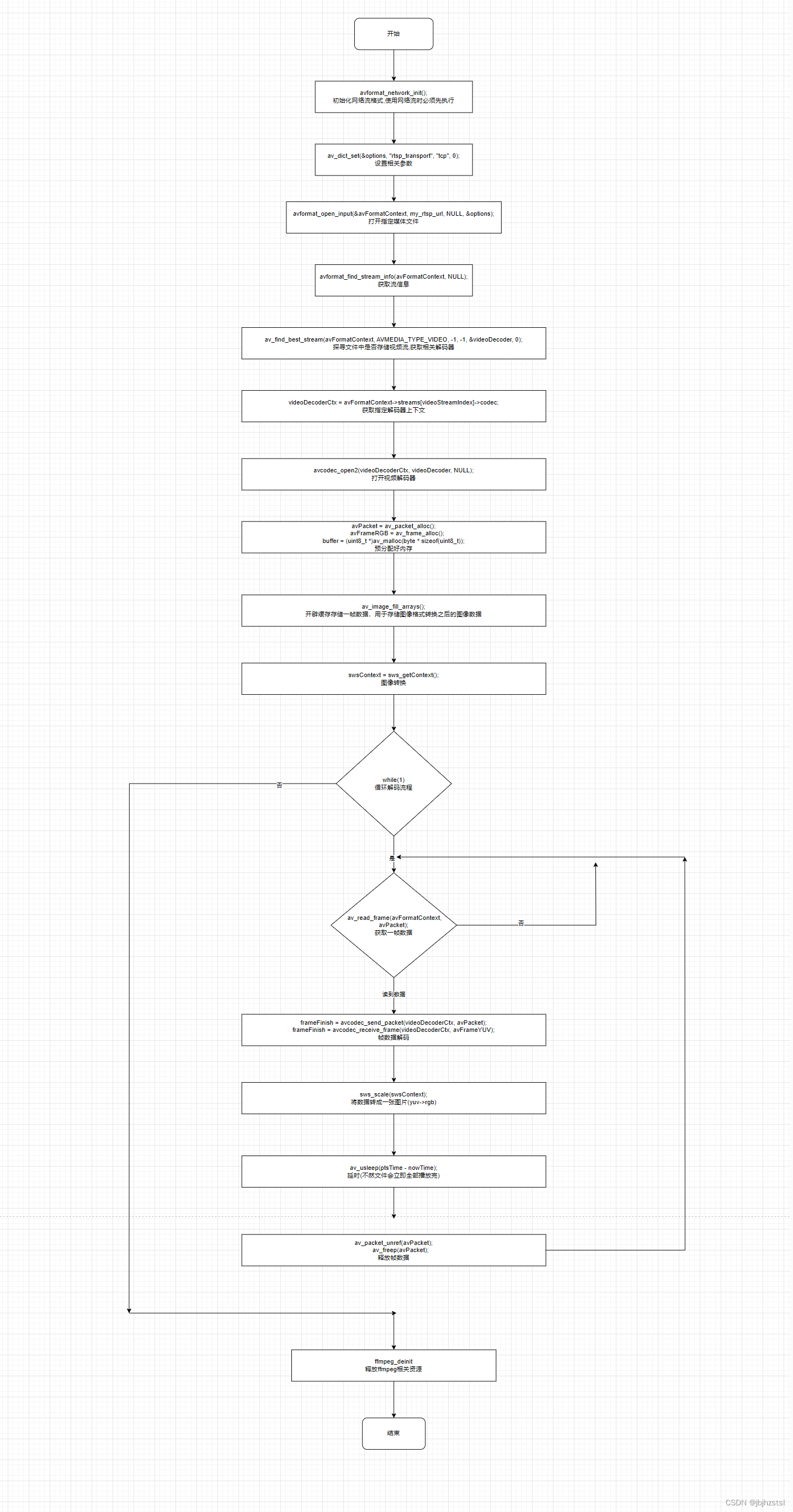
摘要(Abstract):
本篇主要参考论文分享一下CycleGAN.
CycleGAN是实现不同图像之间风格的转换,并且样本数据无需配对即可实现转换
图像到图像的转换是一类视觉和图形问题,其目标是使用对齐图像对的训练集来学习输入图像和输出图像之间的映射(Pix2Pix)。然而,对于许多任务,无法得到配对训练数据训练数据集。CycleGAN提出了一种在没有配对示例的情况下学习将图像从源域 X 转换到目标域 Y 的方法。
CycleGAN的目标是学习映射 G:X→Y,使得 生成图像G(X) 中的图像分布与使用对抗性损失的分布 Y 无法区分。由于这种映射高度受限,我们将其与逆映射 F:Y→X 结合起来,并引入循环一致性损失来推动F(G(X))≈X(反之亦然)。在不存在配对训练数据的几个任务上给出了定性结果:
包括集合风格迁移、对象变形、季节迁移、照片增强等。与几种现有方法的定量比较证明了我们方法的优越性。风格迁移GAN 也能做,但是GAN问题是输入的图像x 和输出的图样 是一种无意义的配对,无法达到以下效果.

