在篇我们将详细学习如何使用预训练的BERT模型。首先,我们将了解谷歌对外公开的预训练的BERT模型的不同配置。然后,我们将学习如何使用预训练的BERT模型作为特征提取器。此外,我们还将探究Hugging Face的Transformers库,学习如何使用Transformers库从预训练的BERT模型中提取嵌入。
接着,我们将了解如何从BERT的编码器层中提取嵌入,并学习如何为下游任务微调预训练的BERT模型。我们先学习为文本分类任务微调预训练的BERT模型,然后学习使用Transformers库微调BERT模型以应用于情感分析任务。最后,我们将学习如何将预训练的BERT模型应用于自然语言推理任务、问答任务以及命名实体识别等任务。
1、预训练的BERT模型
在前面,我们学习了如何使用掩码语言模型构建任务和下句预测任务对BERT模型进行预训练。但是,从头开始预训练BERT模型是很费算力的。因此,我们可以下载预训练的BERT模型并直接使用。谷歌对外公开了其预训练的BERT模型,我们可以直接从其GitHub仓库中下载。谷歌发布了各种配置的预训练BERT模型,如图所示。L表示编码器的层数,H表示隐藏神经元的数量(特征大小)。
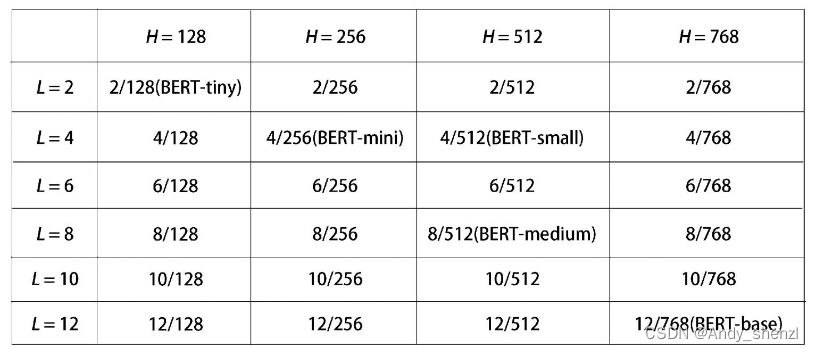
预训练模型可以使用不区分大小写(BERT-uncased)的格式和区分大小写(BERT-cased)的格式。在不区分大小写时,所有标记都转化为小写;在区分大小写时,标记大小写不变,直接用于训练。我们应该使用哪个预训练的BERT模型?是不区分大小写,还是区分大小写?不区分大小写的模型是最常用的模型,但如果我们正在执行某些任务,比如命名实体识别(named entity recognition, NER),则必须保留大小写,使用区分大小写的模型。除此之外,谷歌还发布了使用全词掩码方法训练的预训练BERT模型。
我们可以将预训练模型应用于以下两种场景:
- 作为特征提取器,提取嵌入;
- 针对文本分类任务、问答任务等下游任务对预训练的BERT模型进行微调。
下面,我们将学习如何使用预训练的BERT模型作为特征提取器来提取嵌入,然后详细学习如何为下游任务微调预训练的BERT模型。
2、从预训练的BERT模型中提取嵌入
让我们通过一个例子来学习如何从预训练的BERT模型中提取嵌入。以I love Paris这个句子为例,假设需要提取句子中每个词的上下文嵌入。我们首先需要对句子进行标记,并将这些标记送入预训练的BERT模型,该模型将返回每个标记的嵌入。除了获得标记级(词级)的特征外,还可以获得句级的特征。
下面,让我们详细了解一下到底如何从预训练的BERT模型中提取词级嵌入和句级嵌入。
假设需要执行一项情感分析任务,其样本数据集如图所示。
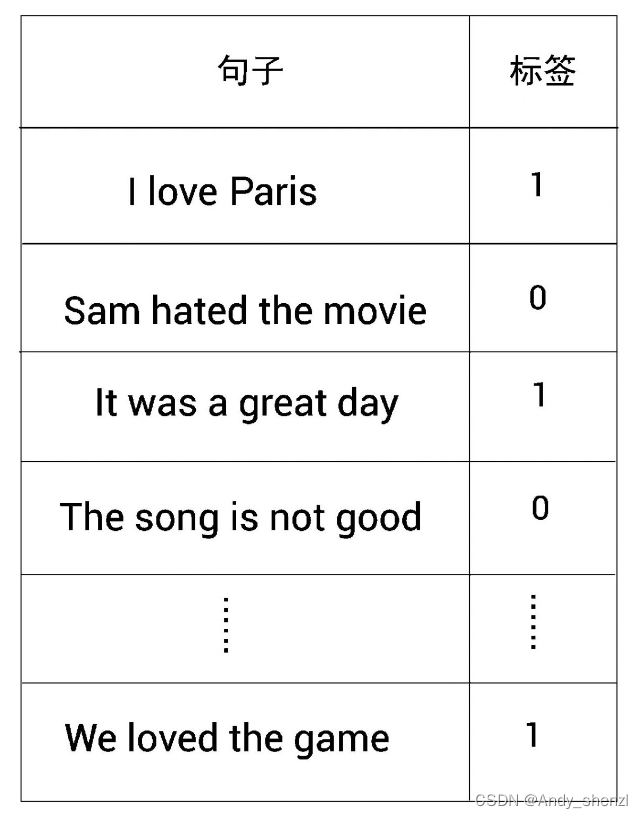
从图中可以看到几个句子及其对应的标签,其中1表示正面情绪,0表示负面情绪。我们可以利用给定的数据集训练一个分类器,对句子所表达的情感进行分类。
但是,我们不能把数据集直接输入分类器。因为数据集包含文本,所以我们需要对文本进行向量化。TF-IDF、word2vec等算法或模型可以对文本进行向量化。但在前面,我们了解到BERT学习的是上下文嵌入,这与word2vec等无上下文嵌入的模型不同。所以,我们将学习如何使用预训练的BERT模型对数据集中的句子进行向量化。
首先,我们来看数据集中的第一句话,即I love Paris。我们使用WordPiece对句子进行分词,并得到标记(单词),如下所示。
tokens = [I, love, Paris]
然后,在开头添加[CLS]标记,在结尾添加[SEP]标记,如下所示。
tokens = [ [CLS], I, love, Paris, [SEP] ]
以此类推,我们对训练集中的所有句子进行标记。但因为每个句子的长度不同,所以标记的长度也不同。为了保持所有标记的长度一致,我们将数据集中的所有句子的标记长度设为7。句子I love Paris的标记长度是5,为了使其长度为7,需要添加两个标记来填充,即[PAD]。因此,新标记如下所示。
tokens = [ [CLS], I, love, Paris, [SEP], [PAD], [PAD] ]
添加两个[PAD]标记后,标记的长度达到所要求的7。下一步,要让模型理解[PAD]标记只是为了匹配标记的长度,而不是实际标记的一部分。为了做到这一点,我们需要引入一个注意力掩码。我们将所有位置的注意力掩码值设置为1,将[PAD]标记的位置设置为0,如下所示。
attention_mask = [ 1, 1, 1, 1, 1, 0, 0]
然后,将所有的标记映射到一个唯一的标记ID。假设映射的标记ID如下所示。
token_ids = [101, 1045, 2293, 3000, 102, 0, 0]
ID 101表示标记[CLS],1045表示标记I,2293表示标记love,以此类推。
现在,我们把token_ids和attention_mask一起输入预训练的BERT模型,并获得每个标记的特征向量(嵌入)。通过代码,我们可以进一步理解以上步骤。
下图显示了如何使用预训练的BERT模型来获得嵌入。为清晰起见,图中显示的是标记而不是标记ID。我们看到,一旦我们将标记作为输入,编码器1就会计算出所有标记的特征,并将其发送给下一个编码器,也就是编码器2。编码器2将编码器1计算的特征作为输入,再计算特征,并将其发送给下一个编码器,也就是编码器3。以这样的方式,每个编码器都会将它的特征发送给下一个编码器。最后的编码器,也就是编码器12,返回句子中所有标记的最终特征(嵌入)。
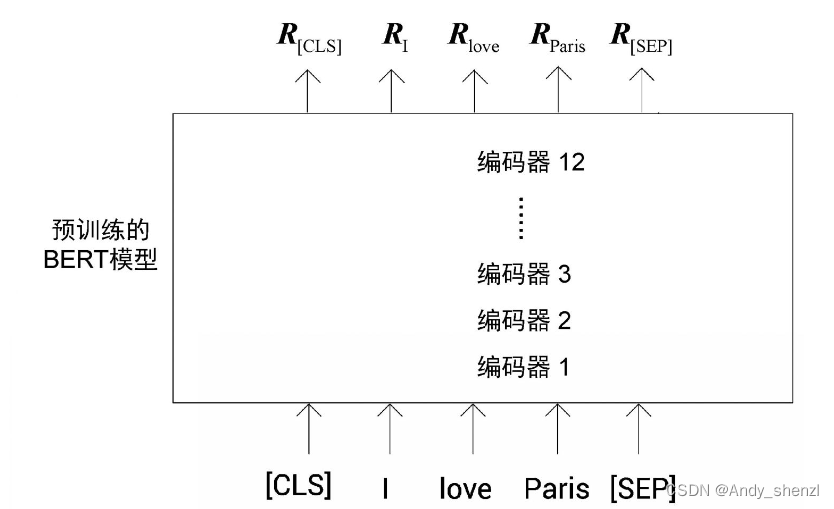
如图,
R
C
L
S
R_{CLS}
RCLS是标记[CLS]的嵌入,
R
I
R_I
RI是标记I的嵌入,
R
l
o
v
e
R_{love}
Rlove是标记love的嵌入,以此类推。这样一来,我们就可以获得每个标记的特征向量。这些特征向量是基于上下文的单词(标记)嵌入。假设使用的是预训练的BERT-base模型配置,那么每个标记的特征向量大小为768。
我们学习了如何获得I love Paris这个句子中每个单词的特征,但是如何获得完整句子的特征呢?
我们已经在句子的开头预留了[CLS]标记,它的特征将代表整个句子的总特征。因此,其他标记的嵌入可以忽略,而只用[CLS]标记的嵌入作为句子的特征。也就是说,句子I love Paris的特征可以用[CLS]标记的特征 R C L S R_{CLS} RCLS来表示。
采用类似的方法,可以计算出训练集中所有句子的特征向量。一旦有了训练集中所有句子的特征,就可以把这些特征作为输入,训练一个分类器来完成情感分析任务了。
请注意,使用[CLS]标记的特征代表整个句子的特征并不总是一个好主意。要获得一个句子的特征,最好基于所有标记的特征进行平均或者汇聚。在后面的章节中,我们将了解更多这方面的知识。
2.1 Hugging Face的Transformers库
Hugging Face是一个致力于通过自然语言将AI技术大众化的组织。它的开源Transformers库在自然语言处理社区中非常受欢迎,尤其对一些自然语言处理任务和自然语言理解(natural language understanding, NLU)任务非常有效。Transformers库包括100多种语言的数千个预训练模型,其优势之一是它与PyTorch和TensorFlow都兼容。
我们可以直接使用pip安装Transformers库,如下所示。
pip install Transformers==3.5.1
2.2 BERT嵌入的生成
如何从预训练的BERT模型中提取嵌入?
