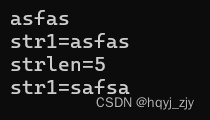
各位同学好,今天开始和各位分享一下python网络爬虫技巧,从基本的函数开始,到项目实战。那我们开始吧。
1. 基本概念
这里简单介绍一下后续学习中需要掌握的概念。
(1)http 和 https 协议。http是超文本传输,接收HTML页面的方法,服务器80端口。https是http协议的加密版本,服务端口是443端口。
(2)URL 统一资源定位符。形如:scheme://host:port/path/?query-string=xxx#anchor
以 https://www.bilibili.com/video/BV1eT4y1Z7NB?p=3 为例
scheme:访问协议,一般为 http 或 https。
host:主机名,域名。上面的 www.bilibili.com
path:查找路径。video/BV1eT4y1Z7NB 就是 path
port:端口号,访问网站时浏览器默认 80 端口
query-string:查询字符串。如上面的 ?p=3,如有多个,用&分隔
anchor:锚点。后台不用管,是前端用来做页面定位的。相当于现在停留的位置是网页的第几个小节。
注:在浏览器中请求一个url,浏览器会对url进行编码。除英文字母,数字和部分符号外,其他全部使用百分号和十六进制码值进行编码。中文字词需要重新编码后再发送给服务器
(3)常用的请求方法
GET 请求。只从服务器获取数据下来(下载文件),并不会对服务器资源产生任何影响的时候使用GET请求。
POST 请求。向服务器发送数据(登录),上传文件等,会对服务器资源产生影响时使用POST请求
2. urllib 库
urllib 库是 python3 中自带的网络请求库,可以模拟浏览器的行为,向服务器发送一个请求,并可以保存服务器返回的数据。
2.1 urlopen 函数
用于打开一个远程的 url 连接,并且向这个连接发出请求,获取响应结果。返回的结果是一个 https 响应对象,这个响应对象中记录了本次 https 访问的响应头和响应体。
使用方法为:
urllib.request.urlopen(url, data=None, [timeout,]*, cafile=None, capath=None, cadefault=False,context=None)参数:
url: 需要打开的网址
data:字节流编码格式,可以用 urllib.parse.urlencode() 和 bytes() 方法转换参数格式,如果要设置了data参数,则请求方式为POST
timeout: 设置网站的访问超时时间,单位:秒。若不指定,则使用全局默认时间。若请求超时,则会抛出urllib.error.URLError异常。
返回值:
http.client.HTTPResponse对象: 返回类文件句柄对象,有read(size),readline,readlines,getcode方法。read(size)若不指定size,则全部读出来。readline读取第一行。readlines返回值以多行的形式读出来。
getcode(): 获取响应状态。返回200,表示请求成功,返回404,表示网址未找到。
geturl(): 返回请求的url。
from urllib import request
# 打开网站,返回响应对象resp
resp = request.urlopen('https://www.baidu.com')
# 通过.read()读取这个网页的源代码,相当于在百度页面右键检查
print(resp.read())
# 返回网页信息
print(resp.getcode()) #状态码
# 200resp.read() 返回类似如下信息,这里只显示部分
b'<html>\r\n<head>\r\n\t<script>\r\n\t\tlocation.replace(location.href.replace("https://","http://"));
\r\n\t</script>\r\n</head>\r\n<body>\r\n\t<noscript><meta http-equiv="refresh" content="0;
url=http://www.baidu.com/"></noscript>\r\n</body>\r\n</html>'2.2 urlretrieve 函数
直接将远程数据下载到本地,方法如下:
rlretrieve(url, filename=None, reporthook=None, data=None)参数:
url:下载链接地址
filename:指定了保存本地路径,若参数未指定,urllib 会生成一个临时文件保存数据。
reporthook:是一个回调函数,当连接上服务器、以及相应的数据块传输完毕时会触发该回调,我们可以利用这个回调函数来显示当前的下载进度。
data:指 POST 导服务器的数据,该方法返回一个包含两个元素的( filename,headers ) 元组,filename 表示保存到本地的路径,header 表示服务器的响应头
# 将百度的首页下载到本地
from urllib import request
# 下载某一张图片,传入图像的url和保存路径
request.urlretrieve('https://gimg2.baidu.com/image_search/src=http%3A%2F%2Fnimg.ws.126.net%2F%3Furl%3Dhttp%253A%252F%252Fdingyue.ws.126.net%252F2021%252F1010%252F90f82dafj00r0q72d001jc000hs009uc.jpg%26thumbnail%3D650x2147483647%26quality%3D80%26type%3Djpg&refer=http%3A%2F%2Fnimg.ws.126.net&app=2002&size=f9999,10000&q=a80&n=0&g=0n&fmt=jpeg?sec=1642840179&t=888aee0d4f561d7238b290c9da876362',
'C:/Users/admin/Documents/Downloads/test1.jpg')
# 下载成功后返回:
('C:/Users/admin/Documents/Downloads/test1.jpg',
<http.client.HTTPMessage at 0x26b86c85a60>)2.3 urlencode 函数
用浏览器发送请求时,如果 url 中包含了中文或其他特殊字符,那么浏览器会自动进行编码。
如果使用代码发送请求,必须手动进行编码,这时需要 urlencode 函数实现。urlencode 把字典数据转换为url编码的数据
方法如下:
urllib.parse.urlencode( 字典 )下面,对张三使用%和十六进制重新编码,键和键之间使用&号连接,空格使用+号连接
from urllib import parse
# 自定义一个字典,后续用于重新编码
params = {'name':'张三','age':18, 'greet':'hello world'}
# 对字典编码
result = parse.urlencode(params)
print(result)
# 除英文和数字外都使用 %号和十六进制来编码
# 打印结果
name=%E5%BC%A0%E4%B8%89&age=18&greet=hello+world实际使用:
如果网址中有中文,需要先将中文从中分割出来,以字典的方式重新编码转换后,再拼接到网址中。
from urllib import parse