目录:
- 简介
- 相关工作
- 原理阐述
- 实现
- 实验结果
- 限制与讨论
一 简介(Introduction)
CycleGAN的创新点在于能够在源域和目标域之间,无须建立训练数据间一对一的映射,就可以实现这种迁移,更重要的是生成新的图片和原始图片是一种有意义的配对.
这里重点介绍一下该图像转换领域的背景技术:
1.1 Pix2Pix 问题
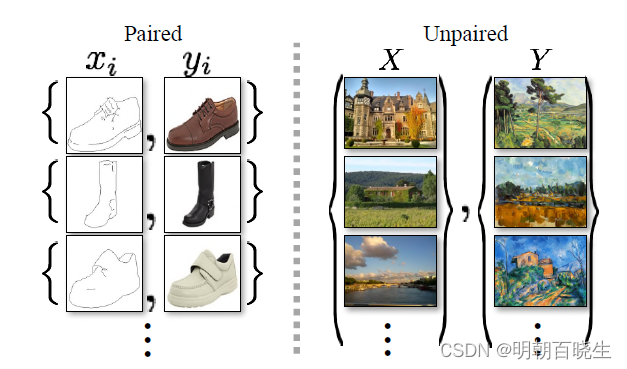
也是风格转换的模型,但是是基于paired 训练数据集的
如上图:
图(左)配对训练 :由训练示例组成,存在一一映射关系。
图(右)无配对训练,由源集和目标集组成,无明确的映射关系。
问题:
获得配对训练数据可能很困难而且很贵
1.2 GAN 问题
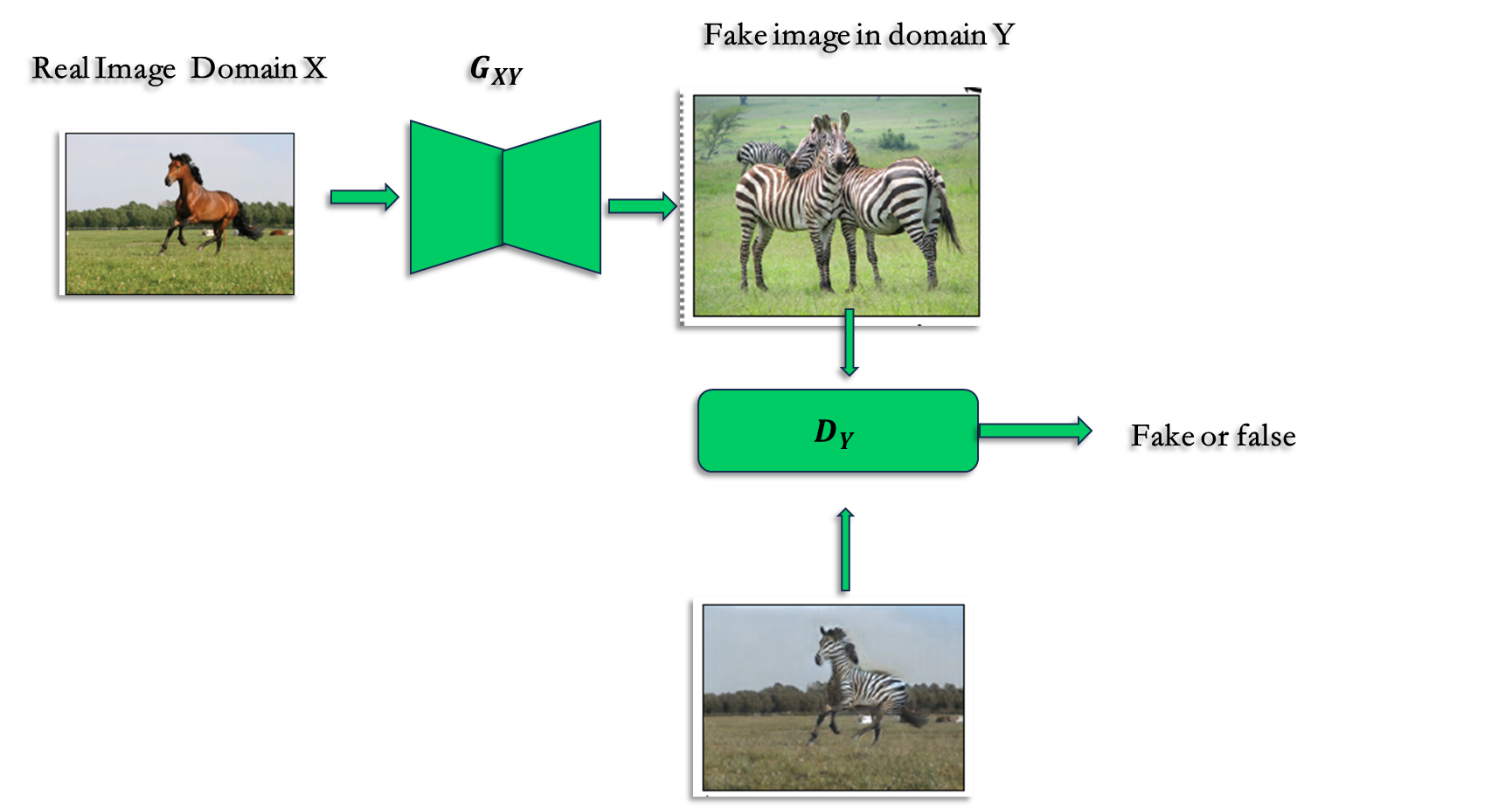
也是风格转换的模型,基于Unpaired 训练数据集的
训练集为一组图像域 X 和 Y 中的不同集合。
我们通过GAN网络训练映射使得输出,与Y域的图像 y 无法区分.
