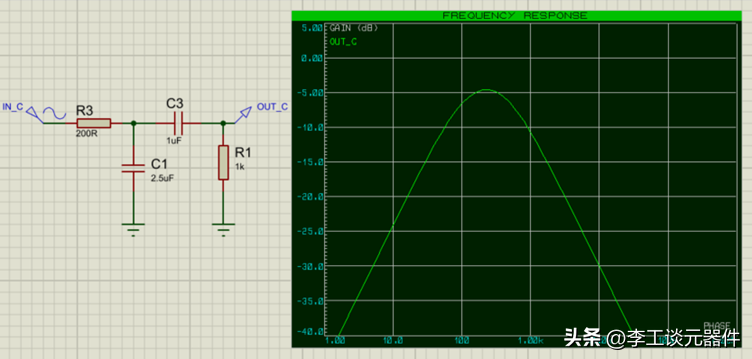
在上篇文章中,我们对照手动编写jdbc的开发流程,对MyBatis进行了梳理。通过这次梳理我们发现了一些之前文章中从未见过的新知识,譬如BoundSql等。本节我想继续MyBatis这个主题,并探索一下MyBatis中的缓存机制。在正式开始梳理前,个人觉得弄清楚缓存是什么,为什么要有缓存是很重要的。那何为缓存?相信配置过计算机的诸位都知道,CPU中有一个名为缓存的部件,它的作用就是缓解高速运转CPU和低速运转磁盘之间数据处理速度不协调的问题。由此,我们可以给缓存一个这样的定义:所谓缓存就是具有缓冲作用的事物,这里的缓冲,即缓解,也就是让矛盾双方之间的矛盾弱化,甚至消失。譬如:在政治和军事上起到缓冲作用的朝鲜和韩国,在现代汽车中起到缓冲作用的安全气囊,在计算机上起到缓冲作用的内存以及CPS一二级缓存等等。如果这个定义可用,那为什么要用缓存这个问题就迎刃而解了:为了缓解矛盾双方的矛盾。按照这个思路去理解MyBatis中的缓存或许就不是什么难事了。
1 MyBatis缓存
在java知识体系中,MyBatis是一个非常常见的数据库访问组件,其可以帮开发者减少开发jdbc代码的烦恼,同时提供一些高效率的数据转换组件以减少开发者编写数据转换代码的痛苦。不过MyBatis不仅仅有这些好处,它还提供了更多实用的功能,譬如本篇文章要梳理的缓存。在MyBatis中引入缓存的主要目的就是缓解矛盾双方之间的矛盾,这里矛盾的双方,从微观角度看是程序和数据库,从宏观角度看是用户和互联网企业。如果刨除其他噪音,我们会发现用户和互联网企业之间的矛盾是程序和数据库之间的矛盾的延申,因为互联网公司是通过对外提供的APP或应用来为用户服务的,说白了用户购买的是互联网公司的服务。如果用户体验不好,那互联网公司就无法长久立足市场!不会吧,一个MyBatis缓存就能引发这么大的变故?这个暂且不说,根据上面的逻辑,MyBatis缓存是为了减少数据库压力,提高数据库性能而出现的。那MyBatis是如何实现这个缓存功能的呢?网络有位大神是这么讲的(原文:MyBatis缓存看这一篇就够了(一级缓存+二级缓存+缓存失效+缓存配置+工作模式+测试)):MyBatis缓存的原理是这样的,数据从数据库中查出来以后,被包装为相应对象,这个对象在使用完后不会被立即销毁,而是储存在MyBatis提供的一个缓冲区中,当再次使用时,直接从缓冲区把这个数据拿出来即可。这样直接从内存中获取数据,从而不再向数据库发送select执行命令的过程,可以减少数据库查询次数,从而提高了数据库的性能。在MyBatis中这个缓冲区(又可以被称为缓存)是通过Map集合实现的。
在MyBatis中,缓存可以分为两类:一级缓存和二级缓存。其中一级缓存的作用域是同一个SqlSession,在同一个SqlSession中两次执行相同的sql语句,第一次执行完毕会将数据库查询的数据写到缓存(内存),第二次会从缓存中获取数据而不进行数据库查询,可以大大提高了数据查询效率。当一个SqlSession结束后该SqlSession中的一级缓存也就不复存在了。MyBtais默认是启动一级缓存的。二级缓存是多个SqlSession共享的,其作用域是mapper的同一个namespace,不同的sqlSession两次执行相同namespace下的sql语句且向sql中传递的参数也相同时,第一次执行完毕会将数据库中查询到的数据写到缓存(内存),第二次会直接从缓存中获取,从而提高了查询效率。MyBatis默认不开启二级缓存,需要在MyBtais全局配置文件中进行setting配置开启二级缓存。
2 MyBatis一级缓存
通过第一小节的概念性描述我们认识了MyBatis中的缓存,知道了在MyBatis中存在两种类别的缓存:一级缓存(一级缓存的生命周期和SqlSession是一个级别)和二级缓存(二级缓存的生命周期和Mapper是一个级别)。其中一级缓存默认是开启的(在MyBatis的配置文件中也可以添加一级缓存开启的配置,具体代码为:<setting name="localCacheScope" value="SESSION"/>),二级缓存需要配置才能开启(具体代码为:<setting name="cacheEnabled" value="true"/>)。通过代码跟踪我们也发现当同时执行两条相同的sql语句时,在第二次执行时,MyBatis会直接从缓存中提取数据。那MyBatis究竟是怎么实现一级缓存的呢?先看一下本节案例执行入口的代码,如下图所示:

其实这段代码和《MyBatis是纸老虎吗?(一)》这篇文章中的案例二基本类似,只不过最后两行代码不太一样。接下来开始执行这个案例,首先程序会在图中第一个断点处停下,之后进入DefaultSqlSession.selectList()方法即可。然后继续,进入DefaultSqlSession中接收四个参数的selectList()方法中,其参数为:String、Object、 RowBounds、ResultHandler。该方法的源码如下所示:
