公众号:程序员白特,欢迎一起交流学习~
原文:https://juejin.cn/post/7265125368553685050?share_token=301335cf-a17e-4115-94f0-264fe0e82f07
前言
在前端面试的过程中,前端工程化一直是考察面试者能力的一个重点,而在我们常用的项目打包工具中,无论是webpack还是rollup,都具备一项很强大的能力——tree-shaking,所以面试官也常常会问到tree-shaking的原理是什么,这时我们该如何回答呢?其实核心原理就是AST。
在前端开发中,其实AST的应用有很多,比如我们前端项目的打包工具webpack、代码检查工具Eslint,代码转换工具babel都依赖了AST的语法分析和转换能力。
AST简单介绍
AST是Abstract Syntax Tree的缩写,这玩意儿的全称叫抽象语法树,它可以用来描述我们代码的语法结构。
举个例子:
// ast.js
let a = 1;
function add() {}
我这里创建了一个文件ast.js,可以把整个文件理解为一个File节点,存放程序体,而里面就是我们javascript的语法节点了,我们javascript语法节点的根节点是Program,而我们在里面定了了两个节点,第一个节点是let a = 1,解析为ast是VariableDeclaration,也就是变量声明节点,第二个节点是function add() {},解析为ast是FunctionDeclaration,也就是函数声明节点。
这里给大家推荐一个平台:AST Explorer,能很清晰看到JavaScript代码转化为AST后的结果,看下下面这张图就一目了然了:
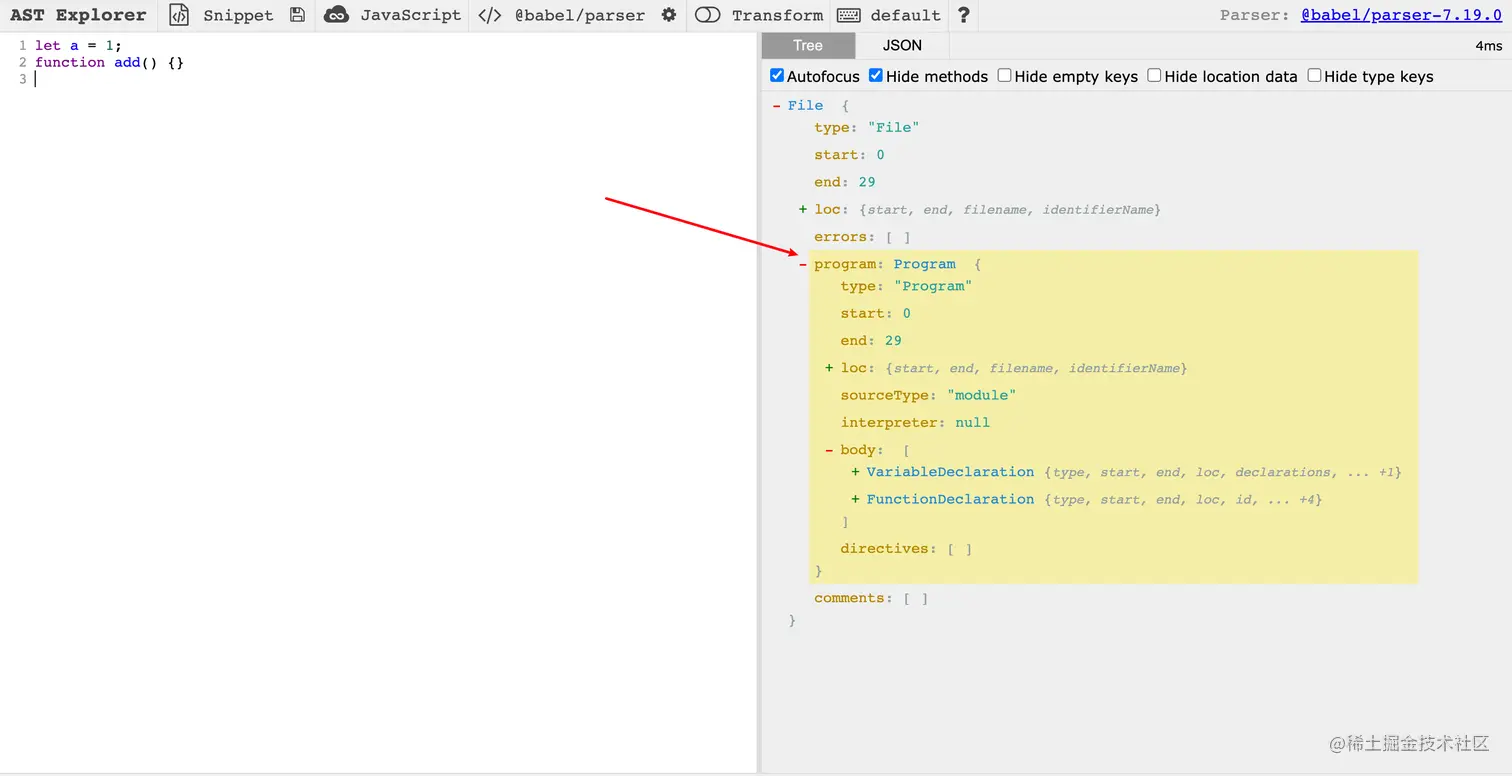
AST的作用
那拿到了代码的ast信息我们能做什么呢?
- 代码分析与转换。
AST可以将我们的代码解析成一棵ast树,我们自然可以将这棵树进行处理和转换,这个最经典的应用莫过于babel了,将我们的高级语法ES6转换为ES5后,然后再把ast树转换成代码输出。除此之外,webpack的处理ES6的import和export也是依赖了ast的能力,以及我们的jsx的语法转换等。 - 语法检查和错误提示。我们把语法解析成
ast树之后,自然就可以按照一定的语法规则去检查它的语法是否正确,一旦错误就可以抛出错误,提醒开发者去修正。比如我们使用的vscode就是利用AST 提供实时的语法检查和错误提示。而在前端项目中,应用的最广的语法检查工具就是ESlint了,基本就是前端项目必备。 - 静态类型检查。这个其实跟第二点有点像,不过第二点是侧重于