问题:
这样的风格转换并不能保证输入x和输出以有意义的配对方法 如上图,一匹马生成了两匹斑马,鉴别器识别依然会是True. 但是跟输入就没有映射关系.
1.3 CycleGAN 方案
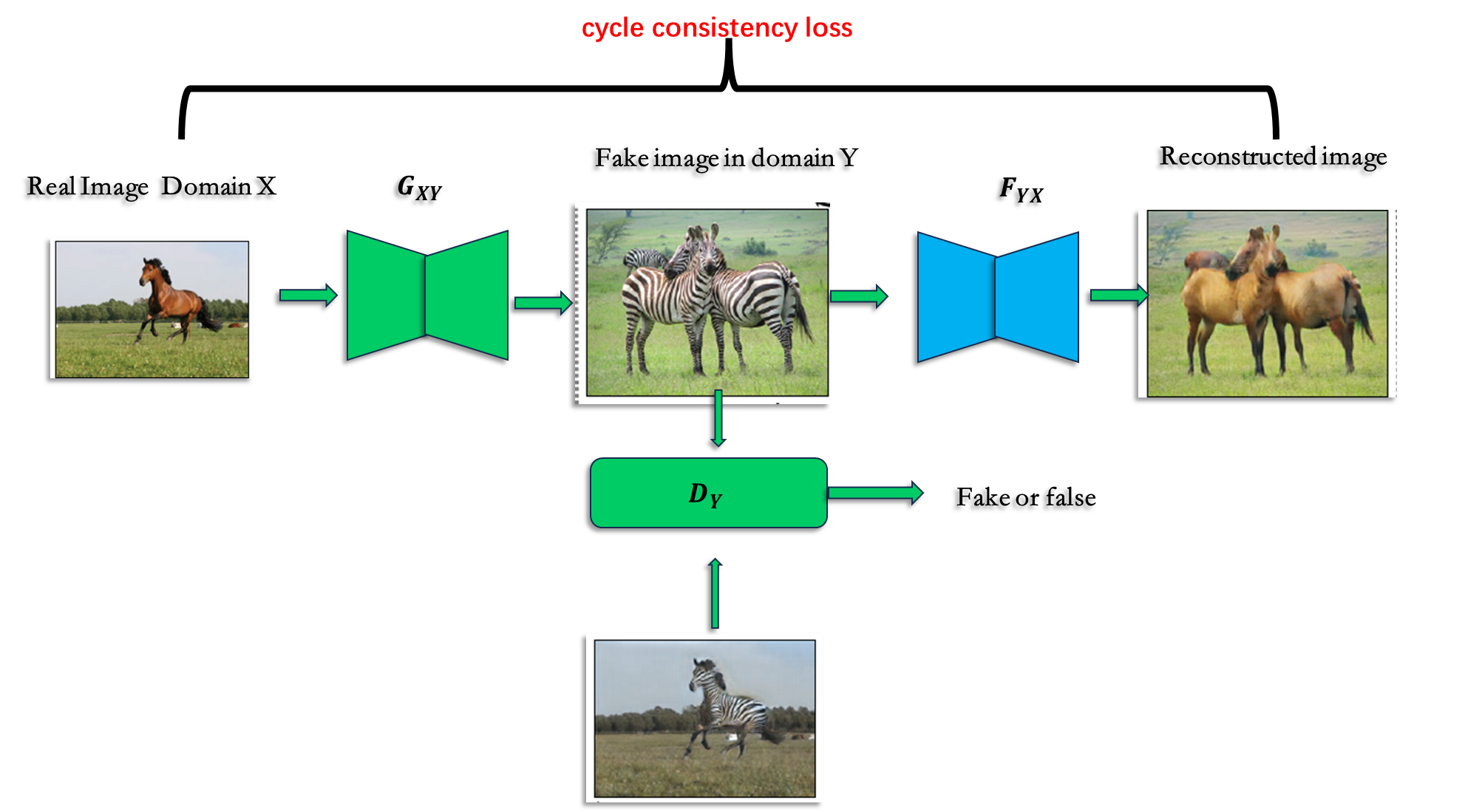
解决方案: 循环一致性约束cycle consistent,使得输入和输出有映射关系
我们已经有了一个生成器
增加一个循环 生成器:
通过增加 a cycle consistency loss 来保证 x 和输出 成为有意义的映射
二 相关工作(relate work)
2.1 Generative Adversarial Networks (GANs)
生成对抗网络 (GAN)在图像生成方面取得了令人印象深刻的成果,
例如:text2image 、image inpainting ,future prediction,在其它领域
例如视频,3D数据也获得了成功.