private <E> List<E> selectList(String statement, Object parameter, RowBounds rowBounds, ResultHandler handler) {
try {
MappedStatement ms = configuration.getMappedStatement(statement);
dirty |= ms.isDirtySelect();
return executor.query(ms, wrapCollection(parameter), rowBounds, handler);
} catch (Exception e) {
throw ExceptionFactory.wrapException("Error querying database. Cause: " + e, e);
} finally {
ErrorContext.instance().reset();
}
}
这段代码很简单,唯一需要关注的就是Executor.query()这行代码。由于跟踪时,executor的实际类型为CachingExecutor,所以下面要看的方法是CachingExecutor中的query()方法,这段代码的运行时状态,如下图所示:
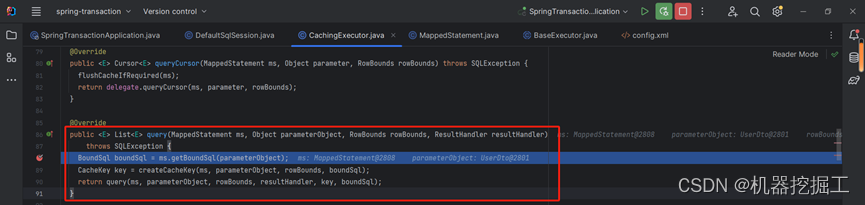
这段逻辑中,我们重点看createCacheKey()这行代码,从调用不难发现,这个被调用的方法位于CachingExecutor类中,源码为:
public CacheKey createCacheKey(MappedStatement ms, Object parameterObject, RowBounds rowBounds, BoundSql boundSql) {
return delegate.createCacheKey(ms, parameterObject, rowBounds, boundSql);
}
由于目前正在被使用的CachingExecutor对象所持有的delegate属性的实际类型为SimpleExecutor,而这个类又继承了BaseExecutor(注意这个类又实现了Executor接口)抽象类。由于SimpleExecutor类中只有doUpdate()、doQuery()、doQueryCursor()、doFlushStatements()及prepareStatement()这几个方法,所以上述源码中的createCacheKey()方法位于BaseExecutor类中,这个方法的源码如下所示:
public CacheKey createCacheKey(MappedStatement ms, Object parameterObject, RowBounds rowBounds, BoundSql boundSql) {
if (closed) {
throw new ExecutorException("Executor was closed.");
}
CacheKey cacheKey = new CacheKey();
cacheKey.update(ms.getId());
cacheKey.update(rowBounds.getOffset());
cacheKey.update(rowBounds.getLimit());
cacheKey.update(boundSql.getSql());
List<ParameterMapping> parameterMappings = boundSql.getParameterMappings();
TypeHandlerRegistry typeHandlerRegistry = ms.getConfiguration().getTypeHandlerRegistry();
// mimic DefaultParameterHandler logic
MetaObject metaObject = null;
for (ParameterMapping parameterMapping : parameterMappings) {
if (parameterMapping.getMode() != ParameterMode.OUT) {
Object value;
String propertyName = parameterMapping.getProperty();
if (boundSql.hasAdditionalParameter(propertyName)) {
value = boundSql.getAdditionalParameter(propertyName);
} else if (parameterObject == null) {
value = null;
