政安晨的个人主页:政安晨
欢迎 👍点赞✍评论⭐收藏
收录专栏: TensorFlow与Keras实战演绎机器学习
希望政安晨的博客能够对您有所裨益,如有不足之处,欢迎在评论区提出指正!
介绍
Keras 3是一个深度学习框架,可以与TensorFlow、JAX和PyTorch互换使用。本文将介绍Keras 3的关键工作流程。
从一个常用实验开始
一个MNIST卷积神经网络
让我们再次从机器学习的Hello World开始:训练一个卷积神经网络来对MNIST数字进行分类。
如果您是第一次看到这篇文章,还没有准备好环境,参考我本专栏的目录文章中关于搭建环境的部分:
政安晨:【TensorFlow与Keras实战演绎机器学习】专栏 —— 目录![]() https://blog.csdn.net/snowdenkeke/article/details/136985399
https://blog.csdn.net/snowdenkeke/article/details/136985399
小伙伴们准备好环境,就跟我一起探索机器学习领域的奇妙吧。
(当然,有时我为了能够随时开展机器学习实验,也会使用Kaggle等在线平台进行训练,我的文章以实用为主,大家跟着我的实战过程,应该会有所受益。)
导入数据
先执行代码,下面代码获取数据:
import keras
import numpy as np
# Load the data and split it between train and test sets
(x_train, y_train), (x_test, y_test) = keras.datasets.mnist.load_data()
# Scale images to the [0, 1] range
x_train = x_train.astype("float32") / 255
x_test = x_test.astype("float32") / 255
# Make sure images have shape (28, 28, 1)
x_train = np.expand_dims(x_train, -1)
x_test = np.expand_dims(x_test, -1)
print("x_train shape:", x_train.shape)
print("y_train shape:", y_train.shape)
print(x_train.shape[0], "train samples")
print(x_test.shape[0], "test samples")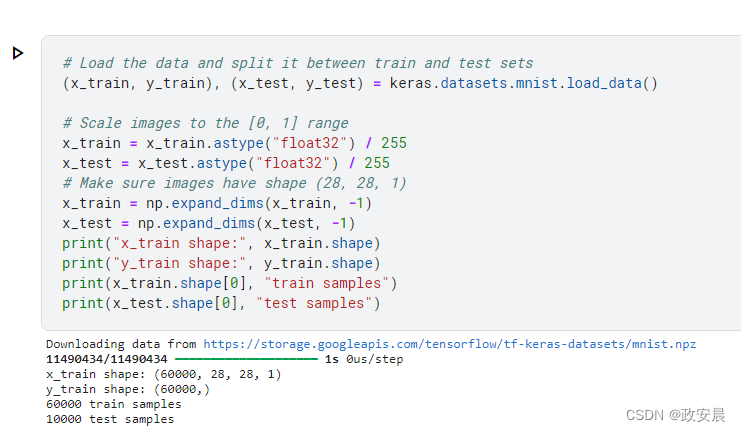
构建模型
下面构建我们需要的模型:
Keras 提供的不同模型构建选项包括:
- 顺序 API(我们在下文中使用的 API)
- 功能 API(最典型)
- 通过子类化编写自己的模型(用于高x
# Model parameters
num_classes = 10
input_shape = (28, 28, 1)
model = keras.Sequential(
[
keras.layers.Input(shape=input_shape),
keras.layers.Conv2D(64, kernel_size=(3, 3), activation="relu"),