# url = 'https://www.baidu.com/s?wd=周杰伦' # 直接用于网络请求时,ascii码不能识别
# 使用方法
url = 'https://www.baidu.com/s'
# 定义一个字典
params = {'wd':'周杰伦'}
# 对中文编码
qs = parse.urlencode(params)
print(qs) #打印编码结果
# 拼接到网址url后面
url = url + '?' + qs
print(url)
# 网络请求,得到网页中的数据
resp = request.urlopen(url)
print(resp.read())打印结果分别为
wd=%E5%91%A8%E6%9D%B0%E4%BC%A6
https://www.baidu.com/s?wd=%E5%91%A8%E6%9D%B0%E4%BC%A6
b'<html>\r\n<head>\r\n\t<script>\r\n\t\tlocation.replace(location.href.replace("https://","http://"));
\r\n\t</script>\r\n</head>\r\n<body>\r\n\t<noscript><meta http-equiv="refresh" content="0;
url=http://www.baidu.com/"></noscript>\r\n</body>\r\n</html>'2.4 parse_qs 函数
将经过编码后的 url 参数解码,返回字典类型,方法如下:
urllib.parse.urlencode( url )应用:
from urllib import parse
# 先对中文进行编码
params = {'name:':'张三','age':18,'greet':'hello world'}
qs = parse.urlencode(params)
print('编码后:',qs)
# 对编码后的结果解码
result = parse.parse_qs(qs)
print('解码后:', result)打印结果如下:
编码后: name%3A=%E5%BC%A0%E4%B8%89&age=18&greet=hello+world
解码后: {'name:': ['张三'], 'age': ['18'], 'greet': ['hello world']}2.4 urlparse 和 urlsplit 函数
分割 url 中的各个组成部分,分割成 scheme,host,path,params,query-string,anchor,具体含义看最上面。
这两个函数的区别是:urlsplit 不返回 params,但是这个参数params基本用不到。
(1)urlparse 方法
urllib.parse.urlparse(urlstring, scheme='', allow_fragments=True)urlstring: 待解析的URL,必填项
scheme: 默认的协议,如 http 或 https 等。
allow_fragments: 即是否忽略fragment。若设为 False,fragment 部分就会被忽略,它会被解析为 path、parameters 或 query 的一部分,而 fragment 部分为空。
返回值为所有分割后的结果
# 使用 urlparse 方法
from urllib import parse
# 给出一个url网址
url = 'https://blog.csdn.net/dgvv4?spm=1001.5501#1'
# 使用 urlparse 解析分割 url 中的组成部分
result = parse.urlparse(url)
print(result) # 获取所有属性
print('scheme:', result.scheme) # 获取指定属性返回值如下:
ParseResult(scheme='https', netloc='blog.csdn.net', path='/dgvv4', params='', query='spm=1001.5501', fragment='1')
scheme: https(2)urlsplit 方法
# 使用 urlsplit 方法
from urllib import parse
# 给出一个url网址
url = 'https://blog.csdn.net/dgvv4?spm=1001.5501#1'
# 使用 urlparse 解析分割 url 中的组成部分
result = parse.urlsplit(url)
print(result)
print('scheme:', result.scheme)
返回值如下,返回结果没有params参数
SplitResult(scheme='https', netloc='blog.csdn.net', path='/dgvv4', query='spm=1001.5501', fragment='1')
scheme: https2.5 Request 函数
如果在请求时增加一些请求头,防止网页发现是爬虫,避免爬虫失败。那么就必须使用resquest.Resquest() 类来实现。比如要增加一个User-Agent。
from urllib import request, parse
# 输入请求
url = 'http://www.acga......com/'
# 输入浏览器页面的User-Agent请求头,使请求头更加像这个浏览器
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.110 Safari/537.36 Edg/96.0.1054.62',
'Refer':'http://www.acganime.com/'}
# data需要经过urlencode重新编码后才能传进去
data = {
'first' : True,
'pn' : 1, #第几页
'kd' : 'cos' }
# 重新编码
data = parse.urlencode(data)
# 编码类型转换成utf-8
data = data.encode('utf-8')
# 使用request.Request,添加请求头,只是定义好了一个类,并没有发送请求
req = request.Request(url, headers=headers, data=data, method='POST') #请求方式为get
# 使用 urlopen 方法获取网页信息
resp = request.urlopen(req) #传入添加请求头后的类
print(resp.read().decode('utf-8')) # 转换成utf-8显示结果返回爬取的网页数据:
<!DOCTYPE html>
<html lang="zh-CN">
<head>
<meta charset="UTF-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge,chrome=1">
<meta name="renderer" content="webkit">
<!-- <meta name="referrer" content="no-referrer" /> -->
<meta name="viewport" content="initial-scale=1.0,maximum-scale=5,width=device-width,viewport-fit=cover">
.........................................................推广,发起网络请求的计算机的IP地址,可从如下活动获得: