author: hjjdebug
date: 2024年 03月 25日 星期一 17:50:02 CST
description: 磁盘文件系统实际操练,解释到bit
文章目录
- 0. 为什么需要磁盘文件系统.
- 1. 磁盘文件系统的任务是什么?
- 2. 空白磁盘是什么? 空白磁盘数据长什么样?
- 3. 格式化磁盘都干了什么? 格式化后的磁盘长什么样?
- 3.1 先找一个空设备
- 3.2 然后后把这个文件与伪设备关联. (相当于你把磁盘放入了驱动器)
- 3.3 然后格式化磁盘 ,
- 3.4 格式化后的磁盘长什么样? 如下图:
- 4.贴上一个系统构成图:
- 5. 把 hello.txt 拷贝到磁盘,
- 1. 引导块和超级块内容未改变.
- 2. inode map 块, 从03变成了07,说明又有一个inode被占用(实际是第2个inode)
- 3. block map 块,从03变成了07,说明又有一个block被占用(实际是第2个block,块号20,从19开始的)
- 4. 节点区变化
- 5. 根目录区变化,多了个hello.txt文件
- 5.1 fp=fopen("/hello.txt","r"); 打开一个文件是指什么意思?
- 6.数据区变化
0. 为什么需要磁盘文件系统.
磁盘是用来存储数据的,这个我们都知道. 为什么要有磁盘文件系统, 磁盘文件系统是干什么的?
如果一个磁盘只需要装一个文件(姑且把一堆数据叫文件吧), 那就不需要文件系统.
只要有两个文件,就要有磁盘管理, 2个文件你总要说清那个文件在前,那个文件在后,都占多大的空间吧.
1. 磁盘文件系统的任务是什么?
甲: 文件系统的任务是什么? 别整那些大块大块没用的说法. 这里又不是考试.
乙: 用白话说,文件系统就是管理文件的.
甲: 怎么管理?
乙: 就是你给个文件名,我能找到文件内容在磁盘上的存储位置. 当然了,也能往磁盘上写文件.
找的过程, 是文件系统的事, 至于把数据读取出来,那是驱动的事,就不在本博讨论了.
甲: 啊? 文件系统就干这点事啊.
乙: 是的. 给个文件名, 我告诉你数据在磁盘的什么位置就够了. 读取数据是驱动的事.
甲: 那要是一个文件比较大,一个块装不下怎么办呢?
乙: 那我就告诉你这个文件有很多个磁盘块,你一个个读出来就可以了.所以说你给定文件路径,
我告诉你的是一个inode,它可以对应很多磁盘块, 而不仅仅是一个磁盘块. 这就是文件系统的任务.
2. 空白磁盘是什么? 空白磁盘数据长什么样?
当你把一张空白盘放入软件驱动器,或者把一个空白硬盘连接上计算机,它目前还是存储不了文件的.
它虽然啥也干不了,但磁盘驱动还是能知道点事情的,它会问, 喂! 磁盘,你能存储多大字节呢?
假如磁盘是1.44M, 它会回答1.44M, 硬盘呢? 可能会回答, 我是2个T.
驱动会说,把你的数据都给我,看看都是什么东西?
磁盘把所有的数据都给了你, 你就看到磁盘中所装的全部数据了.
不能光说不练, 下面先创建一个空白磁盘
没有真盘, 也不用花钱买, 用一个文件起名1.img 就可以模拟了.
$ dd if=/dev/zero of=1.img bs=512 count=2880
记录了2880+0 的读入
记录了2880+0 的写出
1474560 bytes (1.5 MB, 1.4 MiB) copied, 0.00448294 s, 329 MB/s
其文件内容, 如图所示:
0000h 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 …
0010h 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 …
0020h 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 …
… 后面全是0
3. 格式化磁盘都干了什么? 格式化后的磁盘长什么样?
3.1 先找一个空设备
相当与你找到了一个可用的磁盘驱动器,linux下操作就是好啊,都不用花钱买,模拟就够了!
$ losetup -f
/dev/loop0
这说明 /dev/loop0设备可以给我们用.
3.2 然后后把这个文件与伪设备关联. (相当于你把磁盘放入了驱动器)
$ sudo losetup /dev/loop0 1.img
(linux 竟能用这种方式来模拟磁盘操作! 赞!)
不信你看看,用lsblk, linux 真的以为有一个设备叫loop0, 它有1.4M 的磁盘空间呢.
