最近建了一个技术交流群,欢迎志同道合的同学加入,群里主要讨论:分享业务解决方案、深度分析面试题并解答工作中遇到的问题,同时也能为我提供写作的素材。
欢迎加Q:312519302,进群讨论
前言
在工作中,大多数的系统都在使用缓存,那你有没有想过为什么要使用缓存?使用缓存后,数据与缓存的一致性如何保证?
带着上面的问题,我们一起探索。
我们刚开始做一个项目的时候,刚起步,流量很小,直接读写数据库即可,性能不错,系统稳定,架构如下图:
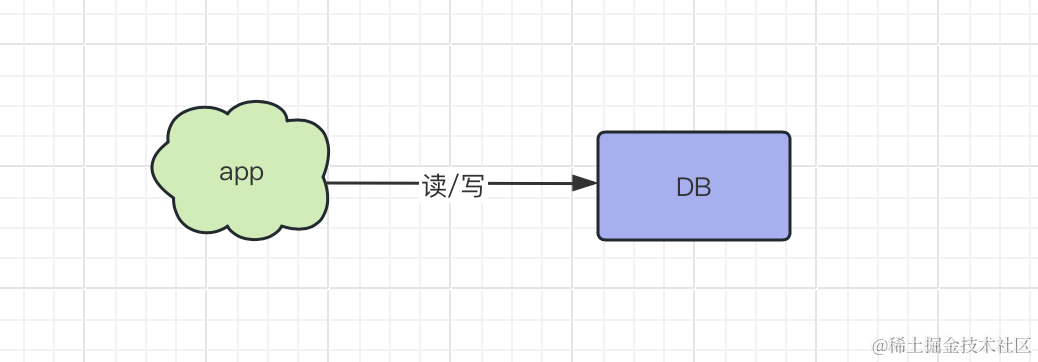
随时时间推移,系统运行一段时间,老板说,要推广我们的系统,给用户赋能,接着搞一波营销,流量激增,结果系统报警了,系统都快挂了,赶紧排查,发现性能瓶颈在数据库。
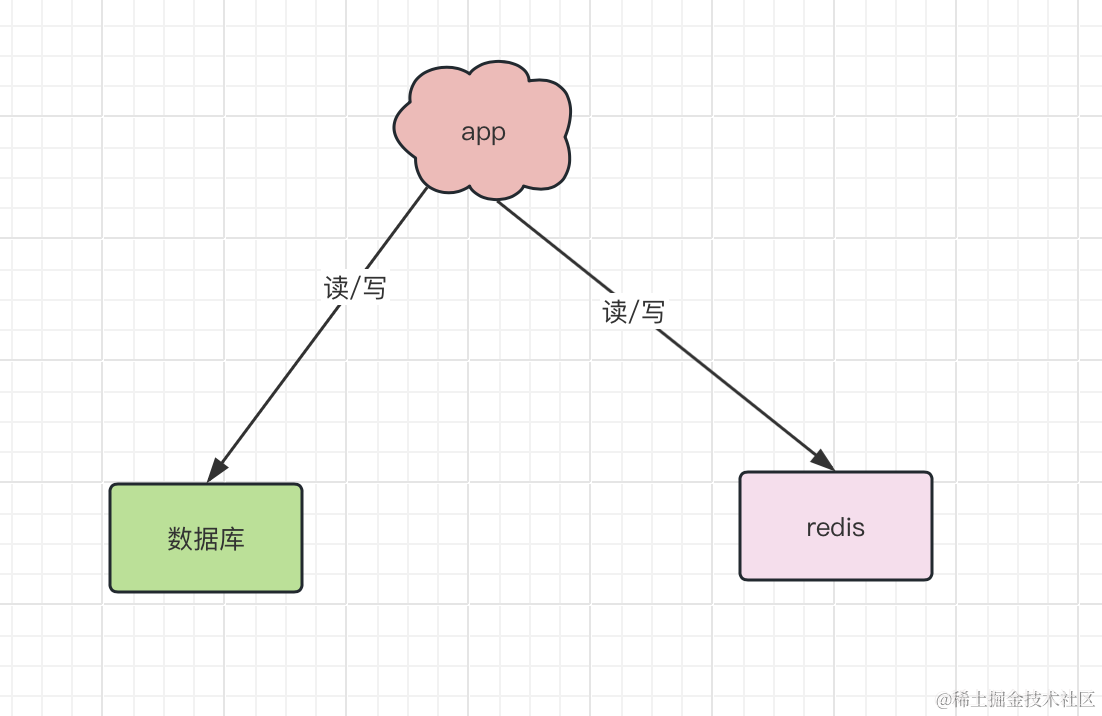
这好办,给服务器加上 Redis,让其作为数据库的缓存。
这样,在客户端请求数据时,如果能在缓存中命中数据,那就查询缓存,不用在去查询数据库,从而减轻数据库的压力,提高服务器的性能。
那我们的架构变为:
看起来非常美好,但是有个问提挡在我们面前,如果数据库的数据有修改的时候,我们是先更新数据库,还是先更新缓存呢?
