目录
一DDL
1.1数据库操作
1.1.1查询所有数据库:
1.1.2创建数据库
1.1.3 使用数据库
1.1.4 删除数据库
1.2表操作
1.2.1表操作
1.2.1.1创建表
1.2.1.1.1约束
1.2.1.1.2 数据类型
1.2.1.1.2.1 数值类型
1.2.1.1.2.2 字符串类型
1.2.1.1.2.3日期类型
1.2.1.1.2图形化工具创建表
1.2.2查询表
1.2.2.3查询建表语句的图形化操作
1.2.3修改表结构
编辑
编辑 编辑1.2.4删除表结构
二DML
2.1添加数据(INSERT)
2.2修改数据 (UPDATE)
2.3删除数据(delete)
三DQL
3.1 基本查询
3.2条件查询
3.3分组查询
3.3.1聚合函数
3.4排序查询
3.5分页查询

一DDL
1.1数据库操作
1.1.1查询所有数据库:
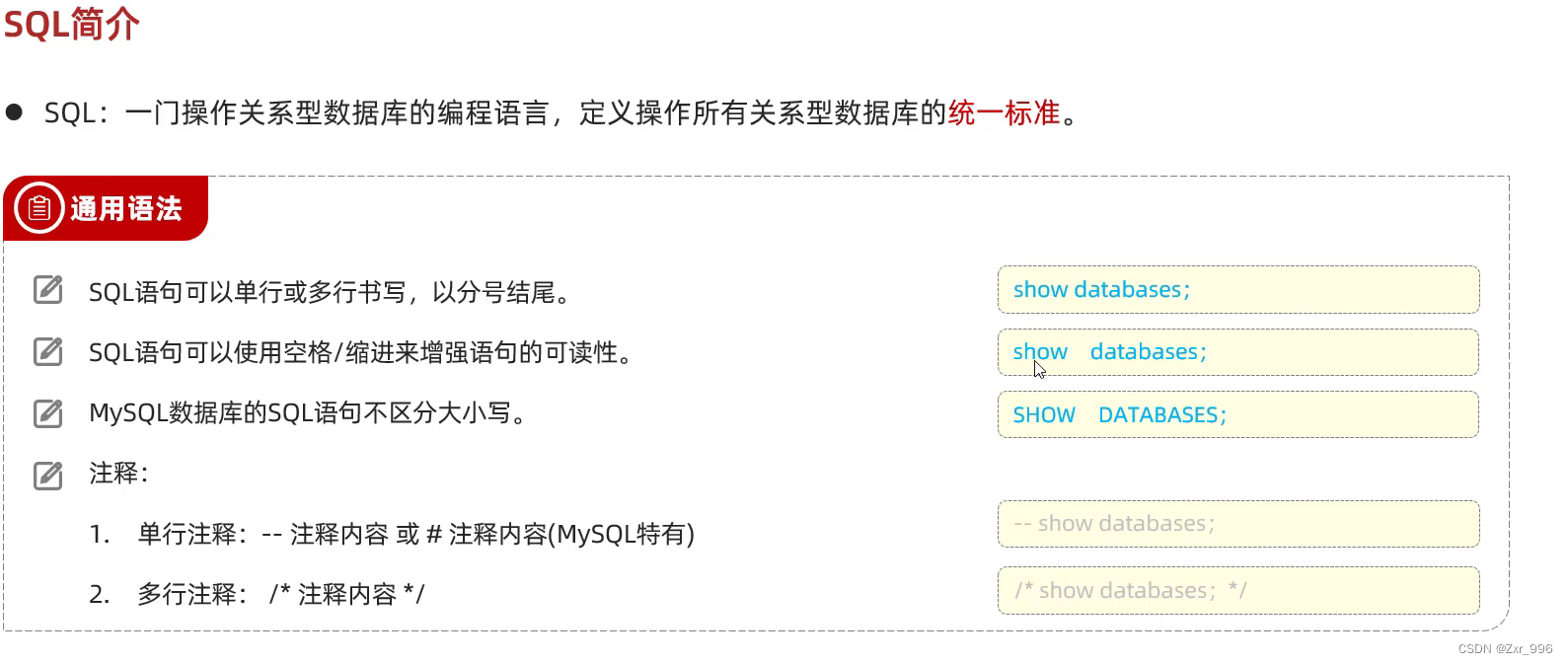
show databases;
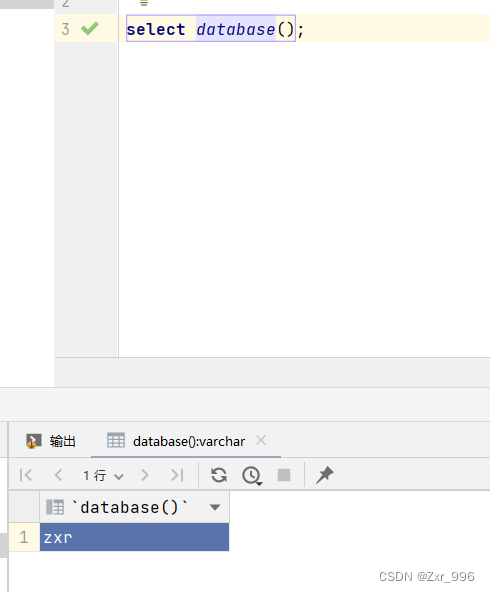
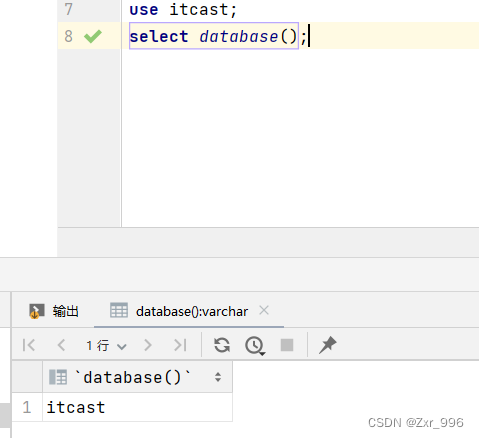
通过指令:select database() ,就可以查询到当前所处的数据库
1.1.2创建数据库
create database itcast;创建一个 itcast 数据库。
1.1.3 使用数据库
use 数据库名;
我们要操作某一个数据库下的表时,就需要通过该指令,切换到对应的数据库下,否则不能操作。
1.1.4 删除数据库
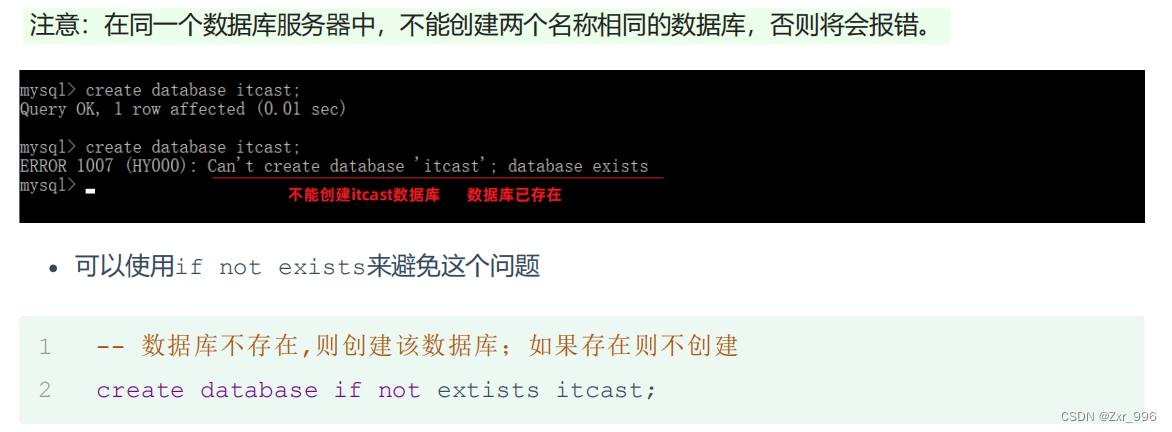
drop database [if exists] 数据库名;
