PS:本篇只在宏观上介绍相关概念和技术,不做数学推导和过于细节介绍,旨在快速有一个宏观认知,不拘泥在细节上,导致很混乱。
涉及技术名词
分布式框架等涉及的技术名词很多,很容易让人眼花缭乱,整体可以概括如下:
1、混合精度训练。
2、并行维度:数据并行、张量并行、流水线并行、模型并行、3D并行、混合并行。
3、ZeRO 1、ZeRO 2、ZeRO 3、ZeRO-offload
4、框架(基本都有或就是基于pytorch):Megatron、DeepSpeed、Megatron-LM、Megatron-DeepSpeed 、pytorch 自带的FSDP。
5、关于Attention优化:Flash Attention、Flash Attention 2、 Paged Attention、Xformers、MHA、MQA、GQA。
6、硬件:nvlink、nvswitch、Infiniband。
1、混合精度训练
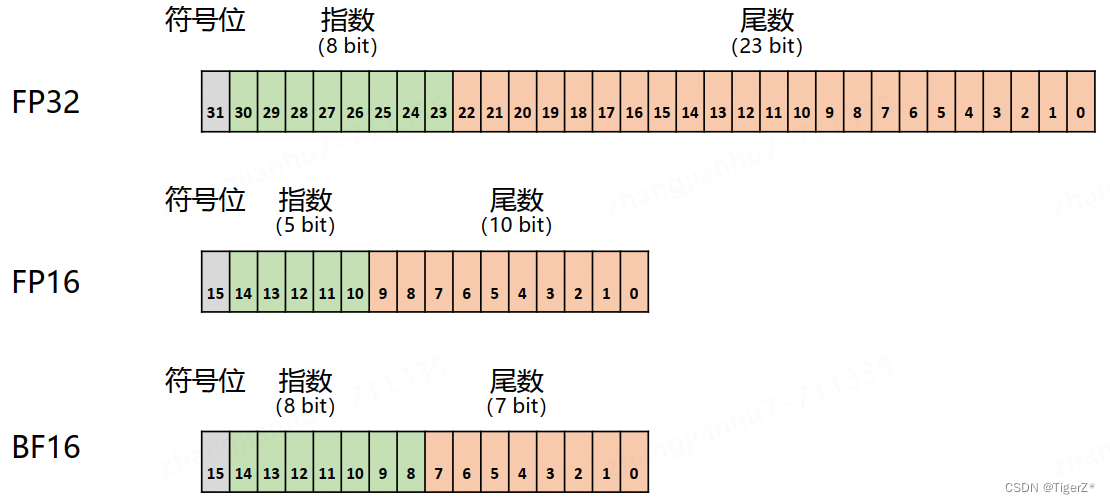
目的是降低显存消耗和加速推理过程。大致原理是模型参数、梯度、激活等使用FP16或BF16,然后再保存一份模型的状态(sgd,如果是Adam则包含模型、一阶专状态、二阶状态三份参数)用于梯度更新。原因是单纯半精度有如下问题:
1)溢出错误:由于FP16的动态范围比FP32位的狭窄很多,因此,在计算过程中很容易出现上溢出和下溢出,溢出之后就会出现"NaN"的问题。在深度学习中,由于激活函数的梯度往往要比权重梯度小,更易出现下溢出的情况。
2)舍入误差:当梯度过小时,小于当前区间内的最小间隔时,该次梯度更新可能会失败。
如下为不同精度的表示。由于 FP16 和 BF16 相较 FP32 精度低,训练过程中可能会出现梯度消失和模型不稳定的问题。因此,需要使用一些技术来解决这些问题,例如动态损失缩放(Dynamic Loss Scaling)和混合精度优化器(Mixed Precision Optimizer)。
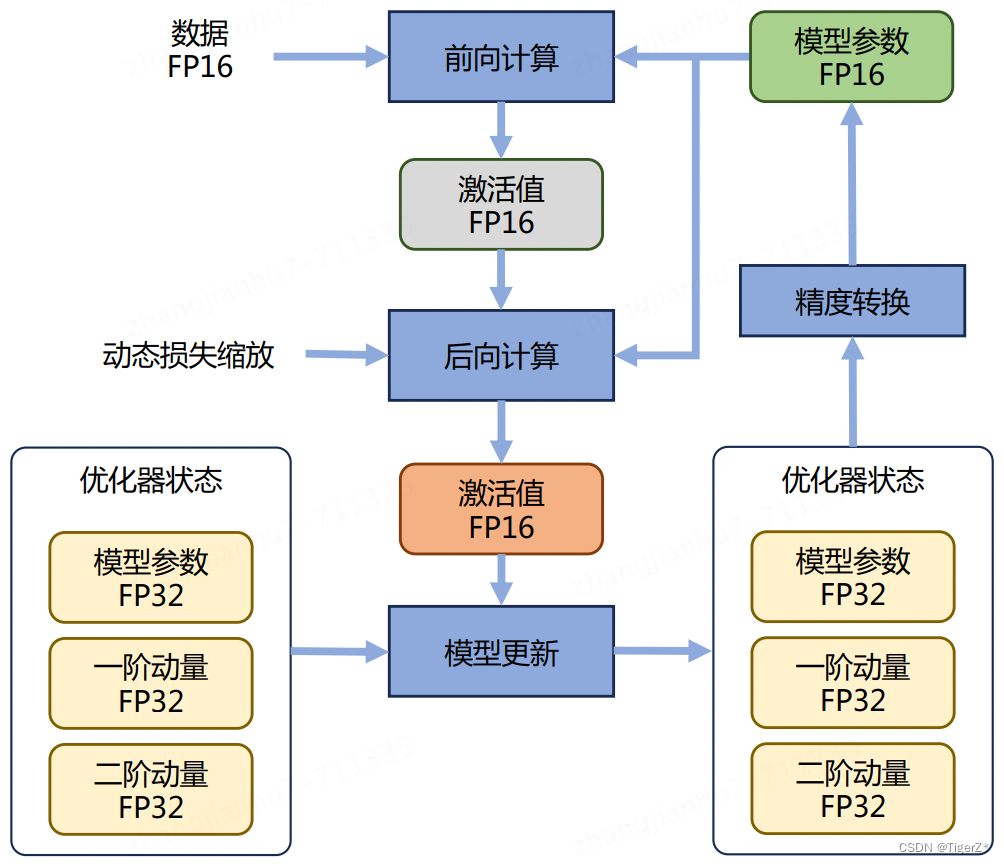
混合训练整体流程如下(Adam为例)。 Adam 优化器状态包括采用 FP32 保存的模型参数备份,一阶动量和二阶动量也都采用 FP32 格式存储。假设模型参数量为 Φ,模型参数和梯度都是用 FP16格式存储,则共需要 2Φ + 2Φ + (4Φ + 4Φ + 4Φ) = 16Φ 字节存储。其中 Adam 状态占比 75%。动态损失缩放反向传播前,将损失变化(dLoss)手动增大 2K 倍,因此反向传播时得到的激活函数梯度则不会溢出;反向传播后,将权重梯度缩小 2K 倍,恢复正常值。举例来说,对于包含 75 亿个参数模型,如果用 FP16 格式,只需要 15GB 计算设备内存,但是在训练阶段模型状态实际上需要耗费 120GB。
使用方式很简单(需要Tensor core 支持),如下
# amp依赖Tensor core架构,所以模型必须在cuda设备下使用
model = Model()
model.to("cuda") # 必须!!!
