数据集heart_learning.csv与heart_test.csv是关于心脏病的数据集,heart_learning.csv是训练数据集,heart_test.csv是测试数据集。要求:target和target2为因变量,其他诸变量为自变量,用神经网络模型(多层感知器)对target和target2做预测,并与实际值比较来验证预测情况。变量说明:pain,ekg,slope,thal是分类变量,在做模型训练前需要对其进行转换为因子型变量。target是定类多值因变量,target2是二值变量,文中分别对其进行预测。
| 变量名称 | 变量说明 |
| age | 年龄 |
| sex | 性别,取值1代表男性,0代表女性 |
| pain | 胸痛的类型,取值1,2,3,4,代表4种类型 |
| bpress | 入院时的静息血压(单位:毫米汞柱) |
| chol | 血清胆固醇(单位:毫克/分升) |
| bsugar | 空腹血糖是否大于120毫克/公升,1代表是,0代表否 |
| ekg | 静息心电图结果,取值0,1,2代表3中不同的结果 |
| thalach | 达到的最大心率 |
| exang | 是否有运动性心绞痛,1代表是0代表否 |
| oldpeak | 运动引起的ST段压低 |
| slope | 锻炼高峰期ST段的斜率,取值1代表上斜,2代表平坦,3代表下斜 |
| ca | 荧光染色的大血管数目,取值为0,1,2,3 |
| thal | 取值3代表正常,取值6代表固定缺陷,取值7代表可逆缺陷 |
| target | 因变量,直径减少50%以上的大血管数目,取值0,1,2,3,4 |
| target2 | 因变量,取值1表示target大于0,取值0表示target等于0 |
根据神经网络模型,本文模型设置3层神经网络隐藏层,每个隐藏层分别有2,4,6,8,10个隐藏单元数,使用两组模型,第一组是不使用权衰减,第二组是使用权衰减。文中分两大部分,一是对target2进行预测模型验证和对target进行预测和模型验证。因变量target2取值为0和1,target取值取值0,1,2,3,4。
二、对二元因变量target2进行预测和模型验证
1、数据导入与清理
导入分析包:
library(RSNNS)
library(dplyr)
library(sampling)
library(caret)
set.seed(123456)
导入heart_learning数据集,并将分类变量pain,ekg,slope,thal转换为因子变量
heart_learning<-read.csv('f:/桌面/heart_learning.csv',colClasses = rep('numeric',15))%>%
mutate(pain=as.factor(pain)) %>% mutate(ekg=as.factor(ekg)) %>% mutate(slope=as.factor(slope)) %>% mutate(thal=as.factor(thal))
导入heart_test数据集,并将分类变量pain,ekg,slope,thal转换为因子变量
heart_test<-read.csv('f:/桌面/heart_test.csv',colClasses = rep('numeric',15)) %>%
mutate(pain=as.factor(pain)) %>% mutate(ekg=as.factor(ekg)) %>% mutate(slope=as.factor(slope)) %>% mutate(thal=as.factor(thal))
查看数据集heart_learning和heart_test的变量类型
str(heart_learning)
str(heart_test)
将数据集heart_learning按因变量target的取值排序后,再按取值分层抽样,抽样的结果保存在变量
train_sample中,每次抽取70%的数据。
heart_learning<-heart_learning[order(heart_learning$target),]
train_sample<-strata(heart_learning,stratanames = ('target'),size = round(0.7*table(heart_learning$target)),method = 'srswor')
将因子变量转换为哑变量,并拟合到heart_learning数据集中,并去掉多余变量。
dmy<-dummyVars(~pain+ekg+slope+thal,heart_learning,fullRank = TRUE)
heart_learning<-cbind(heart_learning,predict(dmy,heart_learning)) %>% select(-c(pain,ekg,slope,thal)) %>% select(-c(target,target2),everything())
head(heart_learning)

查看数据集heart_learning,加入到哑变量后模型去掉两个因变量target和target2后,共有18个自变量。
对自变量数据进行标准化
center<-apply(heart_learning[,1:18],2,mean)
scale<-apply(heart_learning[,1:18],2,sd)
heart_learning[,1:18]<-scale(heart_learning[,1:18],center=center,scale=scale)
取出抽样后的数据,并保存在变量heart_train中
heart_train<-heart_learning[train_sample$ID_unit,]