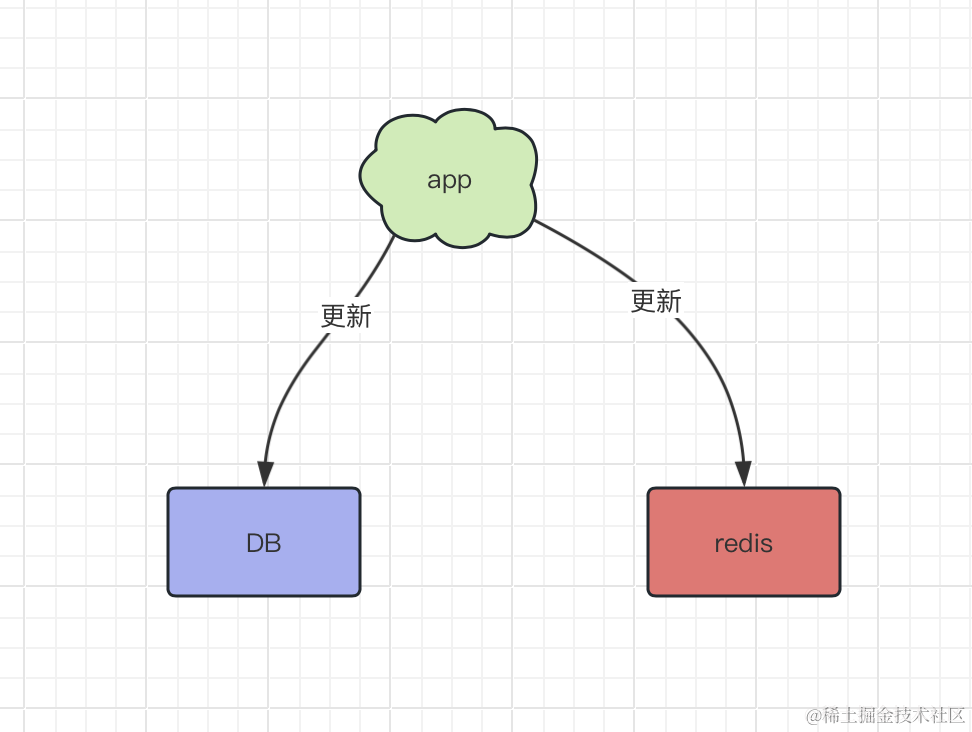
由于引入了缓存,那么在数据更新时,不仅要更新数据库,而且要更新缓存,这两个更新操作存在前后的问题:
- 先更新数据库,再更新缓存
- 先更新缓存,再更新数据库
想了想,为了保证数据是最新的数据,那我们选择 先更新数据库,再更新缓存, 一顿操作猛如虎,系统优化完成后,上线,数据库压力也下来,吞吐量得到明显的提高,心里那个激动啊,我TM真是牛逼,等着老板的嘉奖。
过了一段时间后,有人反馈,我修改了数据后,查看详情,发现数据没变,但是我修改数据的时候,提示我修改成功。擦,难道是系统出bug了?