语法检查,而这个是针对类型检查的,比如我们的Typescript会利用ast进行类型检查和推断。 - 代码重构。基于AST树,我们可以对代码进行
自动重构。比如提取函数、变量重命名、语法升级、函数移动等。
其实在实际开发中,我们也可以利用做很多的事情,比如实现自动埋点、自动国际化、依赖分析和治理等等,有兴趣的小伙伴可以自行去探索。
而今天我主要介绍的就是AST的一大应用,就是我们webpack强大的Tree-Shaking能力。
Tree-shaking
Tree-shaking翻译过来的意思就是摇树。这棵树可以把它比喻为现实中的树,可以这样理解,摇树就是把发黄、没有作用还要汲取养分的叶子给给摇掉。把这个搬到javascript程序里面来就是,移除Javascript上下文中的未引用代码(dead-code)。
废话不多说,直接看例子:
// test.js
function add(a, b) {
return a + b;
}
function multiple(a, b) {
return a * b;
}
let firstNum = 3, secondNum = 4;
add(firstNum, secondNum);
在这段代码中,我们定义了两个函数add和multiple,两个变量firstNum和secondNum,然后调用了add方法并将firstNum和secondNum作为参数传入。
很明显,multiple方法是没有被调用到的,打包的时候其实是可以被删除掉的,以减少我们打包后的代码体积。
那么,如何删除multiple呢?这时候就该我们的ast就登场了!要实现这个功能,分三步走。
第一步:解析源代码生成ast
先看如下代码:
const acorn = require('acorn');
const fs = require('fs');
const path = require('path');
const buffer = fs.readFileSync(path.resolve(process.cwd(), 'test.js')).toString();
const body = acorn.parse(buffer, {
ecmaVersion: 'latest',
}).body;
这里我们选中acorn(babel其实是基于acorn实现解析器的)来对我们的代码进行解析,运行前需要先执行npm install acorn安装下acorn,然后读取文件内容传入acorn,得到ast。
我们可以用AST Explorer,来看一眼我们现在的AST。

