请结合B站-技术蛋老师 视频学习
核心语法
一、增:数据库/表格
create
create database 数据库名;
#创建表(列名+类型)
mysql> create table eggs_record(
-> id int,
-> egg_name varchar(10),
-> sold date
-> );
这里 ,用来隔开列名,最后一列后无(date类型格式 年-月-日)还可以设置默认条件 NOT NULL、NULL、AUTO_INCREMENT自动递增
一般情况下会设置 PRIMARY KEY主键,给每一行进行约束,使得MySQL可以更准确找到对应数据,设置其中一个列名为主键,设置后列名的数据需要是唯一的,例:id是递增的,肯定是唯一的,因此会加上主键(主键一定不为NULL)

mysql> create table eggs_record(
-> id int primary key auto_increment,
-> egg_name varchar(10) not null,
-> sold date null
-> );
Query OK, 0 rows affected (0.03 sec)
mysql> desc eggs_record;
+----------+-------------+------+-----+---------+----------------+
| Field | Type | Null | Key | Default | Extra |
+----------+-------------+------+-----+---------+----------------+
| id | int | NO | PRI | NULL | auto_increment |
| egg_name | varchar(10) | NO | | NULL | |
| sold | date | YES | | NULL | |
+----------+-------------+------+-----+---------+----------------+
3 rows in set (0.03 sec)insert into 数据库名.表格名

mysql> insert into egg.eggs_record (id,egg_name,sold)
-> values (1,'鸡蛋','2024-3-25');
Query OK, 1 row affected (0.00 sec)
mysql> insert into egg.eggs_record (id,egg_name,sold)
-> values (2,'鸭蛋','2024-3-26');
Query OK, 1 row affected (0.00 sec)
mysql> insert into egg.eggs_record (id,egg_name,sold)
-> values (DEFAULT,'鸭蛋',NULL);
Query OK, 1 row affected (0.00 sec)
#### DEFAULT:设置默认值,前面添加了递增的关键字
mysql> select * from eggs_record;
+----+----------+------------+
| id | egg_name | sold |
+----+----------+------------+
| 1 | 鸡蛋 | 2024-03-25 |
| 2 | 鸭蛋 | 2024-03-26 |
| 3 | 鸭蛋 | NULL |
+----+----------+------------+
3 rows in set (0.05 sec)二、改:更新表格
alter table 需要新增一列

mysql> alter table eggs_record
-> add stock int null;
Query OK, 0 rows affected (0.02 sec)
Records: 0 Duplicates: 0 Warnings: 0
mysql> desc eggs_record;
+----------+-------------+------+-----+---------+----------------+
| Field | Type | Null | Key | Default | Extra |
+----------+-------------+------+-----+---------+----------------+
| id | int | NO | PRI | NULL | auto_increment |
| egg_name | varchar(10) | NO | | NULL | |
| sold | date | YES | | NULL | |
| stock | int | YES | | NULL | |
+----------+-------------+------+-----+---------+----------------+
4 rows in set (0.03 sec)update set where 修改具体数据

mysql> update egg.eggs_record
-> set sold = '2024-01-01'
-> where id =3;
Query OK, 1 row affected (0.00 sec)
Rows matched: 1 Changed: 1 Warnings: 0
mysql> select * from egg.eggs_record;
+----+----------+------------+-------+
| id | egg_name | sold | stock |
+----+----------+------------+-------+
| 1 | 鸡蛋 | 2024-03-25 | NULL |
| 2 | 鸭蛋 | 2024-03-26 | NULL |
| 3 | 鸭蛋 | 2024-01-01 | NULL |
+----+----------+------------+-------+三、 删:数据/表格/库
delete from
drop



mysql> delete from egg.eggs_record
-> where id = 1;
Query OK, 1 row affected (0.00 sec)
mysql> select * from egg.eggs_record;
+----+----------+------------+-------+
| id | egg_name | sold | stock |
+----+----------+------------+-------+
| 2 | 鸭蛋 | 2024-03-26 | NULL |
| 3 | 鸭蛋 | 2024-01-01 | NULL |
+----+----------+------------+-------+
2 rows in set (0.05 sec)四、查:选择/去重/排序/过滤
用例:新冠感染月份表-汇总表
select * from 表格名
查看具体列数 选择列名


distinct 不同的 位置紧跟select

想查询涉及到那些州 (去重)

order by 排序 后面+ASC(Ascending) DESC(从高到低,大到小)


where 条件 order by 列名 过滤


SELECT *
FROM Covid_month
WHERE Recovered >= 10000 AND Country != 'Brazil'
ORDER BY Confirmed DESC;


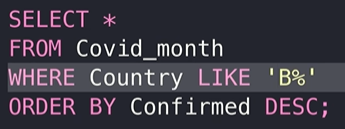
 第三个字符为b
第三个字符为b
五、查:连接
join
内连接-并集 inner join + on条件定位 (选择两边所有的数据,两张表合并,合并的时候以国家名作为合并的条件,出来的结果把from的表格放左边,inner join表格放右边,把左右两边的值以某个条件合并在一起)

SELECT *
FROM Covid_month
INNER JOIN Covid_total
ON Covid_month.Country = Covid_total.Country;union 并集


一个上一个下合并在一张表里面


左连接 left join
如果需要从表格A左连接表格B,和inner join一样,用on进行定位,左连接的时候会保留左边的表格所有选取的数据,把右边表格符合条件的合并过来

