前言
最近在CF (Cloud Foundry) 云平台上遇到一个比较经典的案例。因为牵扯到JVM (app进程)与数据库连接两大块,稍有不慎,很容易引起不快。
在云环境下,有时候相互扯皮的事蛮多。如果是DB的问题,就会找DB相关部门。关键是如何自证。涉及到职场生存法则,大家都不愿意去背锅,谁背锅,意味着谁要担责。
下边我们看看这个案例。
现场
某一个微服务的Java应用,在部署到云环境下,大概过了几个小时以后,就频繁的宕掉,自动重启,一会儿又宕掉。DevOPS马上发警告邮件,并且给出了一些error message, 甚至相关的callstack也给出来了。
java.sql.SQLTransientConnectionException: HikariPool-******* - Connection is not available, request timed out after 5001ms., at com.zaxxer.hikari.pool.HikariPool.createTimeoutException(HikariPool.java:696), at com.zaxxer.hikari.pool.HikariPool.getConnection(HikariPool.java:197), at com.zaxxer.hikari.pool.HikariPool.getConnection(HikariPool.java:162), at com.zaxxer.hikari.HikariDataSource.getConnection(HikariDataSource.java:100), at org.hibernate.engine.jdbc.connections.internal.DatasourceConnectionProviderImpl.getConnection(DatasourceConnectionProviderImpl.java:122), at org.hibernate.internal.NonContextualJdbcConnectionAccess.obtainConnection(NonContextualJdbcConnectionAccess.java:38), at org.hibernate.resource.jdbc.internal.LogicalConnectionManagedImpl.acquireConnectionIfNeeded(LogicalConnectionManagedImpl.java:108), at org.hibernate.resource.jdbc.internal.LogicalConnectionManagedImpl.getPhysicalConnection(LogicalConnectionManagedImpl.java:138), at org.hibernate.resource.jdbc.internal.LogicalConnectionManagedImpl.getConnectionForTransactionManagement(LogicalConnectionManagedImpl.java:276), at org.hibernate.resource.jdbc.internal.LogicalConnectionManagedImpl.begin(LogicalConnectionManagedImpl.java:284), at org.hibernate.resource.transaction.backend.jdbc.internal.JdbcResourceLocalTransactionCoordinatorImpl$TransactionDriverControlImpl.begin(JdbcResourceLocalTransactionCoordinatorImpl.java:246), at org.hibernate.engine.transaction.internal.TransactionImpl.begin(TransactionImpl.java:83), at org.springframework.orm.jpa.vendor.HibernateJpaDialect.beginTransaction(HibernateJpaDialect.java:164), at org.springframework.orm.jpa.JpaTransactionManager.doBegin(JpaTransactionManager.java:421), at org.springframework.transaction.support.AbstractPlatformTransactionManager.startTransaction(AbstractPlatformTransactionManager.java:400), at
就这咋一看,就是connection用完了,拿不到连接了。DB相关人员开始就有点紧张了。难道是DB出问题了?
于是他们单独给DBOps那边开了个ticket,让DBOps直接上AWS PG实例里头查看,一顿查,发现数据库活的好好的呢,在那个时间段,连接数也都还正常。这样的话,他们肯定不会背这锅。
微服务这边,在得知这些结果以后,感觉就有些不太妙了。于是再重新再去查监控:
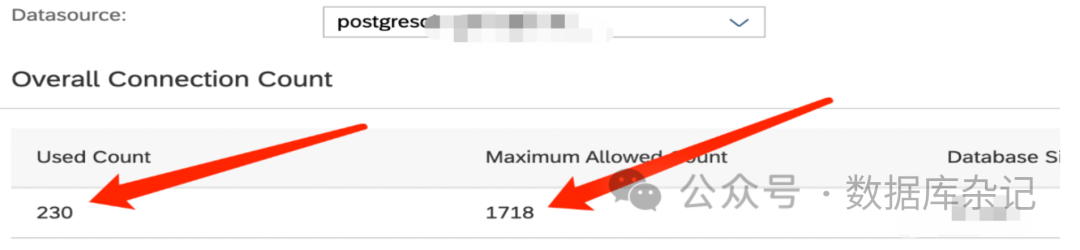
总数确实也还在那里。单独针对那众目标微服务,再看看细化的情况:
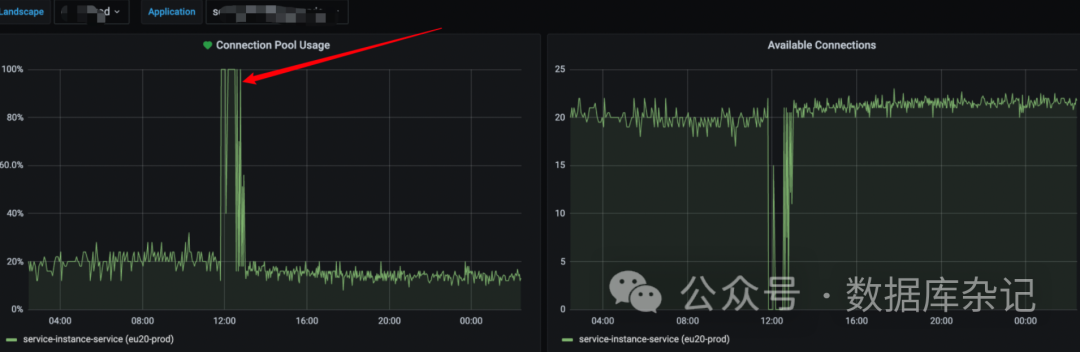
到这里,一看,200个连接瞬间被击垮。看到这里,基本上也就知道,与数据库大概率没什么关系了。应该是应用层出了什么故障了。
什么原因会导致数据库正常但是连接拿不到(不断超时、我们这里是默认5秒还拿不到连接,就算超时,app会自动重启)?
