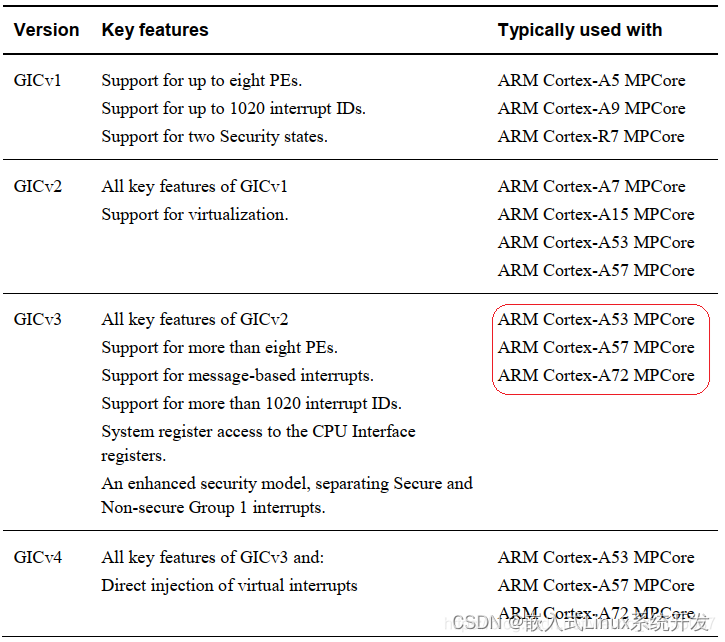
为什么需要RDD
分布式计算需要:
- 分区控制(多台机器并行计算,将一份数据分成多份,在不同机器上执行)
- Shuffle控制(不同分区数据肯定需要进行相关的关联,不同分区进行数据传输叫Shuffle控制)
- 数据存储\序列化\发送
- 数据计算API
- 等一些列功能
这些功能,不能简单的通过Python内置的本机集合对象(如 List\字典)去完成
我们在分布式框架中,需要有一个统一的数据抽象对象,来实现上述分布式计算所需功能。
这个抽象对象,就是RDD。它可以让海量数据在spark集群中进行均等分区,同时分区之间的交互,也就是Shuffle,RDD也提供相应的实现代码。以及数据的存储,在内存中的,在磁盘中的,网络序列化、IO,包括提供一些高级计算API。这些东西RDD都有提供。所以RDD是spark中最重要的一个核心抽象对象。
什么是RDD
RDD概念的诞生来自于一片国外论文
Matei等人提出了RDD这种数据结构

标题翻译过来,弹性分布式数据集:一个在内存集群计算中可以实现高度容错的计算对象。
RDD定义
RDD(Resilient Distributed Dataset)叫做弹性分布式数据集,是Spark中最基本的数据抽象,代表一个不可变、可
分区、里面的元素可并行计算的集合。
- Dataset:一个数据集合,用于存放数据的。
- Distributed:RDD中的数据是分布式存储的,可用于分布式计算。(RDD的数据是跨越机器存储的,也可以是认为跨进程)
- Resilient:RDD中的数据可以存储在内存中或者磁盘中。(可以进行动态扩容,动态缩容。内存和磁盘之间可以相互转移)
RDD 五大特性