optimizer = optim.SGD(model.parameters(), ...)
# (新增)创建GradScaler对象
scaler = GradScaler(enabled=True) # 虽然默认为True,体验一下过程
for epoch in epochs:
for img, target in data:
optimizer.zero_grad()
# (新增)启动autocast上下文管理器
with autocast(enabled=True):
# (不变)上下文管理器下,model前向传播,以及loss计算自动切换数值精度
output = model(img)
loss = loss_fn(output, target)
# (修改)反向传播
scaler.scale(loss).backward()
# (修改)梯度计算
scaler.step(optimizer)
# (新增)scaler更新
scaler.update()但是注意并行训练时需要autocast装饰model的forward函数
MyModel(nn.Module):
@autocast()
def forward(self, input):
...2、并行维度
单设备计算速度主要由单块计算加速芯片的运算速度和数据 I/O 能力来决定,对单设备训练效率进行优化,主要的技术手段有混合精度训练、算子融合、梯度累加等;多设备加速比需要综合考虑计算、显存、通信三方面因素。
并行大体上分为:数据并行、模型并行(细分为流水线并行和张量并行)、混合并行(也叫3D并行,混合使用数据并行和模型并行)。
数据并行:对数据进行切分,并将同一个模型复制到多个设备上,并行执行不同的数据分片,这种方式通常被称为数据并行。它和单计算设备训练相比,最主要的区别就在于反向计算中的梯度需要在所有计算设备中进行同步,以保证每个计算设备上最终得到的是所有进程上梯度的平均值。
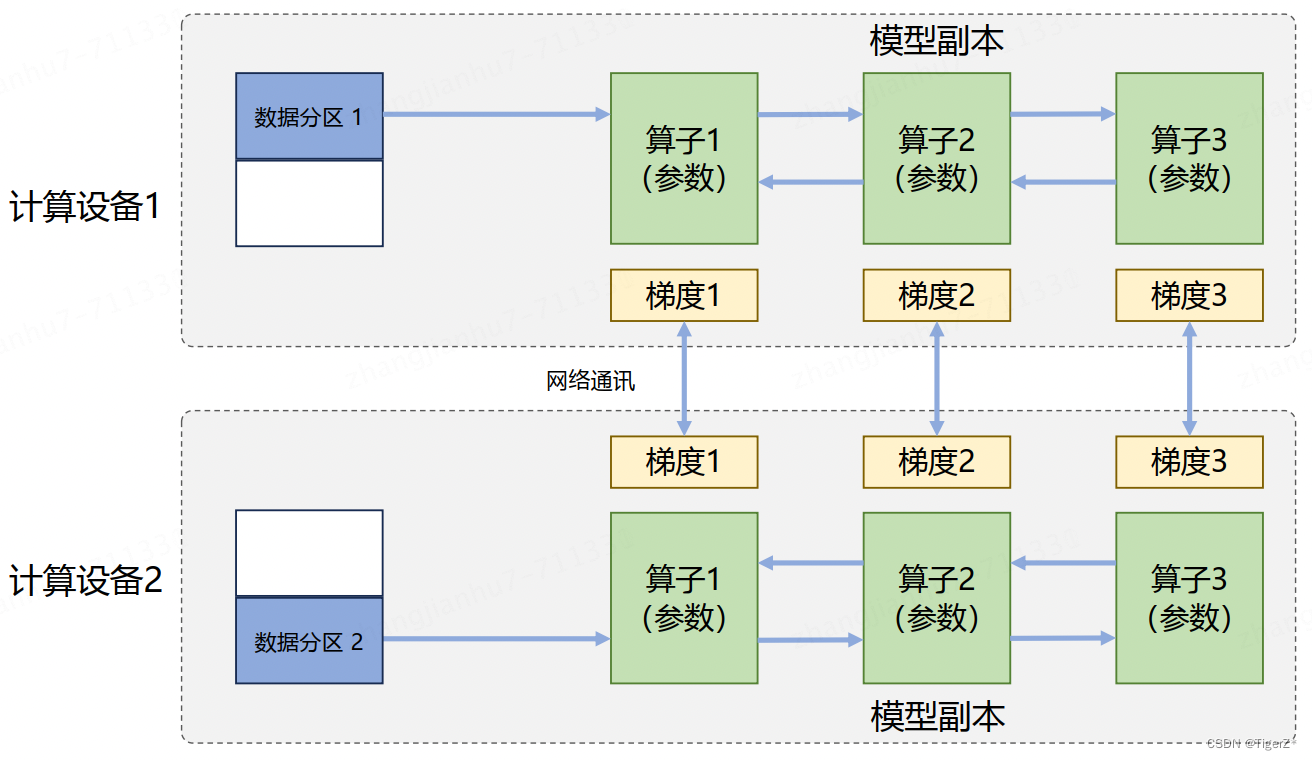
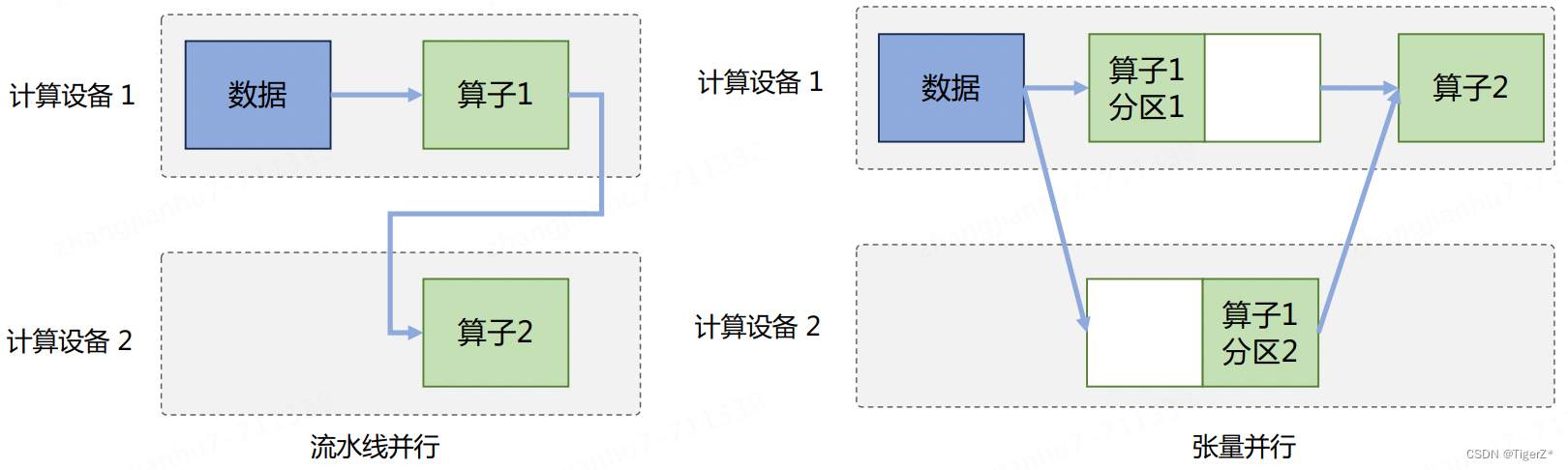
