Q&A with RAG
Overview
LLMs支持的最强大的应用程序之一是复杂的问答 (Q&A) 聊天机器人,这些应用程序可以回答有关特定源信息的问题,使用一种称为检索增强生成(RAG)的技术。
RAG
RAG 是一种利用额外数据增强 LLM 知识的技术。
LLMs可以推理广泛的主题,但它们的知识仅限于训练它们的特定时间点的公共数据。如果想要构建能够推理私有数据或模型截止日期之后引入的数据的 AI 应用程序,您需要使用模型所需的特定信息来增强模型的知识。引入适当的信息并将其插入模型提示的过程称为检索增强生成 (RAG)。
LangChain 有许多组件旨在帮助构建问答应用程序以及更广泛的 RAG 应用程序。
这里重点关注非结构化数据的问答
RAG Architecture
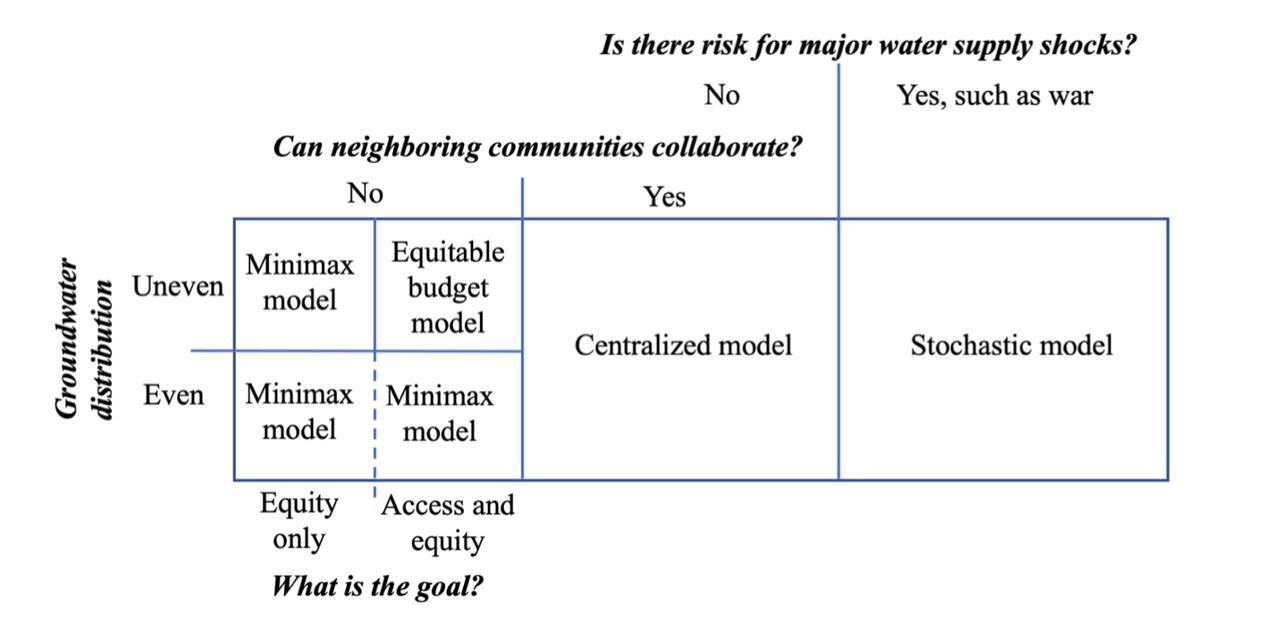
典型的 RAG 应用程序有两个主要组件:
- Indexing:用于从源获取数据并为其建立索引的管道。这通常发生在离线状态。
- Retriever and generation:实际的 RAG 链,它在运行时接受用户查询并从索引中检索相关数据,然后将其传递给模型。
从原始数据到回答的最常见的完整序列如下所示:
Indexing
- Load:首先需要加载数据,通过
DocumentLoaders完成 - Split:
Text splitters将large Documents分成更小的chunks。这对于索引数据和将其传递到模型都很有用,因为大块更难搜索并且不适合模型的有限上下文窗口。 - Store:存储和索引我们的分割,这通常是使用
VectorStore和Embeddings模型来完成的。

Retrieval and generation
- Retrieve:给定用户输入,使用检索器从存储中检索相关分割。
- Generate:
ChatModel / LLM使用包含问题和检索到的数据的提示生成答案

Quickstart
LangChain 有许多组件旨在帮助构建问答应用程序以及更广泛的 RAG 应用程序。为了熟悉这些,我们将基于文本数据源构建一个简单的问答应用程序。在此过程中,我们将介绍一个典型的问答架构,讨论相关的 LangChain 组件,并重点介绍更先进的问答技术的其他资源。我们还将看到 LangSmith 如何帮助我们跟踪和理解我们的应用程序。随着我们的应用程序变得越来越复杂,LangSmith 将变得越来越有帮助。
Preview
创建一个简单的索引管道和 RAG 链,用大约 20 行代码来完成此操作:
import bs4
from langchain import hub
from langchain_community.document_loaders import WebBaseLoader
from langchain_community.vectorstores import Chroma
from langchain_core.output_parsers import StrOutputParser
from langchain_core.runnables import RunnablePassthrough
from langchain_openai import ChatOpenAI, OpenAIEmbeddings
from langchain_text_splitters import RecursiveCharacterTextSplitter
# Load, chunk and index the contents of the blog.
loader = WebBaseLoader(
web_paths=("https://lilianweng.github.io/posts/2023-06-23-agent/",),
bs_kwargs=dict(
parse_only=bs4.SoupStrainer(
class_=("post-content", "post-title", "post-header")
)
),
)
docs = loader.load()
text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=200)
splits = text_splitter.split_documents(docs)
vectorstore = Chroma.from_documents(documents=splits, embedding=OpenAIEmbeddings())
# Retrieve and generate using the relevant snippets of the blog.
retriever = vectorstore.as_retriever()
prompt = hub.pull("rlm/rag-prompt")
llm = ChatOpenAI(model_name="gpt-3.5-turbo", temperature=0)
def format_docs(docs):
return "\n\n".join(doc.page_content for doc in docs)
rag_chain = (
{"context": retriever | format_docs, "question": RunnablePassthrough()}
| prompt
| llm
| StrOutputParser()
)
rag_chain.invoke("What is Task Decomposition?")
'Task decomposition is a technique that breaks down complex tasks into smaller and simpler steps, allowing agents to plan and execute them more effectively. It involves transforming big tasks into multiple manageable tasks, often utilizing prompting techniques like Chain of Thought or Tree of Thoughts. Task decomposition can be done using simple prompting by LLM, task-specific instructions, or with human inputs.'
# cleanup
vectorstore.delete_collection()
Detailed walkthrough
逐步浏览一下上面的代码,以真正了解发生了什么
1. Indexing : Load
首先加载博客文章内容,可以使用DocumentLoaders,从源加载数据并返回文档列表的对象。Document是一个具有一些page_content(str)和metadata(dict)的对象。
本例中,使用WebBaseLoader,使用urllib从Web URL加载HTML,并使用BeautifulSoup将其解析为文本。
可以通过bs_kwargs将参数传递给BeautifulSoup解析器来自定义HTML->text解析。
在这种情况下,只有类为“post-content”、“post-title”或“post-header”的 HTML 标记是相关的,因此我们将删除所有其他标记。
import bs4
from langchain_community.document_loaders import WebBaseLoader
# Only keep post title, headers, and content from the full HTML.
bs4_strainer = bs4.SoupStrainer(class_=("post-title", "post-header", "post-content"))
loader = WebBaseLoader(
web_paths=("https://lilianweng.github.io/posts/2023-06-23-agent/",),
bs_kwargs={"parse_only": bs4_strainer},
)
docs = loader.load()
len(docs[0].page_content)
42823
print(docs[0].page_content[:500])
LLM Powered Autonomous Agents
Date: June 23, 2023 | Estimated Reading Time: 31 min | Author: Lilian Weng
Building agents with LLM (large language model) as its core controller is a cool concept. Several proof-of-concepts demos, such as AutoGPT, GPT-Engineer and BabyAGI, serve as inspiring examples. The potentiality of LLM extends beyond generating well-written copies, stories, essays and programs; it can be framed as a powerful general problem solver.
Agent System Overview#
In
2. Indexing : Split
我们加载的文档长度超过 42k 个字符,这太长了,无法适应许多模型的上下文窗口。即使对于那些可以在其上下文窗口中容纳完整帖子的模型,模型也可能很难在很长的输入中找到信息。
为了解决这个问题,将Document分割成块以进行嵌入和矢量存储。这可以帮助我们在运行时仅检索博客文章中最相关的部分。
在本例中,我们将把文档分成 1000 个字符的块,块之间有 200 个字符的重叠。重叠有助于降低将语句与与其相关的重要上下文分开的可能性。
我们使用 RecursiveCharacterTextSplitter(递归字符文本分割器),它将使用常见的分隔符(例如换行符)递归地分割文档,直到每个块的大小合适,这是针对一般文本用例推荐的文本分割器。
设置 add_start_index=True ,以便将每个分割文档在初始文档中开始的字符索引保留为元数据属性“start_index”。
from langchain_text_splitters import RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=1000, chunk_overlap=200, add_start_index=True
)
all_splits = text_splitter.split_documents(docs)
len(all_splits)
66
len(all_splits[0].page_content)
969
all_splits[10].metadata
{'source': 'https://lilianweng.github.io/posts/2023-06-23-agent/',
'start_index': 7056}
all_splits[10].page_content
'To avoid overfitting, CoH adds a regularization term to maximize the log-likelihood of the pre-training dataset. To avoid shortcutting and copying (because there are many common words in feedback sequences), they randomly mask 0% - 5% of past tokens during training.\nThe training dataset in their experiments is a combination of WebGPT comparisons, summarization from human feedback and human preference dataset.'
