最近在搞AI. 遇到了一个问题,就是要进行doc文档的解析。并且需要展示每个文档的总页数。
利用AI. 分别尝试了chatGPT, 文心一言, github copilot,Kimi 等工具,给出来的答案都不尽如人意。
给的最多的查询方式就是下面这种。
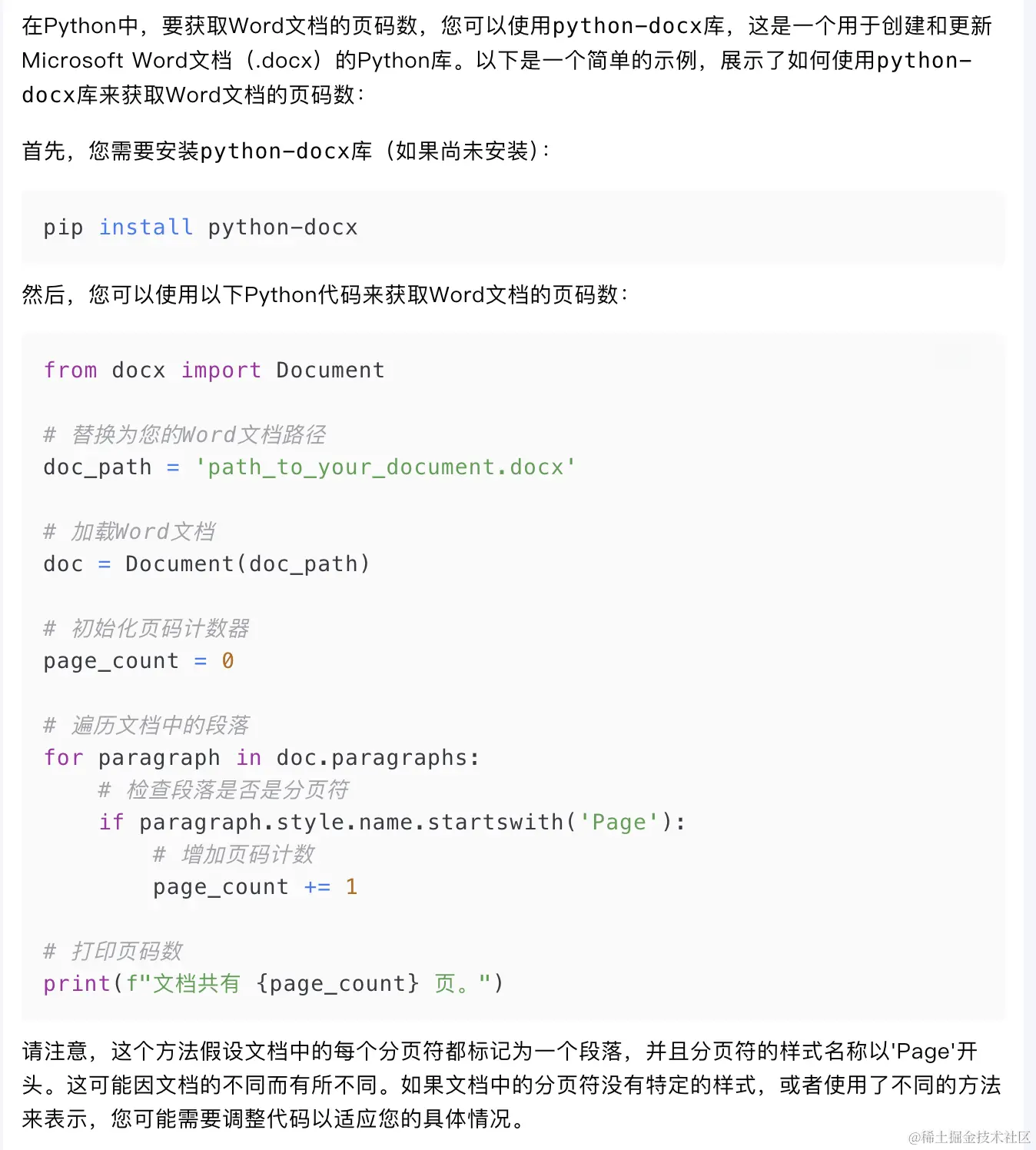
这个给大家避雷一下。使用python-docx的方式,是没有办法获取文档总页数的。 如果想获取,也只能是获取一个近似值,大体就是根据每个页面平均有多少个段落,或者平均有多少行的方式,近似的得到一个结果。完全是不准确的。
那么如果想要获取总页数,应该怎么办呢? 经过一番调研这里给出两种解决方案,两种方案也都各有优缺点。可能也不一定是完全准确的,但是相比于上面的方式还是要好出很多。
一、 使用langchain
langchain是什么,这里就不详细介绍了,是AI领域当前非常流行的一套框架。 langchain中提供了很多开箱即用的功能,比如文档解析、文档拆分, 向量比较、摘要提取等。 在文档解析中,就有对于word文档解析的方法,这在个方法中,我们可以间接获取文档页数。
地址: www.langchain.com.cn/modules/ind…
方法:
word_path = '/xxx/xxx.docx'
loader = UnstructuredWordDocumentLoader(word_path, mode="paged")
docs = loader.load_and_split(texts_splitter)
for doc in docs:
print(doc)这里的mode可以选择paged,也可以使用elements 一个是按照页进行分割,一个是按照元素做分割。那么怎么获取页数呢,在返回的元素中,就可以找到page_number这样一个字段。

所以无论我们使用paged还是使用elements,都可以从返回结果(集合)中通过获取page_number的最大值,来得到该文档的总页数。
局限性: 这种方法也不是没有任何缺点,但是整理来说还是相对准确的。确定就是有的时候,文档明明是三页。但是解析出来的结果可能是两页。 我出现过一次,主要是我自己做了测试,第二页空白比较多的时候,又添加了第三页。这个时候,第三页的内容出现在第二页的解析结果中了。 导致最终识别的结果为2.
2. 没啥好办法,word2pdf
的确,没啥好的办法了,只能先把word转换为pdf, 然后获取pdf的页数。 pdf的页数获取还是很简单的,很多pdf相关工具,都有这个功能,也就一行代码的事。给一个例子吧:
from fitz import fitz
doc = fitz.open(pdf_path)
print(doc.page_count)
问题主要在于word如何转为pdf, 我这里使用的是libreOffice. 不同的平台有不同平台的安装包。 具体的使用,这里就不详细介绍了。
局限性 主要局限性就是平台限制, 比如我们的文档通常是在windows上, 而部署平台一般是在linux上,相当于libreOffice要装在linux上,这个时候,由于平台不同,转换出来的pdf页数可能也会有一些差距,都一页少一页这类的。 有没有好的方案呢。 两种,一种是用windows系统做部署服务器。 一种是使用wps+docker desktop的方式。
两种方式,都有点小缺陷, 但是误差不大,可接受的就用这两种方法把,接受不了的,可以按照给的思路,自己去折腾折腾。
好了,感谢关注,谢谢支持。