环境准备
三台centos7虚拟机,设置固定ip(自己设置),设置ssh秘密登录(自己设置),安装jdk8(自己安装)


准备安装包hadoop-3.3.6.tar.gz
位置在/home/hadoop
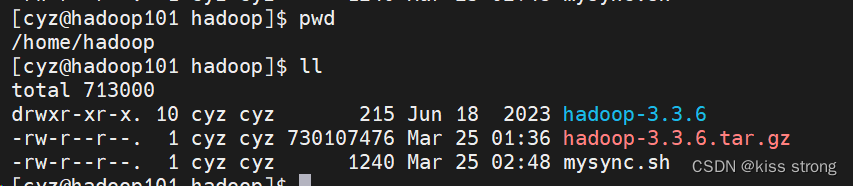
准备服务器之间同步脚本 mysync.sh,用于分发文件使用的
#!/bin/bash
# 分发文件使用的
# 判空
if [ $# -lt 1 ]
then
echo "输入参数为空!!!"
exit
fi
# 如果非空 遍历主机
for host in hadoop102 hadoop103
do
# 参数可能多个 再嵌套一层循环
for file in $@
do
# 判断file是否为存在
if [ -e $file ]
# 如果文件存在 执行then
then
# 1. 获取文件的目录
# 但是传递的参数可能为软链接 所以先进入
pdir=$(cd -P $(dirname $file);pwd)
# 2. 获取文件名
fname=$(basename $file)
# 3. 使用ssh命令登录到对应主机上创建相同目录结构
# 但是传递的参数可能为软链接 所以先进入
ssh $host "mkdir -p $pdir"
# 4. 使用rsync命令分发
rsync -av $pdir/$fname $host:$pdir
# 如果不存在 则给出提示之后继续执行下一轮
else
echo "输入的 $file 文件不存在"
fi
done
done
解压安装包设置环境变量
在hadoop101、hadoop102、hadoop103三台机器上都执行如下命令
解压安装包 tar -zxvf hadoop-3.3.6.tar.gz

配置HADOOP_HOME环境变量
vim /etc/profile 添加如下内容
export HADOOP_HOME=/home/hadoop/hadoop-3.3.6
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin
校验是否安装好,执行hadoop version

不是所有人都会出现这个问题,只是我出现了 ,因为系统缺少所需的 32 位兼容库。
安装glibc.i686 在root用户下面安装
yum install glibc.i686安装好了再次执行hadoop version

到此基本配置没有问题
单点安装
默认情况下,Hadoop被配置为在非分布式模式下作为单个Java进程运行。这对调试很有用。
以下示例复制解压缩的conf目录以用作输入,然后查找并显示给定正则表达式的每个匹配项。输出被写入给定的输出目录。
创建input文件夹
[cyz@hadoop101 hadoop]$ mkdir input
[cyz@hadoop101 hadoop]$ ll
total 713000
drwxr-xr-x. 10 cyz cyz 215 Jun 18 2023 hadoop-3.3.6
-rw-r--r--. 1 cyz cyz 730107476 Mar 25 01:36 hadoop-3.3.6.tar.gz
drwxrwxr-x. 2 cyz cyz 6 Mar 25 18:22 input
-rw-r--r--. 1 cyz cyz 1240 Mar 25 02:48 mysync.sh
在input下面创建文件a.txt,内容如下
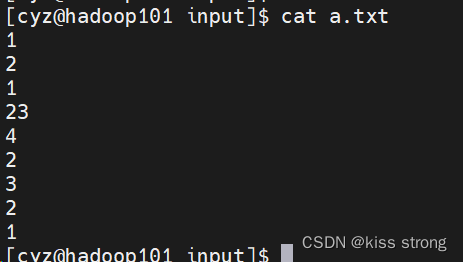
统计a.txt中的单词数量
[cyz@hadoop101 hadoop]$ pwd
/home/hadoop
[cyz@hadoop101 hadoop]$ hadoop jar hadoop-3.3.6/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.6.jar wordcount input/ output 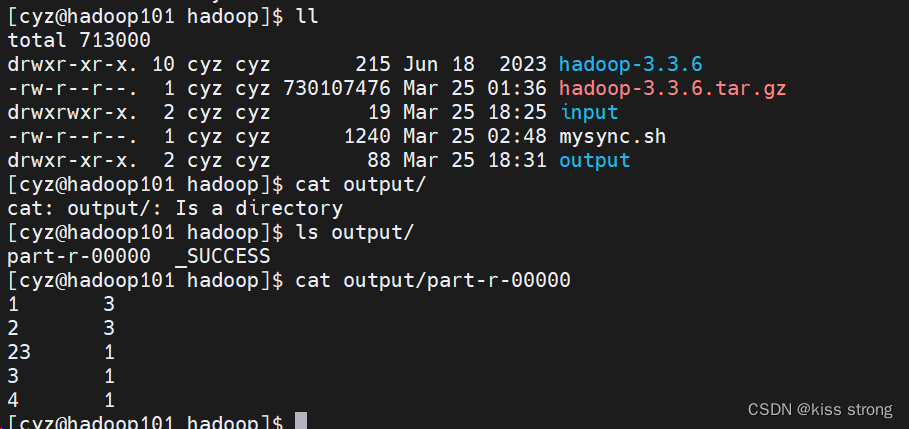 如果output文件夹已经存在就会报错
如果output文件夹已经存在就会报错

如果input文件夹中有多个文件就会一起统计,复制一份a.txt 伪b.txt

再次执行 (先删除output文件夹或者另选文件夹名称)
hadoop jar hadoop-3.3.6/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.6.jar wordcount input/ output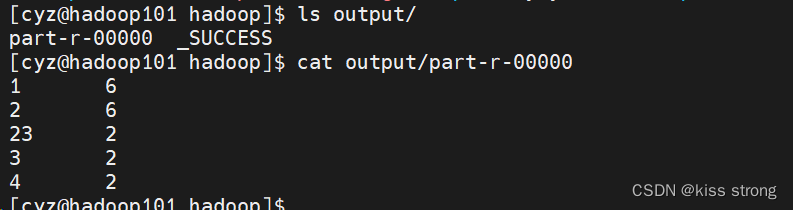
伪分布式安装
Hadoop也可以在伪分布式模式下在单个节点上运行,其中每个Hadoop守护进程在单独的Java进程中运行。
修改配置:配置都在/home/hadoop/hadoop-3.3.6/etc/hadoop/下面
core-site.xml:
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>hdfs-site.xml:
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>测试是否能够ssh本机不需要输入密码(如果不行需要设置ssh免密登录)

以下说明用于在本地运行MapReduce作业
格式化文件系统:
hdfs namenode -format启动NameNode守护程序和DataNode守护程序:
start-dfs.sh
报错,没有设置JAVA_HOME,需要在配置文件etc/hadoop/hadoop-env.sh加上环境变量
export JAVA_HOME=/home/jdk8/jdk1.8.0_401再次执行start-dfs.sh

发现警告,需要停止进程,如下操作

一般出现这个错误都是出现在64位机器上,只需要在hadoop-env.sh、yarn-env.sh两个文件下面加上如下配置即可
export HADOOP_COMMON_LIB_NATIVE_DIR=${HADOOP_HOME}/lib/native
export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib"
再起启动