3. Indexing : Store
现在为 66 个文本块建立索引,以便我们可以在运行时搜索它们。最常见的方法是嵌入每个文档分割的内容并将这些嵌入插入向量数据库(或向量存储)中。
当我们想要搜索分割时,采用文本搜索查询,将其嵌入,并执行某种“相似性”搜索,以识别与查询嵌入最相似的嵌入的存储分割。
最简单的相似性度量是余弦相似性——我们测量每对嵌入(高维向量)之间角度的余弦。
在单个命令中使用Chroma矢量存储和 OpenAIEmbeddings 模型将所有文档分割嵌入并存储。
from langchain_community.vectorstores import Chroma
from langchain_openai import OpenAIEmbeddings
vectorstore = Chroma.from_documents(documents=all_splits, embedding=OpenAIEmbeddings())
这样就完成了管道的索引部分。此时,我们有一个可查询的向量存储,其中包含我们博客文章的分块内容。给定用户问题,理想情况下我们应该能够返回回答该问题的博客文章的片段。
4. Retrieval and Generation : Retrieve
我们要创建的应用程序,它接受用户问题,搜索与问题相关的文档,将检索到的文档和初始问题传递给模型,然后返回答案。
首先,我们需要定义搜索文档的逻辑。 LangChain 定义了一个 Retriever 接口,它包装了一个索引,可以在给定字符串查询的情况下返回相关Documents。最常见的 Retriever 类型是 VectorStoreRetriever,它使用向量存储的相似性搜索功能来促进检索。
任何 VectorStore 都可以使用 VectorStore.as_retriever() 轻松转换为 Retriever:
retriever = vectorstore.as_retriever(search_type="similarity", search_kwargs={"k": 6})
retrieved_docs = retriever.invoke("What are the approaches to Task Decomposition?")
len(retrieved_docs)
print(retrieved_docs[0].page_content)
5. Retrieval and Generation : Generate
将所有内容放在一个链中,该链接受问题、检索相关文档、构造提示、将其传递给模型并解析输出。
from langchain_openai import ChatOpenAI
llm = ChatOpenAI(model_name="gpt-3.5-turbo-0125", temperature=0)
我们将使用已签入 LangChain 提示中心(此处)的 RAG 提示。
from langchain import hub
prompt = hub.pull("rlm/rag-prompt")
example_messages = prompt.invoke(
{"context": "filler context", "question": "filler question"}
).to_messages()
example_messages
使用 LCEL Runnable 协议来定义链,使我们能够 - 以透明的方式将组件和函数连接在一起 - 在 LangSmith 中自动跟踪我们的链 - 开箱即用地进行流式传输、异步和批量调用
from langchain_core.output_parsers import StrOutputParser
from langchain_core.runnables import RunnablePassthrough
def format_docs(docs):
return "\n\n".join(doc.page_content for doc in docs)
rag_chain = (
{"context": retriever | format_docs, "question": RunnablePassthrough()}
| prompt
| llm
| StrOutputParser()
)
for chunk in rag_chain.stream("What is Task Decomposition?"):
print(chunk, end="", flush=True)
Returning sources
- 如何返回特定生成中使用的源文档。
通常,在Q&A应用程序中,向用户展示用于生成答案的来源非常重要。最简单的方法是让链返回每一次检索到的文档。
Chain without sources
import bs4
from langchain import hub
from langchain_community.document_loaders import WebBaseLoader
from langchain_community.vectorstores import Chroma
from langchain_core.output_parsers import StrOutputParser
from langchain_core.runnables import RunnablePassthrough
from langchain_openai import ChatOpenAI, OpenAIEmbeddings
from langchain_text_splitters import RecursiveCharacterTextSplitter
# Load, chunk and index the contents of the blog.
bs_strainer = bs4.SoupStrainer(class_=("post-content", "post-title", "post-header"))
loader = WebBaseLoader(
web_paths=("https://lilianweng.github.io/posts/2023-06-23-agent/",),
bs_kwargs={"parse_only": bs_strainer},
)
docs = loader.load()
text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=200)
splits = text_splitter.split_documents(docs)
vectorstore = Chroma.from_documents(documents=splits, embedding=OpenAIEmbeddings())
# Retrieve and generate using the relevant snippets of the blog.
retriever = vectorstore.as_retriever()
prompt = hub.pull("rlm/rag-prompt")
llm = ChatOpenAI(model_name="gpt-3.5-turbo", temperature=0)
def format_docs(docs):
return "\n\n".join(doc.page_content for doc in docs)
rag_chain = (
{"context": retriever | format_docs, "question": RunnablePassthrough()}
| prompt
| llm
| StrOutputParser()
)
rag_chain.invoke("What is Task Decomposition?")
'Task decomposition is a technique used to break down complex tasks into smaller and simpler steps. It involves transforming big tasks into multiple manageable tasks to enhance model performance. This process can be done using prompting techniques, task-specific instructions, or human inputs.'