如果删除一个不存在的数据库,将会报错。可以加上参数 if exists ,如果数据库存在,再执行删除,否则不执行删除。
drop database if exists itcast; -- itcast数据库存在时删除
1.2表操作
1.2.1表操作
1.2.1.1创建表
create table 表名 (字段 1 字段 1 类型 [ 约束 ] [ comment 字段 1 注释 ] ,字段 2 字段 2 类型 [ 约束 ] [ comment 字段 2 注释 ] ,......字段 n 字段 n 类型 [ 约束 ] [ comment 字段 n 注释 ]) [ comment 表注释 ] ;
create table ta_user(
id int comment 'ID,唯一标识',
username varchar(20) comment '用户名字',
name varchar(10) comment '姓名',
age int comment '年龄',
gender char(1) comment '性别'
)comment '用户表';1.2.1.1.1约束
概念:所谓约束就是作用在表中字段上的规则,用于限制存储在表中的数据。作用:就是来保证数据库当中数据的正确性、有效性和完整性。在 MySQL 数据库当中,提供了以下 5 种约束:
| 约束 | 描述 | 关键字 |
|---|---|---|
|
非空约束
|
限制该字段值不能为
null
| not null |
|
唯一约束
|
保证字段的所有数据都是唯一、不重复的
|
unique
|
|
主键约束
|
主键是一行数据的唯一标识,要求非空且唯一
| primary key |
|
默认约束
|
保存数据时,如果未指定该字段值,则采用默认值
|
aa
|
|
外键约束
|
让两张表的数据建立连接,保证数据的一致性和完整性
|
foreign key