GAN 的成功源于对抗性损失的理念(adversarial loss),这种损失迫使
生成的图像原则上是无法区分的来自真实照片.在图像生成任务中,adversarial loss 作用特别强大 .cycleGAN 也采用了的对抗性损失,使得翻译后的图像无法与目标中的图像区分开
领域。
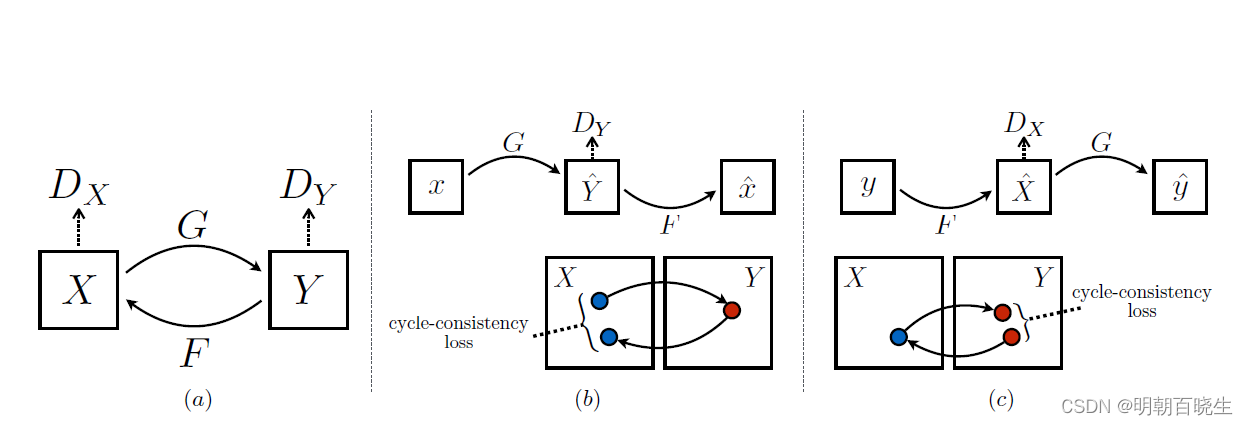
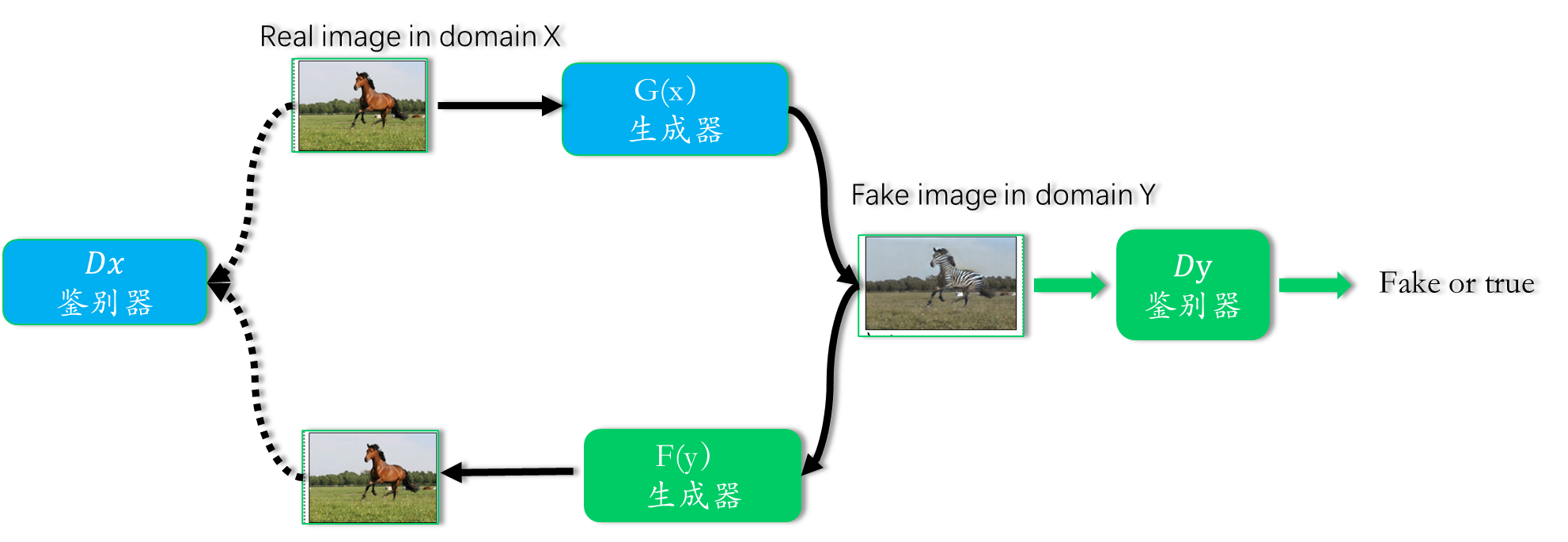
图(a): 模型包含两个映射函数(生成器)
以及对应的鉴别器
: 鉴别图像是否来自生成的图片,还是Y域的图像
: 鉴别图像是否来自生成的图片,还是X域的图像
为了进一步规范映射,我们引入了两个循环一致性损失,它们捕捉了这样的直觉:如果 我们从一个域转换到另一个域,然后再返回,我们应该到达我们开始的地方.
