归并排序
- 前言
- 一、归并排序的基本思想
- 二、归并排序的特性总结
- 三、归并排序的动画展示
- 四、递归实现归并排序的具体代码展示
- 五、非递归实现归并排序
前言
归并排序是一种分治策略的排序算法。它将一个序列分为两个等长(几乎等长)的子序列,分别对子序列进行排序,然后将排序结果合并起来,得到完全有序的序列。这个过程递归进行,直到整个序列有序。归并排序的时间复杂度为O(nlogn),空间复杂度为O(n)。
一、归并排序的基本思想
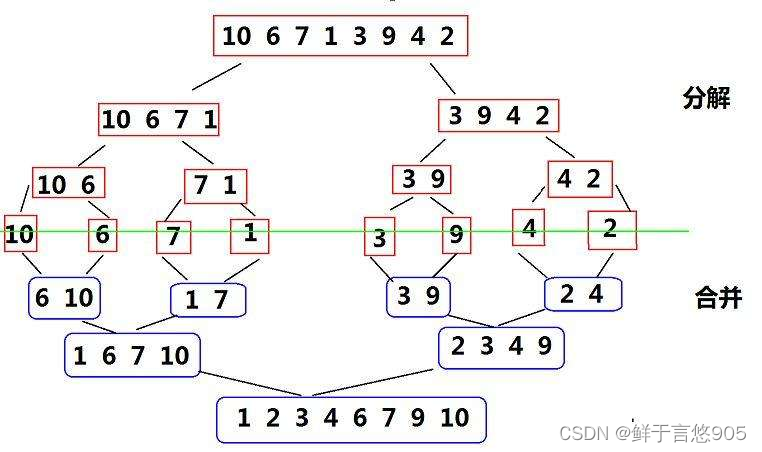
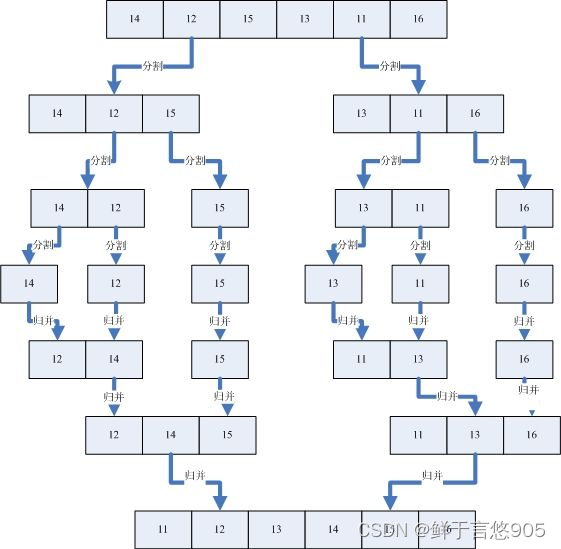
归并排序(MERGE-SORT)是建立在归并操作上的一种有效的排序算法,该算法是采用分治法(Divide and Conquer)的一个非常典型的应用。将已有序的子序列合并,得到完全有序的序列;即先使每个子序列有序,再使子序列段间有序。若将两个有序表合并成一个有序表,称为二路归并。
归并排序的基本思想是将两个或两个以上的有序表合并成一个新的有序表。这个思想可以递归地应用于子序列的排序,最终使得整个序列有序。
具体来说,归并排序可以分为两个主要步骤:分解和合并。
分解步骤是将待排序的序列不断分解成两个子序列,直到子序列的长度为1。这个过程可以通过递归实现,每次递归都将当前序列的中间点作为分割点,将序列分成左右两个子序列。由于子序列的长度为1,因此它们本身就被视为有序序列。
合并步骤是将两个有序子序列合并成一个新的有序序列。这个过程可以通过迭代实现,每次迭代都取两个子序列中的第一个元素,比较它们的大小,将较小的元素添加到新序列中,并将其从原序列中移除。这个过程一直持续到其中一个子序列为空,然后将另一个子序列中剩余的元素全部添加到新序列中。
归并排序的时间复杂度为O(nlogn),其中n是待排序序列的长度。这是因为分解步骤需要递归地将序列分解成子序列,这个过程的复杂度为O(logn);而合并步骤需要将两个子序列合并成一个新序列,这个过程的复杂度为O(n)。由于这两个步骤都需要进行logn次,因此总的时间复杂度为O(nlogn)。
归并排序是一种稳定排序算法,即相等元素的相对顺序在排序前后保持不变。这是因为在合并步骤中,当两个子序列中出现相等元素时,我们总是先取左子序列中的元素,因此相等元素在左子序列中的相对顺序会被保留下来。
二、归并排序的特性总结
- 归并的缺点在于需要O(N)的空间复杂度,归并排序的思考更多的是解决在磁盘中的外排序问题。
- 时间复杂度:O(N*logN)
- 空间复杂度:O(N)
- 稳定性:稳定
归并排序的特性总结起来主要有四点:稳定性、时间复杂度、空间复杂度和递归性。
首先是稳定性。归并排序是一种稳定的排序算法,即相同元素的相对顺序在排序过程中不会改变。这一特性使得归并排序在处理需要保持原始顺序的数据时非常有用,比如在数据库查询、文件处理等场景中,保持数据的原始顺序往往是非常重要的。
其次是时间复杂度。归并排序的时间复杂度为O(nlogn),其中n是待排序数据的数量。这意味着无论数据是已经部分排序还是完全无序,归并排序都能保持较高的效率。这种优良的时间复杂度使得归并排序在处理大规模数据时具有显著优势。
再次是空间复杂度。归并排序的空间复杂度为O(n),因为它需要额外的空间来合并两个已排序的子数组。这意味着在内存有限的情况下,使用归并排序可能需要额外的考虑。然而,在大多数情况下,这种空间消耗是可以接受的,因为归并排序的高效性和稳定性往往能够抵消其空间复杂度的不足。
最后是递归性。归并排序是一种典型的分治算法,它通过递归地将问题分解为更小的子问题来解决。这种递归性使得归并排序的实现相对简单明了,也易于理解和维护。然而,递归也可能导致栈空间的消耗,因此在处理大规模数据时需要注意递归深度的问题。
综上所述,归并排序作为一种高效稳定的排序算法,在实际应用中具有广泛的应用场景。其稳定的特性使得它能够保持数据的原始顺序不变;优良的时间复杂度使得它能够处理大规模数据;额外的空间消耗在大多数情况下是可以接受的;递归性则使得归并排序的实现简单明了。了解这些特性并合理利用它们,可以让我们在实际编程中更加高效地使用归并排序算法。
三、归并排序的动画展示
归并排序是一种分治策略的排序算法。动画展示中,初始时,列表被分为单个元素的子列表。然后,相邻的子列表通过归并操作合并为有序的较长子列表,这一过程递归进行,直至整个列表有序。动画生动展示了如何通过将小有序片段合并为更大有序片段来实现整个列表的排序。
归并排序
四、递归实现归并排序的具体代码展示
#include<stdio.h>