浏览NameNode的web界面;默认情况下,它位于 http://localhost:9870/
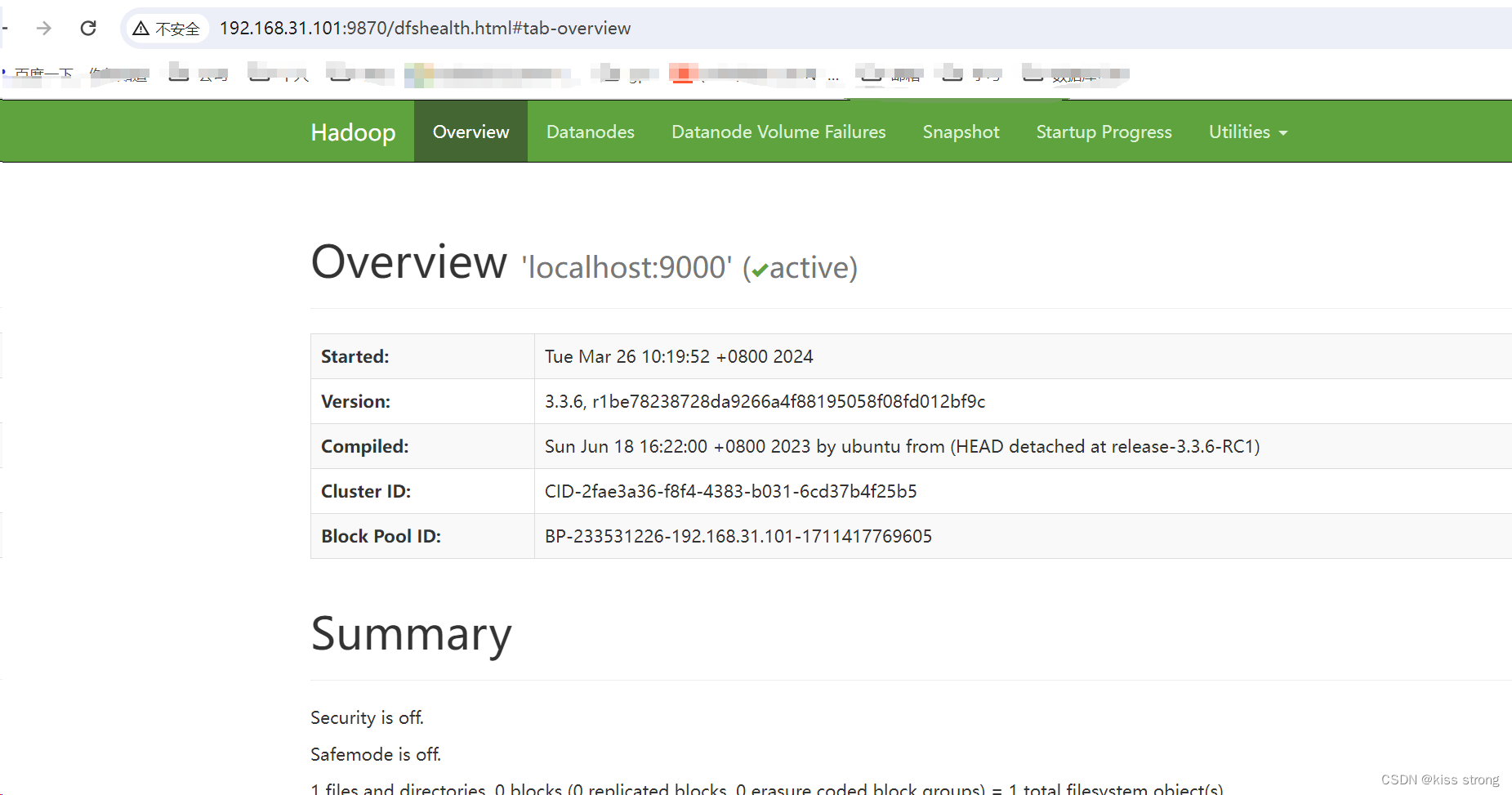
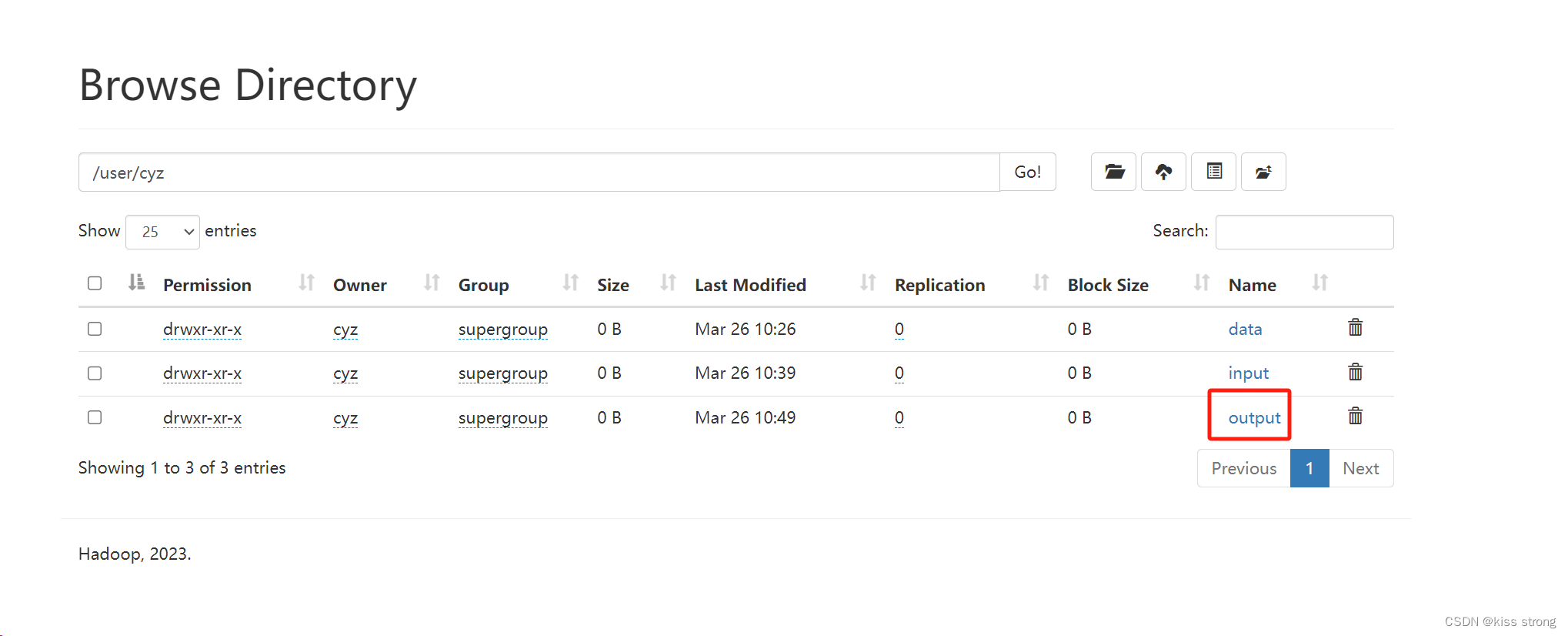
创建执行MapReduce作业所需的HDFS目录
如果写的是相对路径则会文件系统的/user/<username>/下面创建文件夹,如果是绝对路径如/hhh就会在根目录下创建
hdfs dfs -mkdir -p data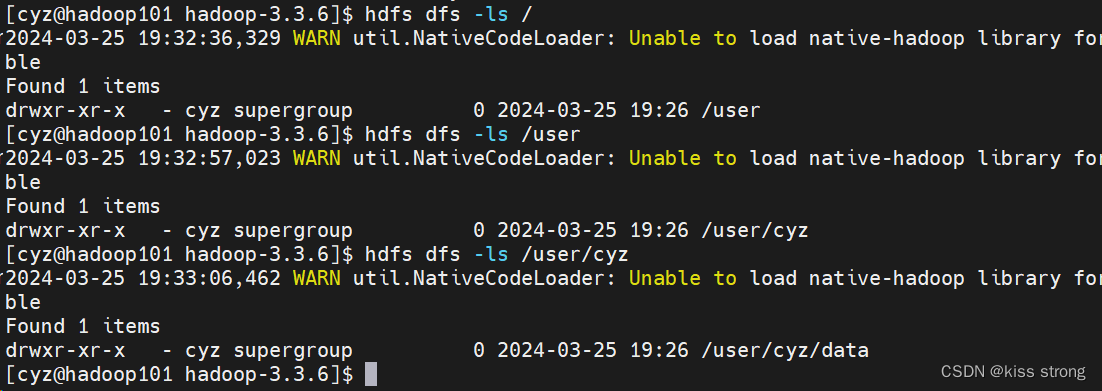
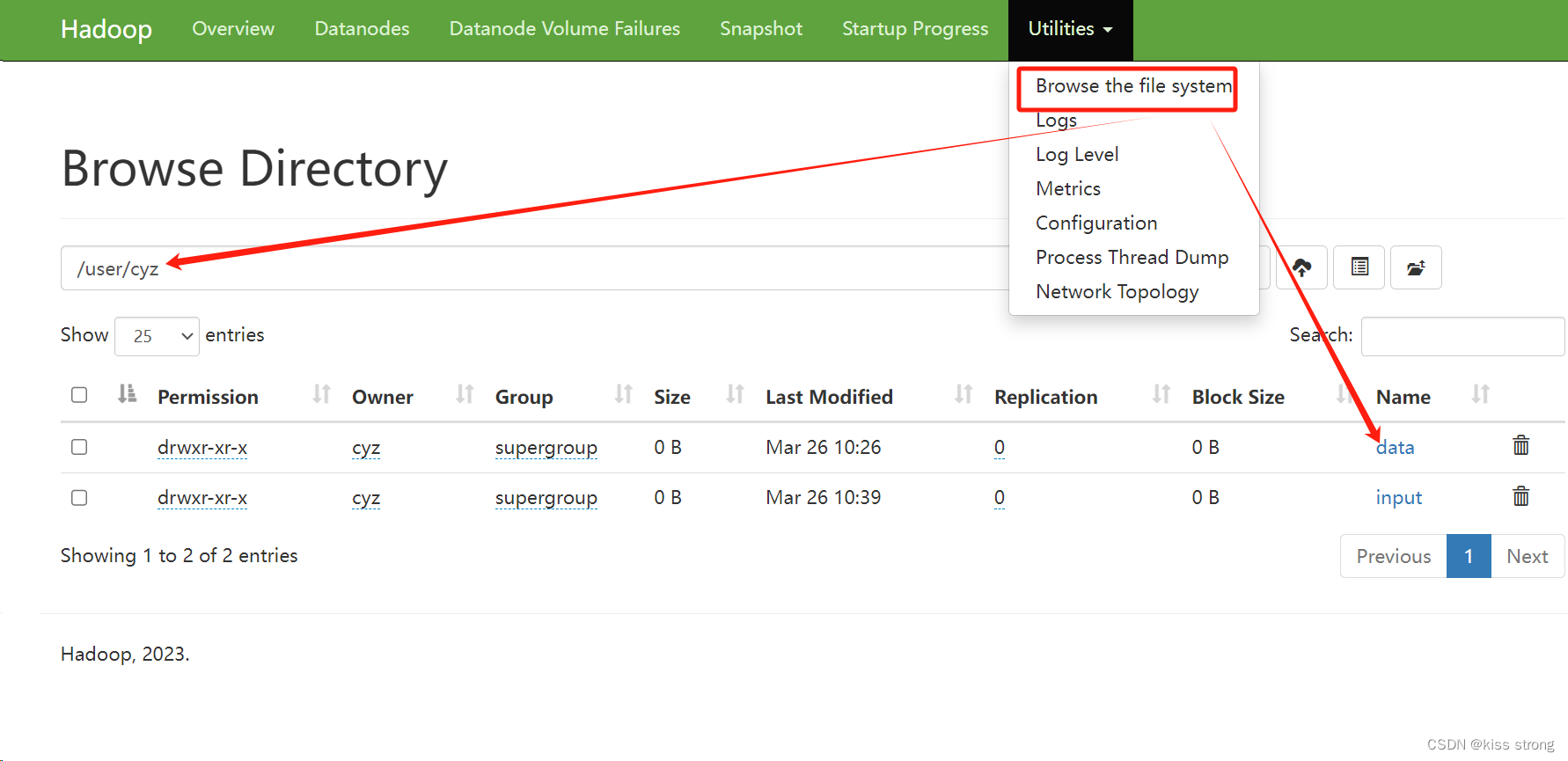
hdfs dfs -mkdir /hhh
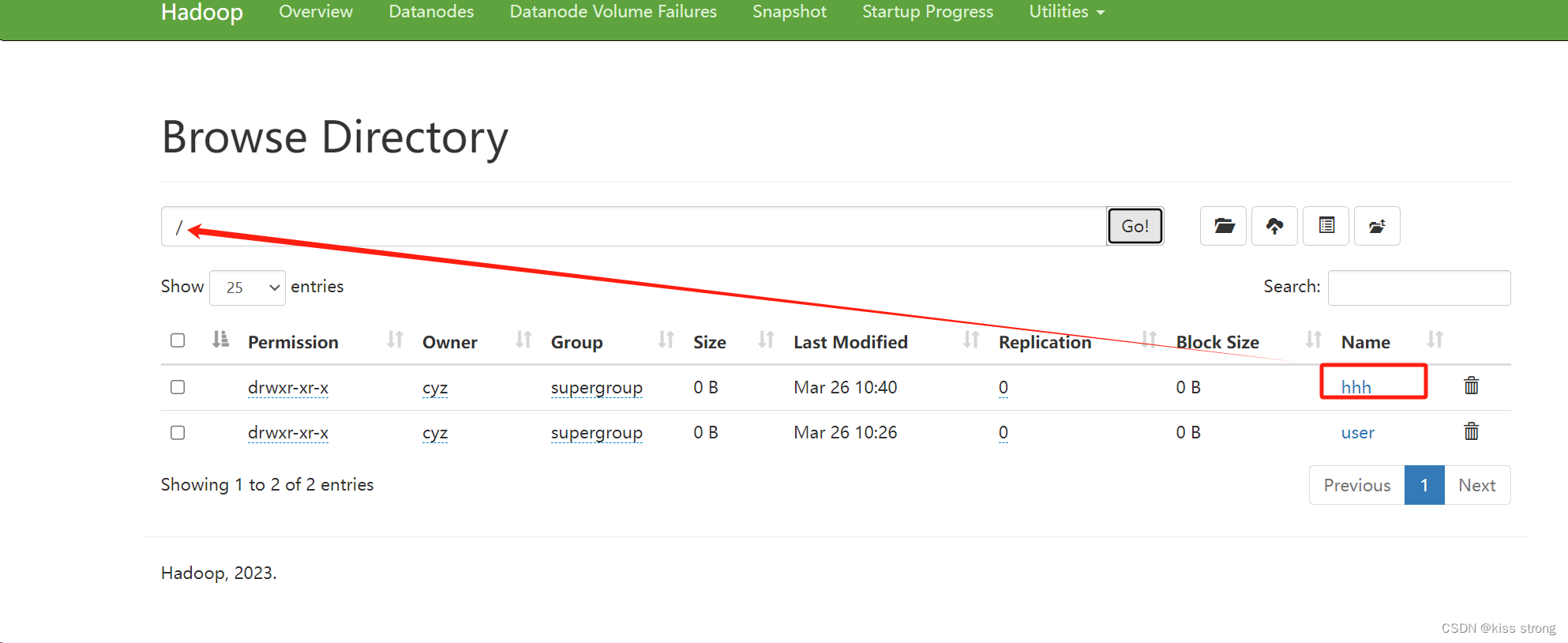
测试文件上传
创建input文件夹
hdfs dfs -mkdir input把之前创建的input下面的a.txt,b.txt上传到文件系统中