Adding sources
使用 LCEL,可以轻松返回检索到的文档:
from langchain_core.runnables import RunnableParallel
rag_chain_from_docs = (
RunnablePassthrough.assign(context=(lambda x: format_docs(x["context"])))
| prompt
| llm
| StrOutputParser()
)
rag_chain_with_source = RunnableParallel(
{"context": retriever, "question": RunnablePassthrough()}
).assign(answer=rag_chain_from_docs)
rag_chain_with_source.invoke("What is Task Decomposition")
{'context': [Document(page_content='Fig. 1. Overview of a LLM-powered autonomous agent system.\nComponent One: Planning#\nA complicated task usually involves many steps. An agent needs to know what they are and plan ahead.\nTask Decomposition#\nChain of thought (CoT; Wei et al. 2022) has become a standard prompting technique for enhancing model performance on complex tasks. The model is instructed to “think step by step” to utilize more test-time computation to decompose hard tasks into smaller and simpler steps. CoT transforms big tasks into multiple manageable tasks and shed lights into an interpretation of the model’s thinking process.', metadata={'source': 'https://lilianweng.github.io/posts/2023-06-23-agent/'}),
Document(page_content='Tree of Thoughts (Yao et al. 2023) extends CoT by exploring multiple reasoning possibilities at each step. It first decomposes the problem into multiple thought steps and generates multiple thoughts per step, creating a tree structure. The search process can be BFS (breadth-first search) or DFS (depth-first search) with each state evaluated by a classifier (via a prompt) or majority vote.\nTask decomposition can be done (1) by LLM with simple prompting like "Steps for XYZ.\\n1.", "What are the subgoals for achieving XYZ?", (2) by using task-specific instructions; e.g. "Write a story outline." for writing a novel, or (3) with human inputs.', metadata={'source': 'https://lilianweng.github.io/posts/2023-06-23-agent/'}),
Document(page_content='The AI assistant can parse user input to several tasks: [{"task": task, "id", task_id, "dep": dependency_task_ids, "args": {"text": text, "image": URL, "audio": URL, "video": URL}}]. The "dep" field denotes the id of the previous task which generates a new resource that the current task relies on. A special tag "-task_id" refers to the generated text image, audio and video in the dependency task with id as task_id. The task MUST be selected from the following options: {{ Available Task List }}. There is a logical relationship between tasks, please note their order. If the user input can\'t be parsed, you need to reply empty JSON. Here are several cases for your reference: {{ Demonstrations }}. The chat history is recorded as {{ Chat History }}. From this chat history, you can find the path of the user-mentioned resources for your task planning.', metadata={'source': 'https://lilianweng.github.io/posts/2023-06-23-agent/'}),
Document(page_content='Fig. 11. Illustration of how HuggingGPT works. (Image source: Shen et al. 2023)\nThe system comprises of 4 stages:\n(1) Task planning: LLM works as the brain and parses the user requests into multiple tasks. There are four attributes associated with each task: task type, ID, dependencies, and arguments. They use few-shot examples to guide LLM to do task parsing and planning.\nInstruction:', metadata={'source': 'https://lilianweng.github.io/posts/2023-06-23-agent/'})],
'question': 'What is Task Decomposition',
'answer': 'Task decomposition is a technique used to break down complex tasks into smaller and simpler steps. This approach allows agents or models to handle difficult tasks more effectively by dividing them into manageable components. It can be implemented through various methods such as prompting, task-specific instructions, or human inputs.'}
Adding chat history
- 如何将聊天记录添加到
Q&A app
在许多Q&A应用程序中,我们希望允许用户进行来回对话,这意味着应用程序需要对过去的问题和答案进行某种“记忆”,以及将这些内容合并到当前思维中的一些逻辑。
首先,更新现有程序:
- Prompt:更新我们的提示以支持历史消息作为输入。
- Contextualizing questions:添加一个子链(sub-chain),该子链接受最新的用户问题并在聊天历史记录的上下文中重新表述它。例如,如果用户问“Can you elaborate on the second point?”之类的后续问题,如果没有前一条消息的上下文,就无法理解这一点。因此我们无法对这样的问题进行有效的检索。
Contextualizing the question
首先,我们需要定义一个子链,该子链接受历史消息和最新的用户问题,并在引用历史信息中的任何信息时重新表述问题。
需要使用一个提示,其中包含名为“chat_history”的 MessagesPlaceholder 变量,这使得我们可以使用”chat_history”输入键将消息列表传递到提示,这些消息将被插入到系统消息之后和包含最新问题的人工消息之前。
from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder
contextualize_q_system_prompt = """Given a chat history and the latest user question \
which might reference context in the chat history, formulate a standalone question \
which can be understood without the chat history. Do NOT answer the question, \
just reformulate it if needed and otherwise return it as is."""
contextualize_q_prompt = ChatPromptTemplate.from_messages(
[
("system", contextualize_q_system_prompt),
MessagesPlaceholder(variable_name="chat_history"),
("human", "{question}"),
]
)
contextualize_q_chain = contextualize_q_prompt | llm | StrOutputParser()
使用这条链,可以提出引用过去消息的后续问题,并将它们重新表述为独立的问题:
from langchain_core.messages import AIMessage, HumanMessage
contextualize_q_chain.invoke(
{
"chat_history": [
HumanMessage(content="What does LLM stand for?"),
AIMessage(content="Large language model"),
],
"question": "What is meant by large",
}
)
Chain with chat history
现在就可以构建完整的链了
注意,这里添加了一些路由功能,以便仅在聊天历史记录不为空时运行“压缩问题链”。
在这里,我们利用了这样一个事实:如果 LCEL 链中的函数返回另一个链,则该链本身将被调用。
qa_system_prompt = """You are an assistant for question-answering tasks. \
Use the following pieces of retrieved context to answer the question. \
If you don't know the answer, just say that you don't know. \
Use three sentences maximum and keep the answer concise.\
{context}"""
qa_prompt = ChatPromptTemplate.from_messages(
[
("system", qa_system_prompt),
MessagesPlaceholder(variable_name="chat_history"),
("human", "{question}"),
]
)
def contextualized_question(input: dict):
if input.get("chat_history"):
return contextualize_q_chain
else:
return input["question"]
rag_chain = (
RunnablePassthrough.assign(
context=contextualized_question | retriever | format_docs
)
| qa_prompt
| llm
)
chat_history = []
question = "What is Task Decomposition?"
ai_msg = rag_chain.invoke({"question": question, "chat_history": chat_history})
chat_history.extend([HumanMessage(content=question), ai_msg])
second_question = "What are common ways of doing it?"
