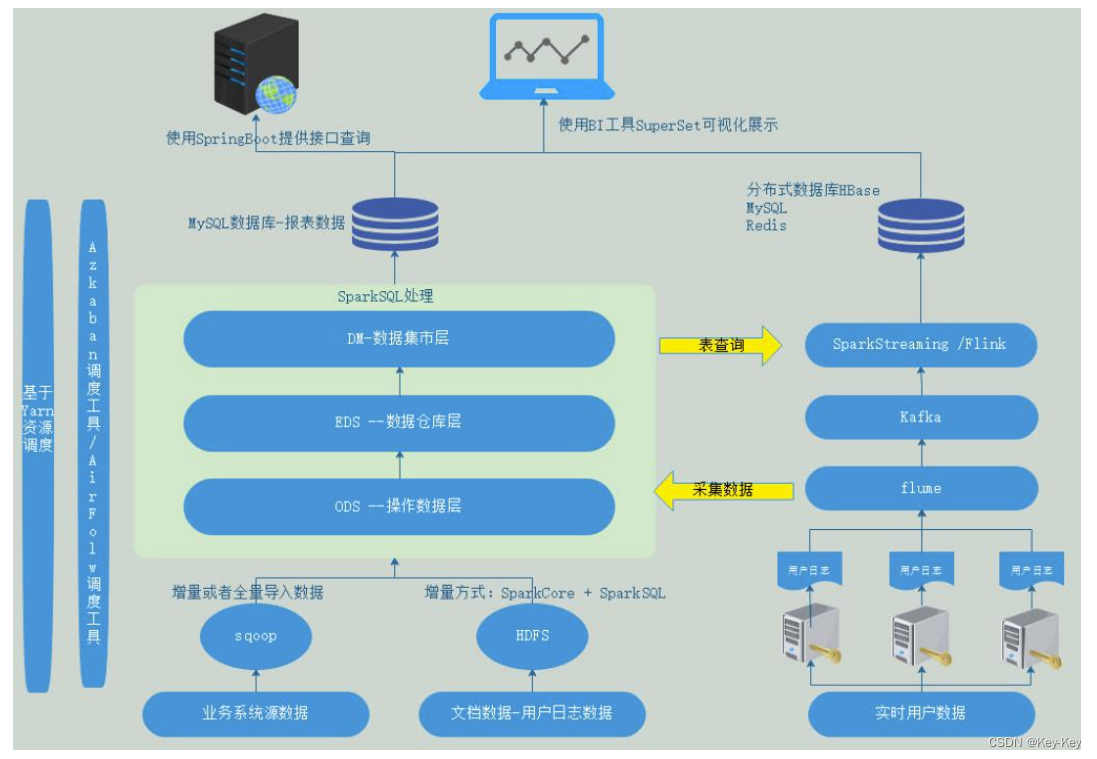
五、数据来源及采集
一类是产生的订单数据,会记录到业务数据库。后期直接通过 sqoop 直接抽取 MySQL 中的数据到 HDFS。另外一类是通过 http 请求,上传到专门采集数据的日志服务器上,每天由运维人员将数据打包上传到数据中心平台某个目录下,然后由定时任务定时来执行 Spark 任务拉取数据,上传至 HDFS 中。这里读取压缩数据使用 SparkCore 进行处理,处理之后将数据以 parquet 格式或者 json 格式存储在 HDFS 中即可。
六、数据仓库模型
数据仓库按照主题分为三个主题:用户、机器、内容(歌曲相关、歌手相关)。每个主题下面都有对应的表。数据仓库的设计分为三层,如下:
ODS 层:
外部数据源:网易云爬取歌曲热度数据、歌手热度数据,爬取数据是 json 格式的数据。
内部数据源:主要有 MySQL 和客户端上传 json 数据。MySQL 使用 Sqoop 抽取数据到 HDFS 中,导入 ODS 层。客户端产生日志到客户端服务器,客户端服务器由运维人员每天将数据压缩成包导入到 HDFS。
EDS 层:
负责信息集成、轻度汇总类数据。例如:将 ODS据进行清洗。
以上 ODS 层和 EDS 层使用 Spark 代码处理数据,然后利用 SparkSQL 读取 ODS 层数据,保存到 Hive 的 EDS 层。
DM 层:
DM 层的数据有一部分是存储在 Hive 表中,或者保存分析结果到 MySQL、HBase。
EDS 层数据是 parquet 格式的数据,放在 Hive 的主要原因是后期使用 Kylin 查询一些业务,数据放 MySQL 的都是结果数据,放在 HBase 的原因是设涉及到大表的明细查询。
七、Azkaban
工作流的调度器
八、Superset
轻量级的数据查询和可视化方案。
九、第一个业务:歌曲热度与歌手热度排行
1、需求
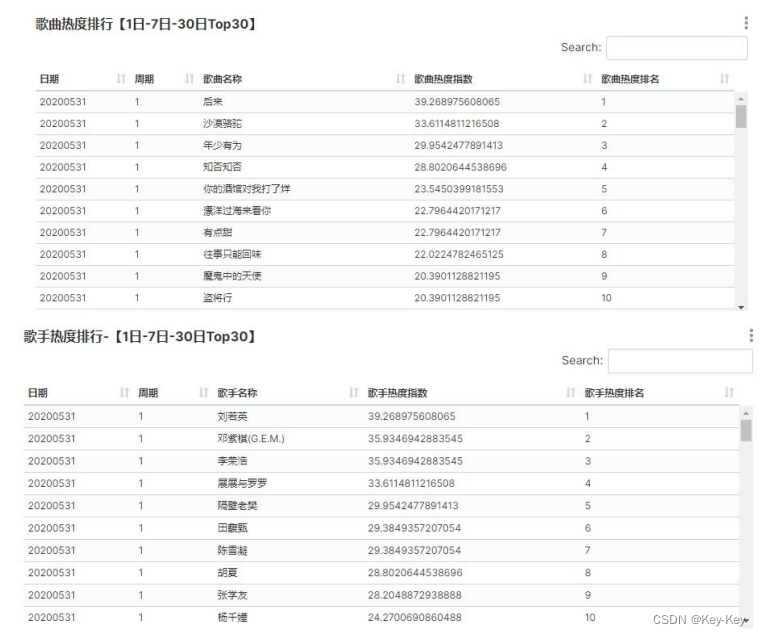
需求是根据用户在各个歌曲点唱机上的点歌行为,来统计最近昨日,近 7 日,近 30 日的歌曲点唱量、歌曲点赞量、点唱用户数、点唱订单数、7 日和 30 日最高点唱量、7 日和30 日最高点赞量及各个周期的歌曲热度和歌手热度。
2、模型设计
- 歌曲歌手的基本信息
这些信息放在业务系统的关系型数据库 MySql song 表中。通过 sqoop 每天定覆盖抽取到数据仓库 Hive 中的 ODS 层中。 - 用户在机器上的点歌行为数据
这部分数据是用户在各个机器上当天的点歌播放行为数据,这些数据是运维每天零点打包以 gz 压缩文件的方式上传到HDFS平台。
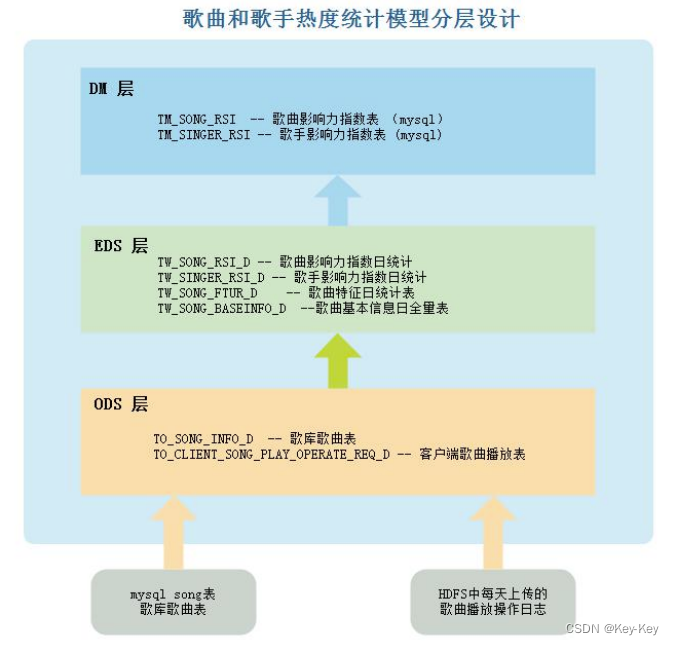
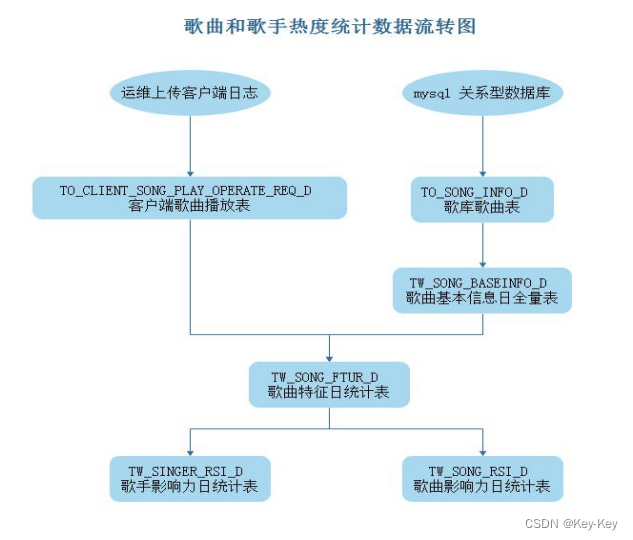
3、数据处理流程
1、准备客户端日志,上传至 HDFS 中