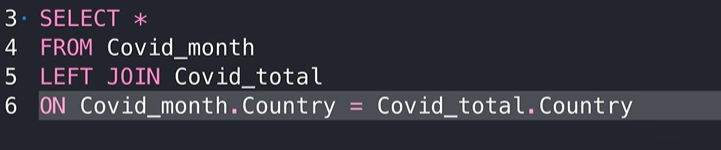
右连接 right join


AS 定义简写,上下用到的地方都要改为简写

六、工具选择:navicat-选择新建查询-方便练习
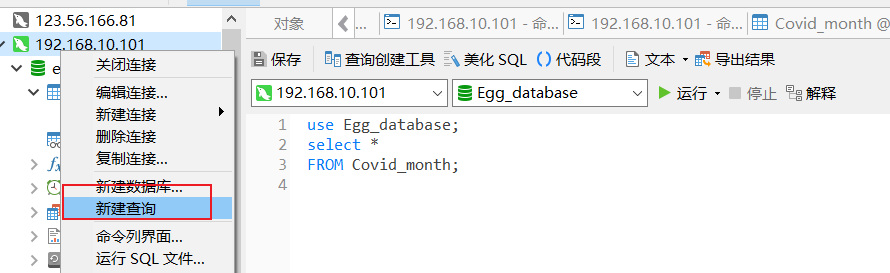
七、聚合函数 必须搭配 group by 子句使用
1.计算每个班的人数:select class_name,count(*) from student group by class_name;
2.计算每个班级男生、女生人数:select class_name,sex,count(*) from student group by class_name,sex;
3.计算每个班平均分(重命)select class_name,avg(score) as avg_score from student group by class_name;
4.对id进行降序排序:select * from student order by id desc;
八、其他补充
alter table meishi change column meishi fresh; 改表名
ALTER TABLE student CHANGE COLUMN class_name new_class_name VARCHAR(50); 改字段名
alter table student modify column class_name varchar(60) comment '班级'; 改字段属性
update orders1 set product_num=34 ,consumer_name='大理',consumption=345 where id=10; 改字段
备份表 创建相同表结构,在导入源数据
create table eggs_bak like eggs_record;
insert into eggs_bak select * from eggs_record;

九、sql优化
-
避免使用 SELECT *:
我会强调避免在查询中使用 SELECT *,而是明确指定需要检索的列。这样可以减少查询返回的数据量,降低网络传输成本和数据库的负载,并且可以更好地利用索引。 -
使用 UNION ALL 代替 UNION:
如果查询中需要使用 UNION 操作符,我会优先选择使用 UNION ALL。因为 UNION ALL 不会进行重复的去重操作,相比于 UNION,它的执行效率更高。 -
控制索引的数量:
我会强调控制索引的数量,避免创建过多的索引。虽然索引可以提高查询效率,但是过多的索引会增加数据库的维护成本,影响数据的更新速度,并且可能导致性能下降。 -
选择合理的字段类型:
在设计数据库时,我会选择合理的字段类型和长度,以确保数据存储的效率和查询的性能。例如,对于文本型数据,我会根据实际情况选择合适的 VARCHAR 长度,避免过长的字段长度导致存储浪费。 -
使用连接查询代替子查询:
我会尽量使用连接查询(JOIN)来代替子查询,因为连接查询通常比子查询执行效率更高。子查询在某些情况下可能会导致数据库的性能问题,特别是在嵌套子查询的情况下。
这些优化技巧都是我在实际工作中经常应用的,通过合理地应用这些技巧,我能够提高数据库系统的性能和查询效率。
【mysql】SQL优化15种方法_mysql sql优化-CSDN博客
数据仓库【SQL优化】-CSDN博客
MySQL 中的 GROUP BY 语句及十二个例子 - 墨天轮
十、面试真题
 数据是我自己编的,题目是真题
数据是我自己编的,题目是真题
学生表四个字段 性别 姓名 年龄 班级,统计每个班级男女各有多少名?(完整sql语句)

统计一班男女各有多少名?

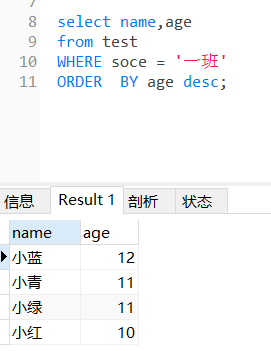
把一班学生的姓名按照年龄倒序排序?(desc排序不能和group by,要使用order by)
索引类型
主要有以下几种类型的索引:
- B-Tree 索引(包括普通索引、唯一索引、组合索引等)
- 哈希索引
- 全文索引
- 空间索引等
索引的作用
- 加速数据的检索和查询速度。
- 通过索引,数据库系统可以更快地定位到符合条件的记录,减少了数据库的查询时间,提高了查询效率。
- 帮助数据库系统优化查询执行计划,减少磁盘 I/O 操作。
索引的工作原理
- 不同类型的索引有不同的工作原理,但主要的原理是通过数据结构来组织数据,以便快速地检索、定位和访问数据。
- 例如,B-Tree 索引使用平衡树的结构来组织数据,哈希索引使用哈希表等。
- 当查询时,数据库系统会先根据索引定位到符合条件的记录,然后再根据定位到的位置获取相关的数据。
索引是越多越好吗?
- 不是。虽然索引可以提高查询的速度,但索引也会占用额外的存储空间,并且在数据更新时需要额外的维护成本(如插入、更新、删除操作)。
- 过多的索引可能会导致数据库性能下降,因为在更新数据时需要维护多个索引。
- 正确的做法是根据实际情况和需求,合理地设计和选择索引,尽量避免创建过多的索引,尤其是那些不经常使用或不必要的索引。