开窗函数的详细用法
- 第一章、开窗函数的语法
- 1.1)从聚合开窗函数讲起
- 1.2)开窗函数之取值
- 1.3)排名开窗函数
第一章、开窗函数的语法
开窗函数的语法为:over(partition by 列名1 order by 列名2 ),括号中的两个关键词partition by 和order by 可以只出现一个。over() 前面是一个函数,如果是聚合函数,那么order by 不能一起使用。
1.1)从聚合开窗函数讲起
sum()是聚合函数,当 sum()函数 后面跟上 over()以后,由sum聚合函数就成为了开窗函数。
over() 括号里面就是定义窗口的内容了,partition 是分区,分组的意思。partition by 就是根据某个字段分组。
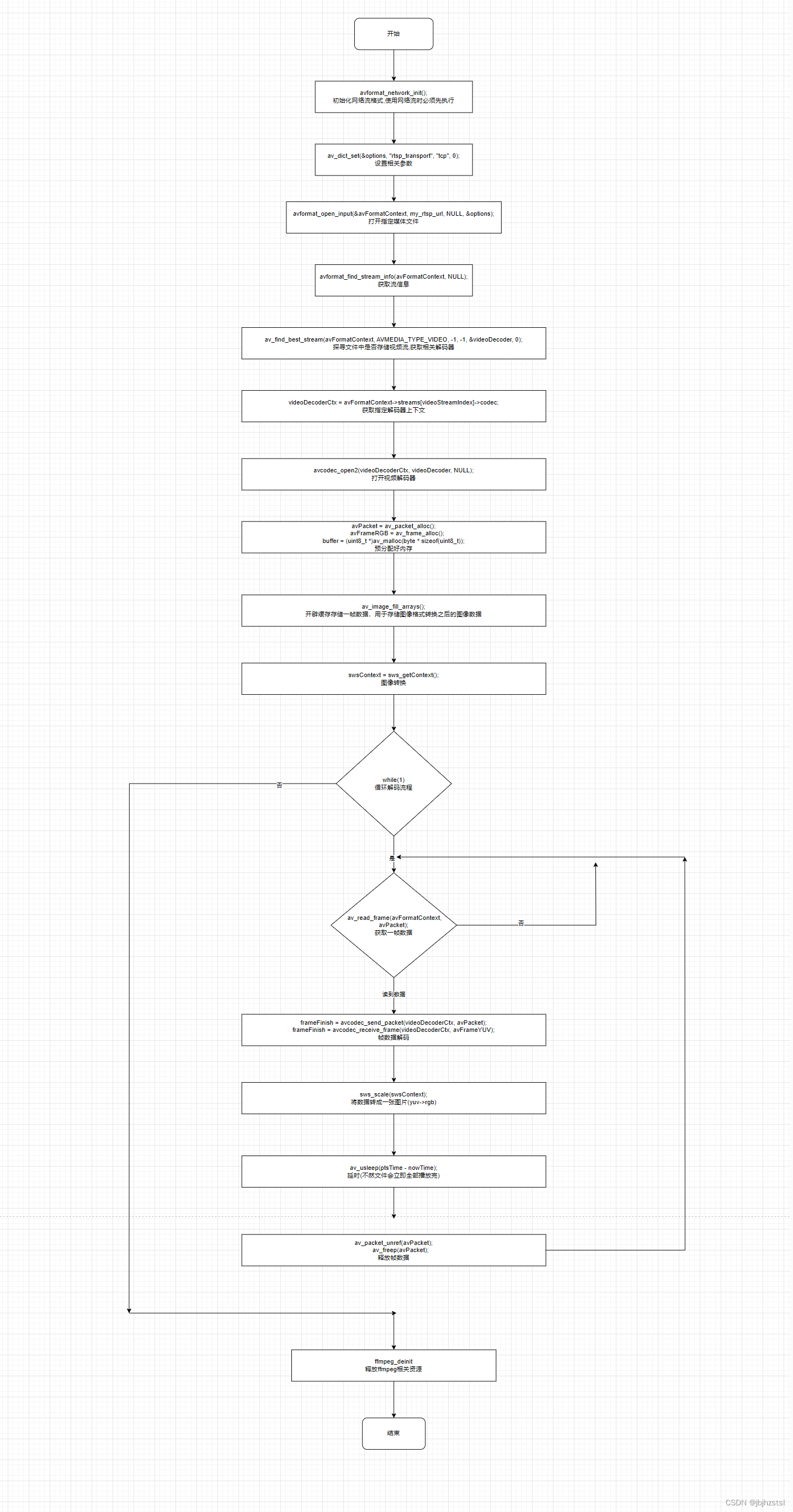
sum(score) over(partition by name )
先根据 name 分组(如图),当前面加了sum(score)后就把根据name分组后的,每个(组)窗口里面的字段 score进行求和操作。
select *,sum(score) over(partition by name) sum窗口函数举例
from kchs
-- 为了简单就只有两个字段,name和score
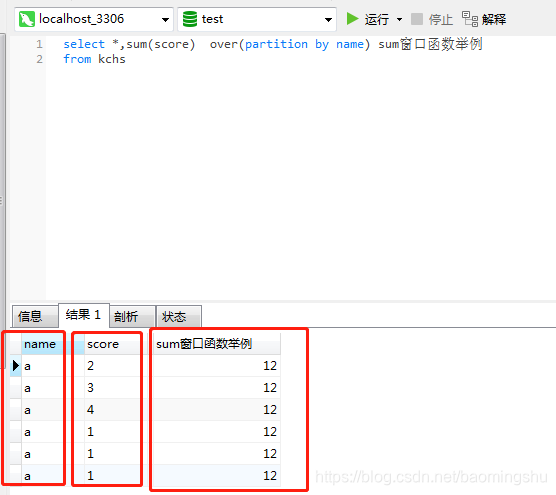
聚合函数同样需要对数据进行排序,但不会显示排名结果。会将当前名次的数据 与 排在这之前的所有数据 依次做相应的计算。
执行语句:
select *,
sum(score) over (order by id) as 累加求和
from kchs
拓展一下:
一,很多聚合函数都可以用作窗口函数的运算,如SUM、AVG、MAX、MIN、COUNT。
二,和gropu by 不同的是窗口函数会生成多行,而不是想group by 一样只有一行
1.2)开窗函数之取值
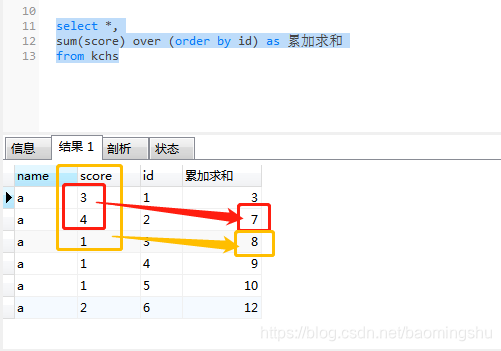
first_value
first_value
lead
lag
first_value:是在窗口里面取到第一个值
first_value(score) over( partition by name)as first_score ,
根据name分区(组),取score列的第一个值
last_value:是在窗口里面取到最后一个值
last_value(score) over(partition by name) as last_score