图(b) 正向循环一致性损失(forward cycle-consistency loss)
生成器G将X域的图像转换为Y域的图像, 再通过生成器F将Y域的图像
转换为X域的图像:
要尽可能的相似
图(c) 反向循环一致性损失(backward cycle-consistency loss)
论文中也提到了跟该领域的一些其它模型的区别
2.2 Image-to-Image Translation
图像到图像的转换想法至少可以追溯到 Hertzmann 等人的
图像类比: 基于在单个输入输出 pair的训练图像 ,用于学习图像之间的纹理 。
更近一点的方法 在CNN上使用 input-output 训练集 去学习.
我们的方案使用pix2pix 框架,去学习一个输入到输入图像的pair映射.
2.3 Unpaired Image-to-Image Translation
其他几种方法也解决了不配对的情况,其目标是
关联两个数据域: X 和 Y 。
Rosales等人提出一个贝叶斯框架,其中包括基于先验的
在基于patch-based 的马尔可夫随机场上计算源图像和风格图像之间的极大似然估计。
CoGAN 和 cross-model 场景网络[1]使用权重共享策略来学习
跨域的通用表示。
Liu等人将上述框架扩展为变分自动编码器 和生成式的组合对抗性网络。
另一条并发线工作 鼓励输入和输出共享特定的“内容”特征,尽管它们可能有所不同
“风格”。这些方法还使用对抗性网络,强制输出接近输入的附加项在预定义的度量空间中,例如类标签空间,图像像素空间和图像特征空间。
与上述方法不同 ,cycleGAN 的公式并不依赖于任何特定于任务的、预定义的相似性函数
输入和输出,我们也不假设输入和输出必须位于相同的低维嵌入中
空间。这使得我们的方法成为通用解决方案适用于许多视觉和图形任务。
2.3 Cycle Consistency
这个思想是这篇论文的核心创新点
使用传递性作为规范结构化数据的方法有着悠久的历史。
在视觉跟踪领域,强制执行简单的前后一致性几十年来一直是标准技巧 。
在语言领域,验证和改进翻译通过“反向翻译和协调”是一种由人工翻译人员使用技术。
最近,高阶循环一致性已被用于
structure from motion、3D shape matching 、cosegmentation,dense semantic alignment
depth estimation。其中,Zhou Godard等人 与我们的工作最相似,因为他们使用
循环一致性损失作为使用传递性进行监督的一种方式CNN 训练。
在这项工作中,我们将介绍一个类似的损失推动 G 和 F 彼此保持一致
2.4 Neural Style Transfer
神经风格转移
是另一种方式执行图像到图像的转换, 通过将一幅图像的内容与基于的另一幅图像(通常是一幅画)的风格合成. 原理:通过神经网络得到特征后,通过Gram matrix 作为损失函数 另一方面,我们的首要重点是学习两个图像集合之间的映射,而不是之间的映射 两个特定的图像,通过尝试捕捉对应关系高层外观结构之间。所以, 我们的方法可以应用于其他任务,例如绘画!照片、物体变形等,其中单个样品转移方法效果不佳。
三 原理阐述(Formulation)
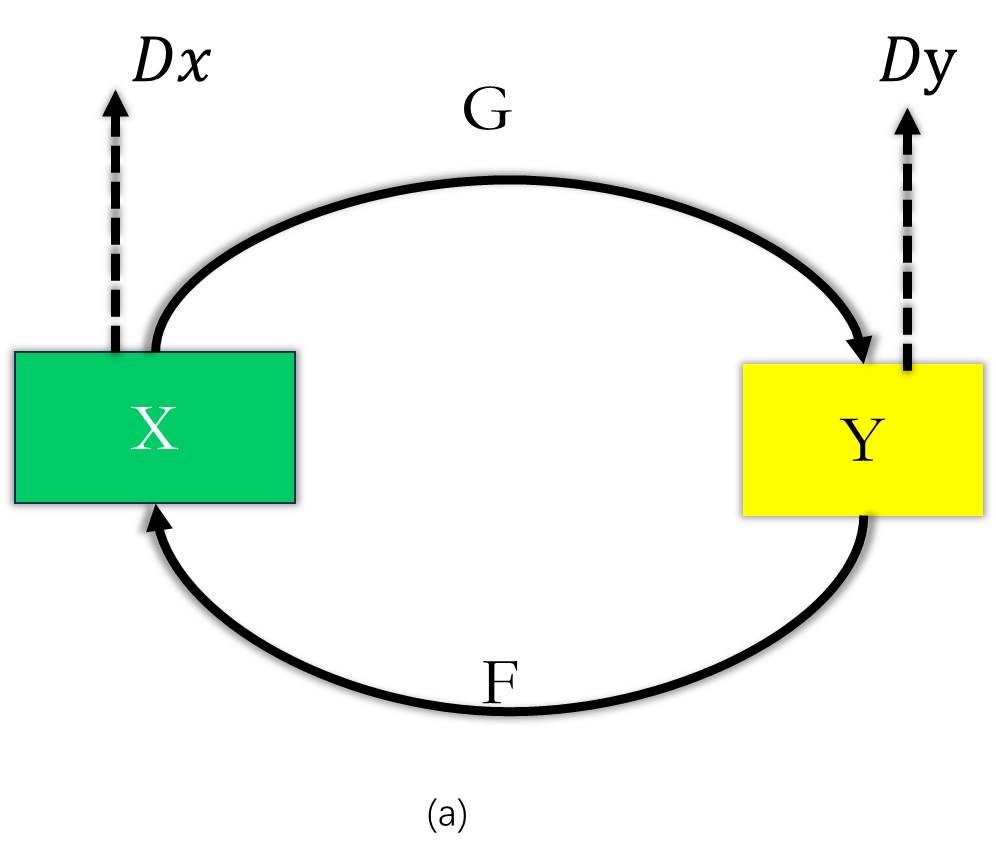
我们的目标是学习 X域和Y 域之间的映射函数.