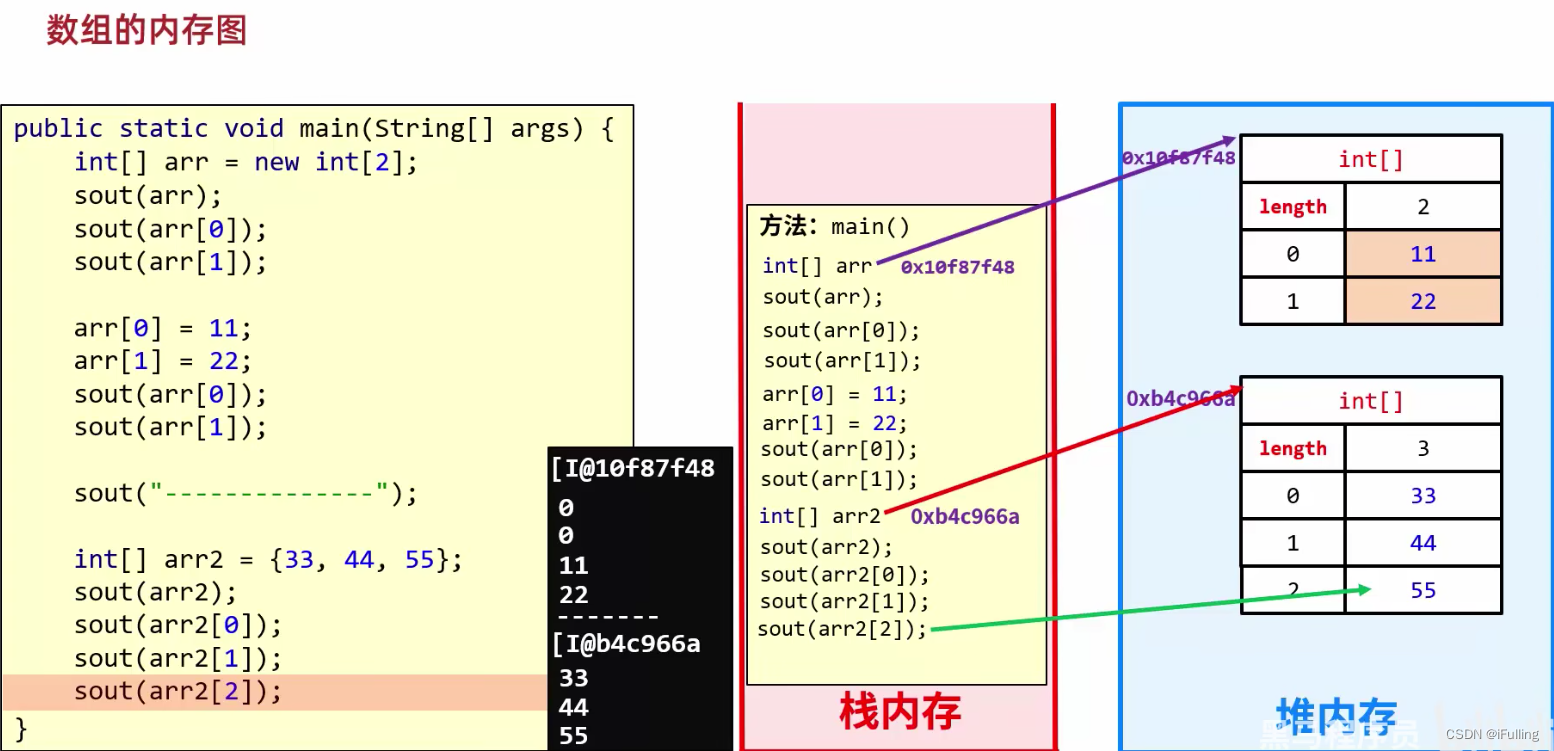
特性1:RDD是有分区的
分区时RDD数据存储的最小单位
一份RDD的数据,本质上是分隔成了多个分区
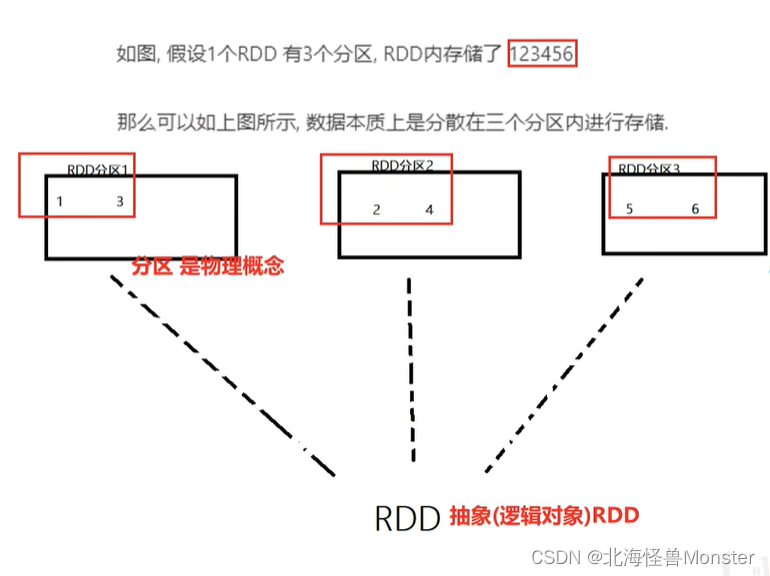
如上图,以三个物理存在的分区,组成了一个逻辑上的RDD对象
这个抽象对象指的是代码里面的RDD对象,但它的底层实体是运行在服务器上的RDD对应的分区
代码演示:
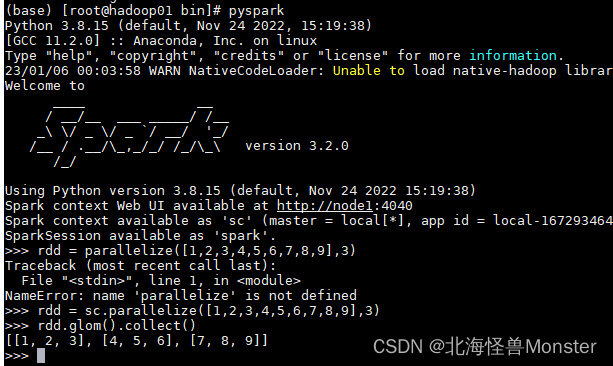
启动spark本机模式进行测试
有个问题记录一下,spark在不读取hadoop上的文件时,是否可以独立运行?因为我刚才没有启动Hadoop,启动spark报错。
网上搜了一堆,结论是:可以的,但是需要特定版本的spark。
还有就是为什么在 spark交互式客户端中写代码,我们需要像前面demo那样创建 SparkContext对象。看截图,因为spark已经为我们创建了。我们只管写executor执行的代码。
以下代码证明了,RDD是分区存储的。
特性2:RDD的方法会作用在其所有分区上
简单的说,虽然数据是分区存储,但是在处理数据时,所有分区数据都会进行处理。也就是说一段代码执行之后,所有分区数据都会被影响。
代码中,逻辑上只写了一个map,但是物理层面上每个分区都会执行。

特性3:RDD之间是有依赖关系(RDD有血缘关系)

如上代码,RDD之间是有依赖关系的,
比如:RDD2会产生RDD3,但是RDD2 依赖RDD1
同样,RDD3会产生RDD4,但是RDD3 依赖RDD2
会形成一个链条,这个链条称之为RDD的血缘关系。也叫做RDD的迭代计算关系。
