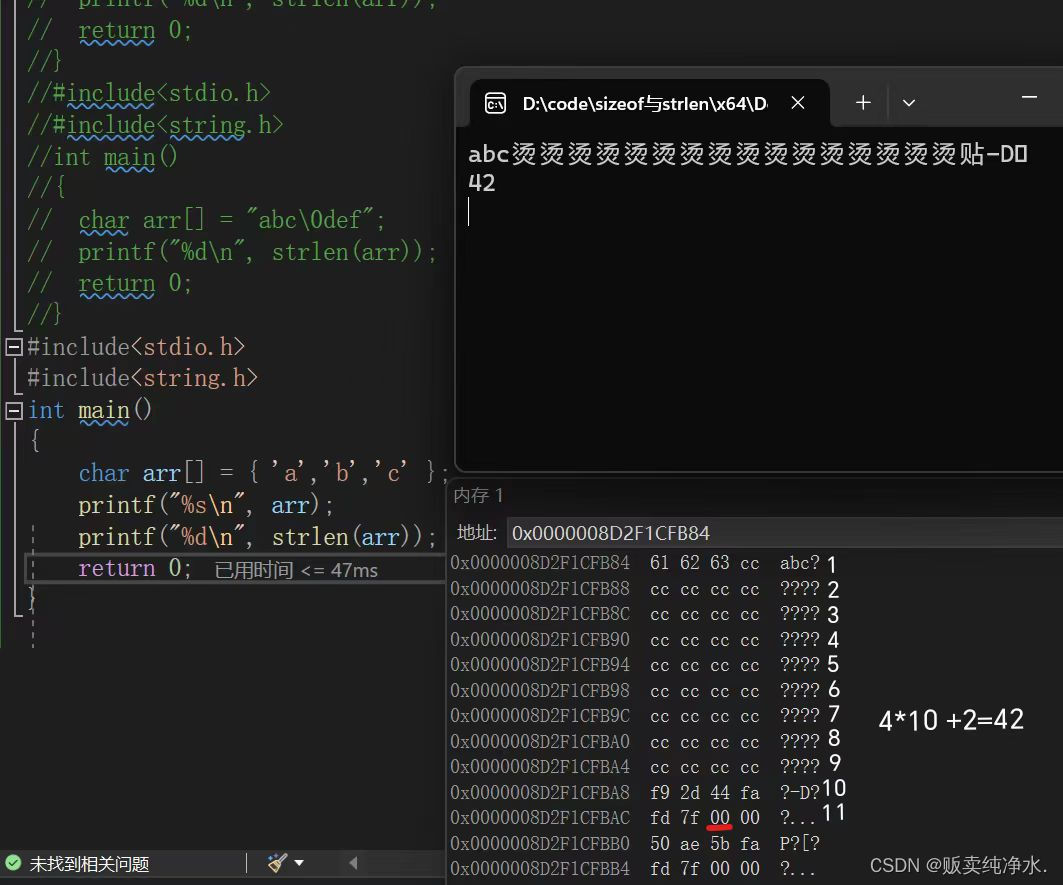
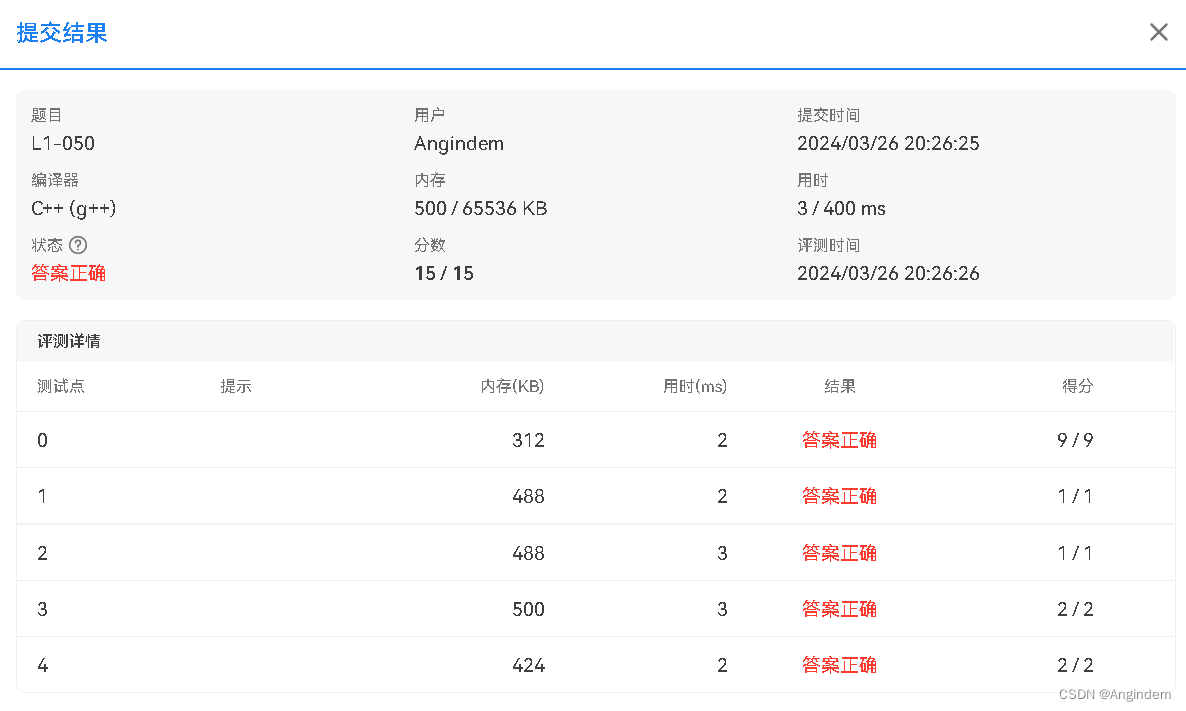
目前从事大数据相关的开发,都离不开SQL,不管是关系型数据库还是非关系型数据,在做不同数据库间迁移或者转换的时候都会用到SQL转换。今天来为大家分享一个有趣的开源项目,SQLGlot,一个纯Python开发的SQL转换器,目前GitHub上已经5.3k星了,感兴趣可以关注看看。

项目介绍
SQLGlot 是一个全面的 SQL 解析器、转译器、优化器和引擎,纯由Python开发。
该项目可以用于格式化 SQL 或在 DuckDB、Presto/Trino、Spark/Databricks、Snowflake 和 BigQuery 等 21 种不同的方言之间进行转换。其目标是读取多种 SQL 输入,并在目标方言中输出正确语法和语义上的 SQL。这是一个非常全面的通用 SQL 解析器,具有强大的测试套件。它还相当高效,并且纯粹使用 Python 编写。可以轻松定制解析器、分析查询、遍历表达式树,并以程序方式构建 SQL。语法错误会被突出显示,方言不兼容性则会根据配置发出警告或引发。然而,SQLGlot 并不旨在成为 SQL 验证器,因此可能无法检测到某些语法错误。
GitHub地址:GitHub - tobymao/sqlglot: Python SQL Parser and Transpiler
官方文档:sqlglot API documentation
使用安装
使用pip安装:
pip3 install "sqlglot[rs]"
# Without Rust tokenizer (slower):
# pip3 install sqlglot使用案例
格式转换
SQLGlot可以轻松从一种方言翻译成另一种方言。例如,日期/时间函数因方言而异,并且可能难以处理:
import sqlglot
sqlglot.transpile("SELECT EPOCH_MS(1618088028295)", read="duckdb", write="hive")[0]'SELECT FROM_UNIXTIME(1618088028295 / POW(10, 3))'SQLGlot 甚至可以转换自定义时间格式:
import sqlglot
sqlglot.transpile("SELECT STRFTIME(x, '%y-%-m-%S')", read="duckdb", write="hive")[0]"SELECT DATE_FORMAT(x, 'yy-M-ss')"标识符分隔符和数据类型也可以翻译:
import sqlglot
# Spark SQL requires backticks (`) for delimited identifiers and uses `FLOAT` over `REAL`
sql = """WITH baz AS (SELECT a, c FROM foo WHERE a = 1) SELECT f.a, b.b, baz.c, CAST("b"."a" AS REAL) d FROM foo f JOIN bar b ON f.a = b.a LEFT JOIN baz ON f.a = baz.a"""
# Translates the query into Spark SQL, formats it, and delimits all of its identifiers
print(sqlglot.transpile(sql, write="spark", identify=True, pretty=True)[0])WITH `baz` AS (
SELECT
`a`,
`c`
FROM `foo`
WHERE
`a` = 1
)
SELECT
`f`.`a`,
`b`.`b`,
`baz`.`c`,
CAST(`b`.`a` AS FLOAT) AS `d`
FROM `foo` AS `f`
JOIN `bar` AS `b`
ON `f`.`a` = `b`.`a`
LEFT JOIN `baz`
ON `f`.`a` = `baz`.`a`同时也会保留注释的内容:
sql = """
/* multi
line
comment
*/
SELECT
tbl.cola /* comment 1 */ + tbl.colb /* comment 2 */,