$ lsblk
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT
loop0 7:0 0 1.4M 0 loop
sda 8:0 0 931.5G 0 disk
├─sda1 8:1 0 400G 0 part /storage
└─sda2 8:2 0 531.5G 0 part /disk
nvme0n1 259:0 0 119.2G 0 disk
├─nvme0n1p1 259:1 0 512M 0 part /boot/efi
└─nvme0n1p2 259:2 0 118.8G 0 part /
3.3 然后格式化磁盘 ,
$ sudo mkfs -t minix /dev/loop0
[sudo] hjj 的密码:
480 个 inode
1440 个块
首个数据区=19 (19)
区大小=1024
最大尺寸=268966912
我选择把磁盘格式化为minix , 因为它简单. 早期linux 内核用过这种类型.
内容打印的很清楚了, 480个inode 是说最多存480个文件.
文件总大小为1440个块,一块1024byte. 所以叫1.44M 磁盘嘛.
首个数据块在第19个块. 前边18个被系统管理给使用了.
最大尺寸 258966912 是什么? 约等于256M, 它说的minix系统最大能管理256M 空间,再多就管不了了.
3.4 格式化后的磁盘长什么样? 如下图:
如果是真的磁盘,还需要工具把整个磁盘数据读出来,
而在linux 下用loop设备模拟, 数据都不用读了, 1.img 本身就是! 方便啊!
//第一个块是引导块,空块
00000000: 0000 0000 0000 0000 0000 0000 0000 0000 …
00000010: 0000 0000 0000 0000 0000 0000 0000 0000 …
00000020: 0000 0000 0000 0000 0000 0000 0000 0000 …
… 后面全是0
000003e0: 0000 0000 0000 0000 0000 0000 0000 0000 …
000003f0: 0000 0000 0000 0000 0000 0000 0000 0000 …
第一个块0-03ff 是引导块,如果是引导盘,0x1fe,0x1ff会放引导标记0x55,0xAA
//第二个块数据是超级块
00000400: e001 a005 0100 0100 1300 0000 001c 0810 …
00000410: 8f13 0100 0000 0000 0000 0000 0000 0000 …
00000420: 0000 0000 0000 0000 0000 0000 0000 0000 …
… 后面全是0
struct d_super_block { // disk super_block
unsigned short s_ninodes;
unsigned short s_nzones;
unsigned short s_imap_blocks;
unsigned short s_zmap_blocks;
unsigned short s_firstdatazone;
unsigned short s_log_zone_size;
unsigned long s_max_size;
unsigned short s_magic;
};
e001(ninodes,0x01e0=480) inode 480,决定了inode区所占数据块大小,这属于系统占用
a005(nzones,0x05a0=1440) 总的数据块数, 扣除文件系统管理占用,其余给用户使用
0100(imap_blocks,0x01=1) imap占一块,在super块之后
0100(zmap_blocks,0x01=1) zmap占一块,在imap之后
1300(firstdatazone,0x13=19) 数据块从19块开始,不说也没关系,因为inode没有参考它
0000(logzonesize,0)
001c0810(max_size,0x10081c00=268966912) 本系统最大可管理的尺寸大小
8f13(magic) 魔幻数, MINIX 文件系统标志
//第三个块是i节点位图, bit0表示空闲,bit1表示占用
00000800: 0300 0000 0000 0000 0000 0000 0000 0000 …
00000810: 0000 0000 0000 0000 0000 0000 0000 0000 …
00000820: 0000 0000 0000 0000 0000 0000 0000 0000 …
00000830: 0000 0000 0000 0000 0000 0000 feff ffff …
00000840: ffff ffff ffff ffff ffff ffff ffff ffff …
00000850: ffff ffff ffff ffff ffff ffff ffff ffff …
… 后面全是FF
(3*16+12)*8+1=481 个inode,为什么说是480个inode?
feff 中的0应该不是inode位了.
03表示已经有2个inode 被占用了,实际上是一个,1号节点被占用了,它就是根节点,见后面
初始化时写成3, 可能时为了方便吧.
//第4个块是block 位图, bit0表示空闲,bit1表示占用
00000c00: 0300 0000 0000 0000 0000 0000 0000 0000 …
00000c10: 0000 0000 0000 0000 0000 0000 0000 0000 …
00000c20: 0000 0000 0000 0000 0000 0000 0000 0000 …
00000c30: 0000 0000 0000 0000 0000 0000 0000 0000 …
00000c40: 0000 0000 0000 0000 0000 0000 0000 0000 …
00000c50: 0000 0000 0000 0000 0000 0000 0000 0000 …
00000c60: 0000 0000 0000 0000 0000 0000 0000 0000 …
00000c70: 0000 0000 0000 0000 0000 0000 0000 0000 …
00000c80: 0000 0000 0000 0000 0000 0000 0000 0000 …
00000c90: 0000 0000 0000 0000 0000 0000 0000 0000 …
00000ca0: 0000 0000 0000 0000 0000 0000 0000 0000 …
00000cb0: 00c0 ffff ffff ffff ffff ffff ffff ffff …
00000cc0: ffff ffff ffff ffff ffff ffff ffff ffff …
00000cd0: ffff ffff ffff ffff ffff ffff ffff ffff …
… 后面全是FF
11168+14=1422
总共 1422 block, 不是1440?!