} else if (typeHandlerRegistry.hasTypeHandler(parameterObject.getClass())) {
value = parameterObject;
} else {
if (metaObject == null) {
metaObject = configuration.newMetaObject(parameterObject);
}
value = metaObject.getValue(propertyName);
}
cacheKey.update(value);
}
}
if (configuration.getEnvironment() != null) {
// issue #176
cacheKey.update(configuration.getEnvironment().getId());
}
return cacheKey;
}
这段代码的处理逻辑非常清晰,判断当前对象上的close属性是否为true,如果是就抛出异常,否则就创建CacheKey对象,并调用该对象上的update()方法。为了更加深入的了解这段代码的处理逻辑,我们来看一下CacheKey类的源码,如下所示:
public class CacheKey implements Cloneable, Serializable {
private static final long serialVersionUID = 1146682552656046210L;
public static final CacheKey NULL_CACHE_KEY = new CacheKey() {
private static final long serialVersionUID = 1L;
@Override
public void update(Object object) {
throw new CacheException("Not allowed to update a null cache key instance.");
}
@Override
public void updateAll(Object[] objects) {
throw new CacheException("Not allowed to update a null cache key instance.");
}
};
private static final int DEFAULT_MULTIPLIER = 37;
private static final int DEFAULT_HASHCODE = 17;
private final int multiplier;
private int hashcode;
private long checksum;
private int count;
// 8/21/2017 - Sonarlint flags this as needing to be marked transient. While true if content is not serializable, this
// is not always true and thus should not be marked transient.
private List<Object> updateList;
public CacheKey() {
this.hashcode = DEFAULT_HASHCODE;
this.multiplier = DEFAULT_MULTIPLIER;
this.count = 0;
this.updateList = new ArrayList<>();
}
public CacheKey(Object[] objects) {
this();
updateAll(objects);
}
public int getUpdateCount() {
return updateList.size();
}
public void update(Object object) {
int baseHashCode = object == null ? 1 : ArrayUtil.hashCode(object);
count++;
checksum += baseHashCode;
baseHashCode *= count;
hashcode = multiplier * hashcode + baseHashCode;
updateList.add(object);
}
public void updateAll(Object[] objects) {
for (Object o : objects) {
update(o);
}
}
@Override
public boolean equals(Object object) {
if (this == object) {
return true;
}
if (!(object instanceof CacheKey)) {
return false;
}