同样,我们以I love Paris这句话为例,看看如何使用Hugging Face的Transformers库中的预训练BERT模型为句子中的所有单词获得基于上下文的嵌入。
首先,导入必要的库模块,如下所示。
from transformers import BertModel, BertTokenizer
import torch
接下来,下载预训练的BERT模型。这里使用的是不区分大小写的模型bert-base-uncased。顾名思义,它是以BERT为基础的模型,有12个编码器,并且是用小写的标记来训练的。由于使用的是BERT-base,因此特征向量的大小是768。
下载并加载预训练的模型。
model = BertModel.from_pretrained('bert-base-uncased')
然后,下载并加载用于预训练模型的词元分析器。
tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
下面,让我们看看如何对输入进行预处理。
2.2.1 对输入进行预处理
假设输入句如下所示。
sentence = 'I love Paris'
对该句进行分词,并获得标记,如下所示。
tokens = tokenizer.tokenize(sentence)
打印这些标记。
print(tokens)
以上代码的输出如下所示。
['i', 'love', 'paris']
现在,将[CLS]标记加在前面,将[SEP]标记加在后面,如下所示。
tokens = ['[CLS]'] + tokens + ['[SEP]']
查看更新后的标记。
print(tokens)
输出如下。
['[CLS]', 'i', 'love', 'paris', '[SEP]']
我们可以看到,标记列表的开头处有一个[CLS]标记,其结尾处有一个[SEP]标记,且标记长度为5。
假设需要将标记长度设为7,那么需要在列表最后添加两个[PAD]标记来满足长度要求,如下所示。
tokens = tokens + ['[PAD]'] + ['[PAD]']
打印更新后的标记列表。
print(tokens)
输出如下。
['[CLS]', 'i', 'love', 'paris', '[SEP]', '[PAD]', '[PAD]' ]
如上所示,现在我们有一个带有[PAD]标记的标记列表,且标记长度为7。
接下来,需要创建注意力掩码。如果标记不是[PAD],那么将注意力掩码值设置为1,否则我们将其设置为0,如下所示。
attention_mask = [1 if i!= '[PAD]' else 0 for i in tokens]
打印attention_mask。
print(attention_mask)
输出如下。
[1, 1, 1, 1, 1, 0, 0]
可以看出,在有[PAD]标记的位置,注意力掩码值为0,在其他位置为1。
接下来,将所有标记转换为它们的标记ID,如下所示。
token_ids = tokenizer.convert_tokens_to_ids(tokens)
看一下token_ids的值。
print(token_ids)
输出如下。
[101, 1045, 2293, 3000, 102, 0, 0]
可以看到,每个标记都被映射到不同的标记ID。
现在,将token_ids和attention_mask转换为张量,如下所示。
token_ids = torch.tensor(token_ids).unsqueeze(0)
attention_mask = torch.tensor(attention_mask).unsqueeze(0)
下面,我们就可以将token_ids和attention_mask输入到预训练的BERT模型中,并得到嵌入向量。
2.2.2 获得嵌入向量
如以下代码所示,我们将token_ids和attention_mask送入模型,并得到嵌入向量。需要注意,model返回的输出是一个有两个值的元组。第1个值hidden_rep表示隐藏状态[插图]的特征,它包括从顶层编码器(编码器12)获得的所有标记的特征。第2个值cls_head表示[CLS]标记的特征。
hidden_rep, cls_head = model(token_ids, attention_mask = attention_mask, return_dict=False)