首个数据区 = 19, 1440-18=1422,
就是说前边18个区1-18被系统占用, 数据区从第19块开始. 第一块是从super_block块算起的.
所以第19块对应的绝对地址(18个系统块+1个引导块算19块) 19*1024 = 0x4c00
这块对应的就是根目录数据区了.
03表示有2个块被占用了, 嗯,占就占吧,反正数据从第19块开始,其对应地址是0x4c00,1号inode说的.
只要它的bit位与数据块对上就好了,如果有对应偏差那计算时扣除计算偏差就可以了.
//第5个块, 是节点区
00001000: ed41 0000 4000 0000 ab0e 0166 0002 1300 .A…@…f…
00001010: 0000 0000 0000 0000 0000 0000 0000 0000 …
00001020: 0000 0000 0000 0000 0000 0000 0000 0000 …
00001030: 0000 0000 0000 0000 0000 0000 0000 0000 …
… 后面全是0 , 这个节点是1号节点, 1号节点就是根节点"/",根就是从这里开始的.
它非常的重要,所有的文件操作,只要先找到根,才能找到后续的文件.
该节点对应盘块0x13=19 ,所以叫数据区从19块开始, 节点区还属于系统管理区.
struct d_inode { // disk inode
unsigned short i_mode;
unsigned short i_uid;
unsigned long i_size;
unsigned long i_time;
unsigned char i_gid;
unsigned char i_nlinks;
//前7个是直接块号寻址,第8个是一级间接寻址,第9个是2级间接寻址
//所谓1级间接寻址,是第一次拿到的块,其储存的全部是块号数据,由此再拿到文件数据
//所谓2级间接寻址,可以递推知.
unsigned short i_zone[9];
};
一个inode 共32 bytes
//第20个块, 根目录区,根节点对应的数据区. 这就是所谓的第19盘块,
绝对偏移却是(19*1024=19456=0x4c00)处,
因为绝对偏移还要加上1块启动块
00004c00: 0100 2e00 0000 0000 0000 0000 0000 0000 …
00004c10: 0000 0000 0000 0000 0000 0000 0000 0000 …
00004c20: 0100 2e2e 0000 0000 0000 0000 0000 0000 …
00004c30: 0000 0000 0000 0000 0000 0000 0000 0000 …
一个目录项占用了32bytes, 这里保存了.,… 两个目录项, 它们都对应第1号inode
struct dir_entry {
unsigned short inode_nr;
char name[NAME_LEN]; //NAME_LEN 这里的表现是30个字符
};
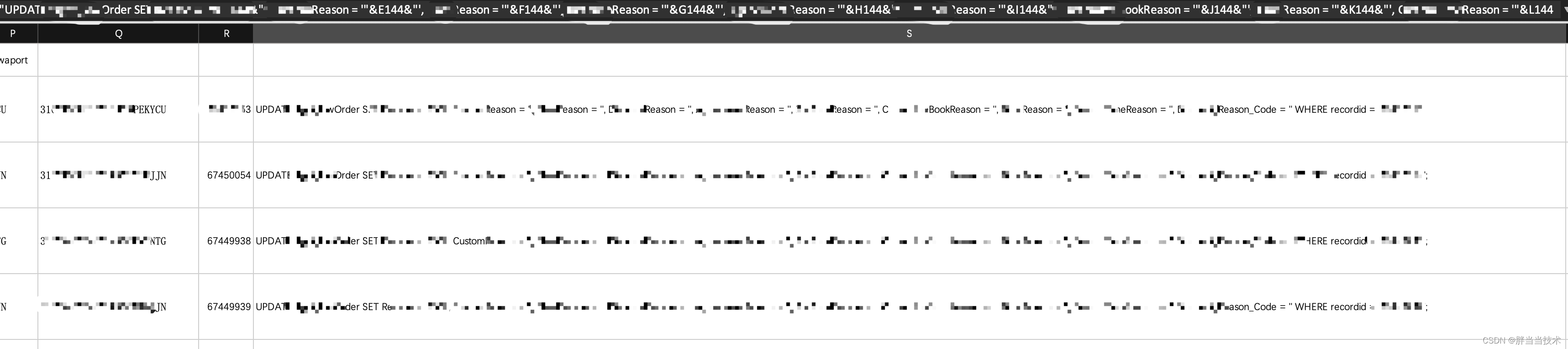
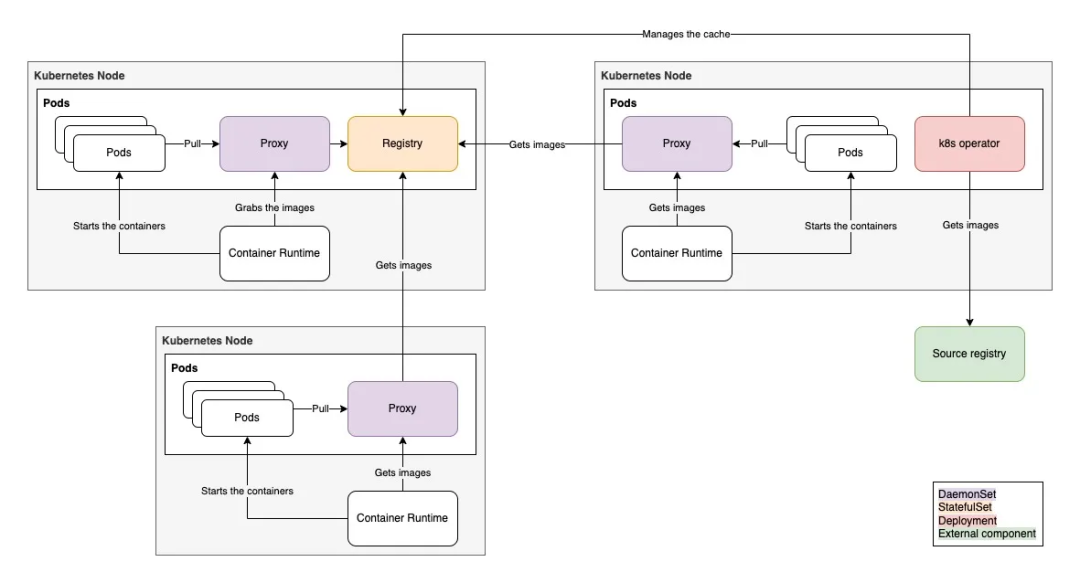
4.贴上一个系统构成图:
 来自赵炯博士的old_linux 的一张图片.
来自赵炯博士的old_linux 的一张图片.
解释清楚了这些数据的用途,你就对minix 文件系统了解了. 稍带着也理解了别的文件系统需要完成的工作.
5. 把 hello.txt 拷贝到磁盘,
$ sudo mount -t minix 1.img /mnt //把磁盘映像可以mount到一个安装点上来操作, 有了文件系统就可以用mount 命令