final CacheKey cacheKey = (CacheKey) object;
if ((hashcode != cacheKey.hashcode) || (checksum != cacheKey.checksum) || (count != cacheKey.count)) {
return false;
}
for (int i = 0; i < updateList.size(); i++) {
Object thisObject = updateList.get(i);
Object thatObject = cacheKey.updateList.get(i);
if (!ArrayUtil.equals(thisObject, thatObject)) {
return false;
}
}
return true;
}
@Override
public int hashCode() {
return hashcode;
}
@Override
public String toString() {
StringJoiner returnValue = new StringJoiner(":");
returnValue.add(String.valueOf(hashcode));
returnValue.add(String.valueOf(checksum));
updateList.stream().map(ArrayUtil::toString).forEach(returnValue::add);
return returnValue.toString();
}
@Override
public CacheKey clone() throws CloneNotSupportedException {
CacheKey clonedCacheKey = (CacheKey) super.clone();
clonedCacheKey.updateList = new ArrayList<>(updateList);
return clonedCacheKey;
}
}
从源码可以看出这个类非常简单,拥有五个属性,它们分别为:int类型的multiplier,int类型的hashcode,long类型的checksum,int类型的count以及List<Object>类型的updateList。这个类拥有两个构造方法,一个无参构造方法,一个接收Object[]数组的有参构造方法。其中无参构造方法主要是给这个类的其中四个属性赋值,它们分别是:updateList(默认数据是空的ArrayList对象)、hashcode(默认值是17)、multiplier(默认值是37)、count(默认值是0)。有参构造方法会首先调用无参构造方法,然后再调用updatAll()方法。这个updateAll()方法的处理逻辑非常简单,就是遍历数据,然后分别调用update()方法。这个update()方法的处理逻辑很简单,就是计算传递进来的Object对象的hash值,然后做一些列运算,得出一个数据赋值给CacheKey的hashcode属性,最后传进本方法的object数据存到updateList数组对象中。这个类还有一个getUpdateCount(),其作用就是返回updateList数组中的数据量。还有这个类重写了Object类中的equals()方法和toString()方法,我们知道equals()方法是两个对象比较时常用的方法,所以重写这个方法的目的是重写这两个对象的比对逻辑,而重写toString()方法是为了以约定的方式向调用者展示自身数据。由于这个类实现了Cloneable接口,所以这个类又重写了Cloneable中的clone()方法。总体来说,CacheKey类是MyBatis框架提供的一个缓存key,目的是在我们缓存sql查询结果时使用。现在再回到BaseExecutor类的createCacheKey()方法中,此时再看这一系列的cacheKey.update()方法,我们似乎不再那么茫然了,这一系列操作的目的不过就是让CacheKey的hashcode值唯一。参与hashcode值计算的数据有:sql语句的id值、查询语句的分页偏移量、查询语句的分页条数、BoundSql中的sql属性、parameterMapping(如果有的话)、environmentId(如果有的话)等。待CacheKey创建完成后,持续向上返回,直到返回到CachingExecutor中的query()方法为止。此时可以看到该方法的最后一行代码,如下图所示:

可以发现这段代码调用了CachingExecutor类中接收六个参数的query()方法,这些参数分别为:MappedStatement、Object、RowBounds、ResultHandler、CacheKey、BoundSql,具体如下图所示:

这个方法在整个系列中被看了很多次,为了完整理解,这里再贴一下这个方法的源码,如下所示:
public <E> List<E> query(MappedStatement ms, Object parameterObject, RowBounds rowBounds, ResultHandler resultHandler,
CacheKey key, BoundSql boundSql) throws SQLException {
Cache cache = ms.getCache();
if (cache != null) {
flushCacheIfRequired(ms);
if (ms.isUseCache() && resultHandler == null) {
ensureNoOutParams(ms, boundSql);
@SuppressWarnings("unchecked")
List<E> list = (List<E>) tcm.getObject(cache, key);
if (list == null) {
list = delegate.query(ms, parameterObject, rowBounds, resultHandler, key, boundSql);
tcm.putObject(cache, key, list); // issue #578 and #116
}
return list;
}
}
return delegate.query(ms, parameterObject, rowBounds, resultHandler, key, boundSql);
}
从源码可以看出,这段代码会首先从MappedStatement中拿一下Cache,如果缓存不为空则走if分支,否则继续调用SimpleExecutor类中的query()方法。我们跟踪的案例没有走if分支,所以这里直接看SimpleExecutor中的query()方法(从BaseExecutor类继承来的方法)的执行状态如下图所示:
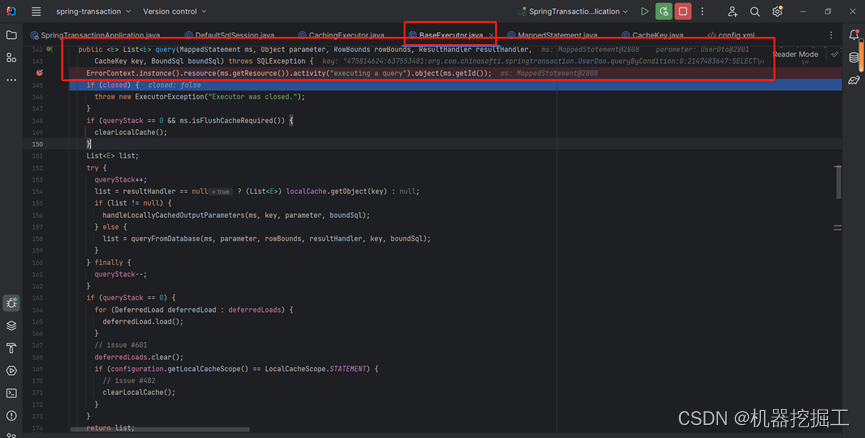
先看图中list = resultHandler == null ? (List<E>) localCache.getObject(key) : null这段代码,这里会先判断resultHandler是否null,如果时,则直接执行localCache.getObject(key)这段代码,否则直接返回null。由于调用该方法时传递进来的ResultHandler对象为null,所以这里直接执行localCache.getObject(key)方法,最终返回了null,即承载数据库查询结果的List<T>对象的结果为null,接下了会直接执行BaseExecutor类中的queryFromDatabase()方法,执行情况如下图所示:
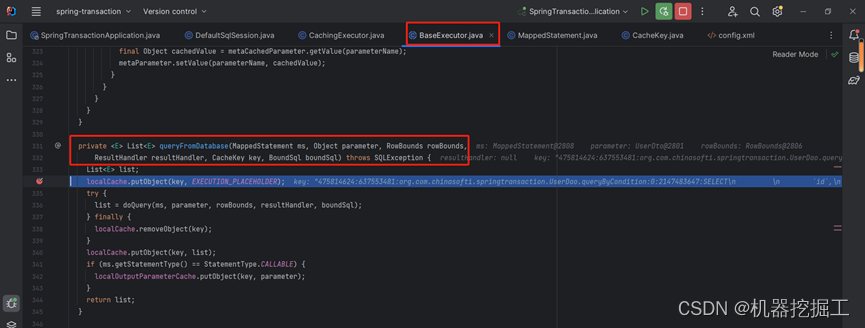
由图可以看出,这个方法首先会向localCache对象中放一个key(前面执行CachingExecutor中的query()方法时创建的CacheKey对象),其对应的数据为EXECUTION_PLACEHOLDER枚举。接下来该方法会直接调用BaseExecutor子类实现的doQuery()方法,这里的子类是SimpleExecutor类。紧接着finally块中会把localCache对象中的CacheKey移除。接着再向localCache对象中的存放CacheKey及其对应的数据doQuery()方法返回的结果。然后向上返回doQuery()方法的查询结果。直至最初调用者,即SpringTransactionApplication类的mybatis()方法中。
紧接着程序会继续调用同样的查询语句进行查询。下面用一章图片展示一下程序的运行时状态,具体如下图所示:

由于前面已经梳理过执行流程,所以这次会跳过非关键环节,直接看BaseExecutor类的query()方法的执行状态,如下图所示:
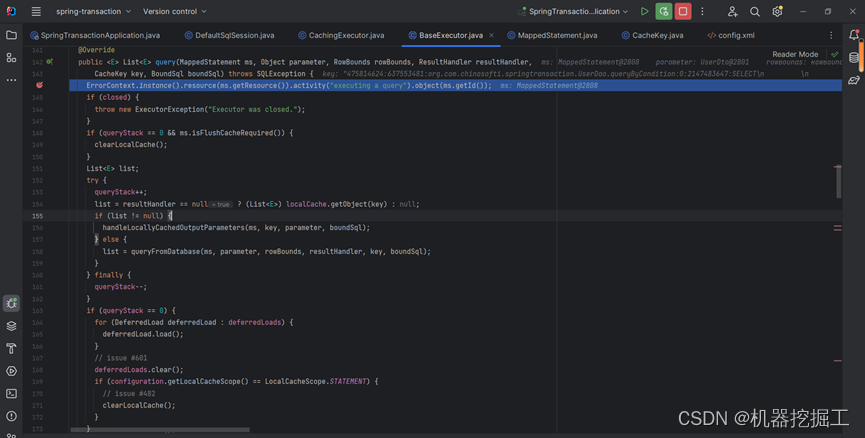
最终会执行list = resultHandler == null ? (List<E>) localCache.getObject(key) : null,跟前面执行逻辑一样。由于resultHandler是null,这里会直接执行localCache.getObject(key)这个逻辑,由于这里localCache中存在数据,具体如下图所示:
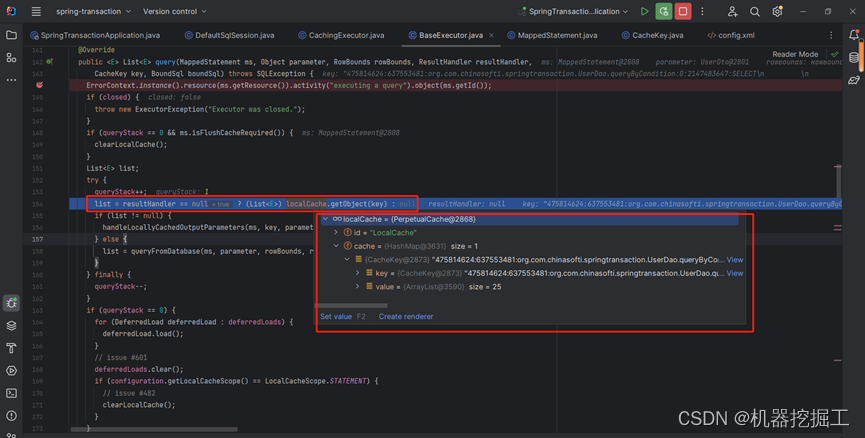
根据上面这张图片可以直到最终list对象不为空,会有二十五条数据,具体可以看下面这幅图片:
最终代码走到了handleLocallyCacheOutputParameters()方法中,这个方法位于BaseExecutor类中,这个方法的源码如下所示:
private void handleLocallyCachedOutputParameters(MappedStatement ms, CacheKey key, Object parameter,
BoundSql boundSql) {
if (ms.getStatementType() == StatementType.CALLABLE) {
final Object cachedParameter = localOutputParameterCache.getObject(key);
if (cachedParameter != null && parameter != null) {
final MetaObject metaCachedParameter = configuration.newMetaObject(cachedParameter);
final MetaObject metaParameter = configuration.newMetaObject(parameter);
for (ParameterMapping parameterMapping : boundSql.getParameterMappings()) {
if (parameterMapping.getMode() != ParameterMode.IN) {
final String parameterName = parameterMapping.getProperty();
final Object cachedValue = metaCachedParameter.getValue(parameterName);
metaParameter.setValue(parameterName, cachedValue);
}
}
}
}
}
通过上面的梳理,我们可以看到MyBatis的一级缓存对象在Executor的实现类BaseExecutor中,其名字为localCache,该变量的类型为:PerpetualCache,并且查询缓存的时间点就在将要去查询数据库的时候,从代码层面看,这个逻辑位于BaseExecutor类的queryFromDatabase()方法中。下面让我们一起看一下PerpetualCache的源码吧:
public class PerpetualCache implements Cache {
private final String id;
private final Map<Object, Object> cache = new HashMap<>();
public PerpetualCache(String id) {
this.id = id;
}
@Override
public String getId() {
return id;
}
@Override
public int getSize() {
return cache.size();
}
@Override
public void putObject(Object key, Object value) {
cache.put(key, value);
}
@Override
public Object getObject(Object key) {
return cache.get(key);
}
@Override
public Object removeObject(Object key) {
return cache.remove(key);
}
@Override
public void clear() {
cache.clear();
}
@Override
public boolean equals(Object o) {
if (getId() == null) {
throw new CacheException("Cache instances require an ID.");
}
if (this == o) {
return true;
}
if (!(o instanceof Cache)) {
return false;
}
Cache otherCache = (Cache) o;
return getId().equals(otherCache.getId());
}
@Override
public int hashCode() {
if (getId() == null) {
throw new CacheException("Cache instances require an ID.");
}
return getId().hashCode();
}
}
public interface Cache {
/**
* @return The identifier of this cache
*/
String getId();
/**
* @param key
* Can be any object but usually it is a {@link CacheKey}
* @param value
* The result of a select.