未抽取的数据保存在heart_valid,用以选出分类准确率最高的模型。
heart_valid<-heart_learning[-train_sample$ID_unit,]
2、模型训练,数据拟合,选出用于数据预测和验证的具体模型
设置初始数据框,将模型结果保存在该变量中,初始为250*5的数据框,每列的列名为
'size1','size2','size3','cdecay','accuclass',分别代表:第一隐藏层的单元数,第二隐藏层的单元数,第三隐藏层的单元数,前面三列分别取值为2,4,6,8,10,第四列cdecay为权衰减常数,取值为0或0.005,第五列accuclass为模型分类的准确率,而分类准确率由下面的表达式定义,(length(which(class1==heart_valid$target2)))/length(heart_valid$target2)。target2取两个值0和1,prob得到预测取值为1类型的概率,表达式class<-1*(prob>0.5)得到如果概率大于0.5即认为该类别的就是1类别。
mlp()用于建立多层感知器模型,分别用到了两组模型不用权衰减和使用权衰减,下面是主程序。
result.target2<-as.data.frame(matrix(0,nrow=5*5*5,ncol=5))
colnames(result.target2)<-c('size1','size2','size3','cdecay','accuclass')
index<-0
mlp_models<-list()
for(size1 in seq(2,10,2))
for(size2 in seq(2,10,2))
for(size3 in seq(2,10,2)){
print(paste0('size1=',size1,'size2=',size2,'size3=',size3))
mlp_model_nodecay<-mlp(heart_train[,1:18],heart_train$target2,
size=c(size1,size2,size3),
inputsTest = heart_valid[,1:18],
targetsTest = heart_valid$target2,
maxit = 300,
learnFuncParams = c(0.1))
mlp_model_decay<-mlp(heart_train[,1:18],heart_train$target2,
size=c(size1,size2,size3),
inputsTest = heart_valid[,1:18],
targetsTest = heart_valid$target2,
maxit = 300,
learnFunc='BackpropWeightDecay',
learnFuncParams = c(0.1,0.005))
prob1 <- mlp_model_nodecay$fittedTestValues
class1<-1*(prob1>0.5)
prob2 <- mlp_model_decay$fittedTestValues
class2<-1*(prob2>0.5)
mlp_models<-c(mlp_models,list(mlp_model_nodecay),list(mlp_model_decay))
index<-index+1
result.target2[index,1]<-size1
result.target2[index,2]<-size2
result.target2[index,3]<-size3
result.target2[index,4]<-0
result.target2[index,5]<-(length(which(class1==heart_valid$target2)))/length(heart_valid$target2)
index<-index+1
result.target2[index,1]<-size1
result.target2[index,2]<-size2
result.target2[index,3]<-size3
result.target2[index,4]<-0.005
result.target2[index,5]<-(length(which(class2==heart_valid$target2)))/length(heart_valid$target2)
}
上面函数分别用到了两组模型不用权衰减和使用权衰减,权衰减常数为0和0.005,index用于设置size1,size2,size3不同取值的编号,参数不同的取值代表不同的模型。函数运行将得到结果集result.target2。
head(result.target2)
运行得到:
head(result.target2) size1 size2 size3 cdecay accuclass 1 2 2 2 0.000 0.5483871 2 2 2 2 0.005 0.5483871 3 2 2 4 0.000 0.8064516 4 2 2 4 0.005 0.5483871 5 2 2 6 0.000 0.5483871 6 2 2 6 0.005 0.5483871
从上面得到的结果集result.target2第五列选取出分类准确率最高的模型对应的参数。
which.max(result.target2[,5])
[1] 57
分类准确率最高的参数为由第57行显示。
result.target2[which.max(result.target2[,5])]
运行将得到模型的参数为size1=4,size2=2,size3=4,不使用权衰减,分类准确率最高为0.8387.