|
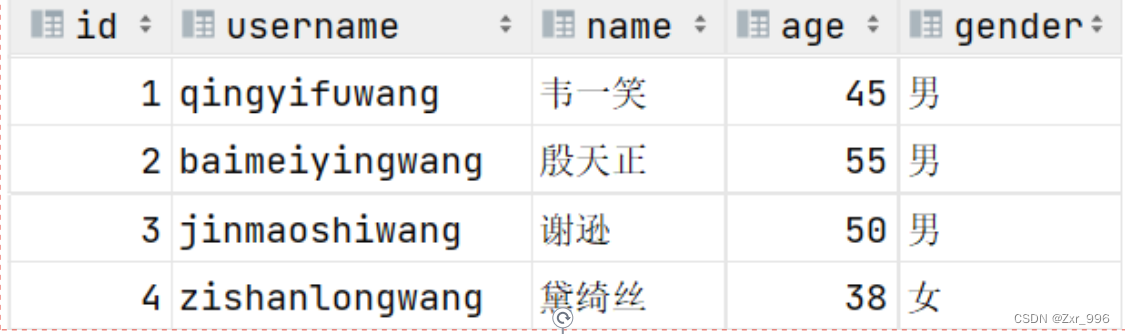
- id 是一行数据的唯一标识
- username 用户名字段是非空且唯一的
- name 姓名字段是不允许存储空值的
- gender 性别字段是有默认值,默认为男
![]()
create table ta_user(
id int primary key auto_increment comment 'ID,唯一标识',
username varchar(20) not null unique comment '用户名字',
name varchar(10) not null comment '姓名',
age int comment '年龄',
gender char(1) default '男' comment '性别'
)comment '用户表';1.2.1.1.2 数据类型
1.2.1.1.2.1 数值类型

举例子:分数 --- 总分 100 分 , 最多出现一位小数score double ( 4 , 1 )年龄字段 --- 不会出现负数 , 而且人的年龄不会太大age tinyintunsigned
1.2.1.1.2.2 字符串类型
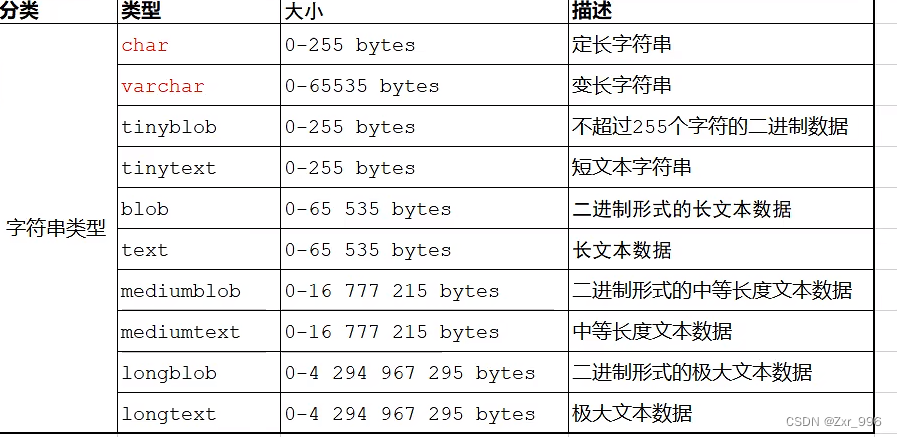
char 与 varchar 都可以描述字符串,char 是定长字符串,指定长度多长,就占用多少个字符,和字段值的长度无关。varchar 是变长字符串,指定的长度为最大占用长度。相对来说, char 的性能会更高些。char性能高,浪费空间varchar 性能低,节省空间
例子:用户名 username --- 长度不定 , 最长不会超过 50username varchar ( 50 )手机号 phone --- 固定长度为 11phone char ( 11 )