hdfs dfs -put input/*.txt input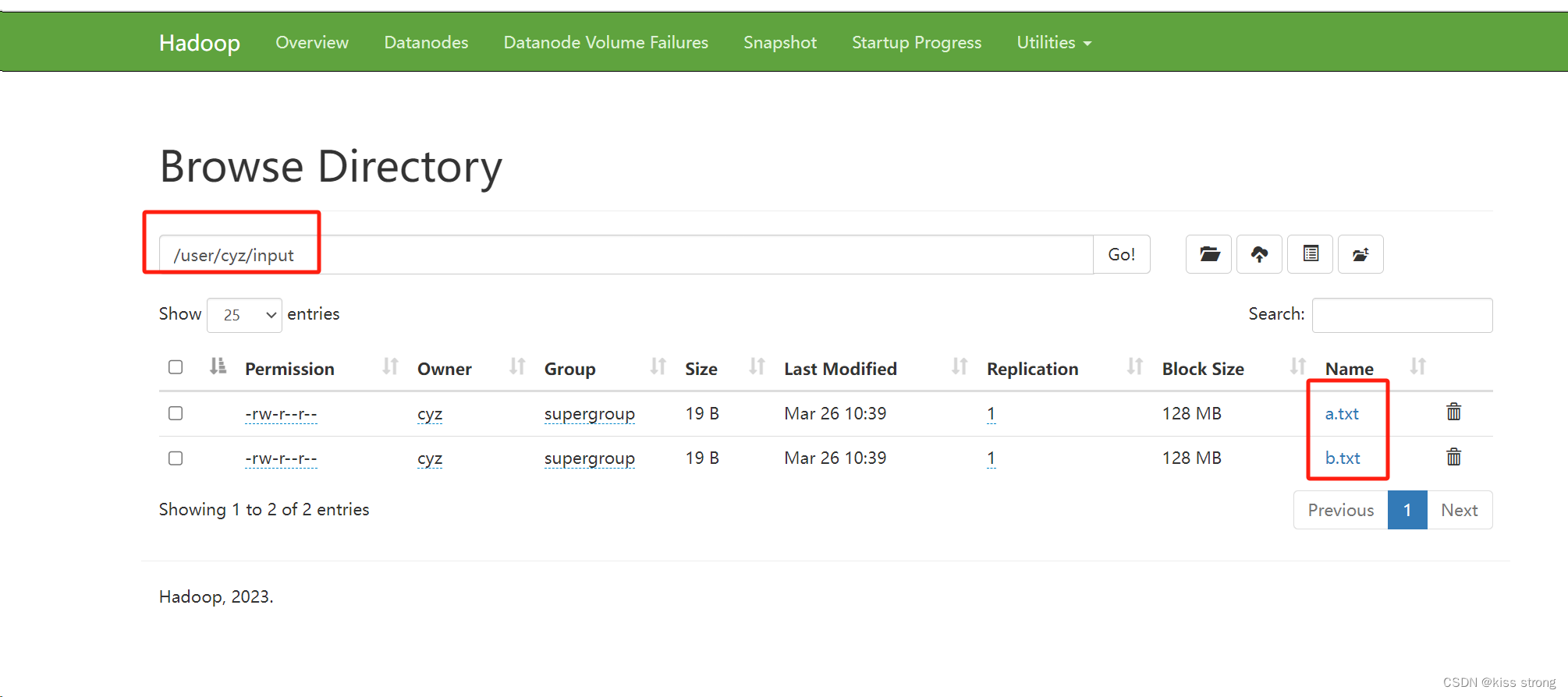
使用工具计算单词数
hadoop jar hadoop-3.3.6/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.6.jar wordcount input output
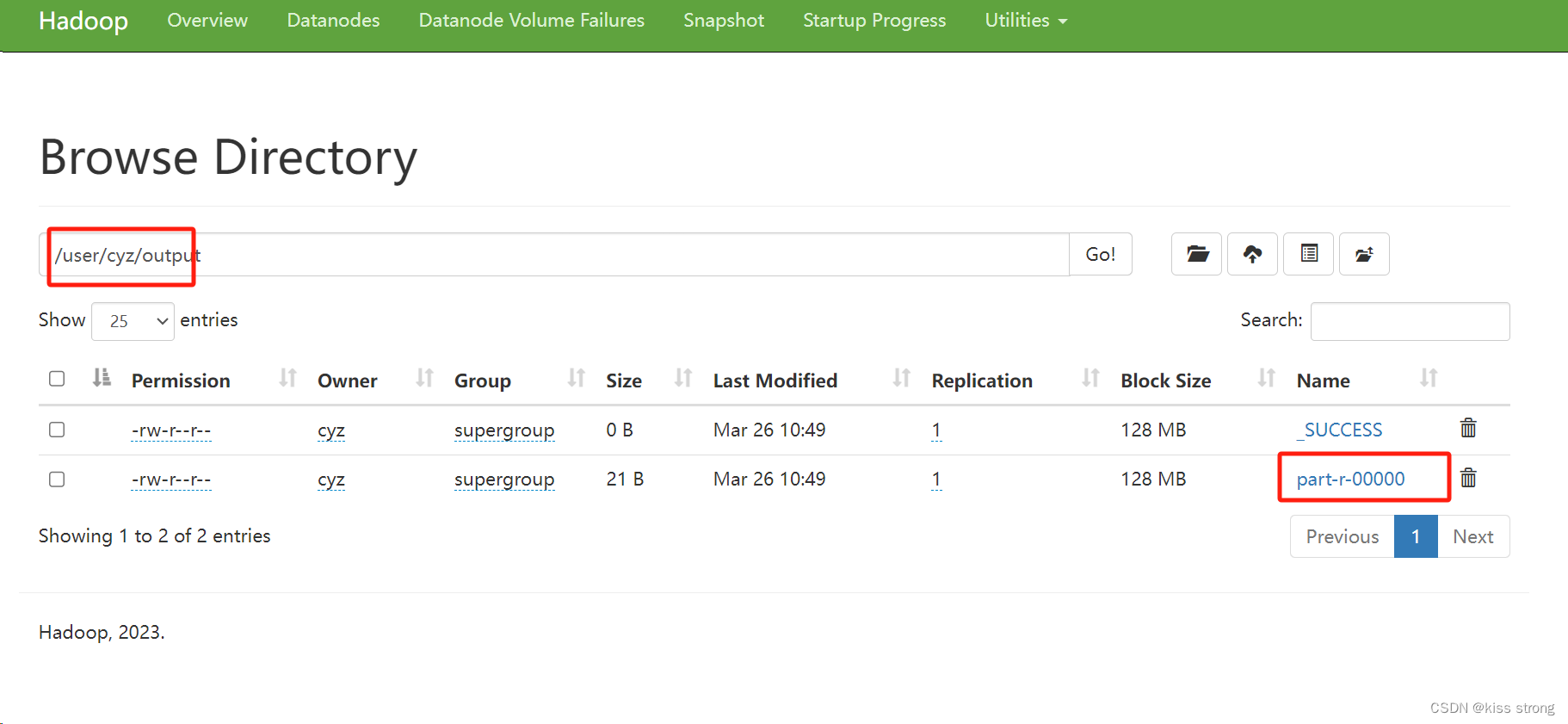 下载文件
下载文件
hdfs dfs -get output output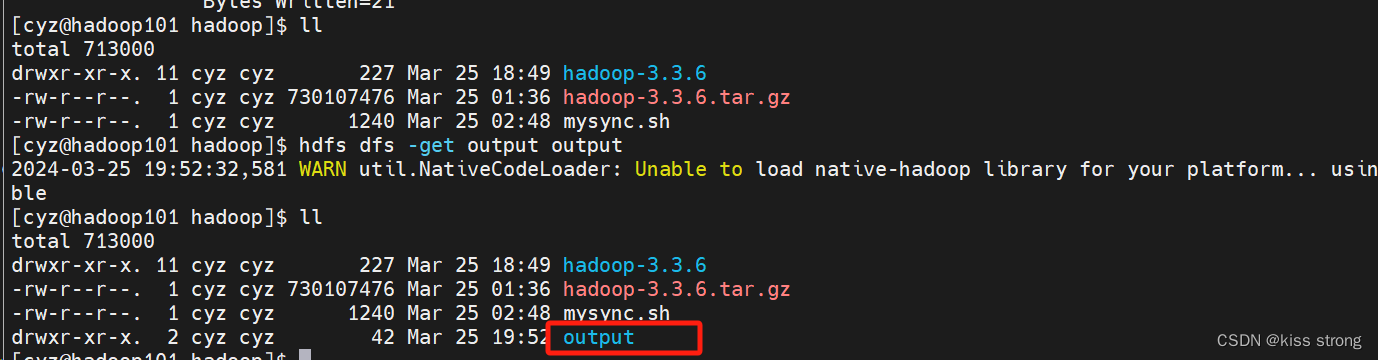
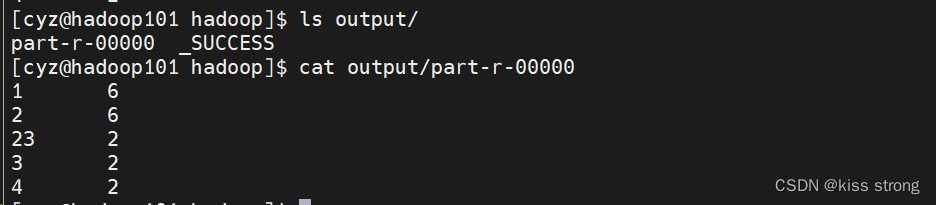 直接查看文件系统中文件
直接查看文件系统中文件
hdfs dfs -cat output/* 关闭NameNode守护程序和DataNode守护程序:
关闭NameNode守护程序和DataNode守护程序:
stop-dfs.sh
全分布式安装
描述及介绍
本部分档描述了如何安装和配置Hadoop集群,从几个节点到数千个节点的超大集群。
Hadoop的Java配置由两种类型的重要配置文件驱动:
- 只读默认配置-core-default.xml、hdfs-default.xml,yarn-default.xml和mapred-default.xml。特定于站点的配置-etc/hadoop/core-Site.xml、etc/hdooop/hdfs-Site.xml、etc/hodop/yarn-Site.xml和etc/hadop/mapred-Site.xml。
- 此外,您还可以通过/etc/Hadoop/Hadoop-env.sh和etc/haooop/yarn-env.sh设置特定于站点的值来控制分布的bin/目录中的Hadoop脚本。
- 要配置Hadoop集群,您需要配置Hadoop守护进程执行的环境以及Hadoop守护程序的配置参数。
- HDFS守护进程是NameNode、SecondaryNameNode和DataNode。YARN守护进程是ResourceManager、NodeManager和WebAppProxy。如果要使用MapReduce,那么MapReduce作业历史服务器也将运行。对于大型安装,这些通常在单独的主机上运行。
管理员应该使用/etc/hadoop/adoop-env.sh,以及可选的/etc/hadoop/mapred-env.sh和/etc/hadoop/yarn-env.h脚本来对hadoop守护进程的进程环境进行特定站点的自定义。
至少,您必须指定JAVA_HOME,以便在每个远程节点上正确定义它。
管理员可以使用下表中显示的配置选项配置各个守护程序:
| Daemon | Environment Variable |
|---|---|
| NameNode | HDFS_NAMENODE_OPTS |
| DataNode | HDFS_DATANODE_OPTS |
| Secondary NameNode | HDFS_SECONDARYNAMENODE_OPTS |
| ResourceManager | YARN_RESOURCEMANAGER_OPTS |
| NodeManager | YARN_NODEMANAGER_OPTS |
| WebAppProxy | YARN_PROXYSERVER_OPTS |
| Map Reduce Job History Server | MAPRED_HISTORYSERVER_OPTS |
例如,要将Namenode配置为使用parallelGC和4GB Java堆,应在hadoop-env.sh中添加以下语句
export HDFS_NAMENODE_OPTS="-XX:+UseParallelGC -Xmx4g"配置文件中指定的重要参数
etc/hadoop/core-site.xml
| Parameter | Value | Notes |
|---|---|---|
fs.defaultFS | NameNode URI | hdfs://host:port/ |
io.file.buffer.size | 131072 | SequenceFiles中使用的读/写缓冲区的大小。 |
-
etc/hadoop/hdfs-site.xmlConfigurations for NameNode
| Parameter | Value | Notes |
|---|---|---|
dfs.namenode.name.dir | 本地文件系统上的路径,NameNode持久存储命名空间和事务日志 | 如果这是一个逗号分隔的目录列表,则名称表将复制到所有目录中,以实现冗余。 |
dfs.hosts / dfs.hosts.exclude | 允许/排除的数据节点列表。 | 如有必要,请使用这些文件来控制允许的数据节点列表。 |
dfs.blocksize | 268435456 | 用于大型文件系统的256MB HDFS块大小。一般根据磁盘来定,如果是硬盘则是128,如果是固态硬盘则是256 |
dfs.namenode.handler.count | 100 | 更多的NameNode服务器线程来处理来自大量DataNode的RPC |
Configurations for DataNode:
| Parameter | Value | Notes |
|---|---|---|
dfs.datanode.data.dir | 数据节点的本地文件系统上的路径的逗号分隔列表,数据节点应存储其块 | 如果这是一个逗号分隔的目录列表,那么数据将存储在所有命名目录中,通常存储在不同的设备上 |
-
etc/hadoop/yarn-site.xmlConfigurations for ResourceManager and NodeManager:
| Parameter | Value | Notes |
|---|---|---|
yarn.acl.enable | true / false | 启用ACL?默认为false。 |
yarn.admin.acl | Admin ACL | 用于在群集上设置管理员的ACL。ACL用于逗号分隔的用户空间逗号分隔的组。默认为特殊值*,表示任何人。只有空间的特殊价值意味着没有人可以访问 |
yarn.log-aggregation-enable | false | 启用或禁用日志聚合的配置 |
Configurations for ResourceManager
| Parameter | Value | Notes |
|---|---|---|
yarn.resourcemanager.address | ResourceManager host:port for clients to submit jobs. | host:port如果已设置,则覆盖在yarn.resourcemanager.hostname中设置的主机名。 |
yarn.resourcemanager.scheduler.address | ResourceManager host:port for ApplicationMasters to talk to Scheduler to obtain resources. | host:port如果已设置,则覆盖在yarn.resourcemanager.hostname中设置的主机名。 |
yarn.resourcemanager.resource-tracker.address | ResourceManager host:port for NodeManagers. | host:port如果已设置,则覆盖在yarn.resourcemanager.hostname中设置的主机名。 |
yarn.resourcemanager.admin.address | ResourceManager host:port for administrative commands. | host:port如果已设置,则覆盖在yarn.resourcemanager.hostname中设置的主机名。 |
yarn.resourcemanager.webapp.address | ResourceManager web-ui host:port. | host:port如果已设置,则覆盖在yarn.resourcemanager.hostname中设置的主机名。 |