rag_chain.invoke({"question": second_question, "chat_history": chat_history})
Streaming
- 如何流式传输最终答案以及中间步骤。
通常,在Q&A应用程序中,向用户展示用于生成答案的来源非常重要。最简单的方法是让链返回每一代中检索到的文档。
Chain with sources
import bs4
from langchain import hub
from langchain_community.document_loaders import WebBaseLoader
from langchain_community.vectorstores import Chroma
from langchain_core.output_parsers import StrOutputParser
from langchain_core.runnables import RunnableParallel, RunnablePassthrough
from langchain_openai import ChatOpenAI, OpenAIEmbeddings
from langchain_text_splitters import RecursiveCharacterTextSplitter
# Load, chunk and index the contents of the blog.
bs_strainer = bs4.SoupStrainer(class_=("post-content", "post-title", "post-header"))
loader = WebBaseLoader(
web_paths=("https://lilianweng.github.io/posts/2023-06-23-agent/",),
bs_kwargs={"parse_only": bs_strainer},
)
docs = loader.load()
text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=200)
splits = text_splitter.split_documents(docs)
vectorstore = Chroma.from_documents(documents=splits, embedding=OpenAIEmbeddings())
# Retrieve and generate using the relevant snippets of the blog.
retriever = vectorstore.as_retriever()
prompt = hub.pull("rlm/rag-prompt")
llm = ChatOpenAI(model_name="gpt-3.5-turbo", temperature=0)
def format_docs(docs):
return "\n\n".join(doc.page_content for doc in docs)
rag_chain_from_docs = (
RunnablePassthrough.assign(context=(lambda x: format_docs(x["context"])))
| prompt
| llm
| StrOutputParser()
)
rag_chain_with_source = RunnableParallel(
{"context": retriever, "question": RunnablePassthrough()}
).assign(answer=rag_chain_from_docs)
Streaming final outputs
for chunk in rag_chain_with_source.stream("What is Task Decomposition"):
print(chunk)
添加一些逻辑来编译返回的流:
output = {}
curr_key = None
for chunk in rag_chain_with_source.stream("What is Task Decomposition"):
for key in chunk:
if key not in output:
output[key] = chunk[key]
else:
output[key] += chunk[key]
if key != curr_key:
print(f"\n\n{key}: {chunk[key]}", end="", flush=True)
else:
print(chunk[key], end="", flush=True)
curr_key = key
output

Streaming intermediate steps
- 流式传输中间步骤
假设我们不仅要传输链的最终输出,还要传输一些中间步骤。以聊天历史链为例,在这里,我们在将用户问题传递给检索器之前重新表述它,这个重新表述的问题不会作为最终输出的一部分返回。我们可以修改我们的链以返回新问题,但出于演示目的,我们将保持原样。
from operator import itemgetter
from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder
from langchain_core.tracers.log_stream import LogStreamCallbackHandler
contextualize_q_system_prompt = """Given a chat history and the latest user question \
which might reference context in the chat history, formulate a standalone question \
which can be understood without the chat history. Do NOT answer the question, \
just reformulate it if needed and otherwise return it as is."""
contextualize_q_prompt = ChatPromptTemplate.from_messages(
[
("system", contextualize_q_system_prompt),
MessagesPlaceholder(variable_name="chat_history"),
("human", "{question}"),
]
)
contextualize_q_chain = (contextualize_q_prompt | llm | StrOutputParser()).with_config(
tags=["contextualize_q_chain"]
)
qa_system_prompt = """You are an assistant for question-answering tasks. \
Use the following pieces of retrieved context to answer the question. \
If you don't know the answer, just say that you don't know. \
Use three sentences maximum and keep the answer concise.\
{context}"""
qa_prompt = ChatPromptTemplate.from_messages(
[
("system", qa_system_prompt),
MessagesPlaceholder(variable_name="chat_history"),
("human", "{question}"),
]
)
def contextualized_question(input: dict):
if input.get("chat_history"):
return contextualize_q_chain
else:
return input["question"]
rag_chain = (
RunnablePassthrough.assign(context=contextualize_q_chain | retriever | format_docs)
| qa_prompt
| llm
)
为了流式传输中间步骤,我们将使用 astream_log 方法。这是一个异步方法,它会生成 JSONPatch 操作,当按照与接收到的相同顺序应用该操作时,会构建 RunState:
class RunState(TypedDict):
id: str
"""ID of the run."""
streamed_output: List[Any]
"""List of output chunks streamed by Runnable.stream()"""
final_output: Optional[Any]
"""Final output of the run, usually the result of aggregating (`+`) streamed_output.
Only available after the run has finished successfully."""
logs: Dict[str, LogEntry]
"""Map of run names to sub-runs. If filters were supplied, this list will
contain only the runs that matched the filters."""
可以流式传输所有步骤(默认)或按名称、标签或元数据包含/排除步骤。在本例中,我们将仅传输属于contextualize_q_chain的中间步骤和最终输出。
注意,在定义 contextualize_q_chain 时,给了它一个相应的标签,现在我们可以对其进行过滤。
为了便于阅读,我们仅显示流的前 20 个块:
# Needed for running async functions in Jupyter notebook:
import nest_asyncio
nest_asyncio.apply()
from langchain_core.messages import HumanMessage
chat_history = []
question = "What is Task Decomposition?"
ai_msg = rag_chain.invoke({"question": question, "chat_history": chat_history})
chat_history.extend([HumanMessage(content=question), ai_msg])
second_question = "What are common ways of doing it?"