登录服务器排查,没发现有更新数据库、缓存的失败的信息,但是发现个问题,缓存是修改前的数据,数据是修改后的数据,那这种问题是怎么产生的呢?
进一步分析,发现缓存与数据库不一致的原因是并发导致的
先更新数据库,再更新缓存
并发为什么能导致数据与缓存不一致呢,我们接着分析,我举个例子,用户A与用户B同时修改一条数据
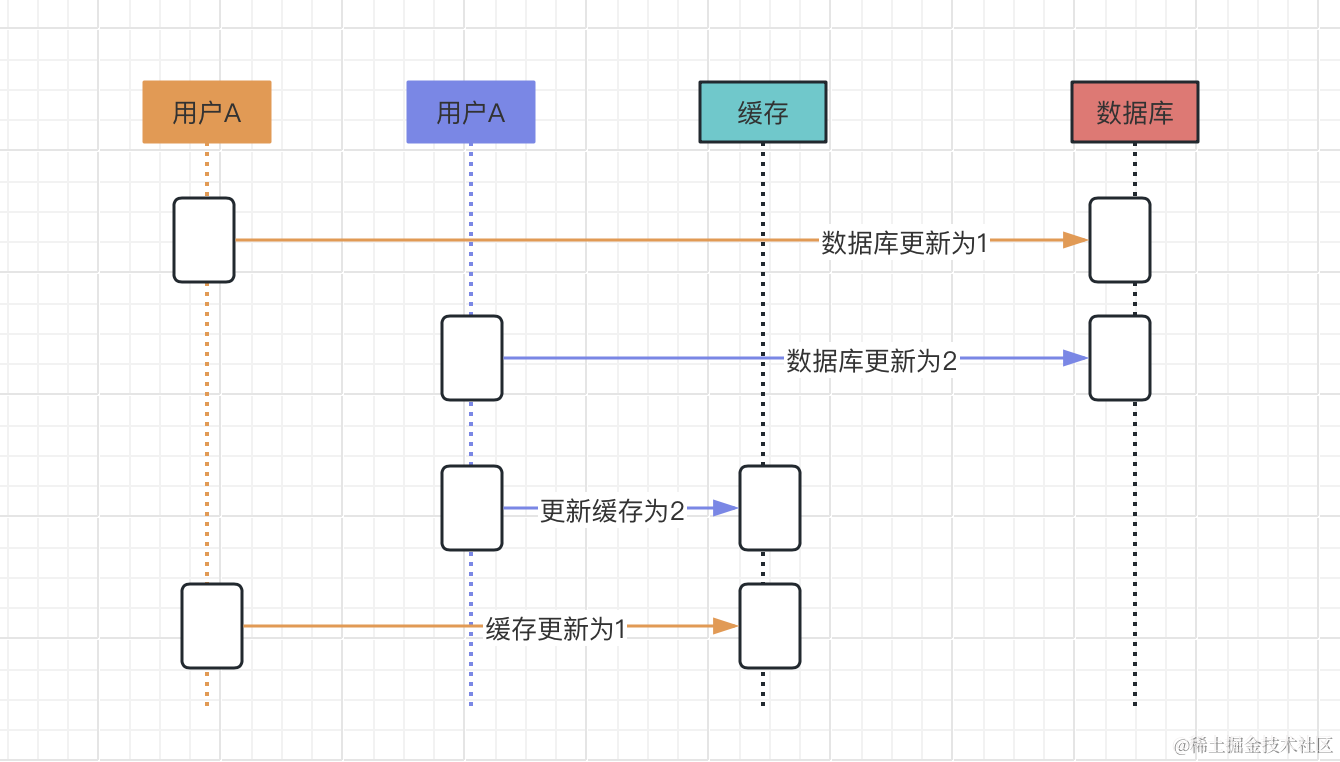
执行步骤:
- 用户A更新数据库为1
- 用户B更新数据库为2****
- 用户B更新缓存2
- 用户A更新缓存为1
从上面可以看出,数据库为2,缓存也应该为1,这就造成了缓存与数据库不一致的现象
那如果我们先更新缓存,再更新数据库呢?