keras.layers.Conv2D(64, kernel_size=(3, 3), activation="relu"),
keras.layers.MaxPooling2D(pool_size=(2, 2)),
keras.layers.Conv2D(128, kernel_size=(3, 3), activation="relu"),
keras.layers.Conv2D(128, kernel_size=(3, 3), activation="relu"),
keras.layers.GlobalAveragePooling2D(),
keras.layers.Dropout(0.5),
keras.layers.Dense(num_classes, activation="softmax"),
]
)可以查看模型摘要:
model.summary()执行如下: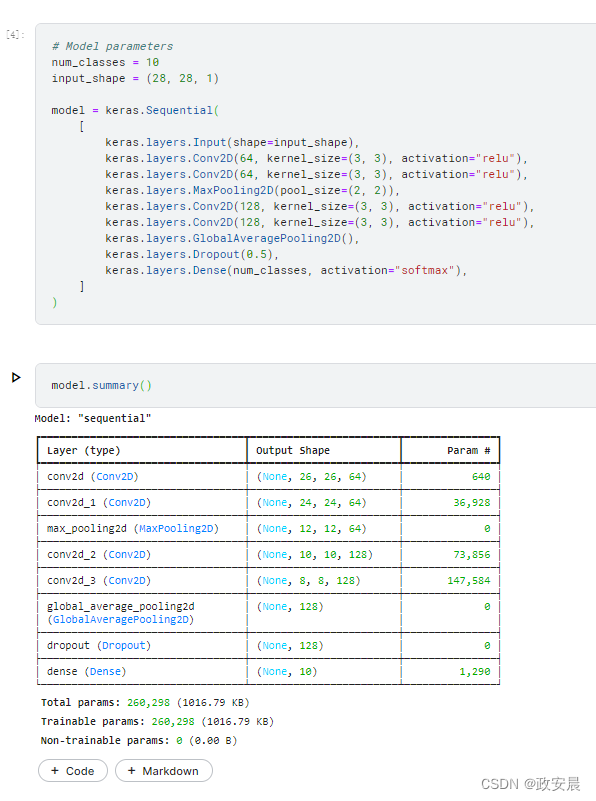
编译与训练
我们使用编译()方法来指定优化器、损失函数和要监控的指标。请注意,对于 JAX 和 TensorFlow 后端,XLA 编译是默认开启的。
model.compile(
loss=keras.losses.SparseCategoricalCrossentropy(),
optimizer=keras.optimizers.Adam(learning_rate=1e-3),
metrics=[
keras.metrics.SparseCategoricalAccuracy(name="acc"),
],
)让我们来训练和评估模型。在训练过程中,我们将留出 15% 的验证数据,以监控未见数据的泛化情况。
batch_size = 128
epochs = 20
callbacks = [
keras.callbacks.ModelCheckpoint(filepath="model_at_epoch_{epoch}.keras"),
keras.callbacks.EarlyStopping(monitor="val_loss", patience=2),
]
model.fit(
x_train,
y_train,
batch_size=batch_size,
epochs=epochs,
validation_split=0.15,
callbacks=callbacks,
)
score = model.evaluate(x_test, y_test, verbose=0)实战演绎如下:
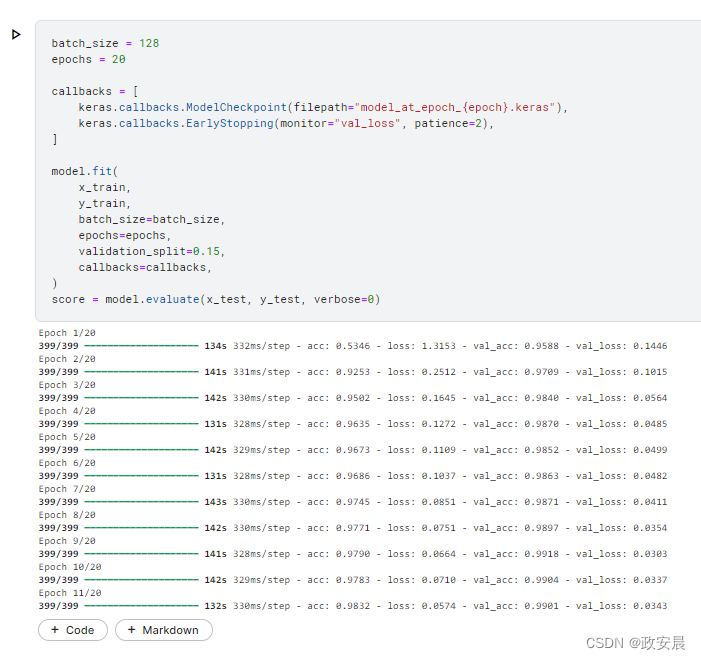
在训练过程中,我们会在每个周期结束时保存模型。
您也可以像这样保存模型的最新状态:
model.save("final_model.keras")然后像这样重新加载:
model = keras.saving.load_model("final_model.keras")接下来,您可以使用 predict() 查询类概率的预测结果:
predictions = model.predict(x_test)演绎如下:
对于首次接触的小伙伴们而言,这就是全部的基本知识啦。
大家只要能跑起来,我们以后循序渐进,包括智能硬件系统的训练、传感器的感知交互训练等等。
大厦真不是一天建成的,小伙伴们一起加油!