概述
MySQL中的自增特性估计大家或多或少都是用过。一张表中只能由一个自增字段,通常我们会把它设置为主键,但是随着大家系统越来越分布式,为了一些性能和可扩展性问题,大家目前选择更多的都是分布式ID(雪花算法、UUID,Redis ID, Leaf)。
但是我觉得还是有必要谈一下自增变量为什么要持久化,或许可以为大家以后设计一些系统作为参考。
自增使用
我们先来看看MySQL自增的使用,自增可以在CREATE TABLE和ALTER TABLE使用:
- 建表时指定自增
- 修改列为自增
建表时指定自增
建表时指定自增列:
create table trade_user(
id int not null auto_increment primary key,
name varchar(20) not null default '' comment 'name'
)comment='trade user';
COPY

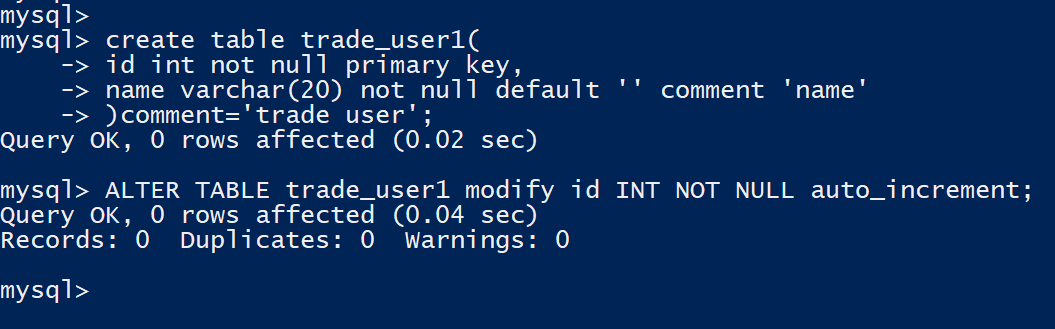
修改列为自增
create table trade_user1(
id int not null primary key,
name varchar(20) not null default '' comment 'name'
)comment='trade user';
ALTER TABLE trade_user1 modify id INT NOT NULL auto_increment;
COPY
自增模式
表中的自增列有一个专用的锁:AUTO-INC锁,这个锁保证并发场景下没有问题。
AUTO-INC锁,这个锁有几种模式,MySQL 8默认的模式为交错模式,我们来查看下MySQL 8默认的锁模式:
SHOW VARIABLES LIKE 'innodb_autoinc_lock_mode';
COPY
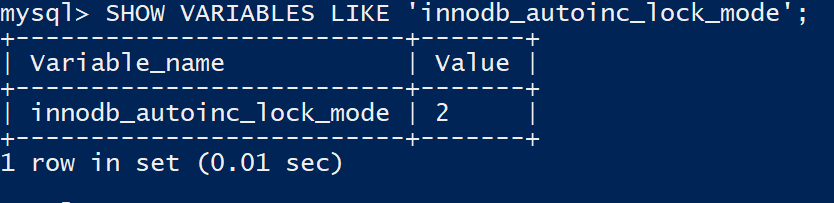
我们看到Value为2,2是什么?来查个表:
| 值 | 自增锁模式 | 备注 |
|---|---|---|
| 0 | “传统”模式 | 为每个语句获取表级自增锁,并在语句结束时释放。 |
| 1 | “连续”模式 | 在查询执行的第一次自增ID的生成时获取表级自增锁,并在语句结束时释放。多个并发的自增语句可以同时获取ID并执行。 |
| 2 | “交错”模式 | 只在自增ID需要的时候获取行级的自增锁。这种方式可以大大降低锁的竞争,提高并发性能,但可能会因事务的回滚导致自增ID的不连续。 |
默认模式
| MySQL版本 | 默认值 | 自增锁模式 |
|---|---|---|
| 5.1 | 0 | “传统”模式 |
| 5.1 – 5.7 | 1 | “连续”模式 |
| 8.0 | 2 | “交错”模式 |
自增问题
交错自增锁的问题是什么?我们来看看官方的解释:
The default setting is 2 (interleaved) as of MySQL 8.0, and 1 (consecutive) before that. The change to interleaved lock mode as the default setting reflects the change from statement-based to row-based replication as the default replication type, which occurred in MySQL 5.7. Statement-based replication requires the consecutive auto-increment lock mode to ensure that auto-increment values are assigned in a predictable and repeatable order for a given sequence of SQL statements, whereas row-based replication is not sensitive to the execution order of SQL statements.