先更新缓存,再更新数据库

执行步骤:
- 用户A更新缓存为1
- 用户B更新缓存2
- 用户B更新数据库为2
- 用户A更新数据库为1
从上面可以看出,数据库为1,缓存也应该为2,还是造成了缓存与数据库不一致的现象
结论: 无论是先更新数据库,再更新缓存,还是先更新缓存,再更新数据库,在并发访问修改一条数据的时候,都会出现不一致的情况
想了想,那不更新缓存了,直接删除缓存。也就是数据库后更新后,直接删除缓存。 在读取数据的时候,查看缓存中有没有数据,没有数据查询数据库,然后再更新缓存。
这个策略有个名字:Cache Aside 策略, 中文:旁路缓存策略
旁路缓存策略
Cache Aside(旁路缓存)策略是最常用的,应用程序直接与「数据库、缓存」交互,并负责对缓存的维护,该策略又可以细分为「读策略」和「写策略」。

写策略的步骤:
- 先更新数据库中的数据,再删除缓存中的数据。
读策略的步骤:
- 如果读取的数据命中了缓存,则直接返回数据;
- 如果读取的数据没有命中缓存,则从数据库中读取数据,然后将数据写入到缓存,并且返回给用户。
问题来了,那我们是先更新数据库,再删除缓存还是先删除缓存,再更新数据库?
先删除缓存,再更新数据库

执行步骤:
- 用户A删除缓存
- 用户B查询缓存,缓存中没有数据
- 用户B查询数据库,得到数据
- 用户B更新缓存数据
- 用户A更新数据库为最新的值
从结果看,缓存的是旧值:1,数据库是最新值:2,在并发读+写的场景下,依然数据库跟缓存不一致。
先更新数据库,再删除缓存

执行步骤
- 用户A查询缓存,缓存未命中
- 用户A查询数据库,得到值为:1
- 用户B更新数据库,值更新为:2
- 用户B删除缓存
- 用户A,把查询到的值1,回写到缓存
从结果看,缓存的是旧值:1,数据库是最新值:2,在并发读+写的场景下,依然数据库跟缓存不一致。
从理论上来分析,先更新数据,再删除缓存,依然存在数据库与缓存不一致的情况,但在实际中,出现不一致的情况概率非常低。
因为缓存的写入速度远远大于写入数据库的速度,为了以防万一,再给缓存数据加一个过期时间,如果真出现不一致的情况,也最多在过期时间的这个区间不一致,过期时间到了,重新更新缓存,也能到达最终一致性
方案选择
以下四种方案,我们都分析了,那我们到底用哪一种呢?
- 先更新数据库,再更新缓存
- 先更新缓存,再更新数据库
- 先更新数据库,再删除缓存
- 先删除缓存,再更新数据库
先说我的观点,也是大厂的方案,强烈推荐:先更新数据库,再删除缓存
原因如下:
- 缓存的写入速度远远大于写入数据库的速度,出现不一致的的概率很低
- 设置过期时间,如果真出现不一致的情况,过期时间到期,重新刷新缓存,能达到最终一致性
- 正常的情况,缓存与数据强一致性,也没那么高的要求,如果真要达到强一致性,系统吞吐量必要下降
题外话:对于一致性的解决方案,我对大厂的方案很感兴趣,想了解他他们是怎么解决的。当进去后,深入了解下,使用的方案也是:先更新数据库,再删除缓存 ,最终一致性,没必要强一致性,原因跟上面三条差不多。
这样是不是很完美了嘛,等等,这种方案还有没有问题,想想…,看下图:

更新数据库,删除缓存是两个操作,如果删除缓存失败了呢(这种概率虽然很低),那缓存中依然是旧值,有没有什么方案解决这个问题呢?