yarn.resourcemanager.hostname | ResourceManager host. | host可以设置单个主机名来代替设置所有yars.resourcemanager*地址资源。导致ResourceManager组件的默认端口。 |
yarn.resourcemanager.scheduler.class | ResourceManager Scheduler class. | 容量使用完全限定的类名,例如[UNK]org.apache.hadoop.yarn.server.resourcemanager.scheduler.fair。FairScheduler。 |
yarn.scheduler.minimum-allocation-mb | Minimum limit of memory to allocate to each container request at the Resource Manager. | In MBs |
yarn.scheduler.maximum-allocation-mb | Maximum limit of memory to allocate to each container request at the Resource Manager. | In MBs |
yarn.resourcemanager.nodes.include-path / yarn.resourcemanager.nodes.exclude-path | List of permitted/excluded NodeManagers. | 如有必要,请使用这些文件来控制允许的NodeManager列表。 |
等等,详情请看官网 Apache Hadoop 3.3.6 – Hadoop Cluster Setup
部署集群
规划:
NameNode和 SecondaryNameNode不要安装在同一台服务器
ResourceManager也很消耗内存,不要和 NameNode、SecondaryNameNode配置在同一台机器上
| hadoop101 | hadoop102 | hadoop103 | |
| HDFS | NameNode DataNode | DataNode | SecondaryNameNode DataNode |
| YARN | NodeManager | ResourceManager NodeManager | NodeManager |
配置文件说明
Hadoop配置文件分两类:默认配置文件和自定义配置文件,只有用户想修改某一默认配置值时,才需要修改自定义配置文件,更改相应属性值。
默认配置文件
| 要获取的默认文件 | 文件存放在 Hadoop 的 jar 包中的位置 |
| core-default.xml | hadoop-common-3.3.6.jar/core-default.xml |
| hdfs-default.xml | hadoop-hdfs-3.3.6.jar/hdfs-default.xml |
| yarn-default.xml | hadoop-yarn-common-3.3.6.jar/yarn-default.xml |
| mapred-default.xml | hadoop-mapreduce-client-core-3.3.6.jar/mapred-default.xml |
自定义配置文件(重点)
core-site.xml、 hdfs-site.xml、 yarn-site.xml、 mapred-site.xml四个配置文件存放在$HADOOP_HOME/etc/hadoop这个路径上,用户可以根据项目需求重新进行修改配置
配置集群
核心配置文件 配置core-site.xml
[cyz@hadoop101 hadoop]$ vim hadoop-3.3.6/etc/hadoop/core-site.xml
<configuration>
<!--指定NameNode的地址-->
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop101:8020</value>
</property>
<!--指定hadoop数据的存储目录-->
<property>
<name>hadoop.tmp.dir</name>
<value>/home/hadoop/hadoop-3.3.6/data</value>
</property>
<!--配置HDFS网页登录使用的静态用户为Tom -->
<property>
<name>hadoop.http.staticuser.user</name>
<value>cyz</value>
</property>
</configuration>
HDFS配置文件 配置 hdfs-site.xml
[cyz@hadoop101 hadoop]$ vim hadoop-3.3.6/etc/hadoop/hdfs-site.xml
<configuration>
<!--nn web端访问地址-->
<property>
<name>dfs.namenode.http-address</name>
<value>hadoop101:9870</value>
</property>
<!--2nn web端访问地址-->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>hadoop103:9868</value>
</property>
</configuration>
YARN配置文件 配置 yarn-site.xml
[cyz@hadoop101 hadoop]$ vim hadoop-3.3.6/etc/hadoop/yarn-site.xml
<configuration>
<!--指定MR走shuffle -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!--指定ResourceManager的地址-->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop102</value>
</property>
<!--环境变量的继承-->
<property>
<name>yarn.nodemanager.env-whitelist</name>
<value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value>
</property>
</configuration>
MapReduce配置文件 配置 mapred-site.xml
[cyz@hadoop101 hadoop]$ vim hadoop-3.3.6/etc/hadoop/mapred-site.xml<configuration>
<!--指定MapReduce程序运行在Yarn上-->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>配置 workers
[cyz@hadoop101 hadoop]$ vim hadoop-3.3.6/etc/hadoop/workers
hadoop101
hadoop102
hadoop103不能有空格,否则会报错
分发配置到hadoop102 hadoop103
[cyz@hadoop101 hadoop]$ sh mysync.sh hadoop-3.3.6/etc/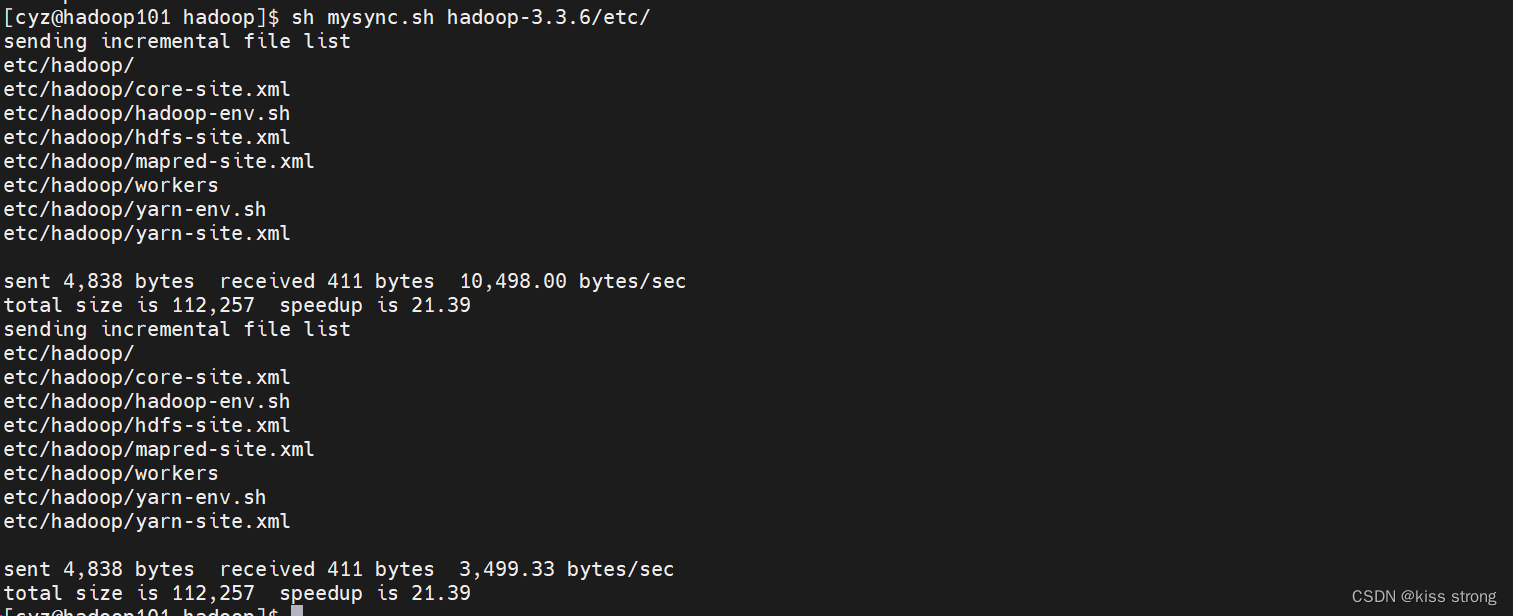
去 hadoop102 hadoop103查看是否成功,成功即可
启动集群
第一次启动需要格式化(如果非第一次启动建议删除data和logs文件夹再次格式化)
hdfs namenode -format
启动 HDFS
start-dfs.sh 如果报错
没有设置JAVA_HOME,需要在配置文件etc/hadoop/hadoop-env.sh加上环境变量
export JAVA_HOME=/home/jdk8/jdk1.8.0_401再次执行start-dfs.sh
发现警告,需要停止进程,如下操作
一般出现这个错误都是出现在64位机器上,只需要在hadoop-env.sh、yarn-env.sh两个文件下面加上如下配置即可
export HADOOP_COMMON_LIB_NATIVE_DIR=${HADOOP_HOME}/lib/native
export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib"
再起启动