给定训练样本集: ,
数据的概率分布为:,
如图(a) 我们的模型包含两个映射 and
此外还包含两个鉴别器 .
目标: 鉴别图片是来自域
还是域
目标: 鉴别图片是来自域
还是域
我们的目标包含两种类型损失:
对抗性损失[adversarial losses]:
用于学习目标图像的分布
循环一致性损失[cycle consistency losses]
以防止学到的映射 G 和 F 彼此矛盾,保证 x 和输出 成为有意义的映射
3.1 Adversarial Loss
这个跟GAN的原理是一样的,优化的目标是
![]()
![]()
公式(1) G尝试生成类似Y域的样本G(x), 旨在区分 真实的样本y和生成样本G(x)。
生成器G的目标是最小化该损失函数, 鉴别器的目标是最大化该损失函数.
公式(2) 同理
3.2 Cycle Consistency Loss

GAN 能保证单个输入映射到一类风格的图片,无法保证转换后的图像包含原图像的信息.
为了保证能映射到期望的
,我们引入了循环一致性(cycle-consistent)约束
cycle consistency loss:
![]()
在初步实验中,我们还尝试替换在
之间具有对抗性损失的这个损失中的范数
和x之间,以及和y之间,但没有观察到提高了性能。
3.3 Full Objective
![]()
控制两个目标的相对重要性。 我们的目标是解决:
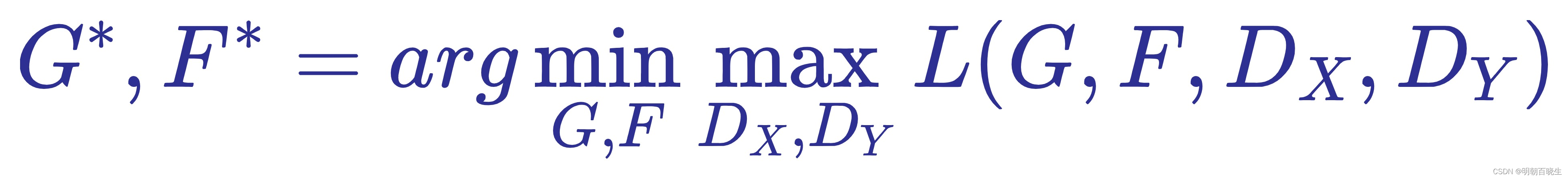
3.4 Identity Loss
这是原论文中没有提到的,但是在代码中有提到.
