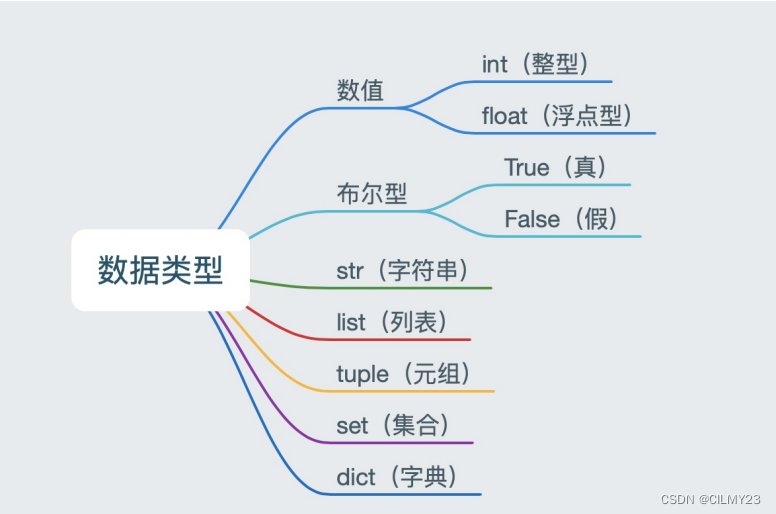
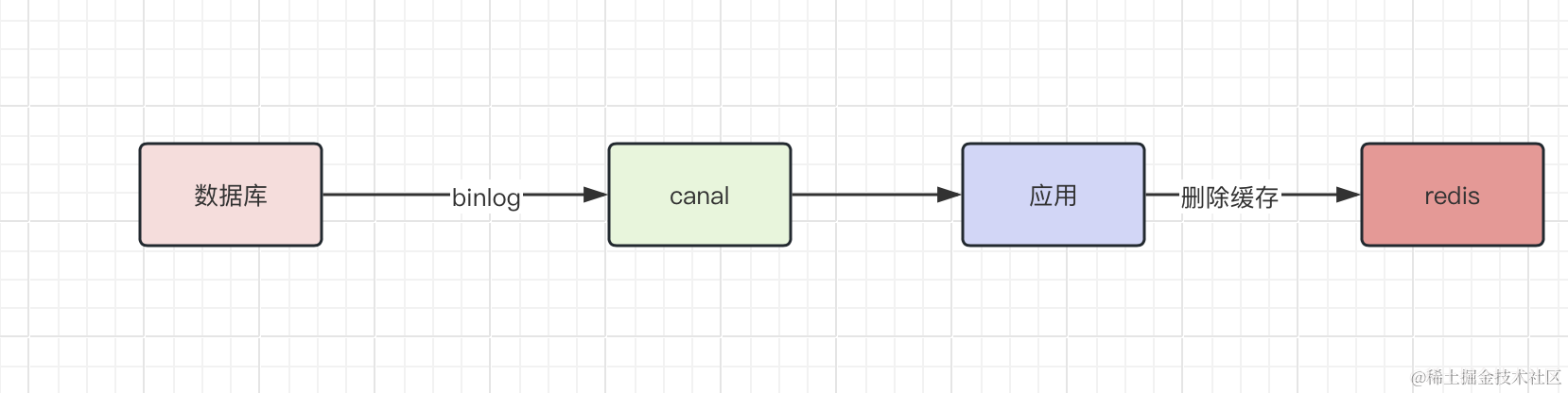
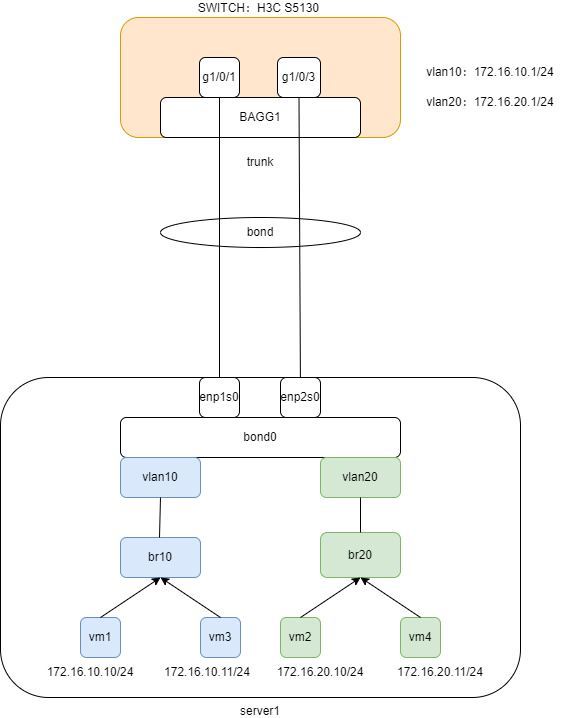
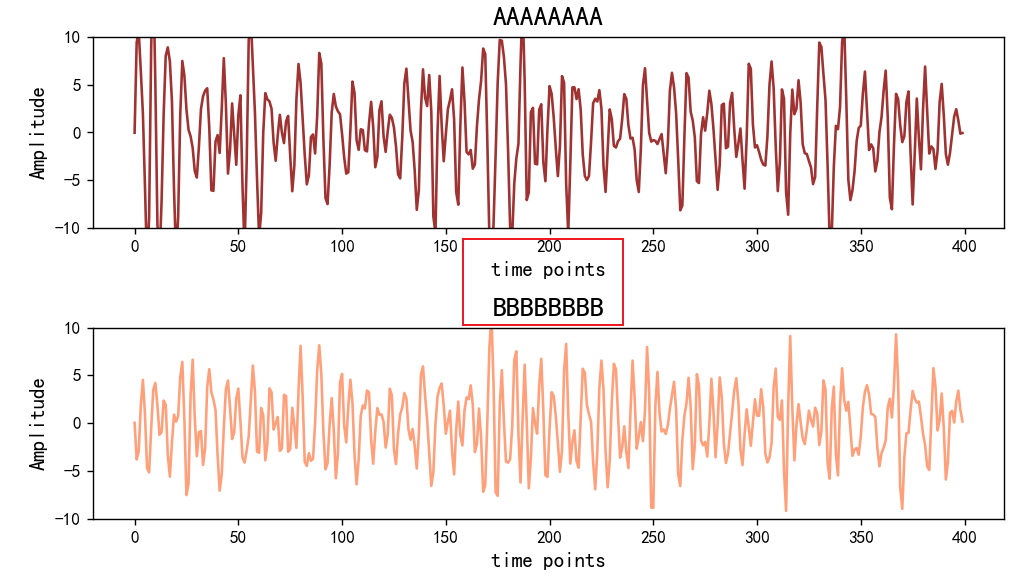
InfoNCE loss是一种用于自监督学习的损失函数,通常用于训练对比学习模型,如自编码器或神经网络。全称是"InfoNCE: Contrastive Estimation of Neural Entropy",基于对比学习的思想,旨在最大化正样本的相似性,同时最小化负样本的相似性。
InfoNCE loss的一般形式如下:
I
n
f
o
N
C
E
L
o
s
s
=
−
l
o
g
(
e
x
p
(
s
i
m
i
l
a
r
i
t
y
(
x
i
,
y
i
)
)
/
(
e
x
p
(
s
i
m
i
l
a
r
i
t
y
(
x
i
,
y
i
)
)
+
Σ
j
≠
i
e
x
p
(
s
i
m
i
l
a
r
i
t
y
(
x
i
,
y
j
)
)
)
InfoNCE Loss = - log( exp(similarity(x_i, y_i)) / (exp(similarity(x_i, y_i)) + Σ j≠i exp(similarity(x_i, y_j)) )
InfoNCELoss=−log(exp(similarity(xi,yi))/(exp(similarity(xi,yi))+Σj=iexp(similarity(xi,yj)))
其中,
similarity(x_i, y_i) 表示样本 x_i 和对应的正样本 y_i 之间的相似性得分。