#include<stdlib.h>
#include <string.h>
#include<time.h>
void MergeSort(int* a, int n);
void _MergeSort(int* a, int begin, int end, int* tmp);
void PrintArray(int* a, int n);
void TestMergeSort()
{
int a[] = { 5, 13, 9, 16, 12, 4, 7, 1, 28, 25, 3, 9, 6, 2, 4, 7, 1, 8 };
//int a[] = { 5, 3, 9, 6, 2, 4, 7, 1, 8 };
PrintArray(a, sizeof(a) / sizeof(int));
MergeSort(a, sizeof(a) / sizeof(int));
PrintArray(a, sizeof(a) / sizeof(int));
}
void PrintArray(int* a, int n)
{
for (int i = 0; i < n; i++)
{
printf("%d ", a[i]);
}
printf("\n");
}
void MergeSort(int* a, int n)
{
int* tmp = malloc(sizeof(int) * n);
if (tmp == NULL)
{
perror;
return;
}
_MergeSort(a, 0, n - 1, tmp);
}
void _MergeSort(int* a, int begin, int end, int* tmp)
{
if (begin == end)return;
int mid = (end + begin) / 2;
_MergeSort(a, begin, mid, tmp);
_MergeSort(a, mid + 1, end, tmp);
int begin1 = begin, begin2 = mid + 1, end1 = mid, end2 = end;
int i = begin;
while (begin1 <= end1 && begin2 <= end2)
{
if (a[begin1] <= a[begin2])
{
tmp[i++] = a[begin1++];
}
else
{
tmp[i++] = a[begin2++];
}
}
while (begin1 <= end1)
{
tmp[i++] = a[begin1++];
}
while (begin2 <= end2)
{
tmp[i++] = a[begin2++];
}
memcpy(a + begin, tmp + begin, sizeof(int) * (end - begin + 1));
}
void TestOP()
{
srand(time(0));
const int N = 1000000;
int* a1 = (int*)malloc(sizeof(int) * N);
for (int i = 0; i < N; ++i)
{
a1[i] = rand();
}
int begin1 = clock();
MergeSort(a1, N);
int end1 = clock();
printf("MergeSort:%d\n", end1 - begin1);
free(a1);
}
int main()
{
TestMergeSort();
TestOP();
return 0;
}
该代码实现了归并排序算法。归并排序是一种分治算法,首先将原始数组递归地分成两个子数组,然后对子数组进行排序,最后将排序好的子数组合并成一个有序数组。
代码中的MergeSort函数是对外接口,用于调用归并排序算法。首先申请了一个临时数组tmp,用于存放归并过程中的临时结果。然后调用_MergeSort函数进行实际的归并排序操作。
_MergeSort函数是核心函数,用于实现归并排序的递归过程。首先判断递归结束的条件,即如果begin和end相等,则只有一个元素,不需要排序。然后找到中间位置mid,将原数组分成两个子数组并分别递归调用_MergeSort函数进行排序。
接下来是合并过程,使用四个指针begin1、begin2、end1和end2分别指向两个子数组的起始和结束位置。然后使用指针i遍历临时数组tmp。比较两个子数组的元素大小,将较小的元素放入tmp数组中,并将对应指针向后移动。直到有一个子数组遍历完毕,将另一个子数组中的剩余元素依次放入tmp数组。