在配置了 ResourceManager的节点 hadoop102 启动 YARN
[cyz@hadoop102 hadoop]$ start-yarn.sh
Starting resourcemanager
Starting nodemanagers
[cyz@hadoop102 hadoop]$
查看jps



web查看
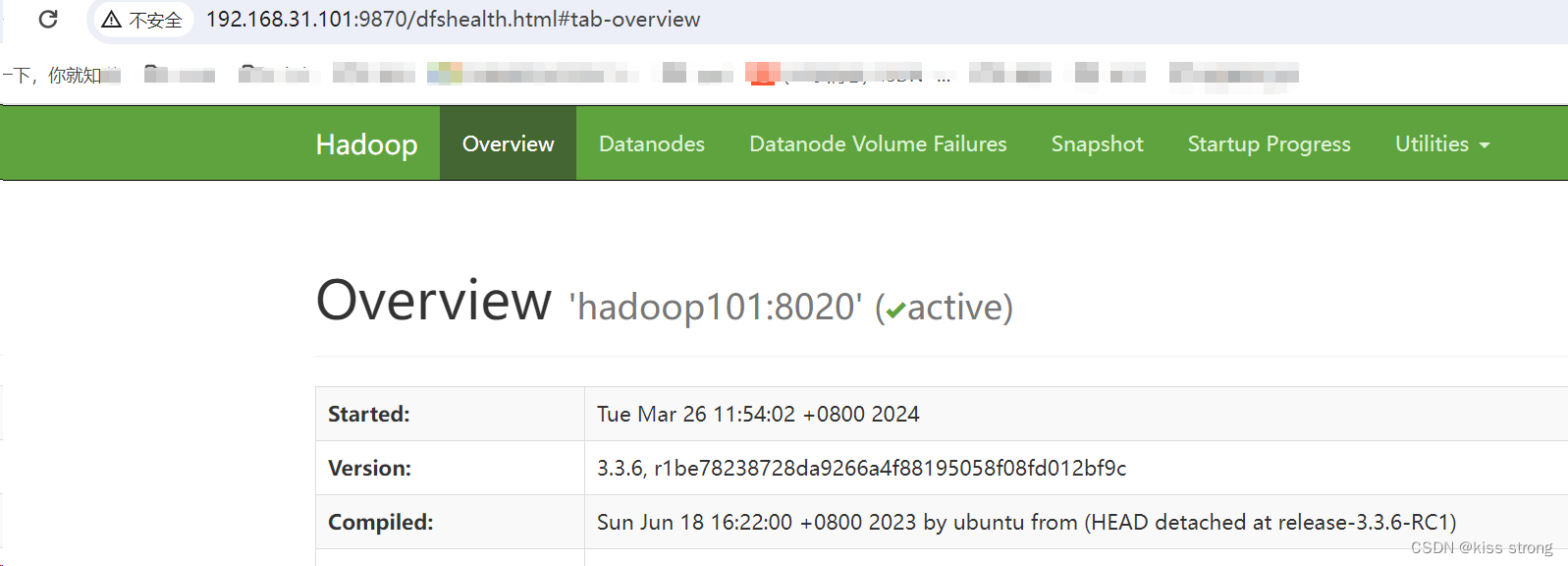
Web端查看 HDFS的 NameNode
http://hadoop101:9870
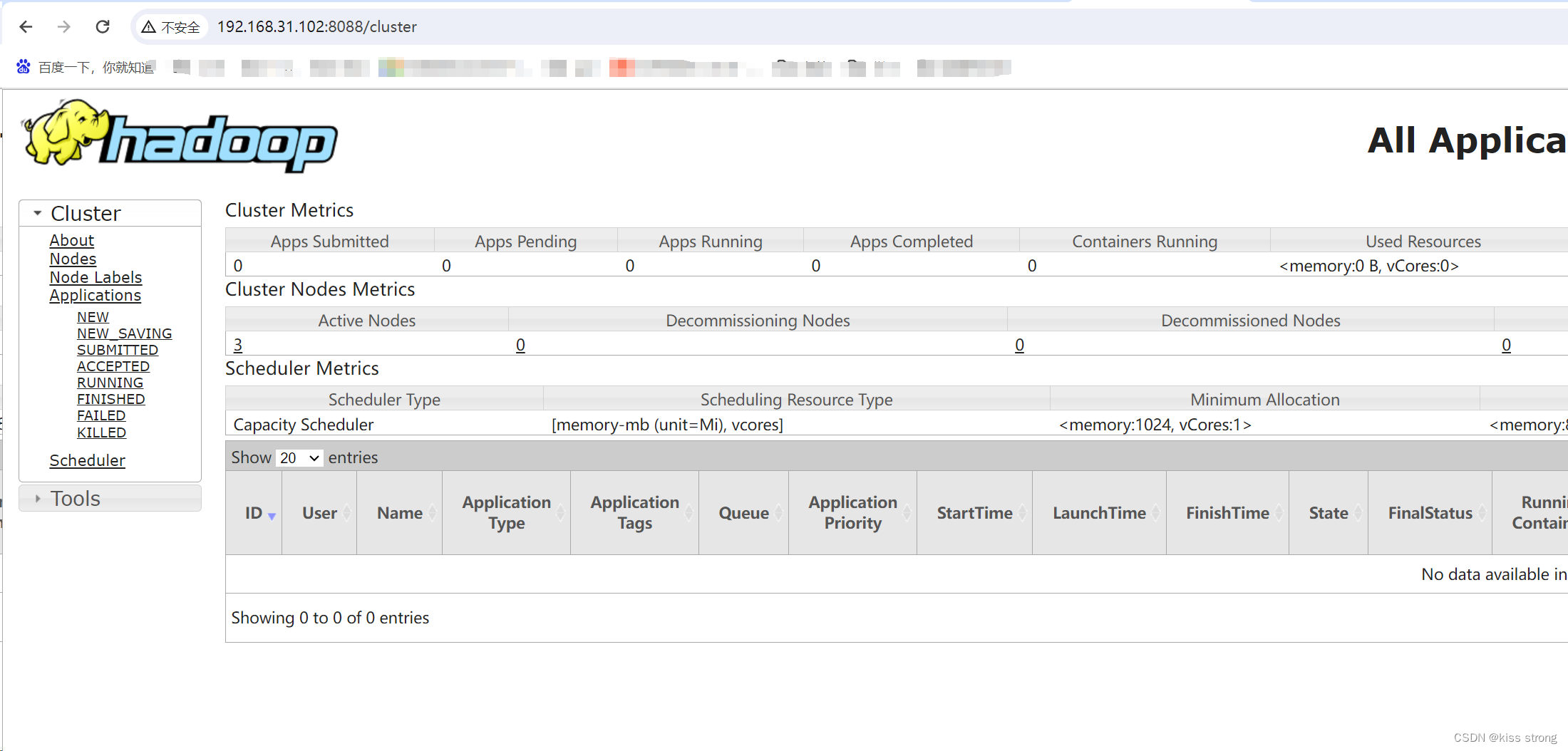
Web端查看 YARN的 ResourceManager
浏览器 中输入 http://hadoop102:8088
集群基本测试
上传文件
上传txt文件夹到服务器input