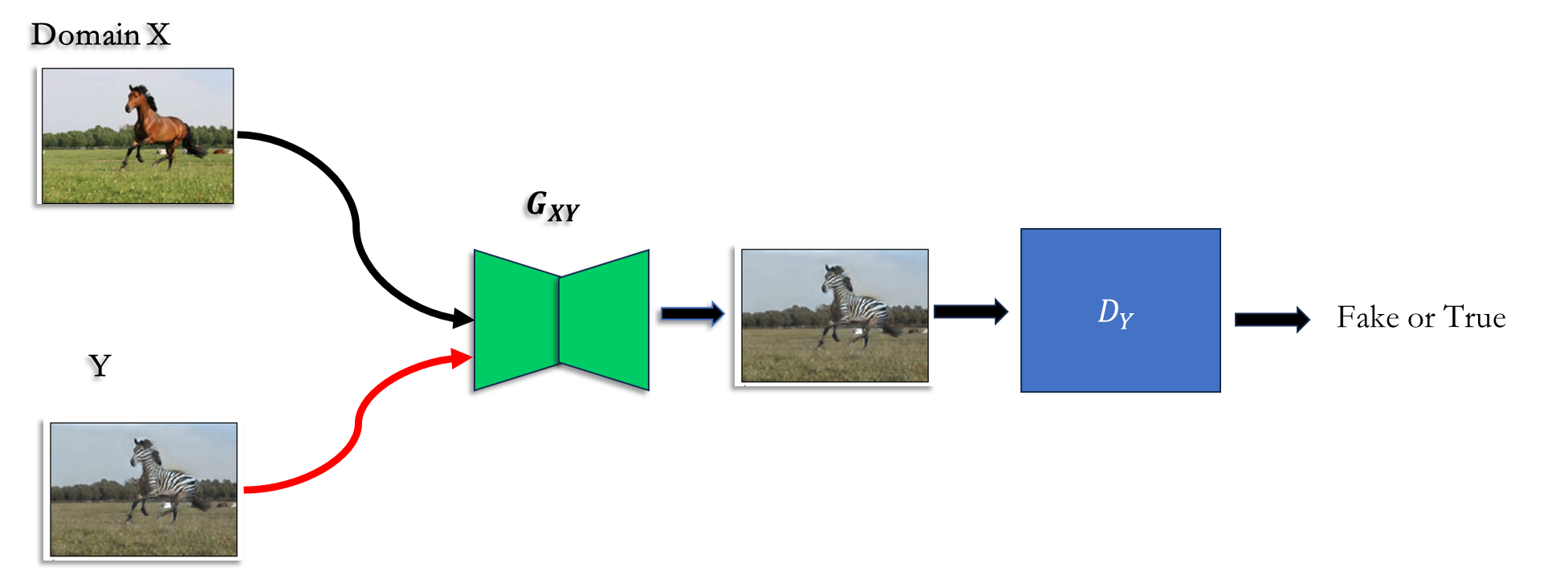
如上图:
输入一张马通过生成器G(X) 期望得到斑马Y
输入一张斑马Y 通过生成器G(Y),依然期望得到斑马Y
四 实现(Implementation)
4.1 网络架构Network Architecture
由两个GAN模型组成,GAN 里面的生成器鉴别器使用的是ResNet 结构.
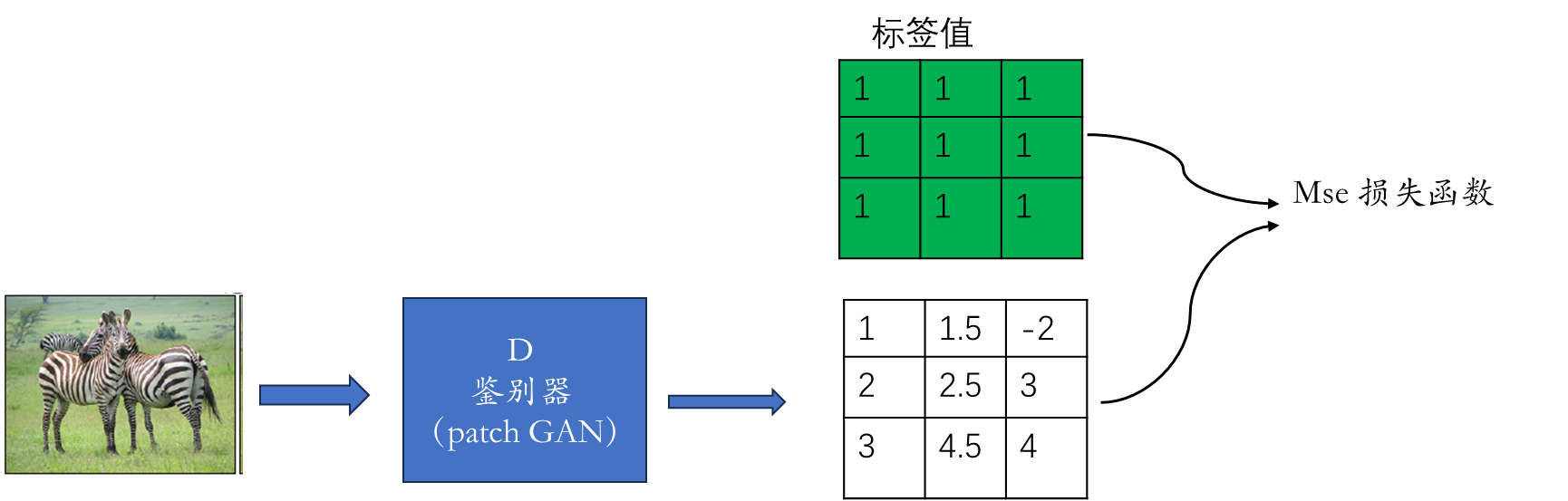
在鉴别器中使用了PatchGAN(70X70的特征矩阵,代表Fake or True)
4.2 PatchGAN
gan鉴别器最终输出的是一个(0,1)的标量,代表概率。
CycleGan 鉴别器输出的是一个(N*N)矩阵,矩阵中每个元素相同于提取的原图像的一类特征.