紧接着我们兵分两路:
1、再找到微服务对应的DynaTrace监控
有一个重大发现:
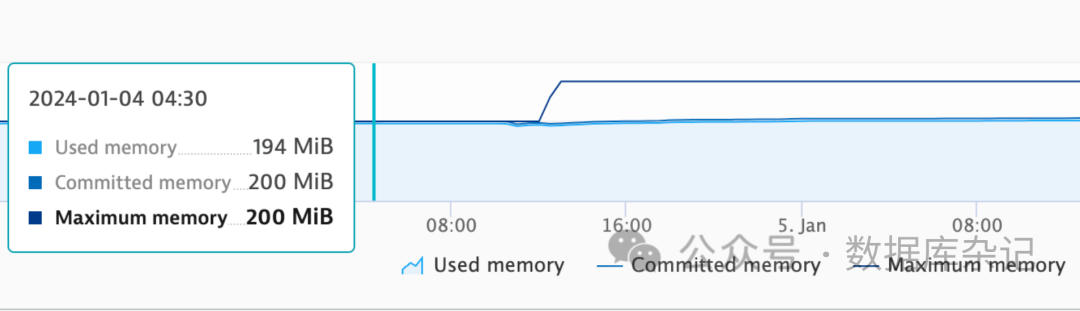
死掉的那一段时间,JVM的Metaspace那一段200MB,全部耗光。但是因为没有CF平台上没有明显的OOM报错,反而容易骗过大家。
2、再细看一下平台那边的Kibana LOG相关细节:
虽然没有:OOM之类的错误提示,却发现有若干下边这样的log:
[33281.379s][error][jvmti] Posting Resource Exhausted event: Metaspace
[33281.379s][error][jvmti] Posting Resource Exhausted event: Metaspace
Resource exhaustion event....
.......
这两条就足以印证jvm的配置参数Metaspace的大小不够,导致最后的问题。
解决方法:将原来的200M调整到300M或250M,就彻底平息了这次事故。
总结:
有的时候,问题不是孤立存在的,从各个层面进行分析,逐个排错,最后还是能找到出问题的原因。如何规避此类事件再次发生,只能进一步加强监控。
以上例为例,因为缺乏对应用层DB Pool的监控预警,比如它很快涨到200,在那一会儿,应该直接就有预警。另一块,针对metaspace耗尽之前也缺乏预警。如果到了90%左右发出预警,那我们仍然有机会重新调整参数,再次部署,一样可以避免问题。
至于引起metaspace上涨的一个主要原因,是因为新部署的app, 增加了另外几个库(合计有几十兆),从而让类的元数据所需空间增加了不少。开发人员平时也很少关注这一块。加起来,刚好快到边界,又没到边界,随着动态类的加载,慢慢又涨了一点,最终导致超标。
关于jvm参数及高优,又是一个非常大的话题:
参考:
https://cloud.tencent.com/developer/article/1408827[1]
https://poonamparhar.github.io/understanding-metaspace-gc-logs[2]
What is Compressed Class Space?[3]
[How to Handle Java Lang OutOfMemoryError Exceptions[4]](https://sematext.com/blog/java-lang-outofmemoryerror/)

上边这张图也能说明一下总的计算方法。Metaspace属于Non-heap的空间。也就是说,在计算总的开销时,它增加了,Java heap那部分就得减小。
JBP_CONFIG_SAP_MACHINE_JRE [memory_calculator_v2: {headroom: 5}]
JBP_CONFIG_SAP_MACHINE_JRE: [memory_calculator_v2: {stack_threads: 600, headroom: 5}]
JBP_CONFIG_JAVA_OPTS [ java_opts: '-Xss512K -XX:ReservedCodeCacheSize=220M -XX:MaxMetaspaceSize=200M -XX:MaxDirectMemorySize=256M -XX:+DisableExplicitGC -XX:+UseG1GC ' ]
上边用的是SAP自己的JVM(使用OpenJDK结果也一样): SAP在给定4096M总的容器内存时:
4096 - 220 - 200 - 256 - 0.05 * 4096 - 0.5 * 250 = 3090.2 M = 3164364K
当stack_threads调为600时,-Xmx2985164K
4096 - 220 - 200 - 256 - 0.05 * 4096 - 0.5 * 600 = 2915.2 M = 2985164K
围绕的公式就是:
MaxHeapSize = 总内存 - CodeCache - MetaspaceSize- DirectMemory - headroom/100 * 总内存 - Xss * Threadcount。(默认线程数是250)
headroom是预留给容器的本地内存的百分比。
这个公式通常也不见于官方文档,属于平台自己控制的。有了这个公式,就可以自己进行精准拿捏了。
还有一些jvm命令行,可以ssh到container内部执行,进行诊断,如:
1、jps -lvm
app/META-INF/.sap_java_buildpack/sap_machine_jre/bin/jps -lvm
1504 jdk.jcmd/sun.tools.jps.Jps -lvm -Dapplication.home=/home/vcap/app/META-INF/.sap_java_buildpack/sap_machine_jre -Xms8m -Djdk.module.main=jdk.jcmd