最后,使用memcpy函数将临时数组tmp中的元素拷贝回原数组a中,完成排序。
五、非递归实现归并排序
#include<stdio.h>
#include<stdlib.h>
#include <string.h>
#include<time.h>
void MergeSort(int* a, int n);
void _MergeSort(int* a, int begin, int end, int* tmp);
void MergeSortNonR(int* a, int n);
void PrintArray(int* a, int n);
void TestMergeSortNonR()
{
int a[] = { 5, 13, 9, 16, 12, 4, 7, 1, 28, 25, 3, 9, 6, 2, 4, 7, 1, 8 };
//int a[] = { 5, 3, 9, 6, 2, 4, 7, 1, 8 };
PrintArray(a, sizeof(a) / sizeof(int));
MergeSortNonR(a, sizeof(a) / sizeof(int));
PrintArray(a, sizeof(a) / sizeof(int));
}
void PrintArray(int* a, int n)
{
for (int i = 0; i < n; i++)
{
printf("%d ", a[i]);
}
printf("\n");
}
void MergeSortNonR(int* a, int n)
{
int* tmp = malloc(sizeof(int) * n);
if (tmp == NULL)
{
perror;
return;
}
int gap = 1;
while (gap < n)
{
for (int i = 0; i < n; i = i+ 2* gap)
{
int begin1 = i, end1 = i + gap - 1, begin2 = i + gap , end2 = begin2 + gap - 1;
if (end1 >= n || begin2 >= n)
break;
if (end2 >= n)
end2 = n - 1;
int j = i;
while (begin1 <= end1 && begin2 <= end2)
{
if (a[begin1] <= a[begin2])
{
tmp[j++] = a[begin1++];
}
else
{
tmp[j++] = a[begin2++];
}
}
while (begin1 <= end1)
{
tmp[j++] = a[begin1++];
}
while (begin2 <= end2)
{
tmp[j++] = a[begin2++];
}
memcpy(a + i, tmp + i, sizeof(int) * (end2 - i + 1));
}
gap *= 2;
}
}
void TestOP1()
{
srand(time(0));
const int N = 1000000;
int* a1 = (int*)malloc(sizeof(int) * N);
for (int i = 0; i < N; ++i)
{
a1[i] = rand();
}
int begin1 = clock();
MergeSortNonR(a1, N);
int end1 = clock();
printf("MergeSortNonR:%d\n", end1 - begin1);
free(a1);
}
int main()
{
TestMergeSortNonR();
TestOP1();
return 0;
}
这段代码是用来实现非递归的归并排序算法。归并排序是一种分治算法,通过将数组分成两个部分,分别对这两个部分进行排序,然后将排好序的两个部分合并起来。
在代码中,首先创建一个临时数组tmp,用来在合并过程中暂存排序后的结果。然后定义一个变量gap作为当前的步长,初始时为1。通过一个循环,每次将gap乘以2,直到gap大于等于n。在循环中,通过两个内嵌的循环,将数组分成若干个子数组,并进行两两合并。
内层循环中,先计算出两个待合并的子数组的起始和结束位置,然后对这两个子数组进行合并操作。合并过程中,比较两个子数组中的元素,将较小的元素放入临时数组tmp中,并移动对应子数组的指针。最后,将tmp中的结果拷贝回原始数组a中。
整体的时间复杂度为O(nlogn),空间复杂度为O(n)。由于该排序算法是稳定的,所以适用于各种类型的数据排序。