在上面的代码中,hidden_rep包含了输入中所有标记的嵌入(特征)。打印一下hidden_rep的大小。
print(hidden_rep.shape)
输出如下。
torch.Size([1, 7, 768])
数组[1, 7, 768]表示[batch_size, sequence_length, hidden_size],也就是说,批量大小设为1,序列长度等于标记长度,即7。因为有7个标记,所以序列长度为7。隐藏层的大小等于特征向量(嵌入向量)的大小,在BERT-base模型中,其为768。
得到每个标记的特征向量的方法如下。
- hidden_rep[0][0]给出了第1个标记[CLS]的特征。
- hidden_rep[0][1]给出了第2个标记I的特征。
- hidden_rep[0][2]给出了第3个标记love的特征。
通过这种方式,可以获得所有标记的上下文特征,这基本上等同于句子中所有单词的上下文嵌入向量。
现在,让我们查看一下cls_head,它包含[CLS]标记的特征。打印cls_head的大小。
print(cls_head.shape)
输出如下。
torch.Size([1, 768])
大小[1, 768]表示[batch_size, hidden_size]。
我们知道cls_head持有句子的总特征,所以,可以用cls_head作为句子I love Paris的整句特征。
2.3 从BERT的所有编码器层中提取嵌入
我们学习了如何从预训练的BERT模型的顶层编码器提取嵌入。除此之外,我们也应该考虑从所有的编码器层获得嵌入。
下面,让我们来探讨这个问题。我们用 h 0 h_0 h0表示输入嵌入层,用 h 1 h_1 h1表示第1个编码器层(第1个隐藏层),用 h 2 h_2 h2表示第2个编码器层(第2个隐藏层),以此类推,一直到最后的第12个编码器层,即 h 1 2 h_12 h12,如图所示。
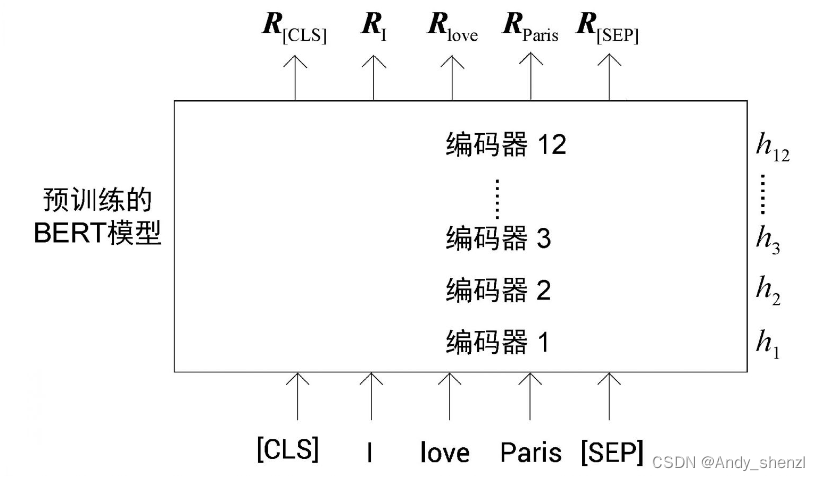
BERT的研究人员尝试了从不同的编码器层中提取嵌入。例如,对于命名实体识别任务,研究人员使用预训练的BERT模型来提取特征。他们没有只使用来自顶层编码器(最后的隐藏层)的嵌入作为特征,而是尝试使用来自其他编码器层(其他的隐藏层)的嵌入作为特征,所得到的F1分数如图所示。
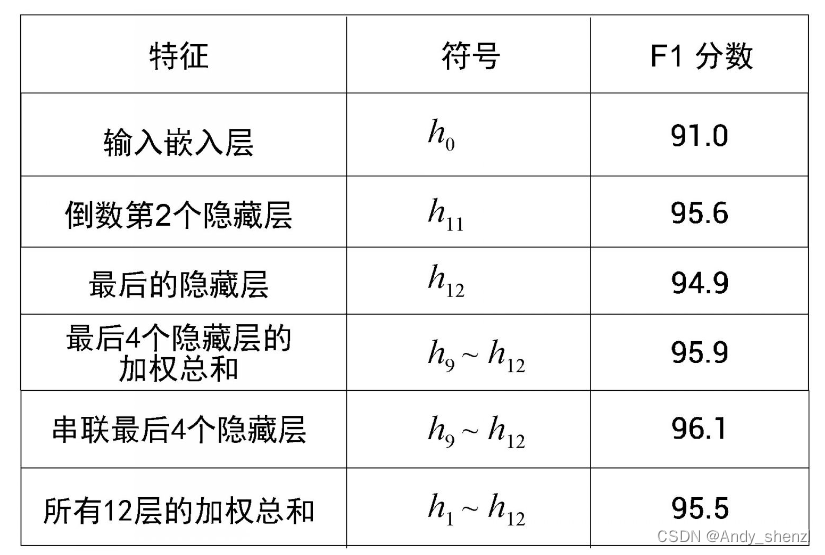
从图中可以看到,将最后4个编码器层(最后4个隐藏层)的嵌入连接起来可以得到最高的F1分数,即96.1。这说明可以使用其他编码器层的嵌入,而不只是提取顶层编码器(最后的隐藏层)的嵌入。
下面,我们将学习如何使用Transformers库从所有编码器层中提取嵌入。
3.1 提取嵌入
首先,我们导入必要的库模块。
from transformers import BertModel, BertTokenizer
import torch
接下来,下载预训练的BERT模型和词元分析器。可以看到,在下载预训练的BERT模型时,需要设置output_hidden_states = True。将此设置为True将允许我们从所有编码器层获得嵌入。
model = BertModel.from_pretrained('bert-base-uncased',
output_hidden_states = True)
tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
3.2 对模型输入进行预处理
我们还是以句子I love Paris为例,对该句进行标记。在句子开头添加[CLS]标记,在结尾添加[SEP]标记。
sentence = 'I love Paris'
tokens = tokenizer.tokenize(sentence)
tokens = ['[CLS]'] + tokens + ['[SEP]']
假设还是将标记长度设置为7,那么需要添加[PAD]标记并定义注意力掩码。
tokens = tokens + ['[PAD]'] + ['[PAD]']
attention_mask = [1 if i!= '[PAD]' else 0 for i in tokens]
接下来,将标记转换成标记ID。