模型并行:对模型进行划分,将模型中的算子分发到多个设备分别完成,往往用于解决单节点内存不足的问题。模型并行从计算图角度分为如下两种:
1)按模型的层切分到不同设备,即层间并行或算子间并行(Inter-operator Parallelism),也称之为流水线并行(Pipeline Parallelism, PP);
2)将计算图层内的参数切分到不同设备,即层内并行或算子内并行(Intra-operator Parallelism),也称之为张量并行(Tensor Parallelism, TP)。需要根据模型的具体结构和算子类型,解决如何将参数切分到不同设备,以及如何保证切分后数学一致性两个问题。
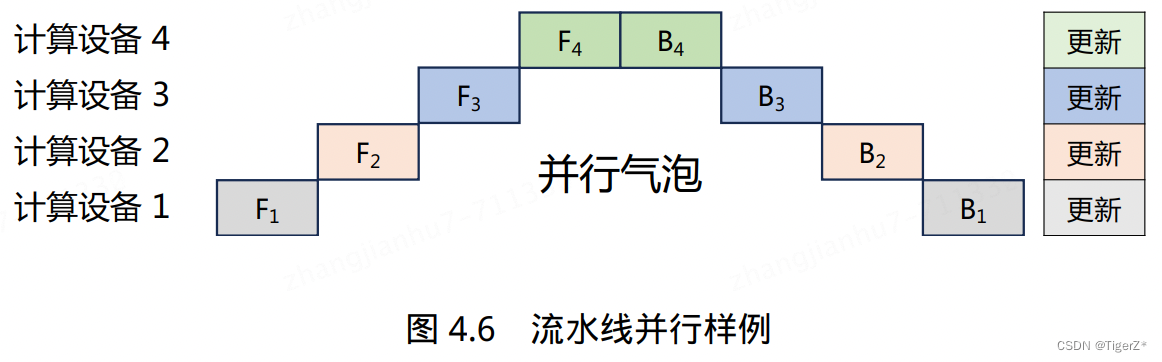
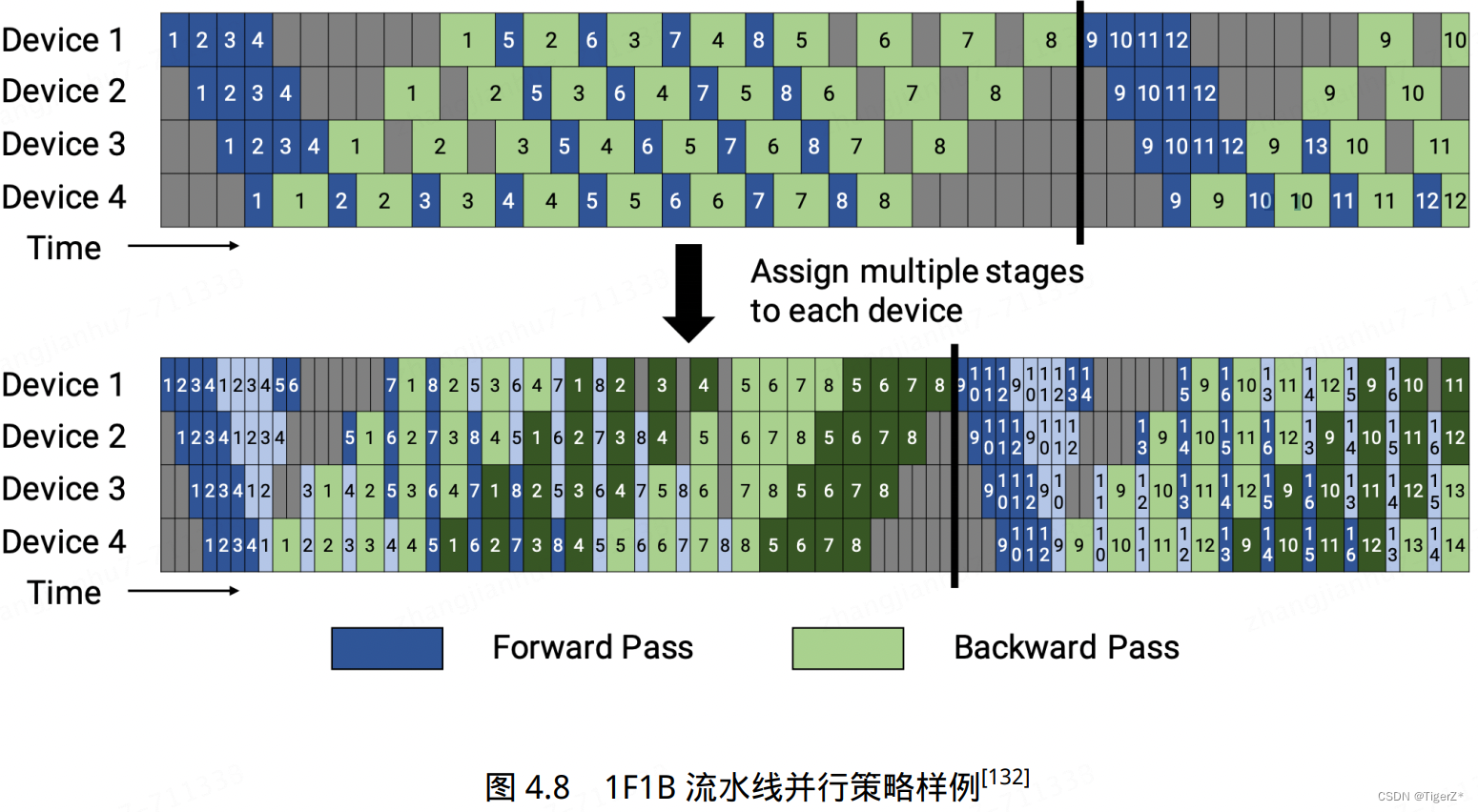
其中流水线并行存在的问题就是并行气泡,改进方案有:Gpipe(数据分割成更小的micro-batch)、megtron里面的1F1B策略(每个设备可以并行执行不同阶段的计算任务)。

混合并行:训练超大规模语言模型时,往往需要同时对数据和模型进行切分,从而实现更高程度的并行,这种方式通常被称为混合并行。针对千亿规模的大语言模型,通常在每个服务器内部使用张量并行策略,由于该策略涉及的网络通信量较大,需要利用服务器内部的不同计算设备之间进行高速通信带宽。通过流水线并行,将模型的不同层划分为多个阶段,每个阶段由不同的机器负责计算。这样可以充分利用多台机器的计算能力,并通过机器之间的高速通信来传递计算结果和中间数据,以提高整体的计算速度和效率。最后,在外层叠加数据并行策略,以增加并发数量,提升整体训练速度。通过数据并行,将训练数据分发到多组服务器上进行并行处理,每组服务器处理不同的数据批次。参考下图BLOOM模型的训练结构。
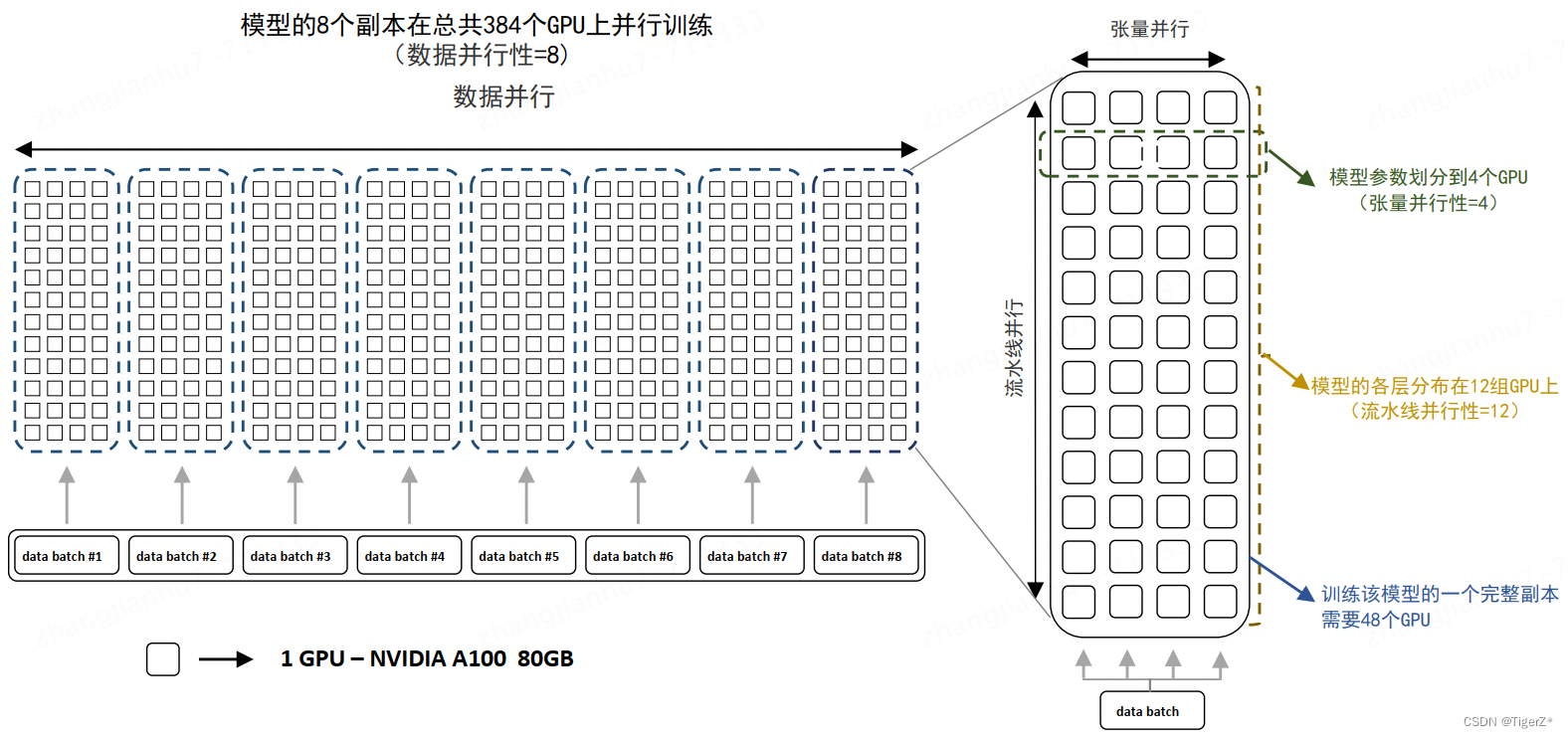
3、zero系列优化
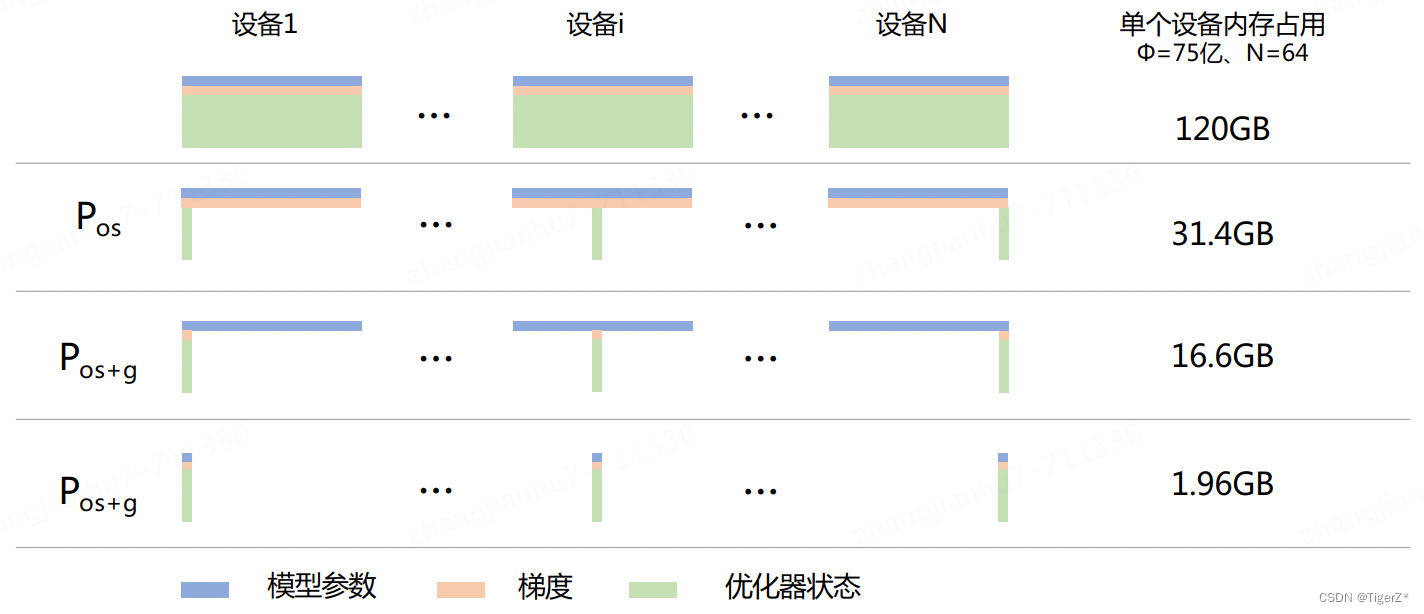