2、清洗客户端日志数据,保存到数仓 ODS 层
3、抽取 MySQL 中 song 数据到Hive ODS
4、清洗“歌库歌曲表”生成“歌曲基本信息日全量表”
是对原来数据字段切分,脏数据过滤,时间格式整理,字段提取等操作。
5、EDS 层生成“歌曲特征日统计表”
6、统计歌手和歌曲热度
注意问题 1:
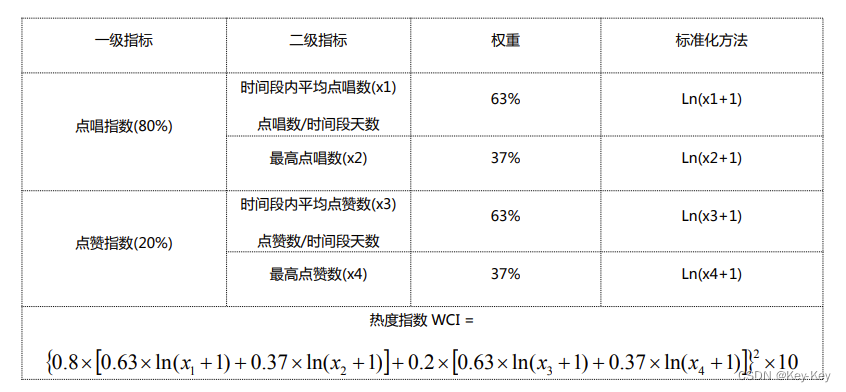
注意问题 2:
“TW_SONG_FTUR_D”进行统计得到歌手影响力指数日统计表“TW_SINGER_RSI_D”和歌曲影响力指数日统计表“TW_SONG_RSI_D”时,分别还将对应的结果使用 SparkSQL 保存到了 MySQL 中。
4、使用 Azkaban 配置任务流
1、清洗客户端日志脚本
2、mysql 数据抽取数据到 Hive ODS脚本
3、清洗歌库歌曲表脚本
4、生成歌曲特征日统计表脚本
5、生成歌曲热度表脚本
6、生成歌手热度表脚本
7、编写 azkaban 各个 job 组成任务流
8、将以上 6 个 job 打包到压缩包中,在 azkaban 中提交执行即可。
4、使用 SuperSet 数据可视化
1、登录 superset
2、 加载数据源
3、加载数据表
4、修改表中对应字段显示名称
5、编辑图表
6、面板可视化展示
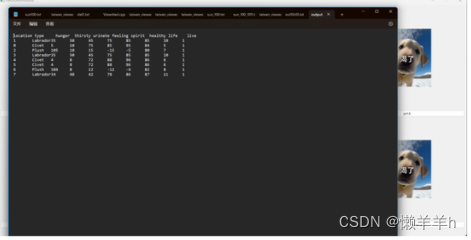
十、第二个业务:机器详细信息统计