t.txt -> rdd1 -> rdd2 -> rdd3 -> rdd4
特性4:Key-Value型的RDD可以有分区器
这个特性是可选的特性,不是无时无刻都存在的。
默认分区器:Hash分区规则,可以手动设置一个分区器(rdd.partitionBy的方法来设置)
这个特性是可能的,因为不是所有RDD都是 Key-Value型
Key-Value RDD:RDD中存储的二元元组,这就是Key-Value型RDD
二元元组:只有2个元素的元组,比如:(“hadoop”,6)
Hash分区规则: 如果我RDD存储了 (“hadoop”,6)(“hadoop”,6)(“flink”,3)(“spark”,1)(“spark”,1)
现在有三个分区,hadoop的会在一个分区,flink在一个分区,spark在一个分区
特性5:RDD的分区规划,会尽量靠近数据所在的服务器
在初始RDD(读取数据的时候)规划的时候,分区会尽量规划到 存储数据所在的服务器上
因为这样可以走本地读取,避免网络读取
本地读取:Executor所在的服务器,同样是一个DataNode,同时这个DataNode上有它要读取的数据,所以可以直接读取机器硬盘即可,无需走网络传输
网络读取:读取数据,需要经过网络的传输才能读取到
本地读取性能 高于 网络读取性能
总结,Saprk会在确保并行计算能力前提下,尽量确保本地读取
这里是尽量确保,不是100%保证
所以这个特性也是可能。
例如:我有三台机器,机器1:datanode1,nodemanager1,机器2:datanode2,nodemanager2,机器3:datanode3,nodemanager3
一份文件分块存储在 机器1 和机器3上。