ct = 0
async for jsonpatch_op in rag_chain.astream_log(
{"question": second_question, "chat_history": chat_history},
include_tags=["contextualize_q_chain"],
):
print(jsonpatch_op)
print("\n" + "-" * 30 + "\n")
ct += 1
if ct > 20:
break
如果想获取检索到的文档,可以根据名称“Retriever”进行过滤:
ct = 0
async for jsonpatch_op in rag_chain.astream_log(
{"question": second_question, "chat_history": chat_history},
include_names=["Retriever"],
with_streamed_output_list=False,
):
print(jsonpatch_op)
print("\n" + "-" * 30 + "\n")
ct += 1
if ct > 20:
break
Per-user retrieval
- 每个用户都有自己的隐私数据时如何进行检索
在构建检索应用程序时,通常必须考虑到多个用户。这意味着可能不仅为一个用户存储数据,而且为许多不同的用户存储数据,并且他们不应该能够看到彼此的数据。这意味着需要能够将检索链配置为仅检索某些信息。这通常涉及两个步骤:
-
Step 1:Make sure the retriever you are using supports multiple users——确保您使用的检索器支持多个用户
目前,LangChain 中还没有对此进行统一的标记或过滤器。相反,每个向量存储和检索器可能有自己的,并且可能被称为不同的东西(命名空间、多租户等)。对于向量存储,这通常作为在相似度搜索期间传入的关键字参数公开。
-
Step 2:Add that parameter as a configurable field for the chain——将该参数添加为链的可配置字段
-
Step 3:Call the chain with that configurable field——使用该可配置字段调用链
Example
在示例中,我们将使用Pinecone。
要配置 Pinecone,请设置以下环境变量:
PINECONE_API_KEY: Your Pinecone API key
from langchain_openai import OpenAIEmbeddings
from langchain_pinecone import PineconeVectorStore
embeddings = OpenAIEmbeddings()
vectorstore = PineconeVectorStore(index_name="test-example", embedding=embeddings)
vectorstore.add_texts(["i worked at kensho"], namespace="harrison")
vectorstore.add_texts(["i worked at facebook"], namespace="ankush")
pinecone kwarg的namespace 可用于分隔文档
# This will only get documents for Ankush
vectorstore.as_retriever(search_kwargs={"namespace": "ankush"}).get_relevant_documents(
"where did i work?"
)
[Document(page_content='i worked at facebook')]
# This will only get documents for Harrison
vectorstore.as_retriever(search_kwargs={"namespace": "harrison"}).get_relevant_documents(
"where did i work?"
)
[Document(page_content='i worked at kensho')]
现在可以创建用于回答问题的链
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.runnables import (
ConfigurableField,
RunnableBinding,
RunnableLambda,
RunnablePassthrough,
)
from langchain_openai import ChatOpenAI, OpenAIEmbeddings
template = """Answer the question based only on the following context:
{context}
Question: {question}
"""
prompt = ChatPromptTemplate.from_template(template)
model = ChatOpenAI()
retriever = vectorstore.as_retriever()
在这里,我们将检索器标记为具有可配置字段。所有向量存储检索器都有 search_kwargs 作为字段。这只是一个字典,具有向量存储特定字段
configurable_retriever = retriever.configurable_fields(
search_kwargs=ConfigurableField(
id="search_kwargs",
name="Search Kwargs",
description="The search kwargs to use",
)
)
现在使用可配置的检索器创建链
chain = (
{"context": configurable_retriever, "question": RunnablePassthrough()}
| prompt
| model
| StrOutputParser()
)
现在使用可配置选项调用该链,search_kwargs 是可配置字段的 id,该值是用于 Pinecone 的搜索 kwargs
chain.invoke(
"where did the user work?",
config={"configurable": {"search_kwargs": {"namespace": "harrison"}}},
)
'The user worked at Kensho.'
Using agents
- 如何使用代理进行
Q&A
这是一个专门优化的代理,用于在必要时进行检索并进行对话。
首先,设置想要使用的检索器,然后将其变成检索器工具
然后,使用此类代理的高级构造函数
最后,逐步介绍如何从组件构建会话检索代理
The Retriever
from langchain_community.document_loaders import TextLoader
loader = TextLoader("../../modules/state_of_the_union.txt")
documents = loader.load()
from langchain_community.vectorstores import FAISS
from langchain_openai import OpenAIEmbeddings
from langchain_text_splitters import CharacterTextSplitter
text_splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=0)
texts = text_splitter.split_documents(documents)
embeddings = OpenAIEmbeddings()
db = FAISS.from_documents(texts, embeddings)
retriever = db.as_retriever()
Retriever Tool
现在为我们的检索器创建一个工具,需要传入的主要内容是检索器的名称以及描述。这些都将被语言模型使用,因此它们应该提供丰富的信息。
from langchain.tools.retriever import create_retriever_tool
tool = create_retriever_tool(
retriever,
"search_state_of_union",
"Searches and returns excerpts from the 2022 State of the Union.",
)
tools = [tool]
Agent Constructor
这里使用高级create_openai_tools_agent API 来构建代理。
请注意,除了工具列表之外,唯一需要传入的是要使用的语言模型。
在底层,该代理正在使用 OpenAI 工具调用功能,因此我们需要使用 ChatOpenAI 模型。
from langchain import hub
prompt = hub.pull("hwchase17/openai-tools-agent")
prompt.messages
from langchain_openai import ChatOpenAI
llm = ChatOpenAI(temperature=0)
from langchain.agents import AgentExecutor, create_openai_tools_agent
agent = create_openai_tools_agent(llm, tools, prompt)
agent_executor = AgentExecutor(agent=agent, tools=tools)
result = agent_executor.invoke(
{
"input": "what did the president say about ketanji brown jackson in the most recent state of the union?"