CAST(x AS SIGNED), # comment 3
y -- comment 4
FROM
bar /* comment 5 */,
tbl # comment 6
"""
# Note: MySQL-specific comments (`#`) are converted into standard syntax
print(sqlglot.transpile(sql, read='mysql', pretty=True)[0])/* multi
line
comment
*/
SELECT
tbl.cola /* comment 1 */ + tbl.colb /* comment 2 */,
CAST(x AS INT), /* comment 3 */
y /* comment 4 */
FROM bar /* comment 5 */, tbl /* comment 6 */元数据
也可以使用表达式助手探索 SQL,以执行诸如在查询中查找列和表之类的操作:
from sqlglot import parse_one, exp
# print all column references (a and b)
for column in parse_one("SELECT a, b + 1 AS c FROM d").find_all(exp.Column):
print(column.alias_or_name)
# find all projections in select statements (a and c)
for select in parse_one("SELECT a, b + 1 AS c FROM d").find_all(exp.Select):
for projection in select.expressions:
print(projection.alias_or_name)
# find all tables (x, y, z)
for table in parse_one("SELECT * FROM x JOIN y JOIN z").find_all(exp.Table):
print(table.name)解析器错误
当解析器检测到语法错误时,它会引发 ParseError:
import sqlglot
sqlglot.transpile("SELECT foo FROM (SELECT baz FROM t")sqlglot.errors.ParseError: Expecting ). Line 1, Col: 34.
SELECT foo FROM (SELECT baz FROM t
~结构化语法错误可用于编程使用:
import sqlglot
try:
sqlglot.transpile("SELECT foo FROM (SELECT baz FROM t")
except sqlglot.errors.ParseError as e:
print(e.errors)[{
'description': 'Expecting )',
'line': 1,
'col': 34,
'start_context': 'SELECT foo FROM (SELECT baz FROM ',
'highlight': 't',
'end_context': '',
'into_expression': None
}]不支持的错误
可能无法在某些方言之间翻译某些查询。对于这些情况,SQLGlot 会发出警告并默认进行尽力翻译:
import sqlglot
sqlglot.transpile("SELECT APPROX_DISTINCT(a, 0.1) FROM foo", read="presto", write="hive")APPROX_COUNT_DISTINCT does not support accuracy
'SELECT APPROX_COUNT_DISTINCT(a) FROM foo'可以通过设置 unsupported_level 属性来更改此行为。例如,我们可以将其设置为 RAISE 或 IMMEDIATE 以确保引发异常:
import sqlglot