1.2.1.1.2.3日期类型

生日字段 birthday ---生日只需要年月日
birthday date创建时间 createtime --- 需要精确到时分秒createtime datetime
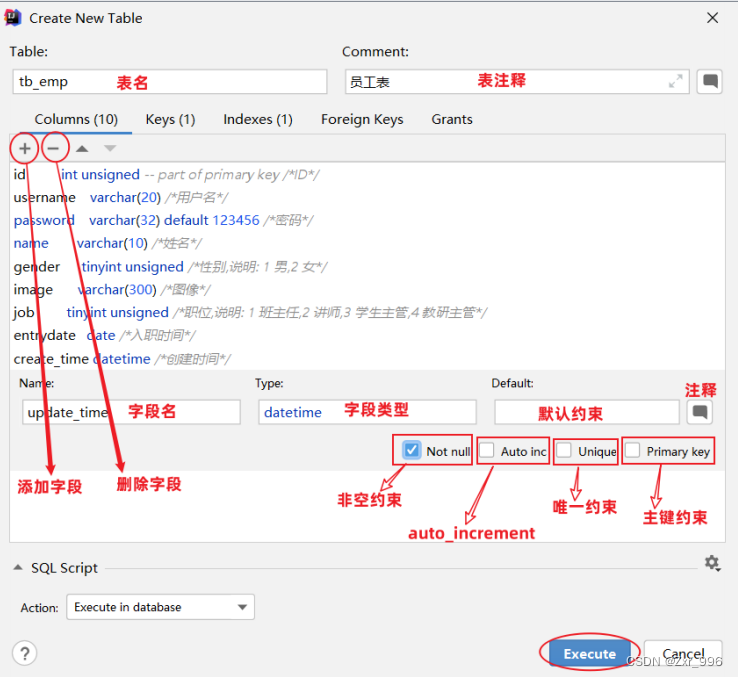
1.2.1.1.2图形化工具创建表

1.2.2查询表

show tables;查询当前数据库所有表
desc ta_user;查询表结构
show create table ta_user;查询建表语句
1.2.2.3查询建表语句的图形化操作
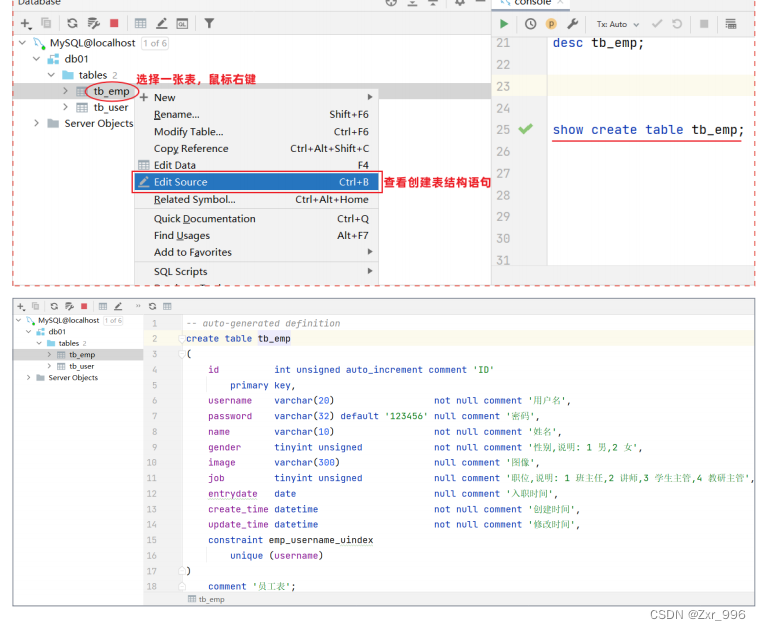
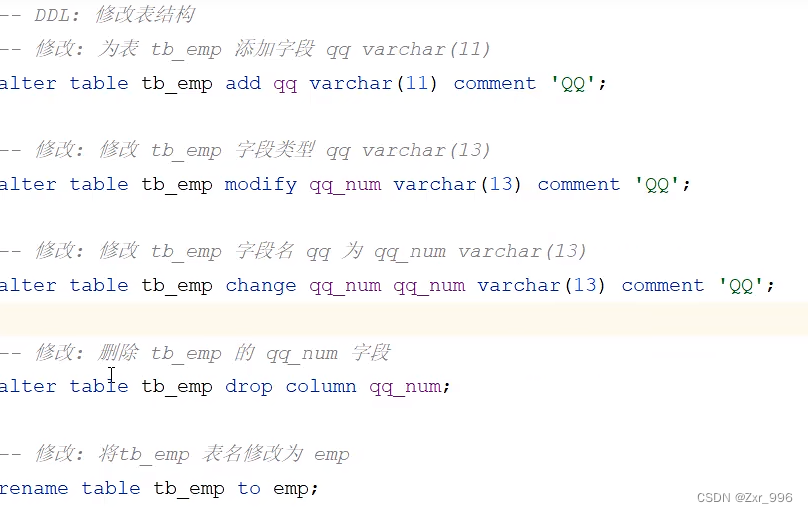
1.2.3修改表结构
关于表结构的修改操作,工作中一般都是直接基于图形化界面操作。

 1.2.4删除表结构
1.2.4删除表结构
drop table if exists 表名;在删除表时,表中的全部数据也会被删除。
二DML
DML 英文全称是 Data Manipulation Language( 数据操作语言 ) ,用来对数据库中表的数据记录进行增、删、改操作添加数据( INSERT )修改数据( UPDATE )删除数据( DELETE )
2.1添加数据(INSERT)

insert语法:
- 向指定字段添加数据
insert into ta_user(id,username,name) values(1,'zxr','zxr'); - 全部字段添加数据
insert into ta_user values (2,'zxr1','zxr1',20,'男');- 批量添加数据(指定字段)