}
)
注意,后续问题询问之前检索到的信息,无需再次检索
Citations
如何才能获得一个模型来引用它在响应中引用的源文档的哪些部分?
from langchain_community.retrievers import WikipediaRetriever
from langchain_core.prompts import ChatPromptTemplate
from langchain_openai import ChatOpenAI
llm = ChatOpenAI(model="gpt-3.5-turbo", temperature=0)
wiki = WikipediaRetriever(top_k_results=6, doc_content_chars_max=2000)
prompt = ChatPromptTemplate.from_messages(
[
(
"system",
"You're a helpful AI assistant. Given a user question and some Wikipedia article snippets, answer the user question. If none of the articles answer the question, just say you don't know.\n\nHere are the Wikipedia articles:{context}",
),
("human", "{question}"),
]
)
prompt.pretty_print()
现在已经有了模型、检索器和提示,将它们链接在一起。需要添加一些逻辑,将检索到的文档格式化为可以传递到提示符的字符串。我们会让我们的链返回答案和检索到的文档。
from operator import itemgetter
from typing import List
from langchain_core.documents import Document
from langchain_core.output_parsers import StrOutputParser
from langchain_core.runnables import (
RunnableLambda,
RunnableParallel,
RunnablePassthrough,
)
def format_docs(docs: List[Document]) -> str:
"""Convert Documents to a single string.:"""
formatted = [
f"Article Title: {doc.metadata['title']}\nArticle Snippet: {doc.page_content}"
for doc in docs
]
return "\n\n" + "\n\n".join(formatted)
format = itemgetter("docs") | RunnableLambda(format_docs)
# subchain for generating an answer once we've done retrieval
answer = prompt | llm | StrOutputParser()
# complete chain that calls wiki -> formats docs to string -> runs answer subchain -> returns just the answer and retrieved docs.
chain = (
RunnableParallel(question=RunnablePassthrough(), docs=wiki)
.assign(context=format)
.assign(answer=answer)
.pick(["answer", "docs"])
)
chain.invoke("How fast are cheetahs?")
Function-calling
Cite documents
from langchain_core.pydantic_v1 import BaseModel, Field
class cited_answer(BaseModel):
"""Answer the user question based only on the given sources, and cite the sources used."""
answer: str = Field(
...,
description="The answer to the user question, which is based only on the given sources.",
)
citations: List[int] = Field(
...,
description="The integer IDs of the SPECIFIC sources which justify the answer.",
)
让我们看看当我们传入函数和用户输入时模型输出是什么样的:
llm_with_tool = llm.bind_tools(
[cited_answer],
tool_choice="cited_answer",
)
example_q = """What Brian's height?
Source: 1
Information: Suzy is 6'2"
Source: 2
Information: Jeremiah is blonde
Source: 3
Information: Brian is 3 inches shorted than Suzy"""
llm_with_tool.invoke(example_q)
添加一个输出解析器,将 OpenAI API 响应转换为一个字典。为此,我们使用 JsonOutputKeyToolsParser:
from langchain.output_parsers.openai_tools import JsonOutputKeyToolsParser
output_parser = JsonOutputKeyToolsParser(key_name="cited_answer", return_single=True)
(llm_with_tool | output_parser).invoke(example_q)
组装链条:
def format_docs_with_id(docs: List[Document]) -> str:
formatted = [
f"Source ID: {i}\nArticle Title: {doc.metadata['title']}\nArticle Snippet: {doc.page_content}"
for i, doc in enumerate(docs)
]
return "\n\n" + "\n\n".join(formatted)
format_1 = itemgetter("docs") | RunnableLambda(format_docs_with_id)
answer_1 = prompt | llm_with_tool | output_parser
chain_1 = (
RunnableParallel(question=RunnablePassthrough(), docs=wiki)
.assign(context=format_1)
.assign(cited_answer=answer_1)
.pick(["cited_answer", "docs"])
)
Cite snippets
注意,如果我们分解文档,使许多文档只有一两句话而不是几个长文档,那么引用文档就大致相当于引用片段,并且对于模型来说可能更容易,因为模型只需要返回每个片段的标识符而不是实际文本。 可能值得尝试这两种方法并进行评估。
class Citation(BaseModel):
source_id: int = Field(
...,
description="The integer ID of a SPECIFIC source which justifies the answer.",
)
quote: str = Field(
...,
description="The VERBATIM quote from the specified source that justifies the answer.",
)
class quoted_answer(BaseModel):
"""Answer the user question based only on the given sources, and cite the sources used."""
answer: str = Field(
...,
description="The answer to the user question, which is based only on the given sources.",
)
citations: List[Citation] = Field(
..., description="Citations from the given sources that justify the answer."
)
output_parser_2 = JsonOutputKeyToolsParser(key_name="quoted_answer", return_single=True)
llm_with_tool_2 = llm.bind_tools(
[quoted_answer],
tool_choice="quoted_answer",
)
format_2 = itemgetter("docs") | RunnableLambda(format_docs_with_id)
answer_2 = prompt | llm_with_tool_2 | output_parser_2
chain_2 = (
RunnableParallel(question=RunnablePassthrough(), docs=wiki)
.assign(context=format_2)
.assign(quoted_answer=answer_2)
.pick(["quoted_answer", "docs"])
)
Direct prompting
大多数模型尚不支持函数调用,可以通过直接提示获得类似的结果。
from langchain_anthropic import ChatAnthropicMessages
anthropic = ChatAnthropicMessages(model_name="claude-instant-1.2")
system = """You're a helpful AI assistant. Given a user question and some Wikipedia article snippets, \
answer the user question and provide citations. If none of the articles answer the question, just say you don't know.