1、需求
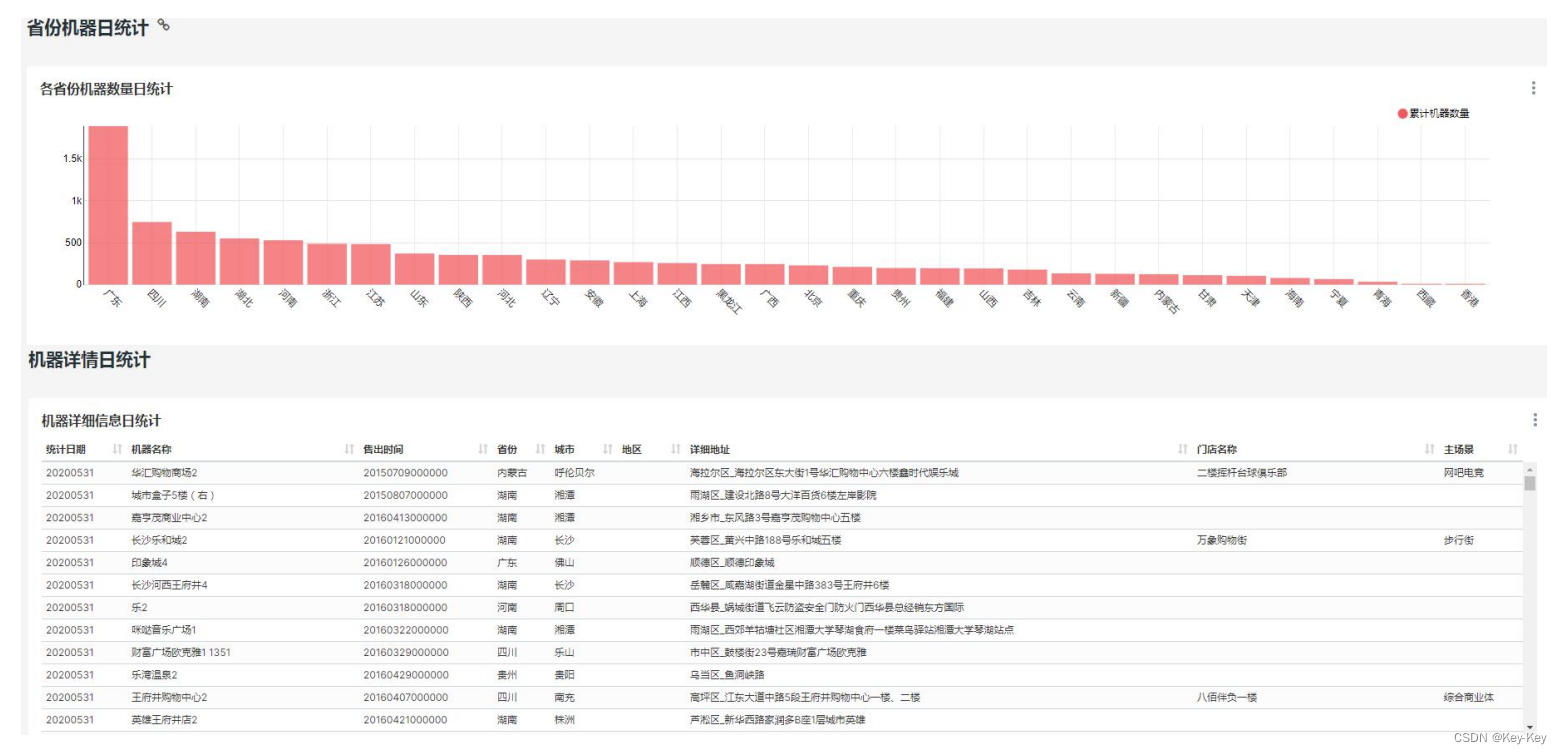
2、模型设计
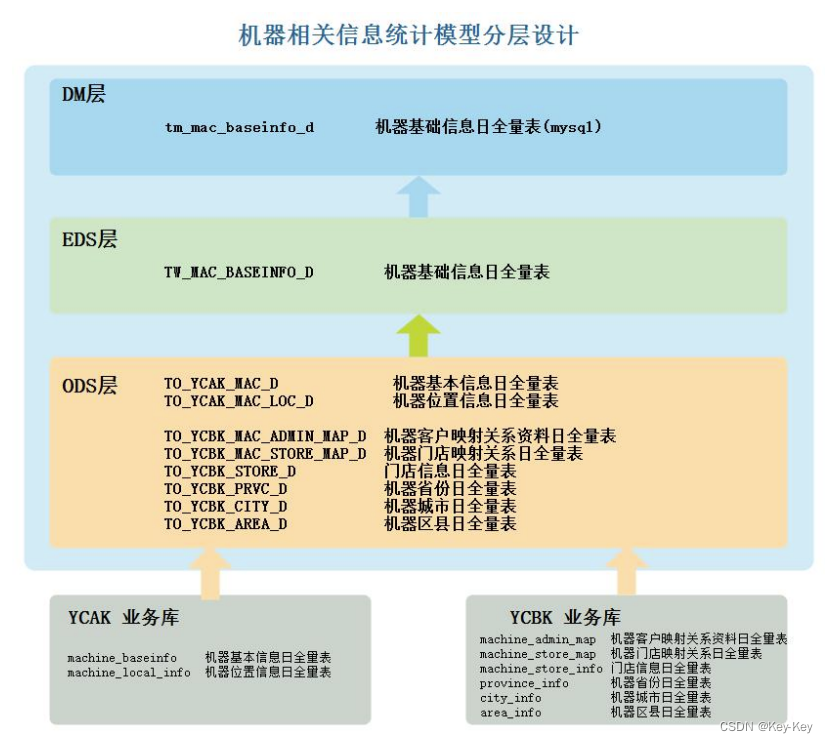
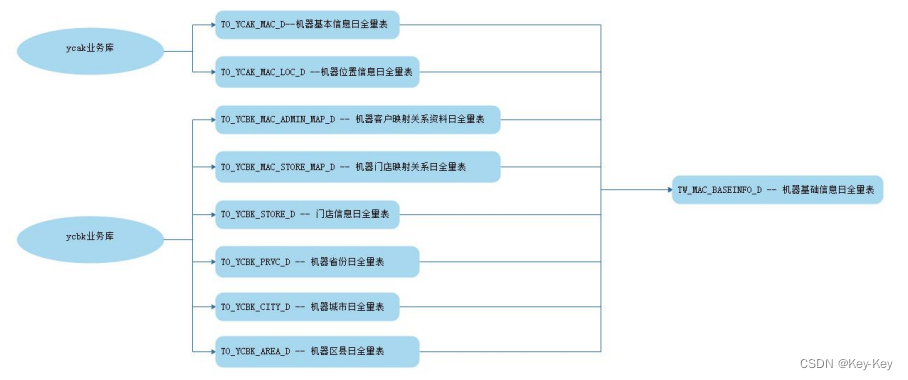
3、数据处理流程
1、将数据导入到对应的 MySQL 业务库中
2、使用 Sqoop 抽取数据到 Hive ODS层
3、代码对 ODS 层数据进行 ETL 清洗
4、使用 Azkaban 配置任务流
1、首先在 Hive 中创建对应的 ODS,EDS 层的表
2、准备好抽取 MySql 数据表的脚本
3、编写提交 Spark 任务处理数据
4、编写 azkaban 任务流,并提交执行
5、使用 SuperSet 数据可视化
十一、第三个业务:日活跃用户统计
1、需求
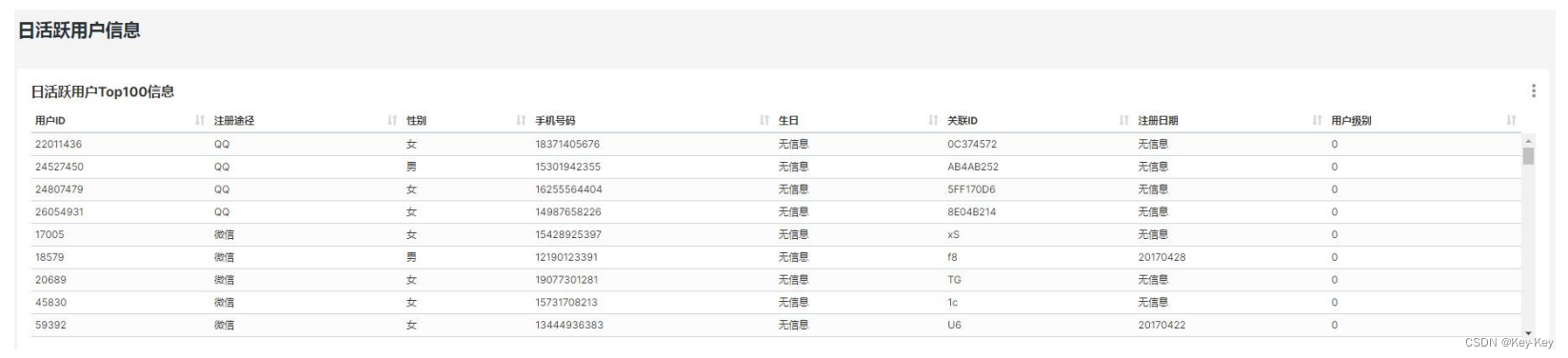
每天统计最近 7 日活跃用户的详细信息
2、 模型设计
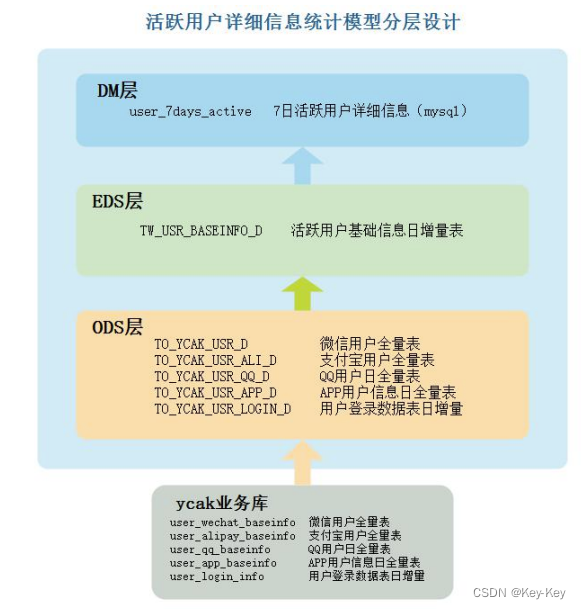
最终获取 7 日用户活跃信息从 EDS 层“TW_USR_BASEINFO_D"表统计得到,这里将统计到的 7 日活跃用户情况存放在 DM 层,这里通过 SparkSQL直接将结果存放在“user_7days_active”表中,提供查询展示。
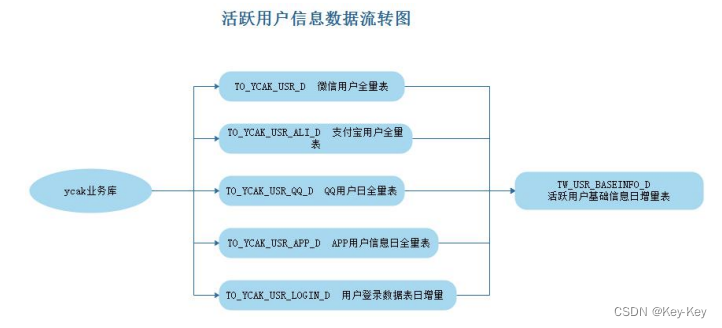