第二步:遍历ast,记录相关信息
一、先明确下我们要记录哪些信息?
我们的主要目的是收集到未引用的代码,然后将它们删除掉,所以我们最容易想到的需要收集的信息有两个:
- 收集所有的
函数或变量类型节点 - 收集所有使用过的
函数或变量类型节点
那我们先试试看:
const acorn = require('acorn');
const fs = require('fs');
const path = require('path');
const buffer = fs.readFileSync(path.resolve(process.cwd(), './src/index.js')).toString();
const body = acorn.parse(buffer, {
ecmaVersion: 'latest',
}).body;
// 引用一个 Generator 类,用来生成 ast 对应的代码
const Generator = require('./generator');
// 创建 Generator 实例
const gen = new Generator();
// 定义变量decls 存储所有的函数或变量类型节点 Map类型
const decls = new Map();
// 定义变量calledDecls 存储被用到过的函数或变量类型节点 数组类型
const calledDecls = [];
这里我引入了一个Generator,其作用就是将每个ast节点转化成对应的代码,来看下Generator的实现:
- 先定义好
Generator类,将其导出。
// generator.js
class Generator {
}
module.exports = Generator;
- 定义
run方法以及visitNode和visitNodes方法。
run:调用visitNodes方法生成代码。visitNode:根据节点类型,调用对应的方法进行对应处理。visitNodes:就是处理数组类型的节点用的,内部循环调用了visitNode方法。
// generator.js
class Generator {
run(body) {
let str = '';
str += this.visitNodes(body);
return str;
}
visitNodes(nodes) {
let str = '';
for (const node of nodes) {
str += this.visitNode(node);
}
return str;
}
visitNode(node) {
let str = '';
switch (node.type) {
case 'VariableDeclaration':
str += this.visitVariableDeclaration(node);
break;
case 'VariableDeclarator':
str += this.visitVariableDeclarator(node);
break;
case 'Literal':
str += this.visitLiteral(node);
break;
case 'Identifier':
str += this.visitIdentifier(node);
break;
case 'BinaryExpression':
str += this.visitBinaryExpression(node);
break;
case 'FunctionDeclaration':
str += this.visitFunctionDeclaration(node);
break;
case 'BlockStatement':
str += this.visitBlockStatement(node);
break;
case 'CallExpression':
str += this.visitCallExpression(node);
break;
case 'ReturnStatement':
str += this.visitReturnStatement(node);
break;
case 'ExpressionStatement':
str += this.visitExpressionStatement(node);
break;
}
return str;
}
}
- 再分别介绍下每个处理节点类型的方法实现
实现visitVariableDeclaration方法
class Generator {
// 省略xxx
visitVariableDeclaration(node) {
let str = '';
str += node.kind + ' ';
str += this.visitNodes(node.declarations);
return str + '\n';
}
// 省略xxx
}
visitVariableDeclaration就是处理let firstNum = 3这种变量声明的节点,node.kind就是let/const/var,然后变量可以一次声明多个,比如我们test.js里面写的let firstNum = 3, secondNum = 4;,这样node.declarations就有两个节点了。