Remember, you must return both an answer and citations. A citation consists of a VERBATIM quote that \
justifies the answer and the ID of the quote article. Return a citation for every quote across all articles \
that justify the answer. Use the following format for your final output:
<cited_answer>
<answer></answer>
<citations>
<citation><source_id></source_id><quote></quote></citation>
<citation><source_id></source_id><quote></quote></citation>
...
</citations>
</cited_answer>
Here are the Wikipedia articles:{context}"""
prompt_3 = ChatPromptTemplate.from_messages(
[("system", system), ("human", "{question}")]
)
from langchain_core.output_parsers import XMLOutputParser
def format_docs_xml(docs: List[Document]) -> str:
formatted = []
for i, doc in enumerate(docs):
doc_str = f"""\
<source id=\"{i}\">
<title>{doc.metadata['title']}</title>
<article_snippet>{doc.page_content}</article_snippet>
</source>"""
formatted.append(doc_str)
return "\n\n<sources>" + "\n".join(formatted) + "</sources>"
format_3 = itemgetter("docs") | RunnableLambda(format_docs_xml)
answer_3 = prompt_3 | anthropic | XMLOutputParser() | itemgetter("cited_answer")
chain_3 = (
RunnableParallel(question=RunnablePassthrough(), docs=wiki)
.assign(context=format_3)
.assign(cited_answer=answer_3)
.pick(["cited_answer", "docs"])
)
Retrieval post-processing
另一种方法是对检索到的文档进行后处理以压缩内容,以便源内容已经足够小,我们不需要模型来引用特定的源或跨度。例如,我们可以将每个文档分解为一两个句子,嵌入它们并仅保留最相关的句子。 LangChain 为此内置了一些组件。在这里,我们将使用 RecursiveCharacterTextSplitter,它通过分割分隔符子字符串来创建分隔大小的块,以及 EmbeddingsFilter,它只保留具有最相关嵌入的文本。
from langchain.retrievers.document_compressors import EmbeddingsFilter
from langchain_openai import OpenAIEmbeddings
from langchain_text_splitters import RecursiveCharacterTextSplitter
splitter = RecursiveCharacterTextSplitter(
chunk_size=400,
chunk_overlap=0,
separators=["\n\n", "\n", ".", " "],
keep_separator=False,
)
compressor = EmbeddingsFilter(embeddings=OpenAIEmbeddings(), k=10)
def split_and_filter(input) -> List[Document]:
docs = input["docs"]
question = input["question"]
split_docs = splitter.split_documents(docs)
stateful_docs = compressor.compress_documents(split_docs, question)
return [stateful_doc for stateful_doc in stateful_docs]
retrieve = (
RunnableParallel(question=RunnablePassthrough(), docs=wiki) | split_and_filter
)
docs = retrieve.invoke("How fast are cheetahs?")
for doc in docs:
print(doc.page_content)
print("\n\n")
chain_4 = (
RunnableParallel(question=RunnablePassthrough(), docs=retrieve)
.assign(context=format)
.assign(answer=answer)
.pick(["answer", "docs"])
)
Generation post-processing
另一种方法是对模型生成进行后处理。在这个例子中,我们将首先生成一个答案,然后我们将要求模型用引用来注释它自己的答案。这种方法的缺点当然是速度较慢且成本较高,因为需要进行两次模型调用。
class Citation(BaseModel):
source_id: int = Field(
...,
description="The integer ID of a SPECIFIC source which justifies the answer.",
)
quote: str = Field(
...,
description="The VERBATIM quote from the specified source that justifies the answer.",
)
class annotated_answer(BaseModel):
"""Annotate the answer to the user question with quote citations that justify the answer."""
citations: List[Citation] = Field(
..., description="Citations from the given sources that justify the answer."
)
llm_with_tools_5 = llm.bind_tools(
[annotated_answer],
tool_choice="annotated_answer",
)
from langchain_core.prompts import MessagesPlaceholder
prompt_5 = ChatPromptTemplate.from_messages(
[
(
"system",
"You're a helpful AI assistant. Given a user question and some Wikipedia article snippets, answer the user question. If none of the articles answer the question, just say you don't know.\n\nHere are the Wikipedia articles:{context}",
),
("human", "{question}"),
MessagesPlaceholder("chat_history", optional=True),
]
)
answer_5 = prompt_5 | llm
annotation_chain = (
prompt_5
| llm_with_tools_5
| JsonOutputKeyToolsParser(key_name="annotated_answer", return_single=True)
| itemgetter("citations")
)
chain_5 = (
RunnableParallel(question=RunnablePassthrough(), docs=wiki)
.assign(context=format)
.assign(ai_message=answer_5)
.assign(
chat_history=(lambda x: [x["ai_message"]]),
answer=(lambda x: x["ai_message"].content),
)
.assign(annotations=annotation_chain)
.pick(["answer", "docs", "annotations"])
)








![[实战]Springboot与GB28181摄像头对接。摄像头注册上线(一)](https://img-blog.csdnimg.cn/direct/6dde8fa833f645abaa44d5e9c81bb294.png)