3、 数据处理流程
1、将数据导入 mysql 数据库中
2、使用 Sqoop 抽取 mysql 数据到ODS层
3、使用 SparkSQL 对 ODS 层数据进行清洗
4、使用 Azkaban 配置任务流
1、确保在 Hive 中创建各个 ODS 层表及 EDS 层表
2、准备抽取 mysql 数据的 sqoop 脚本
3、编写提交 Spark 任务处理数据的脚本
4、编写 azkaban 任务进行提交
5、使用 SuperSet 数据可视化
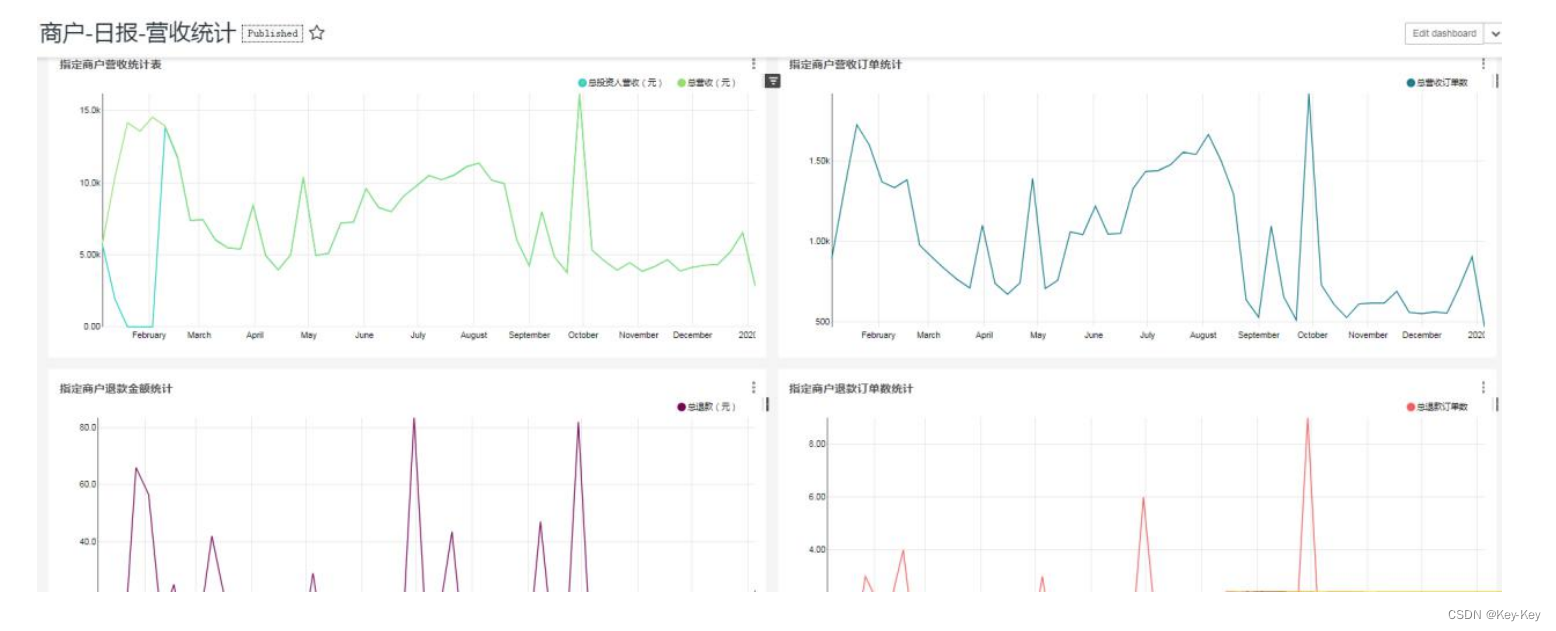
十二、第四个业务:商户营收统计
1、需求
指的是统计投资人、代理人、合伙人各部分营收情况
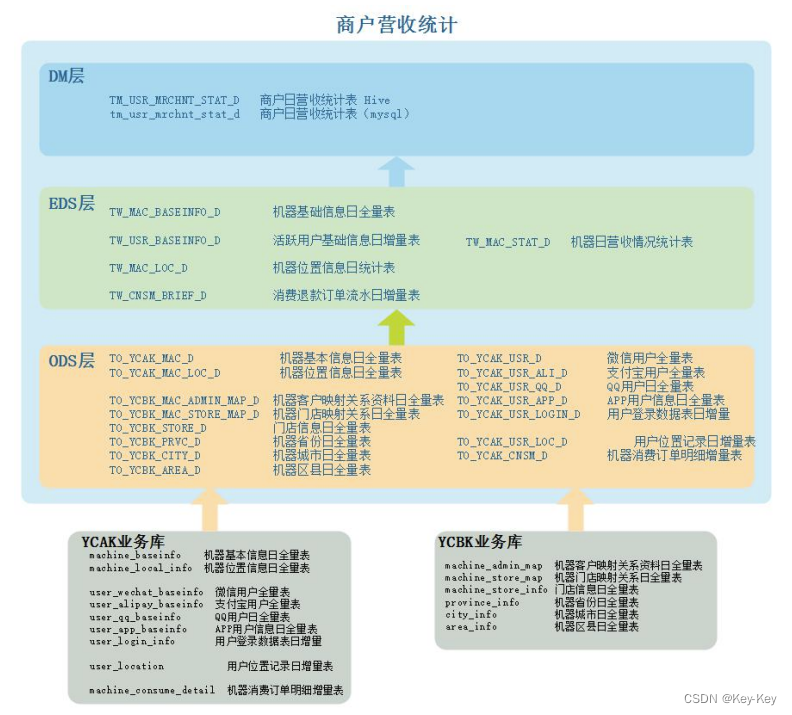
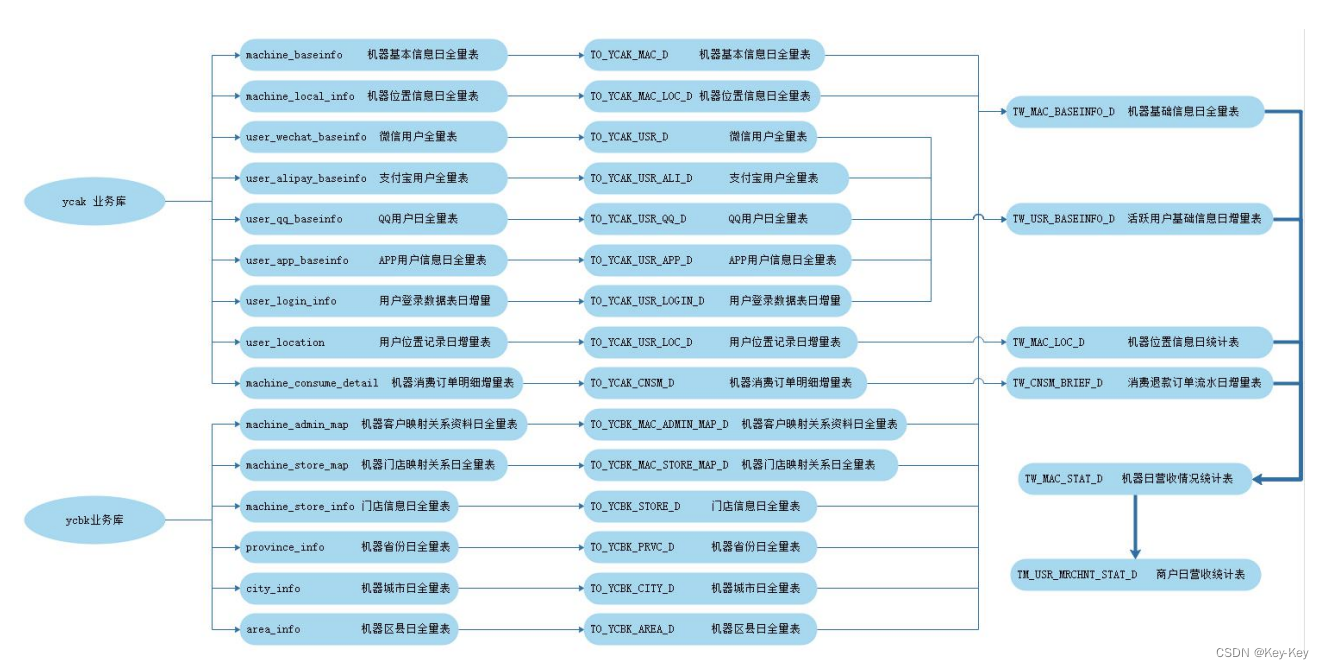
2、模型设计
1、TW_MAC_BASEINFO_D 机器基础信息日全量表
含每天统计到的机器的歌库版本、系统版本、所处位置、门店名称、场景情况、投资人分层比例、代理人分层比例、合伙人分层比例、公司分层比例、代理人信息等数据。
2、TW_MAC_LOC_D 机器位置信息日统计表
高德api,获取每天机器所在的位置 。
3、TW_CNSM_BRIEF_D 消费退款订单流水日增量表