通过混合精度和并行维度前两部分的解读,对于数据并行而言,如果你使用的是Adam优化器(目前LLM几乎都是Adam),那么75%的参数都在存储FP32的模型状态。所以zero目标就是针对模型状态的存储进行去冗余的优化。本质而言是针对数据并行的优化,使用分区的方法,即将模型状态量分割成多个分区,每个计算设备只保存其中的一部分。这样整个训练系统内只需要维护一份模型状态,减少了内存消耗和通信开销。包含3种强度的去冗余(不同强度通信开销不同, Zero-1 和 Zero-2 对整体通信量没有影响,对通讯有一定延迟影响,但是整体性能影响很小。 Zero-3 所需的通信量则是正常通信量的1.5 倍。),对应下图的Pos、Pos+g、Pos+g+p:
*zero-1:对 Adam 优化器状态进行分区,图中的 Pos。模型参数和梯度依然是每个计算设备保存一份。此时,每个计算设备所需内存是 4Φ + 12Φ/N 字节,其中 N 是计算设备总数。当 N 比较大时,每个计算设备占用内存趋向于 4ΦB,也就是原来 16ΦB 的 1/4。
*zero-2:对模型梯度进行分区,图中的 Pos+g。模型参数依然是每个计算设备保存一份。此时,每个计算设备所需内存是 2Φ + (2Φ+12Φ)/N 字节。当 N 比较大时,每个计算设备占用内存趋向于2ΦB,也就是原来 16ΦB 的 1/8。
*zero-3: 对模型参数也进行分区,图中的 Pos+g+p。此时,每个计算设备所需内存是 (16Φ /N) * B。当 N比较大时,每个计算设备占用内存趋向于 0。
*ZeRO Infinity:可以看成是stage-3的进阶版本,需要依赖于NVMe的支持。他可以offload所有模型参数状态到CPU以及NVMe上。得益于NMVe协议,除了使用CPU内存之外,ZeRO可以额外利用SSD(固态),从而极大地节约了memory开销,加速了通信速度。
使用方法: DeepSpeed使用过程中的一个难点,就在于时间和空间的权衡。先使用下述代码,大概估计一下显存消耗,决定使用的GPU数目,以及ZeRO-stage。原则是,能直接多卡训练,就不要用ZeRO;能用ZeRO-2就不要用ZeRO-3。