hadoop fs -put txt/ /input 
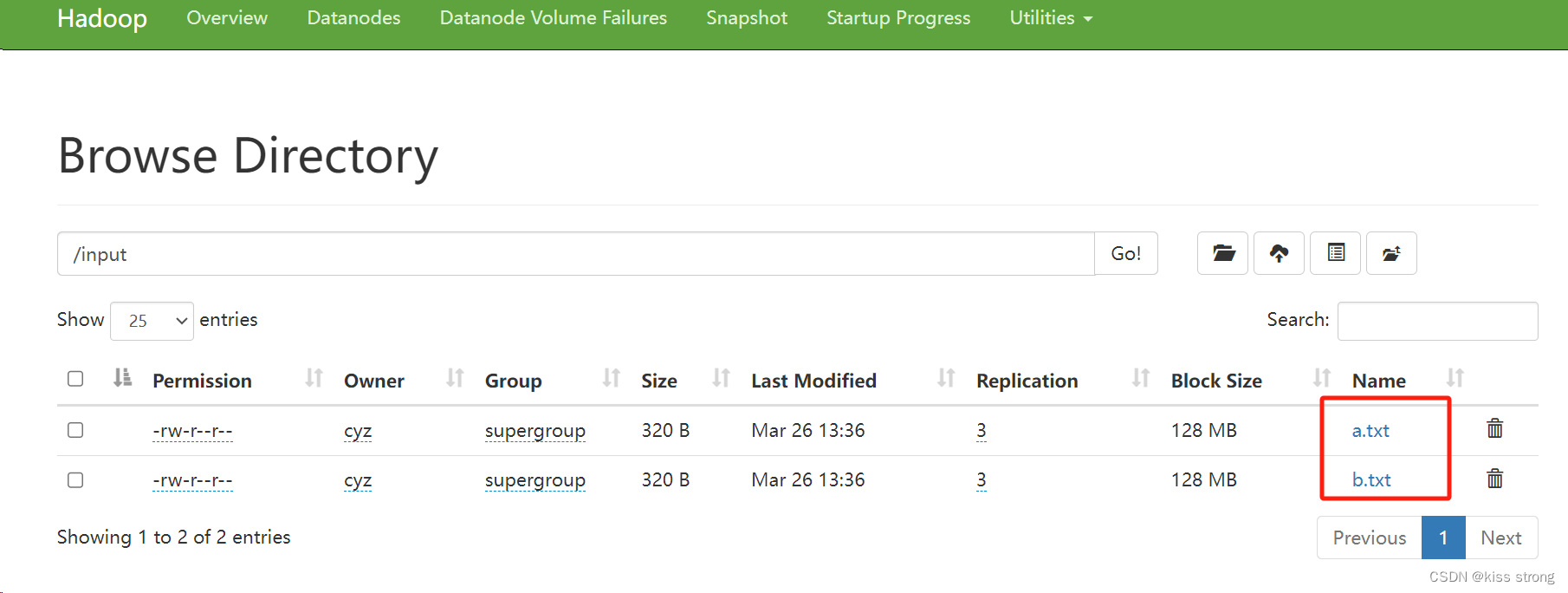 文件存放位置
文件存放位置
/home/hadoop/hadoop-3.3.6/data/dfs/data/current/BP-1683813538-192.168.31.101-1711425202456/current/finalized/subdir0/subdir0

如果上传的是大文件,就会在存储的时候变成多份,如下

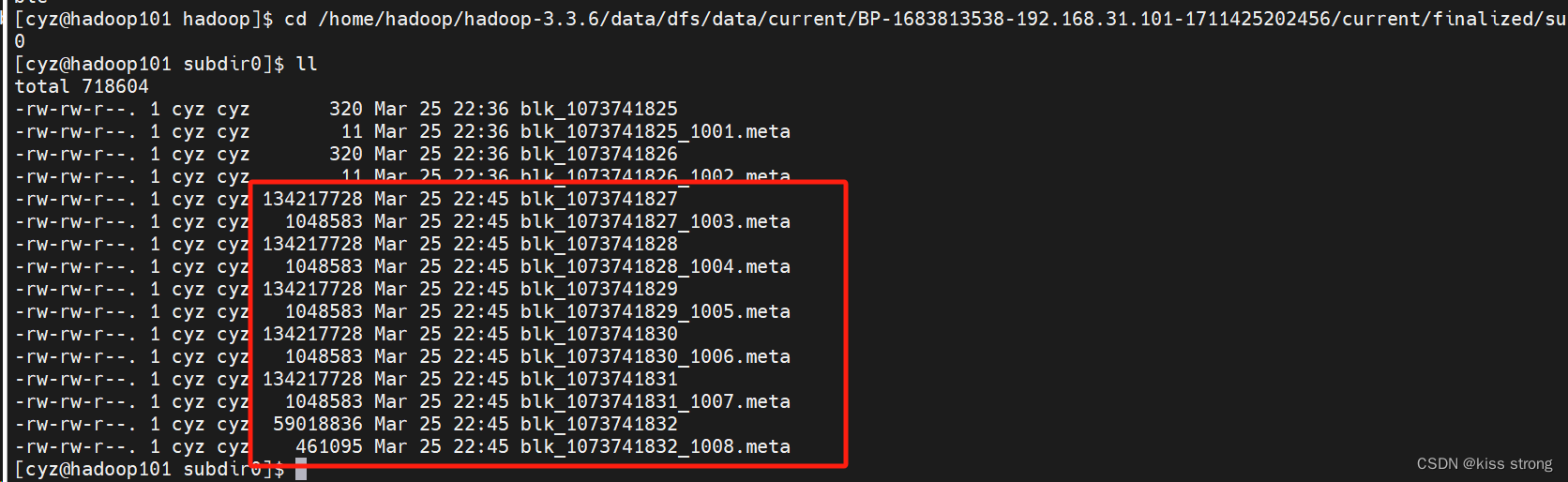 要想通过命令行查看文件,则需要使用拼接命令
要想通过命令行查看文件,则需要使用拼接命令
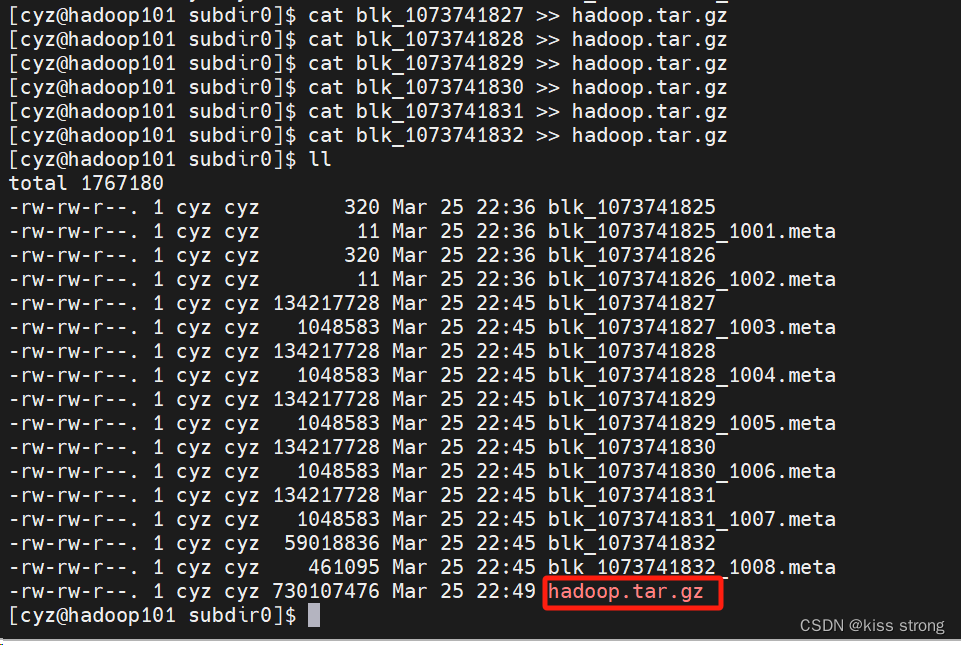
这样才是完整的文件
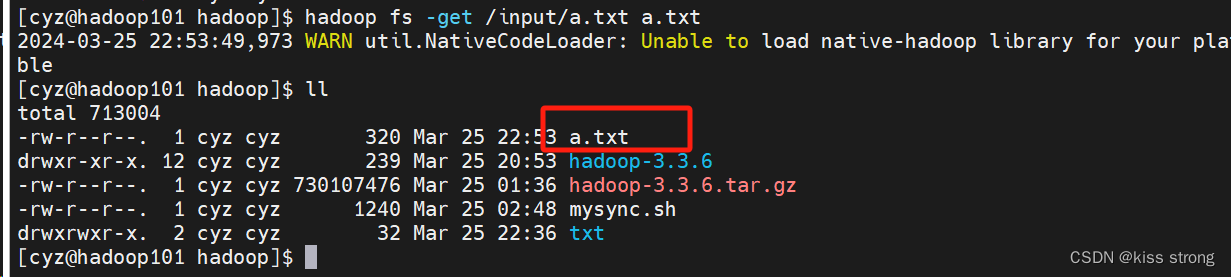
下载文件
hadoop fs -get /input/a.txt a.txt
配置历史服务器
为了查看程序的历史运行情况,需要配置一下历史服务器。具体配置步骤如下
配置 mapred-site.xml
[cyz@hadoop101 hadoop]$ vim hadoop-3.3.6/etc/hadoop/mapred-site.xml
添加如下内容
<!--历史服务器端地址-->
<property>
<name>mapreduce.jobhistory.address</name>
<value>hadoop101:10020</value>
</property>
<!--历史服务器web端地址-->
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>hadoop101:19888</value>
</property>
分发配置
sh mysync.sh hadoop-3.3.6/etc/hadoop/mapred-site.xml