7 org.springframework.boot.loader.JarLauncher -Xmx2985164K -Xss512K -XX:ReservedCodeCacheSize=220M -XX:MaxMetaspaceSize=200M -XX:MaxDirectMemorySize=256M -XX:+DisableExplicitGC -XX:+UseG1GC -XX:-UseCompressedClassPointers -Djava.io.tmpdir=/home/vcap/tmp -Dlog4j2.formatMsgNoLookups=true -XX:+UseContainerCpuShares -agentlib:jdwp=transport=dt_socket,address=8000,server=y,suspend=n,onjcmd=y -agentpath:META-INF/.sap_java_buildpack/jvm_kill/jvmkill-1.16.0.RELEASE-trusty.so=printHeapHistogram=1 -XX:ErrorFile= -Dsun.net.inetaddr.ttl=0 -Dsun.net.inetaddr.negative.ttl=0
2、jcmdVM.flags
vcap@ade456f6-f29d-4e37-7b99-0360:~$ app/META-INF/.sap_java_buildpack/sap_machine_jre/bin/jcmd 7 VM.flags
7:
-XX:CICompilerCount=2 -XX:ConcGCThreads=1 -XX:+DisableExplicitGC -XX:ErrorFile= -XX:G1ConcRefinementThreads=1 -XX:G1HeapRegionSize=1048576 -XX:GCDrainStackTargetSize=64 -XX:InitialHeapSize=69206016 -XX:MarkStackSize=4194304 -XX:MaxDirectMemorySize=268435456 -XX:MaxHeapSize=3057647616 -XX:MaxMetaspaceSize=209715200 -XX:MaxNewSize=1833959424 -XX:MinHeapDeltaBytes=1048576 -XX:NonProfiledCodeHeapSize=0 -XX:ProfiledCodeHeapSize=0 -XX:ReservedCodeCacheSize=230686720 -XX:ThreadStackSize=512 -XX:-UseCompressedClassPointers -XX:+UseCompressedOops -XX:+UseContainerCpuShares -XX:+UseG1GC
3、jcmdGC.heap_info
e456f6-f29d-4e37-7b99-0360:~$ app/META-INF/.sap_java_buildpack/sap_machine_jre/bin/jcmd 7 GC.heap_info
7:
garbage-first heap total 1166336K, used 204288K [0x0000000749c00000, 0x0000000800000000)
region size 1024K, 113 young (115712K), 18 survivors (18432K)
Metaspace used 116011K, capacity 117599K, committed 117704K, reserved 118784K
在云环境下,PG的稳定性还是很牛气的。稳如老狗一点也不为过,除了表膨胀、空间肿胀等需要来加看管,很大一部分云平台都给你扛过去了。当然,常规的性能优化与调整也是必要的,应用层开发人员配合DBA,总能找到比较舒服的解决方案。
参考资料
[1]https://cloud.tencent.com/developer/article/1408827: https://cloud.tencent.com/developer/article/1408827
[2]https://poonamparhar.github.io/understanding-metaspace-gc-logs: https://poonamparhar.github.io/understanding-metaspace-gc-logs/
[3]What is Compressed Class Space?: https://stuefe.de/posts/metaspace/what-is-compressed-class-space/
[4][How to Handle Java Lang OutOfMemoryError Exceptions: https://sematext.com/blog/java-lang-outofmemoryerror/