from transformers import AutoModel
from deepspeed.runtime.zero.stage3 import estimate_zero3_model_states_mem_needs_all_live
## specify the model you want to train on your device
model = AutoModel.from_pretrained("t5-large")
## estimate the memory cost (both CPU and GPU)
estimate_zero3_model_states_mem_needs_all_live(model, num_gpus_per_node=1, num_nodes=1)真实使用主要就是三点:安装DeepSpeed、编写配置文件、训练shell命令。具体可以参考:DeepSpeed使用指南(简略版)-CSDN博客
1)安装(transformers 默认已经集成了deepspeed):
pip install deepspeed # 或 pip install transformers2)编写配置文件,以zero-2为例,命名为ds_config.json
{
"bfloat16": {
"enabled": "auto"
},
"fp16": {
"enabled": "auto",
"loss_scale": 0,
"loss_scale_window": 1000,
"initial_scale_power": 16,
"hysteresis": 2,
"min_loss_scale": 1
},
"optimizer": {
"type": "AdamW",
"params": {
"lr": "auto",
"betas": "auto",
"eps": "auto",
"weight_decay": "auto"
}
},
"scheduler": {
"type": "WarmupLR",
"params": {
"warmup_min_lr": "auto",
"warmup_max_lr": "auto",
"warmup_num_steps": "auto"
}
},
"zero_optimization": {
"stage": 2,
"offload_optimizer": {
"device": "cpu",
"pin_memory": true
},
"allgather_partitions": true,
"allgather_bucket_size": 2e8,
"overlap_comm": true,
"reduce_scatter": true,
"reduce_bucket_size": 2e8,
"contiguous_gradients": true
},
"gradient_accumulation_steps": "auto",
"gradient_clipping": "auto",
"train_batch_size": "auto",
"train_micro_batch_size_per_gpu": "auto",
"steps_per_print": 1e5
}3)编写启动shell脚本
deepspeed --master_port 29500 --num_gpus=2 run_s2s.py --deepspeed ds_config.json4、框架
Megatron、DeepSpeed、Megatron-LM、Megatron-DeepSpeed 、pytorch 自带的FSDP。目前网上已有总结也不是很清楚,其中DeepSpeed是微软的,Megtron是NVIDIA的,用的最多的是deepspeed, transformers库很多也是用Deepspeed。然后DeepSpeed也集成了megatron,所以目前我的理解是用DeepSpeed作为基础(本身基于pytorch),再集成使用megatron、pytorch、flash Attention2是202303xx最优解?
PS:在 DeepSpeed 框架个人理解最大的优势就是zero优化(zero论文和DeepSpeed都是微软团队), Pos 对应 Zero-1, Pos+g 对应 Zero-2, Pos+g+p 对应 Zero-3。