insertinto tb_emp(username, name, gender, create_time, update_time)values('weifuwang','韦一笑',1, now(), now()),('fengzi','张三疯',1, now(), now());- 批量添加数据(全部字段)
insert into ta_user values (3,'zxr2','zxr2',20,'男'),(4,'zxr3','zxr3',20,'男')注意事项
1. 插入数据时,指定的字段顺序需要与值的顺序是一一对应的。2. 字符串和日期型数据应该包含在引号中。3. 插入的数据大小,应该在字段的规定范围内。
2.2修改数据 (UPDATE)
update语法:
update表名set字段名1 =值1 ,字段名2 =值2 , .... [where条件];update ta_user set name='张三' where name='zxr1'2.3删除数据(delete)
delete from 表名 where 条件;
注意• DELETE 语句的条件可以有,也可以没有,如果没有条件,则会删除整张表的所有数据。• DELETE 语句不能删除某一个字段的值 ( 可以使用 UPDATE ,将该字段值置为 NULL)• 当进行删除全部数据操作时,会提示询问是否确认删除所有数据,直接点击Execute
三DQL

3.1 基本查询
- 查询多个字段
-- =================== 基本查询 ======================
-- 1. 查询指定字段 name,entrydate 并返回
select name,entrydate from emp ;
-- 2. 查询返回所有字段
-- 方式一: 推荐 , 效率高 . 更直观