$ sudo cp hello.txt /mnt // 然后就可以调用系统命令来操作文件
$ cd /mnt
$ cat hello.txt
hello from me!
$ sudo umount /mnt
#3 重新查看文件系统
$ xxd 1.img > 2.txt // 将二进制专程文本文件命令
打开文件查看.
$ vim 2.txt
1. 引导块和超级块内容未改变.
2. inode map 块, 从03变成了07,说明又有一个inode被占用(实际是第2个inode)
00000800: 0700 0000 0000 0000 0000 0000 0000 0000 …
00000810: 0000 0000 0000 0000 0000 0000 0000 0000 …
00000820: 0000 0000 0000 0000 0000 0000 0000 0000 …
00000830: 0000 0000 0000 0000 0000 0000 feff ffff …
3. block map 块,从03变成了07,说明又有一个block被占用(实际是第2个block,块号20,从19开始的)
00000c00: 0700 0000 0000 0000 0000 0000 0000 0000 …
00000c10: 0000 0000 0000 0000 0000 0000 0000 0000 …
00000c20: 0000 0000 0000 0000 0000 0000 0000 0000 …
00000c30: 0000 0000 0000 0000 0000 0000 0000 0000 …
00000c40: 0000 0000 0000 0000 0000 0000 0000 0000 …
00000c50: 0000 0000 0000 0000 0000 0000 0000 0000 …
00000c60: 0000 0000 0000 0000 0000 0000 0000 0000 …
00000c70: 0000 0000 0000 0000 0000 0000 0000 0000 …
00000c80: 0000 0000 0000 0000 0000 0000 0000 0000 …
00000c90: 0000 0000 0000 0000 0000 0000 0000 0000 …
00000ca0: 0000 0000 0000 0000 0000 0000 0000 0000 …
00000cb0: 00c0 ffff ffff ffff ffff ffff ffff ffff …
4. 节点区变化
00001000: ed41 0000 6000 0000 8520 0166 0002 1300 .A…`… .f…
00001010: 0000 0000 0000 0000 0000 0000 0000 0000 …
00001020: a481 0000 0f00 0000 8520 0166 0001 1400 … .f…
00001030: 0000 0000 0000 0000 0000 0000 0000 0000 …
从1020开始就是新添的一个inode,inode_map 表示已占用
struct d_inode { // disk inode
unsigned short i_mode;
unsigned short i_uid;
unsigned long i_size;
unsigned long i_time;
unsigned char i_gid;
unsigned char i_nlinks;
//前7个是直接块号寻址,第8个是一级间接寻址,第9个是2级间接寻址
//所谓1级间接寻址,是第一次拿到的块,其储存的全部是块号数据,由此再拿到文件数据
//所谓2级间接寻址,可以递推知.