根据消费退款订单流水日增量表可以统计得到每天每个机器的订单、收入、退款情况,后期统计商户营收情况时,需要从此表中获取对应每台机器当天的订单、收入、退款情况。
4、TW_USR_BASEINFO_D 活跃用户基础信息日增量表
3、数据处理流程
1、将各个业务库的数据导入到 Mysql 中
2、在 Hive 中创建以上模型设计的表
3、执行第二个业务-机器详细信息统计
4、执行第三个业务-日活跃用户统计
5、使用 sqoop 抽取 mysql 数据到 ODS
使用 Sqoop 每天增量抽取 mysql “ycak”库下的 user_location 用户位日增量表数据到 ODS 层 TO_YCAK_USR_LOC_D表中。
使用 Sqoop 每天增量抽取 MySQL“ycak”库下的“machine_consume_detail”机器消费订单明细表到 ODS 层的 TO_YCAK_CNSM_D表。
6、使用 SparkSQL 处理 ODS 层数据得到 EDS层数据
清洗用户位置记录日增量表数据、清洗机器消费订单明细增量表
7、针对 EDS 层数据聚合得到 TW_MAC_STAT_D 机器日统计表数据
8、 针对 TW_MAC_STAT_D 机器日统计表数据得到 DM 层数据
4、使用 Azkaban 配置任务流
十三、第五个业务:地区营收日报统计
1、需求
根据“机器日营收情况统计表”,每天统计省市总营收、总退款、总订单数、总退款订单数、总消费用户数、同退款用户数。
2、模型设计