上面的四种方案,无论是先操作数据库,还是操作缓存,都存在这种问题
问题原因知道了,该怎么解决呢?有两种方法:
- 重试机制
- 订阅 MySQL binlog,再操作缓存
如何保证两个操作都执行成功
重试机制
引入消息中间件,比如:rabbitmq
- 如果应用删除缓存失败,发送消息到mq,然后从消息队列中重新读取数据,然后再次删除缓存,这个就是重试机制。当然,如果重试超过的一定次数,还是没有成功,我们就需要向业务层发送报错信息了。
- 如果删除缓存成功,就要把数据从消息队列中移除,避免重复操作,否则就继续重试
订阅 MySQL binlog,再操作缓存
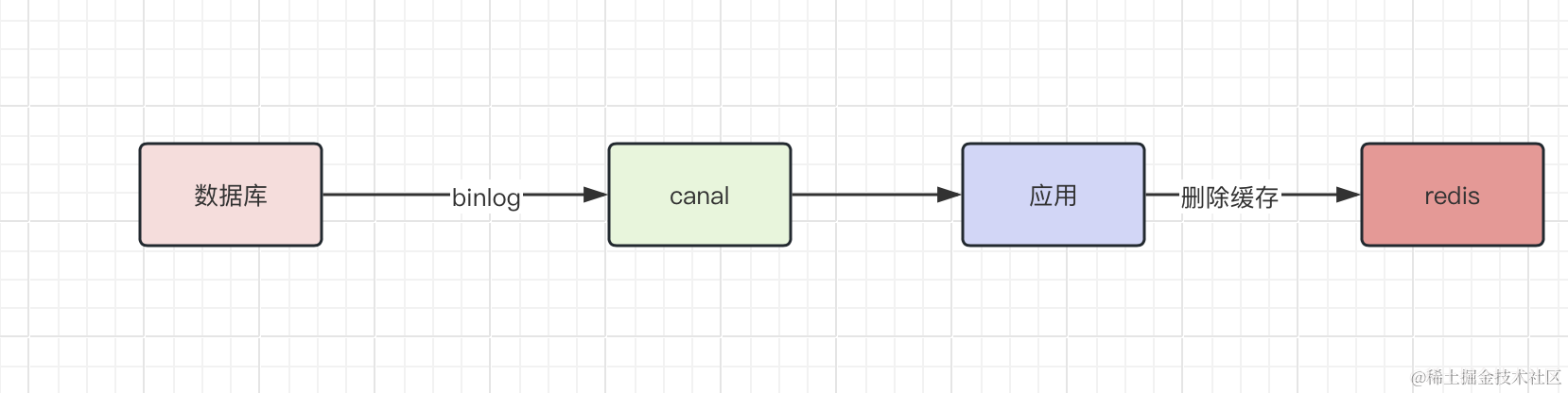
引入canal中间件
canal,译意为水道/管道/沟渠,主要用途是基于 MySQL 数据库增量日志解析,提供增量数据订阅和消费。
canal 工作原理
- canal 模拟 MySQL slave 的交互协议,伪装自己为 MySQL slave ,向 MySQL master 发送dump 协议
- MySQL master 收到 dump 请求,开始推送 binary log 给 slave (即 canal )
- canal 解析 binary log 对象(原始为 byte 流)
所以,如果要想保证「先更新数据库,再删缓存」策略第二个操作能执行成功,我们可以使用「消息队列来重试缓存的删除」,或者「订阅 MySQL binlog 再操作缓存」,这两种方法有一个共同的特点,都是采用异步操作缓存,也可能存在短时间的不一致。
总结
如何保证数据库与缓存一致性?先更新数据库,再删缓存,缓存设置一个过期时间, 这种方案能适用95%以上的场景。
不知道你们在实际工作中,你们的项目,用的那种方案,踩过哪些坑,欢迎留言一起谈论。









![[实战]Springboot与GB28181摄像头对接。摄像头注册上线(一)](https://img-blog.csdnimg.cn/direct/6dde8fa833f645abaa44d5e9c81bb294.png)