unsigned short i_zone[9];
};
一个inode 共32 bytes
第2个inode, a481(mode),0000(uid),0f00 0000(长度15个字节),8520 0166(时间),00(gid),01(nlinks)
1400(对应区块,第20块(0x14)) , 最关键的就是找到数据位置了.
它的物理偏移就是201024=20480=0x5000
难道不是191024吗? 哎! 它就是这样定义的,因为前边还有一个空块启动块呢. 所以偏移就按块号*block_size了.
5. 根目录区变化,多了个hello.txt文件
00004c00: 0100 2e00 0000 0000 0000 0000 0000 0000 …
00004c10: 0000 0000 0000 0000 0000 0000 0000 0000 …
00004c20: 0100 2e2e 0000 0000 0000 0000 0000 0000 …
00004c30: 0000 0000 0000 0000 0000 0000 0000 0000 …
00004c40: 0200 6865 6c6c 6f2e 7478 7400 0000 0000 …hello.txt…
00004c50: 0000 0000 0000 0000 0000 0000 0000 0000 …
.,…对应的inode号是0100(就是1,见后), 1号节点也叫根节点.
hello.txt对应的inode号0200(就是是2,见后),
struct dir_entry {
unsigned short inode_nr;
char name[NAME_LEN]; //NAME_LEN 这里的表现是30个字符
};
我们可以用命令来验证一下:
$ ls -i
2 hello.txt
只所以是0200是2, 是因为intel-cpu是小端序,低位在前,高位在后.
5.1 fp=fopen(“/hello.txt”,“r”); 打开一个文件是指什么意思?
就是说你先要找到根目录的inode,这个简单,就是1号inode, 然后读取其数据,它们都是目录项结构.
查找根目录的目录项,直到找到一个叫hello.txt名称的目录项.拿到它的inode号, 这样就算你打开这个文件了.
问: 为什么找到inode 号就算打开文件了呢?
答: 因为找到了inode 号, 就可以从inode表中取到inode, 就能够找到这个inode对应的数据块,就能够取到这个文件的数据了.
问: 那inode 表又是何时读取到内存的,从哪里得到的呢.
答: 这是mount_root 的时候干的, 当读取超级块时,从超级块中找到inode表, 超级块就是磁盘中固定的第二块(minix)
所以操作文件的第一步,就是先mount_root, 读取超级块,这样就可以随时读取inode表,找到每个文件所在的位置.
还要把根inode 读进来, 以便随时响应从根inode下开始搜索不同目录下的文件.
例如: /foo/bar/some.txt
其操作过程为:
从1号inode处找到根目录数据,读取,
从根目录数据中查找一个叫foo的目录项,找到其对应的inode,从inode所指的数据块中读取数据,为foo目录的数据.
从foo目录数据中查找一个叫bar的目录项,找到其对应的inode,从inode所指的数据块中读取数据,为bar目录的数据.
从bar目录数据中查找一个叫some.txt的目录项,找到其对应的inode,从inode所指的数据块中读取数据,为some.txt的文件数据.
世界就是由循环和递归构成的!
6.数据区变化
这就是数据内容了. 它对应第20个数据块 20*1024=20480=0x5000
00005000: 6865 6c6c 6f20 6672 6f6d 206d 6521 0a00 hello from me!..
00005010: 0000 0000 0000 0000 0000 0000 0000 0000 …
这跟上面inode 2 表示的结果完全一致!