*/
void putObject(Object key, Object value);
/**
* @param key
* The key
*
* @return The object stored in the cache.
*/
Object getObject(Object key);
/**
* As of 3.3.0 this method is only called during a rollback for any previous value that was missing in the cache. This
* lets any blocking cache to release the lock that may have previously put on the key. A blocking cache puts a lock
* when a value is null and releases it when the value is back again. This way other threads will wait for the value
* to be available instead of hitting the database.
*
* @param key
* The key
*
* @return Not used
*/
Object removeObject(Object key);
/**
* Clears this cache instance.
*/
void clear();
/**
* Optional. This method is not called by the core.
*
* @return The number of elements stored in the cache (not its capacity).
*/
int getSize();
/**
* Optional. As of 3.2.6 this method is no longer called by the core.
* <p>
* Any locking needed by the cache must be provided internally by the cache provider.
*
* @return A ReadWriteLock
*/
default ReadWriteLock getReadWriteLock() {
return null;
}
}
从代码可以看出PerpetualCache类实现了Cache接口。Cache接口提供了一系列方法,这些方法有:
- String getId():获取当前Cache对象的id值
- void putObject(Object key, Object value) :向当前Cache对象中存放指定key,及其对应的数据
- Object getObject(Object key) :根据key,从当前Cache对象中提取数据
- Object removeObject(Object key) :从当前Cache对象中移除指定key的数据
- void clear():清空当前Cache对象中的数据
- int getSize():查询当前Cache对象中的数据总量
由于PerpetualCache实现了Cache接口,因此会对这些接口方法进行实现。同时因为PerpetualCache是通过Map<String, Object>类型的属性cache来缓存从数据库中查询出来的数据集合,所以这些实现方法的操作逻辑,本质上就是对Map的操作。梳理到这里我们还是一起回顾一下Executor的继承结构(注意Executor的实现类BaseExecutor中有一个PerpetualCache类型的localCache属性用于缓存数据),具体如下图所示:

3 MyBatis二级缓存
在前一小节开头我们提到了在MyBatis中启用二级缓存的方法。那这个二级缓存究竟是怎么实现的?下面就让我们一起看看吧!
未完待梳理,敬请谅解
4 总结
在总结前,我想对通过网络搜索到的两篇优质博文的创作者说声谢谢,这两篇博文分别是:《MyBatis缓存看这一篇就够了(一级缓存+二级缓存+缓存失效+缓存配置+工作模式+测试)》和《聊聊MyBatis缓存机制》。由于他们出色得整理,我仅用了半天时间就搞懂了MyBatis缓存。下面就本篇梳理的知识点做一下总结:
首先通过梳理,我对缓存有了更加深刻的认识,并且知道了MyBatis添加缓存功能的原因:缓解矛盾双方的对立。这里对立的双方从宏观角度讲是用户和公司,从微观角度看是程序和数据库。
接着通过梳理,我对MyBatis一级缓存有了更加深刻的了解,并且通过梳理我知道了MyBatis中启用一级缓存的方式,一级缓存的实现原理及一级缓存的工作流程。在MyBatis中一级缓存的生命周期和SqlSession一致;一级缓存内部设计简单,只是一个没有容量限定的HashMap,在缓存的功能性上有所欠缺;一级缓存最大范围是SqlSession内部,如果有多个SqlSession或者在分布式的环境下,数据库写操作会引起脏数据,建议设定缓存级别为Statement。