持久化
遇到了什么问题需要持久化?我们来看个MySQL的bug,bug链接:MySQL Bugs: #199: Innodb autoincrement stats los on restart
这个bug大概描述了MySQL交错模式自增导致的问题,复现步骤:
- 创建一个名为“a”的表,其id字段设置为自增字段。
- 向表中插入三条记录,到此为止,生成的id值分别为1, 2, 3。
- 删除id=3的记录,在表中再次插入一条记录,新记录的id值为4,因此当前表中的id值为1, 2, 4。
- 删除id=4的记录,此时MySQL服务器重启。
- 重启后,向表中再次插入一条记录,新插入的记录的id值变为了3,这就是AUTO_INCREMENT字段生成重复值的情况。
根据描述,这个问题可能导致的问题是复制中断,因为在主从复制中,主库和从库的AUTO_INCREMENT值可能会不同,从而导致主从数据不一致。
没有持久化自增值之前怎么得到自增值
这个我们自己思考下就可以想到:首先自增变量肯定要放到内存里面,并且与表有一一对应关系,然后自增变量要存储到某个地方以便下次服务启动时读取。
MySQL的思路基本和上面差不多,MySQL的自增变量恢复遵循以下步骤:
- 首先,表的自增值肯定是要放到内存中的
- 其次, 我们需要思考哪儿有这个自增值:就是表字段
- 然后,MySQL通过查询表的元数据来定位和获取自增字段的最大值。
- 最后,MySQL执行一条SQL就可以获取了
SELECT MAX(auto_increment_column) FROM table
COPY
例如,要查询’trade_user’表中’id’字段的最大值,可以使用以下SQL:
select max(id) from trade_user
COPY
持久化之后自增ID放到哪儿了?
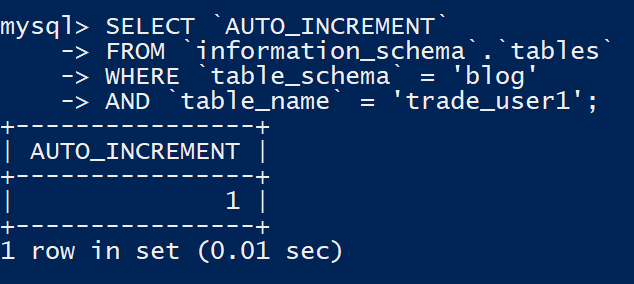
放到了information_schema数据字典中了,如果你要查询你表的当前的自增ID值,执行下面这条SQL:
SELECT `AUTO_INCREMENT`
FROM `information_schema`.`tables`
WHERE `table_schema` = 'blog'
AND `table_name` = 'trade_user1';
COPY
再进一步,到底怎么存储的
先看MySQL官方怎么说:
In MySQL 8.0, this behavior is changed. The current maximum auto-increment counter value is written to the redo log each time it changes and saved to the data dictionary on each checkpoint. These changes make the current maximum auto-increment counter value persistent across server restarts.
这个大概意思就是:
MySQL会把自增计数器的当前最大值写入redo log,并在每次检查点时保存到数据字典中,这样就完成了自增计数器的持久化。
数据库重启了以后怎么恢复?因为重启可能是因为崩溃,最新的自增值还没有写入到数据字典中,那么就得这么干了:
- 数据库启动的时候先从数据字典中获取元数据,把表的自增ID加载到内存中
- 服务器重放redo log中的所有事务,然后把自增ID修改为redo log中的值
总结
从MySQL自增值持久化问题以及解决方案,我们从中可以学习到:
- 数据持久化和一致性的重要性
- 设计系统时要考虑到异常情况,如果没有考虑到异常情况,出一些意料之外的问题你会很蒙蔽
- 全局唯一ID的重要性,这个ID非常重要,要是混乱了,你的饭碗可能瞬间都没了,而且后面的就刷库吧
参考
1. MySQL自增变量持久化 – FOF编程网