4.2 训练细节(Training details)
(1) 损失函数的差异
使用了least-squares loss ,而不是 negative log likelihood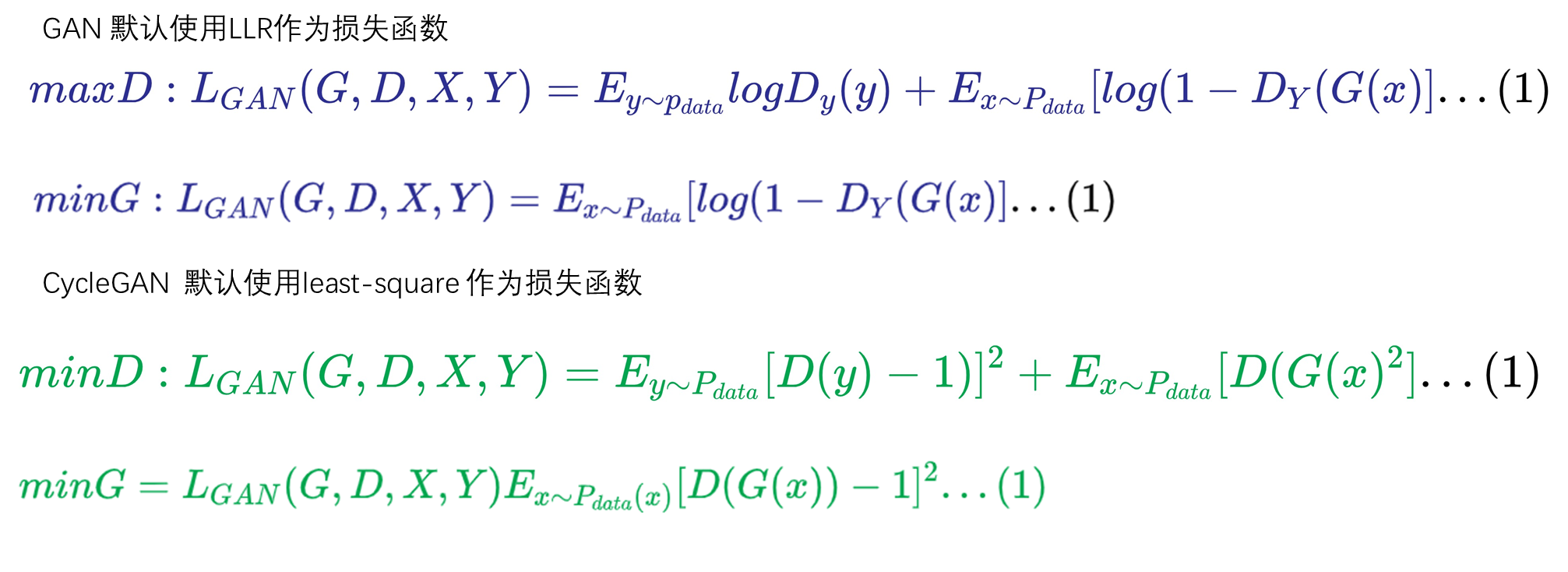
(2) 生成图片的采样
其次,为了减少模型振荡,我们遵循
Shrivastava 等人的策略 并更新判别器
使用生成图像的历史记录而不是
由最新生成器生成的。我们保留一个图像缓冲区,
保留之前生成的50张图像。
.
(3) 超参数设置

五 结果 Result
重点讲了跟其它模型在一些通用数据集上面的性能对比结果

六 限制和讨论(Limitations and Discussion)

尽管我们的方法可以取得引人注目的结果
在许多情况下,结果并不好。Figure-17显示几种典型的失败.
如图中斑马转换生成器,把骑马的人一起转换了.
这种失败可能是由我们量身定制的生成器架构引起的。
该生成器主要针对外观变化有良好的表现.
处理更加多样化和极端的变换,尤其是几何变换
变化,是今后工作的重要课题。
一些故障案例是由训练数据集分布特性引起的。
例如,在horse->zebra 转换示例中(Figure17)(图 17,
右),因为我们的模型是在 horse & zebra ImageNet上训练的,
没有包含一个骑着斑马或者马的人的数据集。
我们还观察到paired training data 和 unparired training 结果之间存在挥之不去的差距
在有些场景下这种差距很难或者不可能接近。 比如 unparired training 例如,我们的
方法有时会排列树木和建筑物的标签在 photos->labels 任务的输出中.
解决这个歧义问题可能需要某种形式的弱语义监督训练。
整合弱或半监督数据可能会导致给更强大的translators,但仍然只占一小部分
完全监督系统的注释成本。
尽管如此,在许多情况下,完全不配对的数据是资源丰富,应该充分利用。
环境
当然论文中也列举了一些成功的案例

https://github.com/pytorch/vision/blob/main/torchvision/models/resnet.py
ResNet18详细原理(含tensorflow版源码)_resnet18网络结构-CSDN博客
风格迁移——Cycle对抗生成网络(CycleGAN)原理介绍及实践 - 知乎
论文地址:https://arxiv.org/abs/1703.10593
官方代码: GitCode - 开发者的代码家园
论文解读视频1:
精读CycleGAN论文-拍案叫绝的非配对图像风格迁移_哔哩哔哩_bilibili
3小时带你吃透!基于CycleGan开源项目实战图像合成,这是我见过最简单的【生成对抗网络】教程!!神经网络与深度学习|人工智能_哔哩哔哩_bilibili