result.target2[which.max(result.target2[,5]),] size1 size2 size3 cdecay accuclass 57 4 2 8 0 0.8387097
取出该参数对于的模型:因为列表结构和result.target2数据框的行是一一对应的。
mlp_model<-mlp_models[[which.max(result.target2[,5])]]
mlp_model
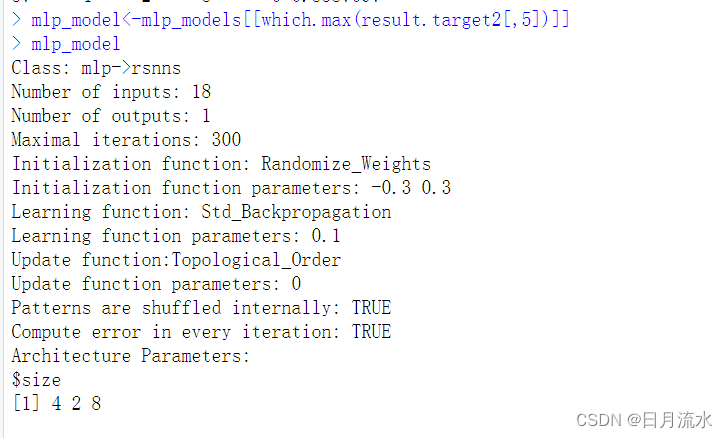
上图为该模型的细节。
3、将上面得到的准确率最高的感知器模型用于测试数据集的预测和验证。
将测试数据集heart_test进行上面步骤的数据清理和标准化
heart_test<-cbind(heart_test,predict(dmy,heart_test)) %>% select(-c(pain,ekg,slope,thal)) %>%
select(-c(target,target2),everything())
heart_test[,1:18]<-scale(heart_test[,1:18],center=center,scale=scale)
将上面得到的最佳模型mlp_model进行测试数据集的预测,预测的结果为响应概率
prob_test<-predict(mlp_model,heart_test[,1:18],type='response')
对概率预测的结果得到了分类预测的结果class.test,即为感知器模型得到最终预测结果。
class.test<-1*(prob_test>0.5)
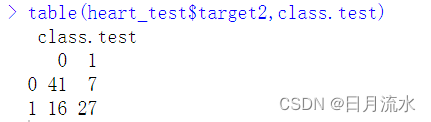
查看模型结果预测值和真实的列联表
table(heart_test$target2,class.test)
运行得到:
三、对多值分类变量target进行预测和模型验证
因为因变量target是分类多值因变量,在模型训练之前需要对因变量进行转换,
y_train<-decodeClassLabels(heart_train$target)
y_valid<-decodeClassLabels(heart_valid$target)
另外需要注意的是预测类别在多值分类变量的情况下应为:
class.test<-apply(prob.test,1,which.max)-1在二值因变量情况下为class.test<-1*(prob_test>0.5),
其他预测这两种因变量的步骤和程序相似,不再这里详细讲述。
下面是程序:
index<-0
y_train<-decodeClassLabels(heart_train$target)
y_valid<-decodeClassLabels(heart_valid$target)
result.target<-as.data.frame(matrix(0,nrow=5*5*5,ncol=5))
colnames(result.target)<-c('size1','size2','size3','cdecay','accuclass')
mlp.models<-list()
for(size1 in seq(2,10,2))
for(size2 in seq(2,10,2))
for(size3 in seq(2,10,2)){
print(paste0('size1=',size1,'size2=',size2,'size3=',size3))
mlp.model.nodecay<-mlp(heart_train[,1:18],y_train,
size=c(size1,size2,size3),
inputsTest = heart_valid[,1:18],
targetsTest = y_valid,
maxit = 300,
learnFuncParams = c(0.1))
mlp.model.decay<-mlp(heart_train[,1:18],y_train,
size=c(size1,size2,size3),
inputsTest = heart_valid[,1:18],
targetsTest = y_valid,
maxit = 300,
learnFunc='BackpropWeightDecay',
learnFuncParams = c(0.1,0.005))
prob3<-mlp.model.nodecay$fittedTestValues
class3<-apply(prob3,1,which.max)-1
prob4<-mlp.model.nodecay$fittedTestValues
class4<-apply(prob4,1,which.max)-1
mlp.models<-c(mlp.models,list(mlp.model.nodecay),list(mlp.model.decay))
index<-index+1
result.target[index,1]<-size1
result.target[index,2]<-size2
result.target[index,3]<-size3
result.target[index,4]<-0
result.target[index,5]<-(length(which(class3 == heart_valid$target)))/length(heart_valid$target)
index<-index+1
result.target[index,1]<-size1
result.target[index,2]<-size2
result.target[index,3]<-size3
result.target[index,4]<-0.005
result.target[index,5]<-(length(which(class4 == heart_valid$target)))/length(heart_valid$target)
}
mlp.model<-mlp.models[[which.max(result.target[,5])]]
prob.test <- predict(mlp.model,heart_test[,1:18],type='response')
class.test<-apply(prob.test,1,which.max)-1
table(heart_test$target,class.tset)
运行将得到:预测概率prob.test,预测分类结果class.test,真实值和预测值的列联表。
table(heart_test$target,class.tset)
运行得到:模型的预测值与真实值的列联表
table(heart_test$target,class.test)
class.test
0 1 3
0 42 6 0
1 11 4 2
2 5 4 2
3 2 5 4
4 2 1 1
![PC电脑技巧[笔记本通过网线访问设备CMW500]](https://img-blog.csdnimg.cn/direct/733dfa3867064b95aa55cf93653508bc.png)