Σ j≠i 表示对所有其他负样本的求和。
exp() 表示指数函数。
InfoNCE loss的目标是最大化正样本之间的相似性得分,同时最小化负样本之间的相似性得分,从而促使模型学习到有意义的特征表示。通过优化InfoNCE loss,模型可以学习到对数据进行有效编码的特征表示,适用于自监督学习任务中的特征学习和表示学习。InfoNCE loss在对比学习和自监督学习中得到广泛应用,能够有效地提高模型的性能和泛化能力。
在其他应用中,其形式也可以是: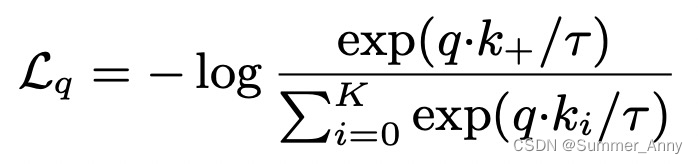
InfoNce Loss
参考:https://cloud.tencent.com/developer/article/2117162
Representation learning with contrastive predictive coding(2018)提出infoNce loss,是对比学习中最常用的loss之一,它和softmax的形式很相似,主要目标是给定一个query,以及k个样本,k个样本中有一个是和query匹配的正样本,其他都是负样本。当query和正样本相似,并且和其他样本都不相似时,loss更小。InfoNCE loss可以表示为如下形式,其中r代表temperature,采用内积的形式度量两个样本生成向量的距离。相比softmax,InfoNCE loss使用了temperature参数,以此将样本的差距拉大,提升模型的收敛速度。温度系数越大,模型对负样本的区分度就越低,这样可以纳入更多的负样本。相反,如果温度系数过小,模型就会更加关注那些特别困难的负样本,从而忽略了其他可能的正样本。