如下给出了 DeepSpeed 3D 并行策略示意图。图中给出了包含 32 个计算设备进行 3D 并行的例子。神经网络的各层分为 4 个流水线阶段。每个流水线阶段中的层在 4 个张量并行计算设备之间进一步划分。最后,每个流水线阶段有两个数据并行实例,使用 ZeRO 内存优化在这 2 个副本之间划分优化器状态量。
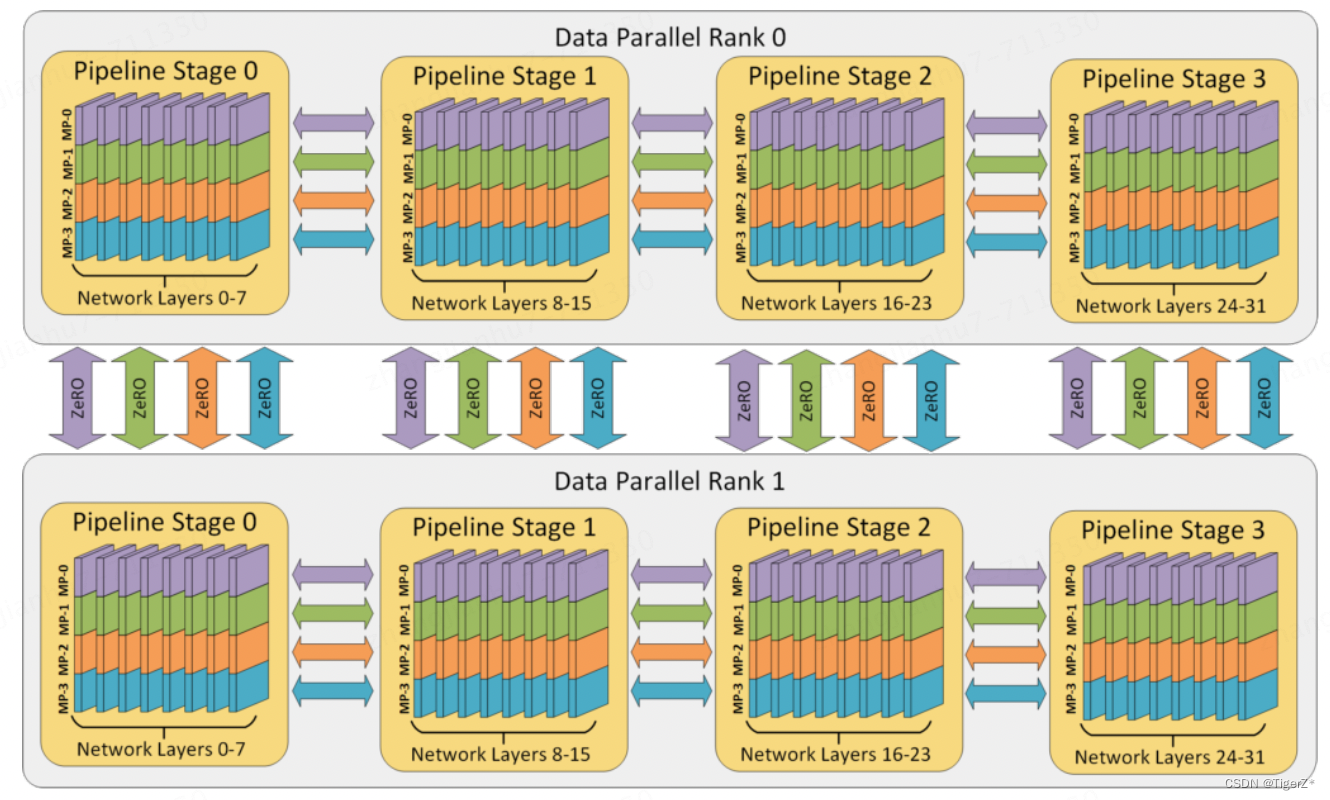
5、关于Attention优化
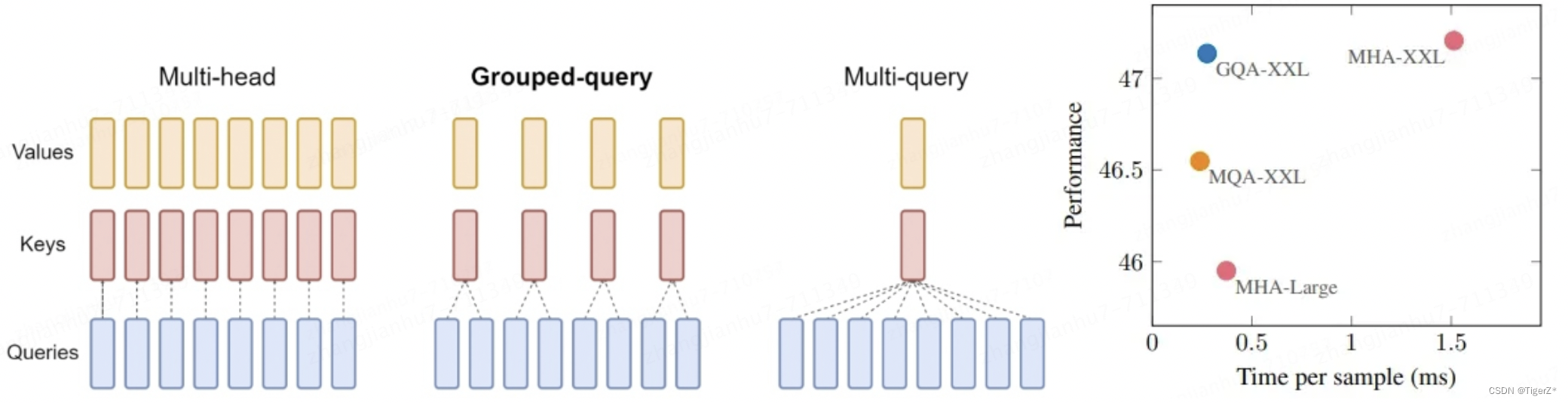
MHA、MQA、GQA
是算法上的概念,对应不同的注意力机制,如下图。
1)MHA(Multi Head Attention)中,每个头有自己单独的 key-value 对;
2)MQA(Multi Query Attention)中只会有一组 key-value 对;
3)GQA(Grouped Query Attention)中,会对 attention 进行分组操作,query 被分为 N 组,每个组共享一个 Key 和 Value 矩阵。GQA-N 是指具有 N 组的 Grouped Query Attention。GQA-1具有单个组,因此具有单个Key 和 Value,等效于MQA。而GQA-H具有与头数相等的组,等效于MHA。
flash Attention、 flash Attention 2、xformer、 Paged Attention
工程实现优化Attention的推理性能。
Flash Attention、Flash Attention 2:主要是利用GPU的并行特性从循环角度进行优化。
Paged Attention:主要是针对KV的缓存(cache)的优化。
Xformer:虽然有优化显存等,底层也用了flash Attention,我的理解是个库,有很多实现。
使用都很简单,都是一句话直接调用,参考:速度飙升200%!Flash Attention 2一统江湖,注意力计算不再是问题! - 知乎,涉及代码如下:
import torch
import torch.nn.functional as F
from flash_attn import flash_attn_func
from xformers.ops import memory_efficient_attention, LowerTriangularMask
def pytorch_func(q, k, v, causal=False):
o = F._scaled_dot_product_attention(q, k, v, is_causal=causal)[0]
return o
def flash_attention(q, k, v, causal=False):
o = flash_attn_func(q, k, v, causal=causal)
return o
def xformers_attention(q, k, v, causal=False):
attn_bias = xformers_attn_bias if causal else None
o = memory_efficient_attention(q, k, v, attn_bias=attn_bias)
return o6、硬件架构
NVLink可以简单理解是GPU卡上有通信接口(网口网线的概念)。nv switch可以理解为是交换机(确实是一个硬件),同一台机器(pod)不同GPU使用nvswich 底层通过nvlink链接(如果卡很少,我的理解其实可以不使用nvswtich,直接卡间互联)。可以参考如下图
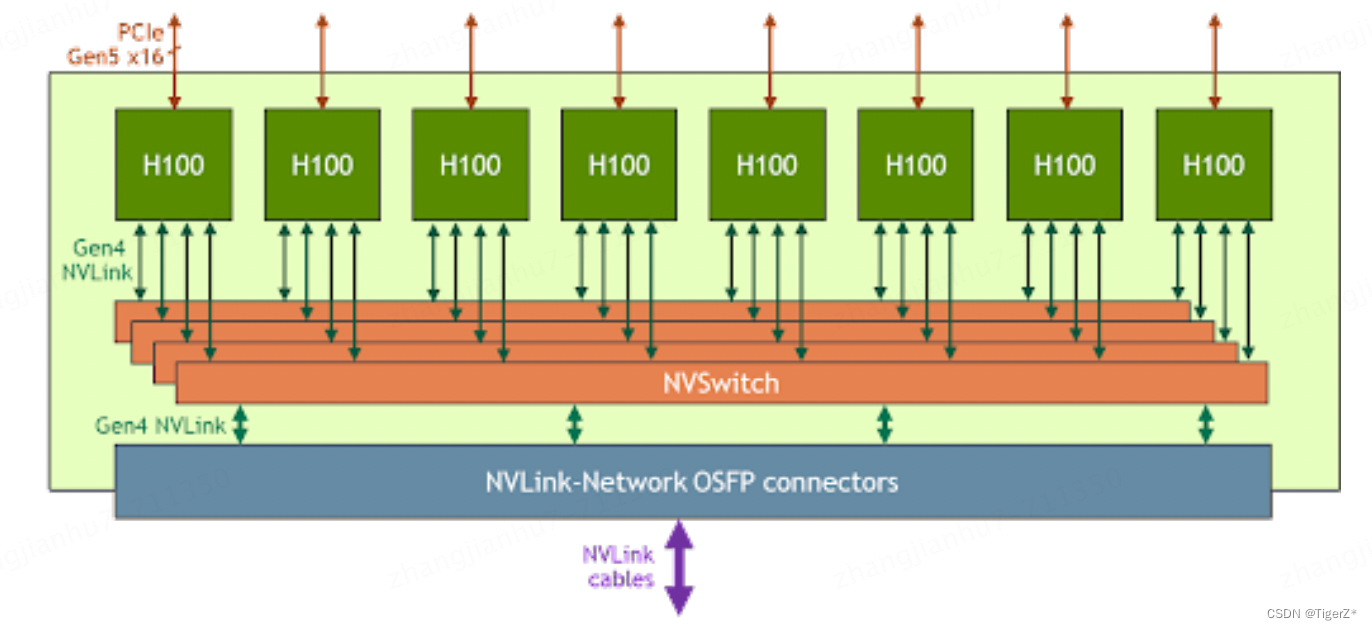
不同机器(pod)之间通过采用InfiniBand网络通信标准的交换机链接,如下图: 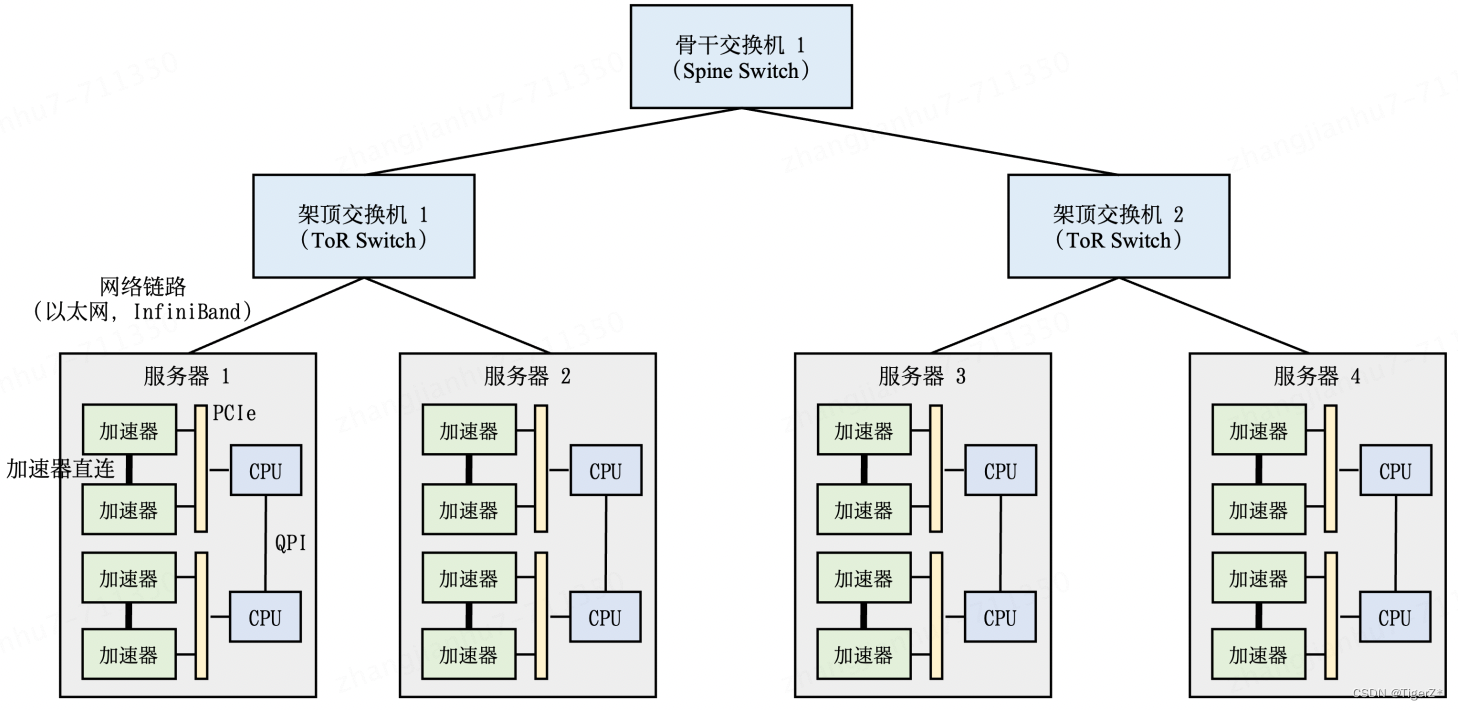
参考链接:
[LLM]大模型训练(一)--DeepSpeed介绍-CSDN博客
LLM(十七):从 FlashAttention 到 PagedAttention, 如何进一步优化 Attention 性能 - 知乎