在 hadoop101启动历史服务器 daemon是守护线程
mapred --daemon start historyserver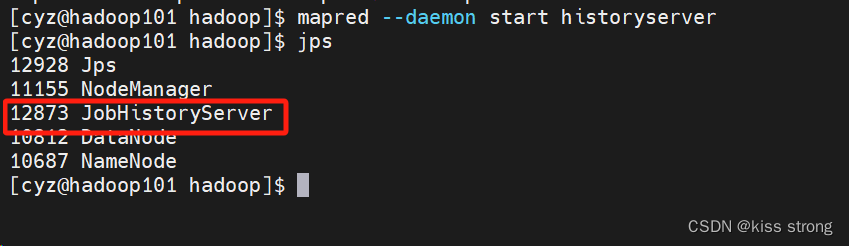
查看 JobHistory
http://hadoop101:19888/jobhistory
配置日志的聚集
日志聚集概念:应用运行完成以后,将程序运行日志信息上传到 HDFS系统上。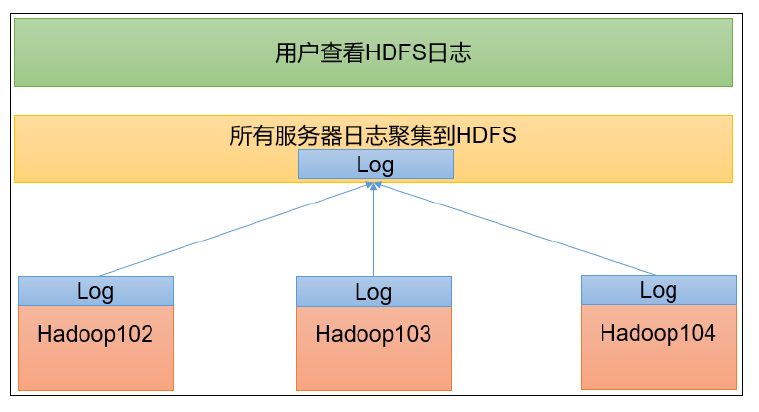
日志聚集功能好处 :可以方便的查看到程序运行详情,方便开发调试 。
开启日志聚集功能需要重新启动 NodeManager 、ResourceManager和HistoryServer。
开启日志聚集功能具体步骤如下
配置 yarn-site.xml
[cyz@hadoop101 hadoop]$ vim hadoop-3.3.6/etc/hadoop/yarn-site.xml在里面加上如下内容
<!--开启日志聚集功能-->
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<!--设置日志聚集服务器地址-->
<property>
<name>yarn.log.server.url</name>
<value>http://hadoop101:19888/jobhistory/logs</value>
</property>
<!--设置日志保留时间为7天-->
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>604800</value>
</property>
分发配置
[cyz@hadoop101 hadoop]$ sh mysync.sh hadoop-3.3.6/etc/hadoop/yarn-site.xml
关闭 NodeManager 、 ResourceManager和 HistoryServer
[cyz@hadoop101 hadoop]$ stop-yarn.sh
Stopping nodemanagers
Stopping resourcemanager
[cyz@hadoop101 hadoop]$ mapred --daemon stop historyserver
[cyz@hadoop101 hadoop]$ jps
13414 Jps
10812 DataNode
10687 NameNode
[cyz@hadoop101 hadoop]$
启动 NodeManager 、 ResourceManage和 HistoryServer
[cyz@hadoop101 hadoop]$ start-yarn.sh
Starting resourcemanager
Starting nodemanagers
[cyz@hadoop101 hadoop]$ mapred --daemon start historyserver
[cyz@hadoop101 hadoop]$ jps
13793 JobHistoryServer
13879 Jps
13640 NodeManager
10812 DataNode
10687 NameNode
[cyz@hadoop101 hadoop]$
删除 HDFS上已经存在的输出文件(非必须,如果不存在就不需要执行)
[cyz@hadoop101 hadoop]$ hadoop fs -rm -r /output执行 WordCount程序
计算服务器上/input下面文件中的单词数
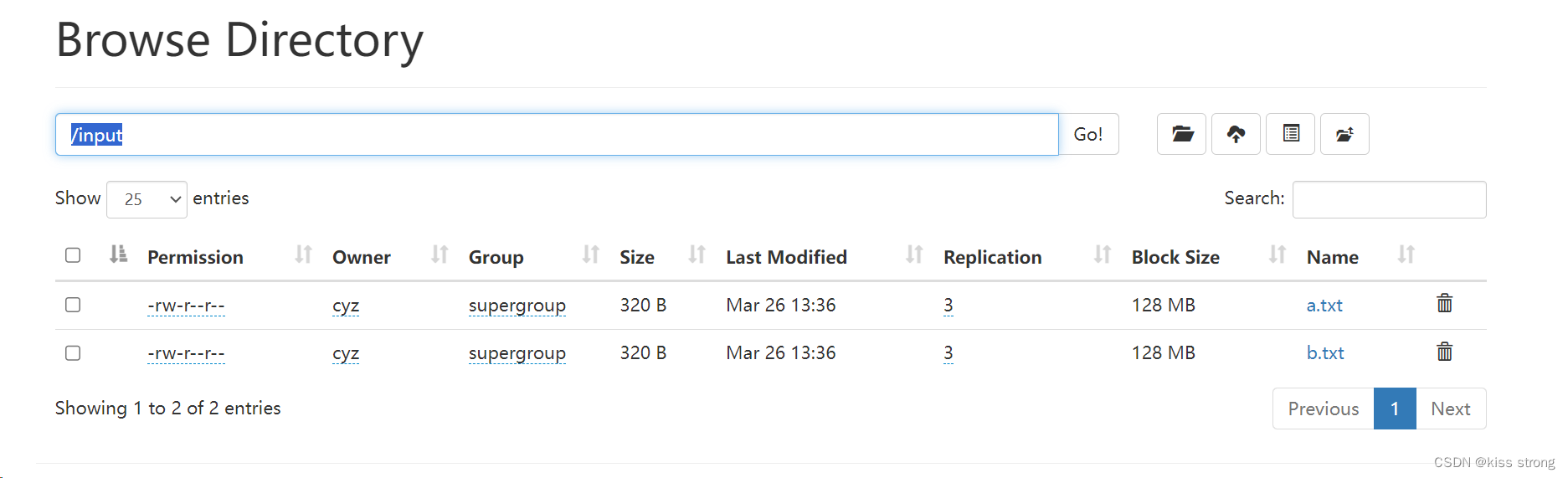
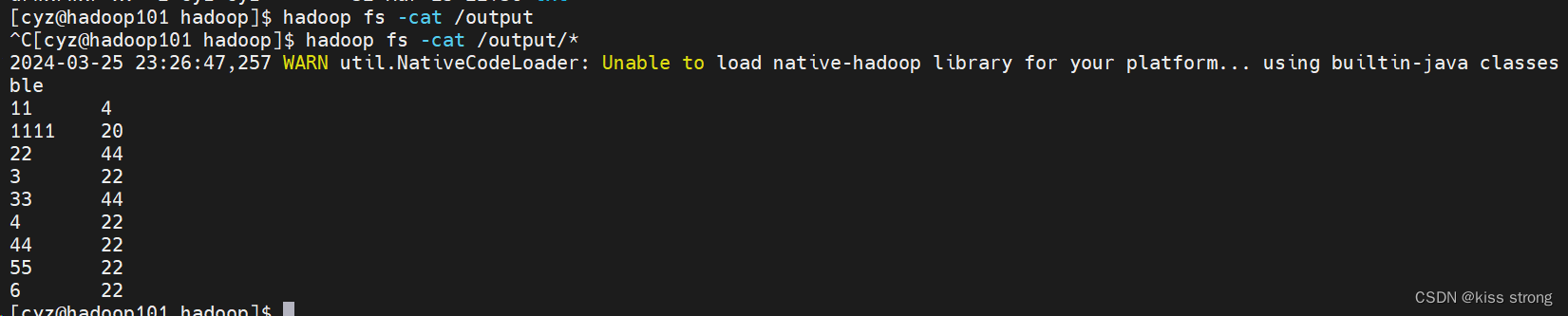
[cyz@hadoop101 hadoop]$ hadoop jar hadoop-3.3.6/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.6.jar wordcount /input /output
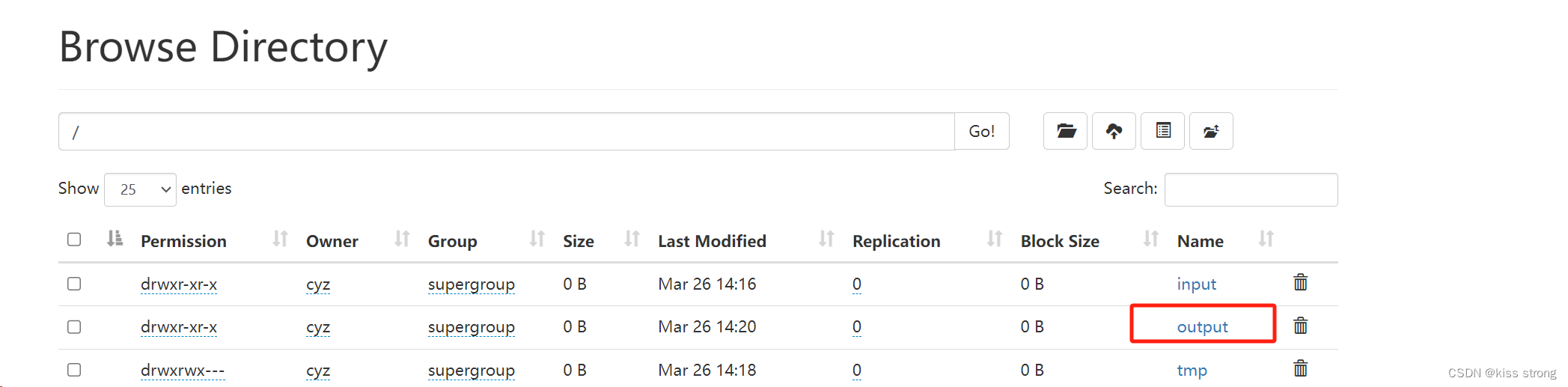