select id, username, password, name, gender, image, job, entrydate, create_time, update_time from emp;
-- 方式二:
select * from emp;
-- 3. 查询所有员工的 name,entrydate, 并起别名(姓名、入职日期) --- as 关键字可以省略
select name as '姓名' ,entrydate as '入职日期' from emp ;
select name '姓名' ,entrydate '入职日期' from emp ;
-- 4. 查询员工有哪几种职位(不要重复) -- distinct
select distinct job from emp;
3.2条件查询

案例'2000-01-01' ( 包含 ) 到 '2010-01-01'( 包含 ) 之间的员工信息-- 方式 1 :select id, username, password , name, gender, image, job, entrydate,create_time, update_timefrom tb_empwhere entrydate >= '2000-01-01' and entrydate <= '2010-01-01' ;-- 方式 2 : between...andselect id, username, password , name, gender, image, job, entrydate,create_time, update_timefrom tb_empwhere entrydate between '2000-01-01' and '2010-01-01' ;
案例 :查询 姓名 为两个字的员工信息select id, username, password , name, gender, image, job, entrydate,create_time, update_timefrom tb_empwhere name like '__' ; # 通配符 "_" 代表任意 1 个字符
案例:查询姓张的select id, username, password , name, gender, image, job, entrydate,create_time, update_timefrom tb_empwhere name like ' 张 %' ; # 通配符 "%" 代表任意个字符( 0 个 ~ 多个)
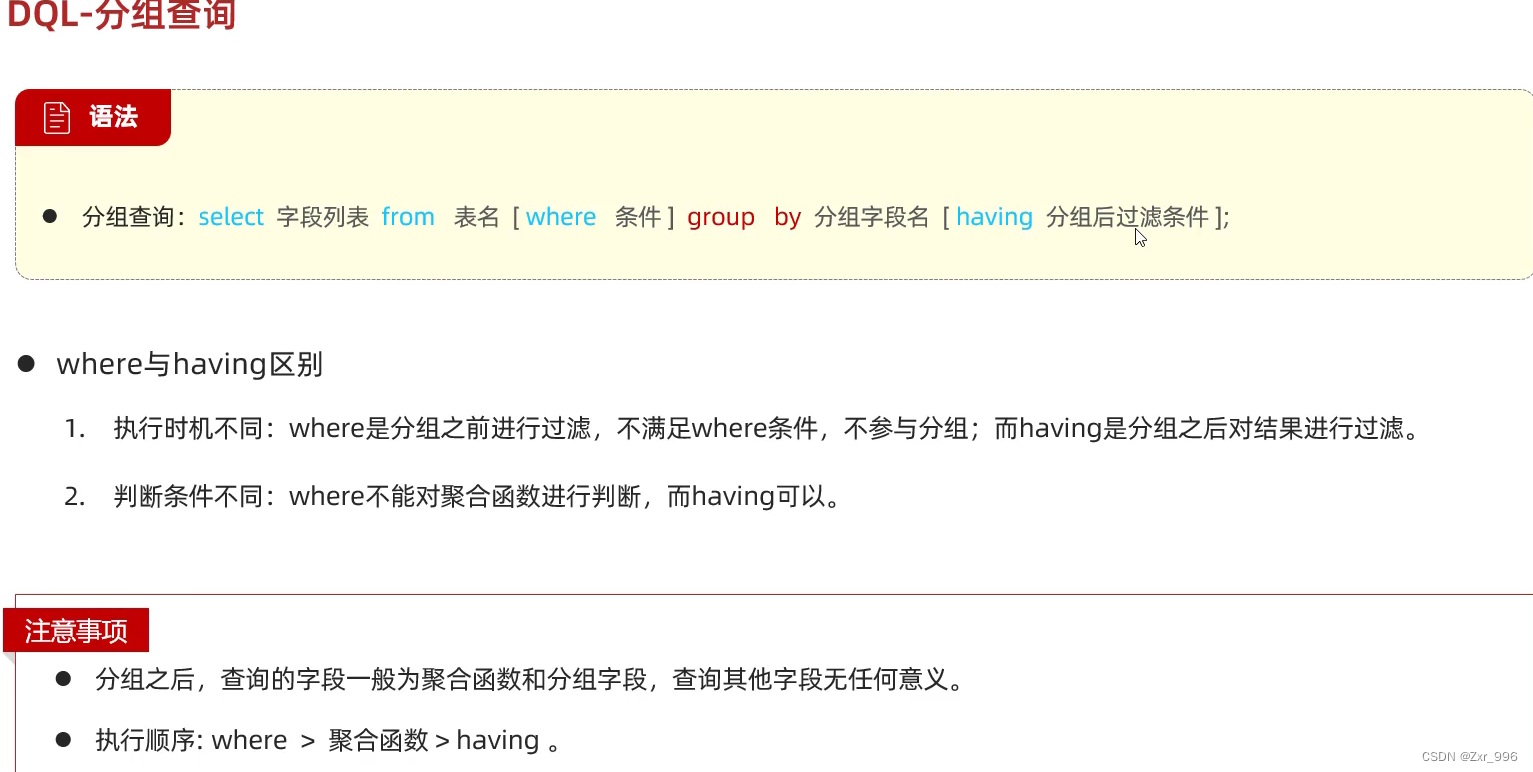
3.3分组查询
分组其实就是按列进行分类 ( 指定列下相同的数据归为一类 ) ,然后可以对分类完的数据进行合并计算。分组查询通常会使用聚合函数进行计算。
3.3.1聚合函数

count :按照列去统计有多少行数据。在根据指定的列统计的时候,如果这一列中有 null 的行,该行不会被统计在其中。
# count(字段)
select count(id) from tb_emp;-- 结果:29
select count(job) from tb_emp;-- 结果:28 (聚合函数对NULL值不做计算)
# count(常量)
select count(0) from tb_emp;
select count('A') from tb_emp;
# count(*) 推荐此写法(MySQL底层进行了优化)
select count(*) from tb_emp;select 字段列表 from 表名 [ where 条件 ] group by 分组字段名 [ having分组后过滤条件 ] ;