Spark运行在YARN集群上。Master就在ResouceManager中。如果我启动2个Executor去执行程序,那么这两个Executor大概率在机器1和机器2上。
为什么说是大概率呢?因为要保证并行计算能力,要是机器1已经负载很重了,那就不会再去部署Executor了。
又或者说,你计算量很大,你开了3个Executor,那么均分在三台机器上。虽然说会网络传输数据,但是从后面走,数据处理时间节约了,这个网络传输时间又算什么呢。所以也需要使用者进行判断。
WordCount案例分析(以RDD视角)
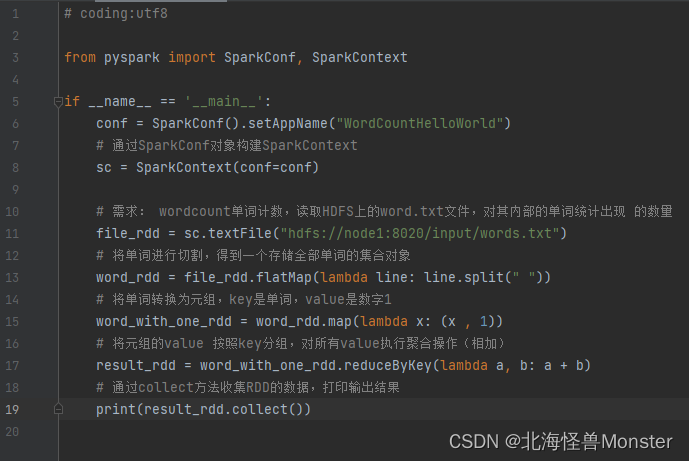
WordCount代码执行图示
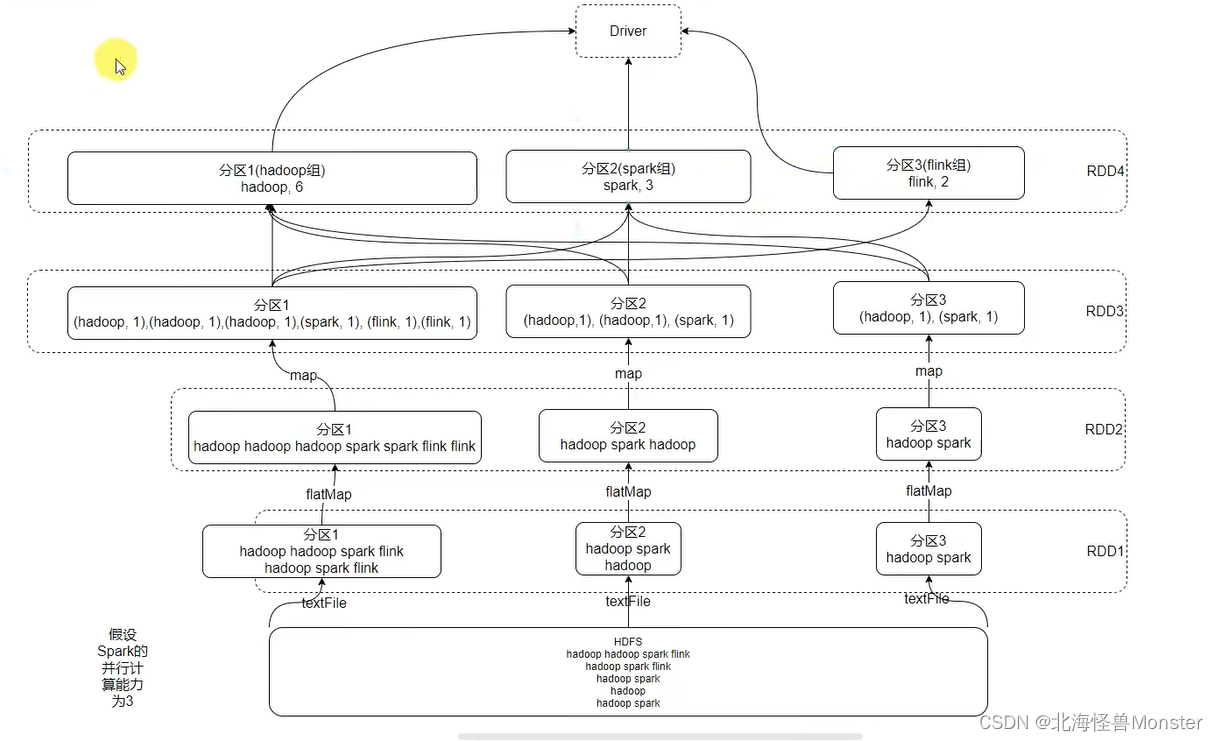
特性1:分区存储。从HDFS中读取文件,存储到三个分区中
特性2:方法会作用在所有分区上
特性3:RDD之间有依赖关系
特性4:分区器,在RDD3 到 RDD4过程中,将元组key值相同的使用hash规则存储到一个分区上,然后再进行汇总相加操作
特性5,就近读取,这张图暂时没有体现出来,对于Spark来说,只要有可能,它就会确保就近读取。
总结
如何正确理解RDD?
弹性分布式数据集,分布式计算的实现载体(数据抽象)
RDD五大特点?
1、分区存储
2、作用方法会作用在每一个RDD上
3、RDD有依赖关系
4、key-value型RDD可以有分区器(可选)
5、RDD在构建的时候会尽量靠近数据所在位置(可选)







![[oeasy]python0043_八进制_oct_octal_october_octave](https://img-blog.csdnimg.cn/img_convert/5122264eb7a1275ed77fbedddfa20c19.png)