--根据name分区(组),取score列的最后一个值
lead 是取当前行的后 N 条数据,并且可以设置默认值
lead(score,1,0) over(partition by name ) as lead_score
--根据name分区(组),score列当前行的后面N行,,如果没有就为默认值0
lag 是取当前行的上 N 条数据,并且可以设置默认值
lag(score,1,0) over(partition by name ) as lag_score
--根据name分区(组),score列当前行的上面N行,如果没有就为默认值0
1.3)排名开窗函数
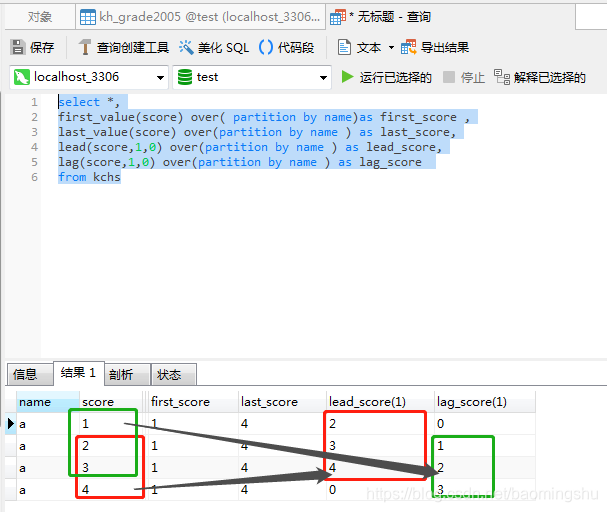
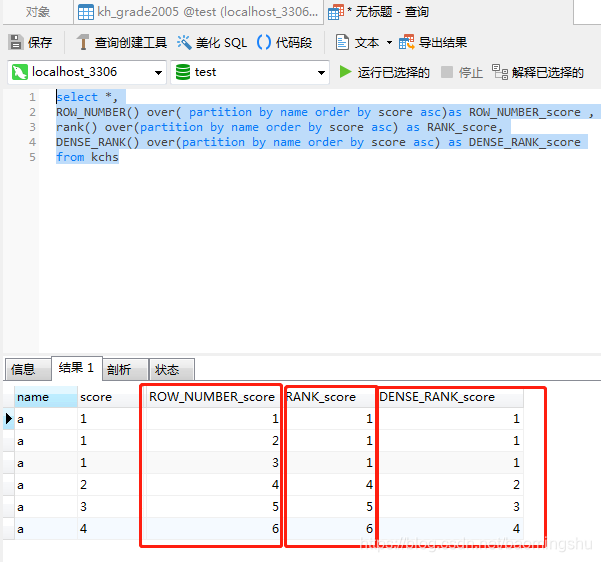
ROW_NUMBER
DENSE_RANK
RANK
row_number ()是为每组的行设置一个连续的递增的数字(123456)
ROW_NUMBER() over( partition by name order by score asc)as ROW_NUMBER_score
rank()是排名,也为每一组的行生成一个序号,如果有相同的值会生成相同的序号,并且接下来的序号是不连序的。例如:有三个人并列第一名,第四名序号为四(111456)
rank() over(partition by name order by score asc) as RANK_score
DENSE_RANK()和RANK()类似,不同的是如果有相同的序号,那么接下来的序号不会间断。例如:有三个人并列第一,第四名序号为2(111234)
DENSE_RANK() over(partition by name order by score asc) as DENSE_RANK_score
注意:
一,排名开窗函数可以单独使用ORDER BY 语句,也可以和PARTITION BY同时使用。
二,ORDER BY 指定排名开窗函数的顺序,在排名开窗函数中必须使用ORDER BY语句。
三,PARTITION BY用于将结果集进行分组,开窗函数应用于每一组。


![【PyTorch][chapter 24][李宏毅深度学习][ CycleGAN]【理论】](https://img-blog.csdnimg.cn/direct/04d3c96000264df3b9a7dfd097952ebf.png)