案例1:根据性别分组 , 统计男性和女性员工的数量
select gender,count(*) from emp group by gender;
案例 2 :查询入职时间在 '2015-01-01' ( 包含 ) 以前的员工 , 并对结果根据职位分组 , 获取员工数量大于等于 2 的职位。select job,count(*) from emp where job <='2015-01-01'group by job having count(*)>2;
3.4排序查询
select 字段列表from 表名[ where 条件列表 ][ group by 分组字段 ]order by 字段 1 排序方式 1 , 字段 2 排序方式 2 … ;
- ASC :升序(默认值)
- DESC:降序
案例:根据入职时间对公司的员工进行升序排序,入职时间相同,再按照更新时间进行降序排序。
# 根据入职时间对公司的员工进行升序排序,入职时间相同,再按照更新时间进行降序排序 select * from emp order by entrydate asc,update_time desc ;
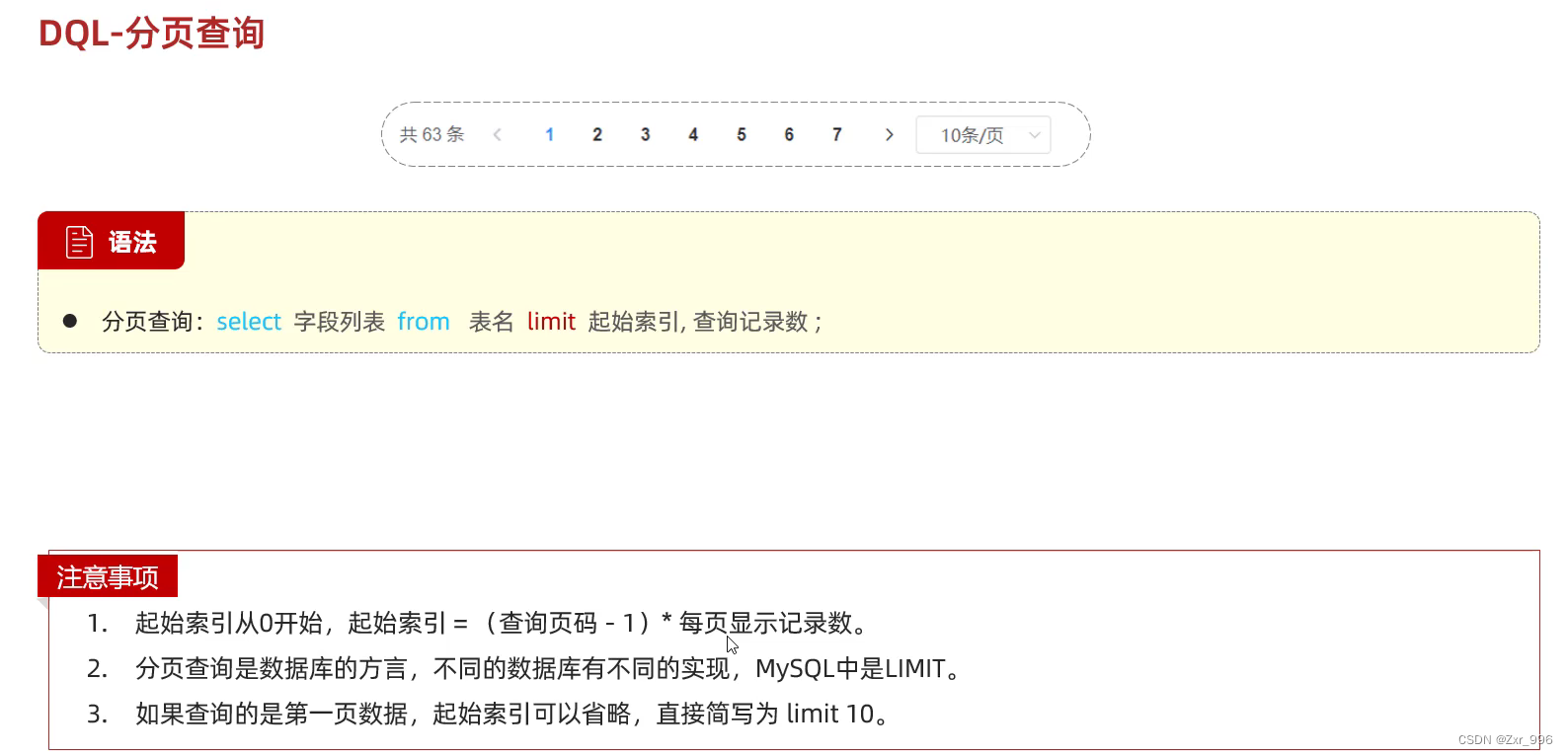
3.5分页查询
语法:
select 字段列表 from 表名 limit 起始索引 , 查询记录数 ;
案例 :查询 第 2 页 员工数据 , 每页展示 5 条记录select id, username, password , name, gender, image, job, entrydate,create_time, update_timefrom tb_emplimit 5 , 5 ; -- 从索引 5 开始,向后取 5 条记录
以上单表查询,下面多表查询:
MYSQL多表设计,多表查询,事务,索引-CSDN博客