根据业务四中统计的“TW_MAC_STAT_D”机器日营收情况统计表,按照省市字段聚合得到以上各个指标。
在 Hive 中建表:TM_MAC_REGION_STAT_D 地区营收日统计表。
3、数据处理流程
使用 SparkSQL 对 ODS 层数据进行清洗。
4、使用 Azkaban 配置任务流
十四、第六个业务:实时统计所有用户的 pv,uv
1、需求
全网用户在实时操作机器的同时,可以使用数据采集接口将实时用户登录操作数据进行采集,针对这些数据可以实时统计每台机器实时的 pv/uv,以及pv/uv,并需要实时保存至 Redis 或者关系型数据库 mysql 中。
2、数据采集接口及数据生产
数据采集接口原理是利用 SpringBoot 提供日志采集服务接口,在 web 系统中当用户操作某个需要监控的行为时,调用 SpringBoot 对应的数据服务接口,通过 Log4j 日志功能将对应的日志实时写入到指定的目录日志文件中,再通过 Flume 监控对应的日志目录,将日志实时采集到 Kafka 中,进而使用流式处理框架进行数据分析处理。
3、数据处理流程
1、在 Kafka 中创建对应的日志接收 topic
2、将日志采集接口打包部署到 mynode5 节点上
3、启动 Flume 日志采集脚本监控目录日志
Flume 配置文件配置读取目录下的日志到 Kafka中
4、启动 SparkStreaming 读取 Kafka 中数据实时统计PV,UV