sqlglot.transpile("SELECT APPROX_DISTINCT(a, 0.1) FROM foo", read="presto", write="hive", unsupported_level=sqlglot.ErrorLevel.RAISE)sqlglot.errors.UnsupportedError: APPROX_COUNT_DISTINCT does not support accuracy
构建和修改 SQL
SQLGlot 支持增量构建 SQL 表达式:
from sqlglot import select, condition
where = condition("x=1").and_("y=1")
select("*").from_("y").where(where).sql()'SELECT * FROM y WHERE x = 1 AND y = 1'可以修改解析树:
from sqlglot import parse_one
parse_one("SELECT x FROM y").from_("z").sql()'SELECT x FROM z'解析表达式还可以通过将映射函数应用于树中的每个节点来递归转换:
from sqlglot import exp, parse_one
expression_tree = parse_one("SELECT a FROM x")
def transformer(node):
if isinstance(node, exp.Column) and node.name == "a":
return parse_one("FUN(a)")
return node
transformed_tree = expression_tree.transform(transformer)
transformed_tree.sql()'SELECT FUN(a) FROM x'SQL优化器
SQLGlot 可以将查询重写为“优化”形式。它执行多种技术来创建新的规范 AST。该 AST 可用于标准化查询或为实现实际引擎提供基础。例如:
import sqlglot
from sqlglot.optimizer import optimize
print(
optimize(
sqlglot.parse_one("""
SELECT A OR (B OR (C AND D))
FROM x
WHERE Z = date '2021-01-01' + INTERVAL '1' month OR 1 = 0
"""),
schema={"x": {"A": "INT", "B": "INT", "C": "INT", "D": "INT", "Z": "STRING"}}
).sql(pretty=True)
)SELECT
(
"x"."a" <> 0 OR "x"."b" <> 0 OR "x"."c" <> 0
)
AND (
"x"."a" <> 0 OR "x"."b" <> 0 OR "x"."d" <> 0
) AS "_col_0"
FROM "x" AS "x"
WHERE
CAST("x"."z" AS DATE) = CAST('2021-02-01' AS DATE)AST 内省
您可以通过调用 repr 来查看解析后的 SQL 的 AST 版本:
from sqlglot import parse_one
print(repr(parse_one("SELECT a + 1 AS z")))
Select(
expressions=[
Alias(
this=Add(
this=Column(
this=Identifier(this=a, quoted=False)),
expression=Literal(this=1, is_string=False)),
alias=Identifier(this=z, quoted=False))])AST 差异
SQLGlot 可以计算两个表达式之间的语义差异,并以将源表达式转换为目标表达式所需的一系列操作的形式输出更改:
from sqlglot import diff, parse_one
diff(parse_one("SELECT a + b, c, d"), parse_one("SELECT c, a - b, d"))[
Remove(expression=Add(
this=Column(
this=Identifier(this=a, quoted=False)),
expression=Column(
this=Identifier(this=b, quoted=False)))),