token_ids = tokenizer.convert_tokens_to_ids(tokens)
然后,把token_ids和attention_mask转换成张量。
token_ids = torch.tensor(token_ids).unsqueeze(0)
attention_mask = torch.tensor(attention_mask).unsqueeze(0)
现在,我们已经对输入进行了预处理。下面,让我们来获取嵌入。
3.3 获取嵌入
在定义模型时,我们设置了output_hidden_states = True,以获得所有编码器层的嵌入。模型返回一个含有3个值的输出元组,如下所示。
last_hidden_state, pooler_output, hidden_states = \
model(token_ids, attention_mask = attention_mask)
上面的代码体现了以下内容。
- last_hidden_state包含从最后的编码器(编码器12)中获得的所有标记的特征。
- pooler_output表示来自最后的编码器的[CLS]标记的特征,它被一个线性激活函数和tanh激活函数进一步处理。
- hidden_states包含从所有编码器层获得的所有标记的特征。
下面,让我们逐一了解每个值。首先来看last_hidden_state,它仅有从最后的编码器(编码器12)中获得的所有标记的特征。让我们看看它的大小。
print(last_hidden_state.shape)
输出如下。
torch.Size([1, 7, 768])
数组[1, 7, 768]表示[batch_size, sequence_length, hidden_size],其表明批量大小为1,序列长度等于标记长度,即7。隐藏层的大小等于特征向量(嵌入向量)的大小,在BERT-base模型中,其大小为768。
每个标记的嵌入如下所示。
- last_hidden_state[0][0]给出了第1个标记[CLS]的特征。
- last_hidden_state[0][1]给出了第2个标记I的特征。
- last_hidden_state[0][2]给出了第3个标记love的特征。
同样,我们可以从顶层编码器获得所有标记的特征。
下面来看pooler_output,它包含来自最后的编码器的[CLS]标记的特征,并将被线性激活函数和tanh激活函数进一步处理。来看pooler_output的大小。
print(pooler_output.shape)
输出如下。
torch.Size([1, 768])
数组[1, 768]表示[batch_size, hidden_size]。
前面已知,[CLS]标记持有该句子的总特征,因此,可以用pooler_output作为I love Paris这个句子的特征。
最后,hidden_states包含从所有编码器层获得的所有标记的特征。它是一个包含13个值的元组,含有所有编码器层(隐藏层)的特征,即从输入嵌入层 h 0 h_0 h0到最后的编码器层 h 12 h_{12} h12。
len(hidden_states)
以上代码的输出如下。
13
可以看到,它包含13个值,具有所有编码器层的特征。
- hidden_states[0]包含从输入嵌入层 h 0 h_0 h0获得的所有标记的特征。
- hidden_states[1]包含从第1个编码器层 h 1 h_1 h1获得的所有标记的特征。
- hidden_states[2]包含从第2个编码器层 h 2 h_2 h2获得的所有标记的特征。
- hidden_states[12]包含从最后一个编码器层 h 12 h_{12} h12获得的所有标记的特征。
让我们进一步了解。首先,打印hidden_states[0]的大小,它包含从输入嵌入层[插图]获得的所有标记的特征。
print(hidden_states[0].shape)
输出如下。
torch.Size([1, 7, 768])
数组[1, 7, 768]表示[batch_size, sequence_length, hidden_size]。
然后,打印hidden_states[1]的大小,它包含从第1个编码器层[插图]获得的所有标记的特征。
print(hidden_states[1].shape)
通过这种方式,我们就可以获得所有编码器层的标记嵌入。