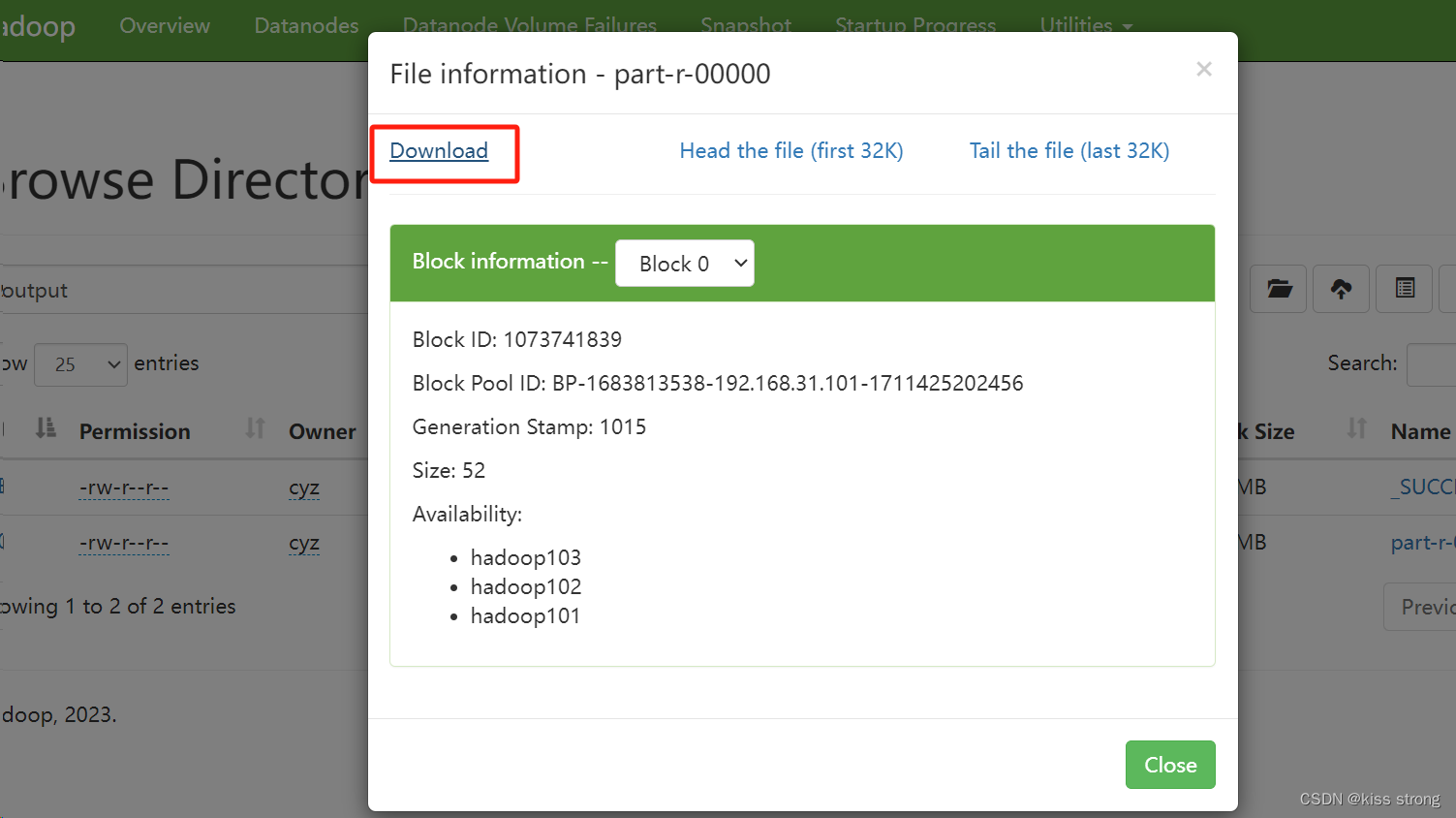
如果下载失败,需要在当前机器上配置域名映射,下载好打开

也可以使用命令查看
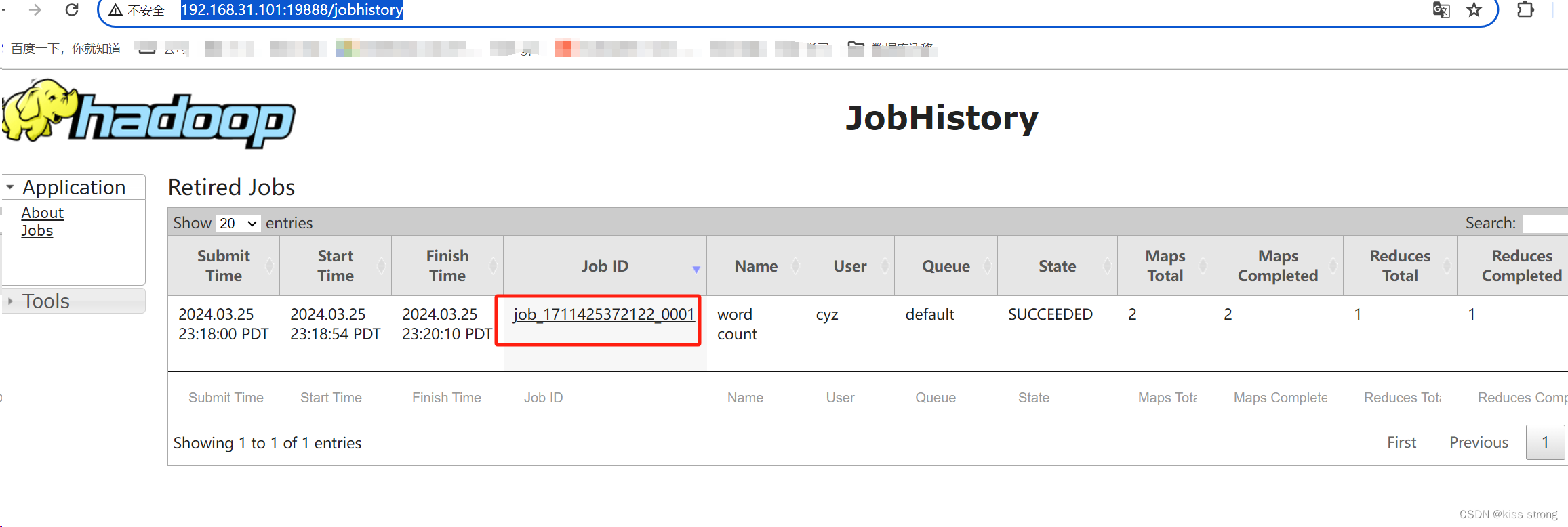
查看日志
http://hadoop101:19888/jobhistory
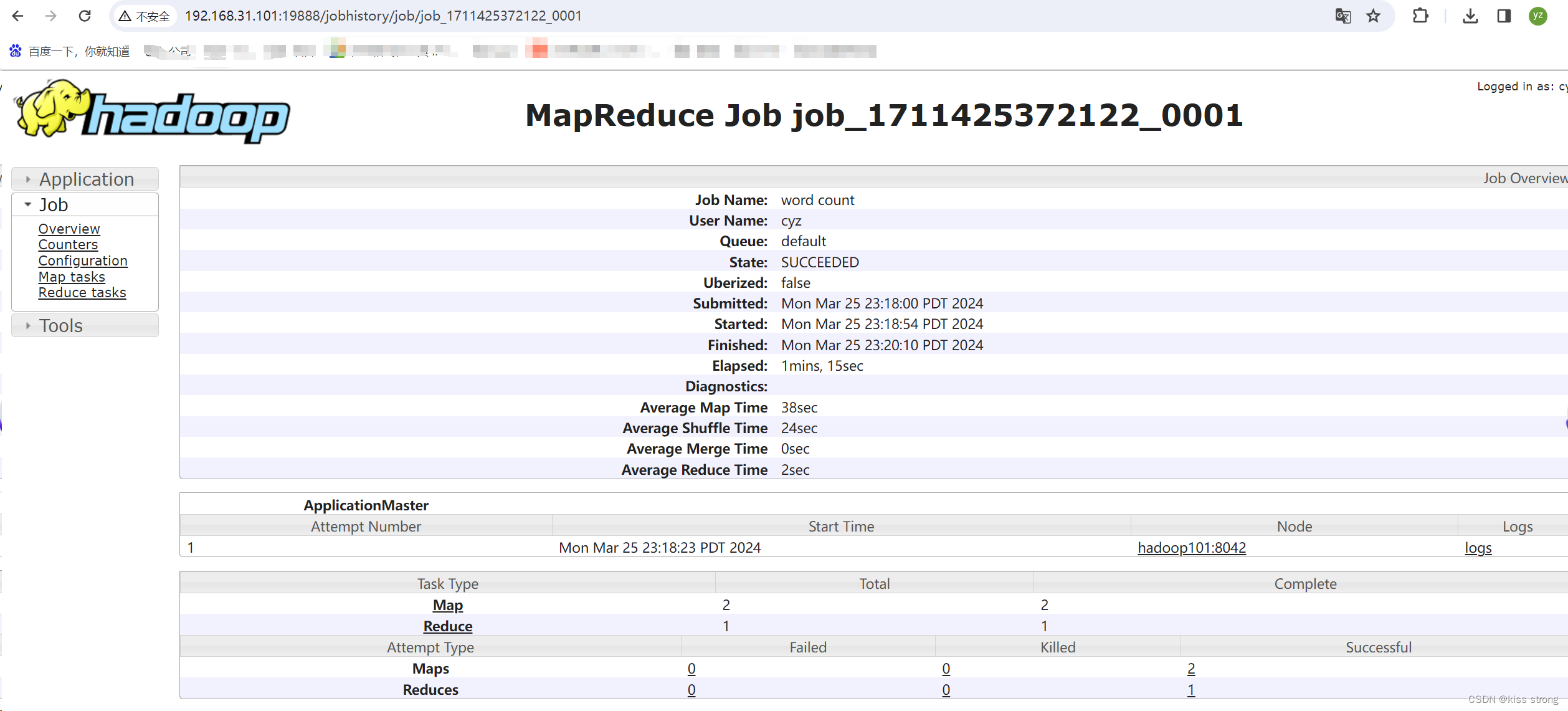
集群启动/停止方式总结
各个模块分开启动 /停止(配置 ssh是前提)常用
整体启动 /停止 HDFS
start dfs.sh/stop dfs.sh
整体启动 /停止 YARN
start yarn.sh/stop yarn.sh
各个服务组件逐一启动 /停止
分别启动 /停止 HDFS组件
hdfs daemon start/stop namenode/datanode/secondarynamenode
启动 /停止 YARN
yarn daemon start/stop resourcemanager/nodemanager
编写 Hadoop集群常用脚本
Hadoop集群启停脚本
(包含 HDFS, Yarn, Historyserver) : myhadoop.sh
#!/bin/bash
if [ $# -lt 1 ]
then
echo "No Args Input..."
exit ;
fi
case $1 in
"start")
echo " =================== 启动hadoop集群==================="
echo " ---------------启动hdfs ---------------"
ssh hadoop101 "/home/hadoop/hadoop-3.3.6/sbin/start-dfs.sh"
echo " ---------------启动yarn ---------------"
ssh hadoop102 "/home/hadoop/hadoop-3.3.6/sbin/start-yarn.sh"
echo " ---------------启动historyserver ---------------"
ssh hadoop101 "/home/hadoop/hadoop-3.3.6/bin/mapred --daemon start historyserver"
;;
"stop")
echo " =================== 关闭hadoop集群==================="
echo " ---------------关闭historyserver ---------------"
ssh hadoop101 "/home/hadoop/hadoop-3.3.6/bin/mapred --daemon stop historyserver"
echo " ---------------关闭yarn ---------------"
ssh hadoop102 "/home/hadoop/hadoop-3.3.6/sbin/stop-yarn.sh"
echo " ---------------关闭hdfs ---------------"
ssh hadoop101 "/home/hadoop/hadoop-3.3.6/sbin/stop-dfs.sh"
;;
*)
echo "Input Args Error..."
;;
esac
查看三台服务器 Java进程脚本: jpsall.sh
#!/bin/bash
for host in hadoop101 hadoop102 hadoop103
do
echo =============== $host ===============
ssh $host jps
done
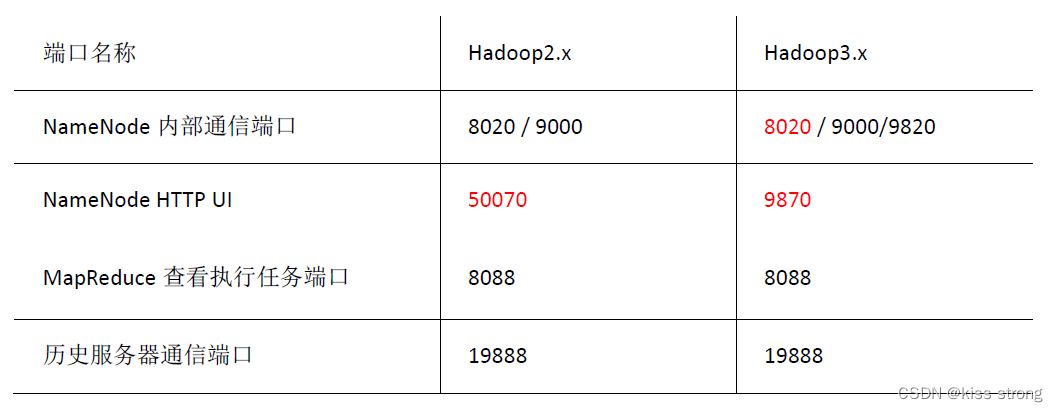
常用端口号说明及版本区别














![[Android]模拟器登录Google Play失败](https://img-blog.csdnimg.cn/direct/d0ca9bc9e9f44dccbccbd31f9d2bd17e.png)