Insert(expression=Sub(
this=Column(
this=Identifier(this=a, quoted=False)),
expression=Column(
this=Identifier(this=b, quoted=False)))),
Keep(
source=Column(this=Identifier(this=a, quoted=False)),
target=Column(this=Identifier(this=a, quoted=False))),
...
]参考: Semantic Diff for SQL.
自定义方言
可以通过子类化 Dialect 来添加方言:
from sqlglot import exp
from sqlglot.dialects.dialect import Dialect
from sqlglot.generator import Generator
from sqlglot.tokens import Tokenizer, TokenType
class Custom(Dialect):
class Tokenizer(Tokenizer):
QUOTES = ["'", '"']
IDENTIFIERS = ["`"]
KEYWORDS = {
**Tokenizer.KEYWORDS,
"INT64": TokenType.BIGINT,
"FLOAT64": TokenType.DOUBLE,
}
class Generator(Generator):
TRANSFORMS = {exp.Array: lambda self, e: f"[{self.expressions(e)}]"}
TYPE_MAPPING = {
exp.DataType.Type.TINYINT: "INT64",
exp.DataType.Type.SMALLINT: "INT64",
exp.DataType.Type.INT: "INT64",
exp.DataType.Type.BIGINT: "INT64",
exp.DataType.Type.DECIMAL: "NUMERIC",
exp.DataType.Type.FLOAT: "FLOAT64",
exp.DataType.Type.DOUBLE: "FLOAT64",
exp.DataType.Type.BOOLEAN: "BOOL",
exp.DataType.Type.TEXT: "STRING",
}
print(Dialect["custom"])<class '__main__.Custom'>
SQL执行
SQLGlot 能够解释 SQL 查询,其中表表示为 Python 字典。该引擎不应该很快,但它对于单元测试和跨 Python 对象本机运行 SQL 很有用。此外,该基础可以轻松地与快速计算内核集成,例如 Arrow 和 Pandas。
下面的示例展示了涉及聚合和联接的查询的执行:
tables = {
"sushi": [
{"id": 1, "price": 1.0},
{"id": 2, "price": 2.0},
{"id": 3, "price": 3.0},
],
"order_items": [
{"sushi_id": 1, "order_id": 1},
{"sushi_id": 1, "order_id": 1},
{"sushi_id": 2, "order_id": 1},
{"sushi_id": 3, "order_id": 2},
],
"orders": [
{"id": 1, "user_id": 1},
{"id": 2, "user_id": 2},
],
}
execute(
"""
SELECT
o.user_id,
SUM(s.price) AS price
FROM orders o
JOIN order_items i
ON o.id = i.order_id
JOIN sushi s
ON i.sushi_id = s.id
GROUP BY o.user_id
""",
tables=tables
)user_id price
1 4.0
2 3.0参考: Writing a Python SQL engine from scratch.
今天分享就到此啦,感兴趣的小伙伴可以自己去安装玩一玩。
注:整理不易,希望点赞关注一波,谢谢啦~