5、启动生产数据代码“ProdeceUserLoginLog”,调用日志采集接口生产数据
6、在 Redis 中查看对应的结果
十五、 第七个业务:实时统计歌曲热榜
1、需求
实时采集用户在机器上点播歌曲的日志数据,统计每分钟歌曲点播热榜。将结果保存到关系型数据库 mysql 中。
2、数据采集接口及数据生产
数据采集接口原理是利用 SpringBoot 提供日志采集服务接口,在 web 系统中当用户操作某个需要监控的行为时,调用 SpringBoot 对应的数据服务接口,通过 Log4j 日志功能将对应的日志实时写入到指定的目录日志文件中,再通过 Flume监控对应的日志目录,将日志实时采集到 Kafka 中,进而使用流式处理框架进行数据分析处理。
3、数据处理流程
1、在 Kafka 中创建对应的日志接收 topic
2、将日志采集接口打包部署到 mynode5 节点上
3、启动 Flume 日志采集脚本监控目录日志
Flume 配置文件配置读取目录下的日志到 Kafka中
4、启动 SparkStreaming 读取 Kafka 中数据实时统计PV,UV
5、启动生产数据代码“ProdeceUserLoginLog”,调用日志采集接口生产数据
6、在 Redis 中查看对应的结果





![[操作系统课设]GeeKOS操作系统的研究与实现](https://img-blog.csdnimg.cn/direct/2545ef2d5fbb4416abb7b3e1cb7c6e14.png)