class Generator {
// 省略xxx
visitVariableDeclaration(node) {
let str = '';
str += node.kind + ' ';
str += this.visitNodes(node.declarations);
return str + '\n';
}
// 省略xxx
}
实现visitVariableDeclarator方法
class Generator {
// 省略xxx
visitVariableDeclaration(node) {
let str = '';
str += node.kind + ' ';
str += this.visitNodes(node.declarations);
return str + '\n';
}
// 省略xxx
}
visitVariableDeclarator就是上面VariableDeclaration的子节点,可以接收到父节点的kind,比如let firstNum = 3它的id就是变量名firstNum,init就是初始化的值3。

实现visitLiteral方法
class Generator {
visitLiteral(node) {
return node.raw;
}
}
Literal即字面量,比如let firstNum = 3里面的3就是一个字符串字面量,除此之外,还有数字字面量,布尔字面量等等,这个直接返回它的raw属性就行啦。

实现visitIdentifier方法
class Generator {
visitIdentifier(node) {
return node.name;
}
}
Identifier即标识符,比如变量名、属性名、参数名等都是,比如let firstNum = 3的firstNum,直接返回它的name属性即可。

实现visitBinaryExpression方法
BinaryExpression即二进制表达式,比如我们的加减乘除运算都是,比如a + b的ast如下:

我们需要拿到它的左右节点和中间的标识符拼接起来。
class Generator {
visitBinaryExpression(node) {
let str = '';
str += this.visitNode(node.left);
str += node.operator;
str += this.visitNode(node.right);
return str + '\n';
}
}
实现visitFunctionDeclaration方法
FunctionDeclaration即为函数声明节点,稍微复杂一些,因为我们要拼接一个函数出来。
function add(a, b) {
return a + b;
}
比如我们这个add函数转成ast如下图:

class Generator {
visitFunctionDeclaration(node) {
let str = 'function ';
str += this.visitNode(node.id);
str += '(';
for (let paramIndex = 0; paramIndex < node.params.length; paramIndex++) {
str += this.visitNode(node.params[paramIndex]);
str += ((node.params[paramIndex] === undefined) ? '' : ',')
}
str = str.slice(0, str.length - 1);
str += '){\n';
str += this.visitNode(node.body);
str += '}';
return str + '\n';
}
}
先拿到node.id,即add,然后处理函数的参数params,由于存在多个params需要循环处理,用逗号拼接,然后再调用visitNode方法拼接node.body即函数体。
实现visitBlockStatement方法
BlockStatement即块语句,就是我们的大括号包裹的部分。比如add函数里面的块语句的ast如下:


class Generator {
visitBlockStatement(node) {
let str = '';
str += this.visitNodes(node.body);
return str;
}
}
只需要用visitNodes函数拼接它的node.body即可。
实现visitCallExpression方法
CallExpression也就是函数调用,比如add(firstNum, secondNum),它比较重要的属性有:
callee:也就是addarguments:也就是调用的参数firstNum和secondNum其ast如下:

class Generator {
visitCallExpression(node) {
let str = '';
str += this.visitIdentifier(node.callee);
str += '(';
for (const arg of node.arguments) {
str += this.visitNode(arg) + ',';
}
str = str.slice(0, -1);
str += ');';
return str + '\n';
}
}
只需要将它的callee以及参数arguments处理好用小括号()拼接起来即可。
实现visitReturnStatement方法
ReturnStatement即返回语法,比如return a + b这种,它的ast如下:
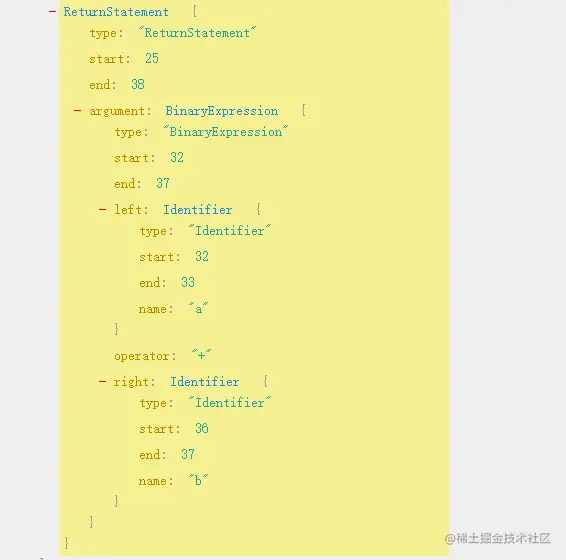
它的实现也比较简单,直接拼接node.argument就好啦:
class Generator {
visitReturnStatement(node) {
let str = '';
str = str + ' return ' + this.visitNode(node.argument);
return str + '\n';
}
}
实现visitExpressionStatement方法
ExpressionStatement即表达式语句,它的特点是执行完之后有返回值,比如add(firstNum, secondNum);,它是在CallExpression外面包裹了一层ExpressionStatement,执行完之后返回函数的调用结果,其ast如下:

所以实现也比较简单,我们只需要处理它的expression返回就好了。
class Generator {
return this.visitNode(node.expression);
}
这样,我们就完整实现Generator了,接下来就可以开始遍历ast了。
// tree-shaking.js
const acorn = require('acorn');
const fs = require('fs');
const path = require('path');
const buffer = fs.readFileSync(path.resolve(process.cwd(), './src/index.js')).toString();
const body = acorn.parse(buffer, {
ecmaVersion: 'latest',
}).body;
// 引用一个 Generator 类,用来生成 ast 对应的代码
const Generator = require('./generator');
// 创建 Generator 实例
const gen = new Generator();
// 定义变量decls 存储所有的函数或变量类型节点 Map类型
const decls = new Map();
// 定义变量calledDecls 存储被用到过的函数或变量类型节点 数组类型
const calledDecls = [];
// 开始遍历 ast
body.forEach(node => {
if (node.type === 'FunctionDeclaration') {
const code = gen.run([node]);
decls.set(gen.visitNode(node.id), code);
return;
}
if (node.type === 'VariableDeclaration') {
for (const decl of node.declarations) {
decls.set(gen.visitNode(decl.id), gen.visitVariableDeclarator(decl, node.kind));
}
return;
}
if (node.type === 'ExpressionStatement') {
if (node.expression.type === 'CallExpression') {
const callNode = node.expression;
calledDecls.push(gen.visitIdentifier(callNode.callee));
for (const arg of callNode.arguments) {
if (arg.type === 'Identifier') {
calledDecls.push(arg.name);
}
}
}
}
if (node.type === 'Identifier') {
calledDecls.push(node.name);
}
})
console.log('decls', decls);
console.log('calledDecls', decls);
使用node tree-shaking.js运行一下,结果如下:

很明显,我们decls总共有四个节点函数或变量类型节点,而被调用的calledDecls只有三个,很明显multiple函数没被调用,可以被tree-shaking掉,拿到这些信息之后,接下来我们开始生成tree-shaking后的代码。
第三步:根据第二步得到的信息,生成新代码
// ...省略
code = calledDecls.map(c => decls.get(c)).join('');
console.log(code);
我们直接遍历calledDecls生成新的源代码,打印结果如下:


咦!跟我们最开始的文件内容一比,发现multiple虽然被移除掉了,但我们的函数调用语句add(firstNum, secondNum);却丢了,那我们简单处理下。
我们声明一个code数组:
// ...省略
const calledDecls = [];
// 保存代码信息
const code = [];
// 省略
然后把不是FunctionDeclaration和VariableDeclaration的信息都存储一下:
// tree-shaking.js
body.forEach(node => {
if (node.type === 'FunctionDeclaration') {
const code = gen.run([node]);
decls.set(gen.visitNode(node.id), code);
return;
}
if (node.type === 'VariableDeclaration') {
for (const decl of node.declarations) {
decls.set(gen.visitNode(decl.id), gen.visitVariableDeclarator(decl, node.kind));
}
return;
}
if (node.type === 'ExpressionStatement') {
if (node.expression.type === 'CallExpression') {
const callNode = node.expression;
calledDecls.push(gen.visitIdentifier(callNode.callee));
for (const arg of callNode.arguments) {
if (arg.type === 'Identifier') {
calledDecls.push(arg.name);
}
}
}
}
if (node.type === 'Identifier') {
calledDecls.push(node.name);
}
// 存储代码信息
code.push(gen.run([node]));
})
最后输出的时候,把code里面的信息也带上:
// tree-shaking.js
code = calledDecls.map(c => decls.get(c)).concat(code).join('');
console.log(code);
然后运行一下,打印结果如下:

这样我们一个简易版本的tree-shaking就完成了,当然,webpack的tree-shaking的能力远比这个强大的多,我们只是写了个最简单版本,实际项目要比这复杂得多:
- 处理文件依赖
import/export - 作用域
scope的处理 递归tree-shaking,因为可能去除了某些代码后,又会产生新的未被引用的代码,所以需要递归处理- 等等…
小结
本文通过ast的语法分析能力,分析JavaScript代码中未被引用的函数或变量,进而实现了一个最简单版本的tree-shaking,希望大家看完都能有所收获哦~



![[Android]模拟器登录Google Play失败](https://img-blog.csdnimg.cn/direct/d0ca9bc9e9f44dccbccbd31f9d2bd17e.png)