参考
-
《深入剖析 Kubernetes(张磊)》
-
补充 详解 Calico 三种模式(与 Fannel 网络对比学习)_calico vxlan-CSDN博客
容器网络
容器的网络栈
-
每个容器有自己的 net namespace
- net namespace 可以称之为网络栈
- 所谓“网络栈”,就包括了:网卡(Network Interface)、回环设备(Loopback Device)、路由表(Routing Table)和 iptables 规则。对于一个进程来说,这些要素,其实就构成了它发起和响应网络请求的基本环境。
-
直接使用宿主机的网络栈(–net=host),即:不开启 Network Namespace
-
$ docker run –d –net=host --name nginx-host nginx -
这个容器启动后,直接监听的就是宿主机的 80 端口。
-
可能带来的问题 —— 容器需要的端口与宿主机的㐰冲突
- 像这样直接使用宿主机网络栈的方式,虽然可以为容器提供良好的网络性能,但也会不可避免地引入共享网络资源的问题,比如端口冲突。所以,在大多数情况下,我们都希望容器进程能使用自己 Network Namespace 里的网络栈,即:拥有属于自己的 IP 地址和端口。
-
-
这个被隔离的容器进程,该如何跟其他 Network Namespace 里的容器进程进行交互呢?
- 在 Linux 中,能够起到虚拟交换机作用的网络设备,是网桥(Bridge)。它是一个工作在数据链路层(Data Link)的设备,主要功能是根据 MAC 地址学习来将数据包转发到网桥的不同端口(Port)上。
- 可以把容器视为独立的主机,网桥视为交换机
- Docker 项目会默认在宿主机上创建一个名叫 docker0 的网桥,凡是连接在 docker0 网桥上的容器,就可以通过它来进行通信。
- 如何把这些容器“连接”到 docker0 网桥上呢? —— 如何把这些容器“连接”到 docker0 网桥上呢?
- veth-pair 可以视为网线
- 它被创建出来后,总是以两张虚拟网卡(Veth Peer)的形式成对出现的。并且,从其中一个“网卡”发出的数据包,可以直接出现在与它对应的另一张“网卡”上,哪怕这两个“网卡”在不同的 Network Namespace 里。
- Veth Pair 常常被用作连接不同 Network Namespace 的“网线”。
不同容器间的通信
-
不同容器之间如何通信?
-
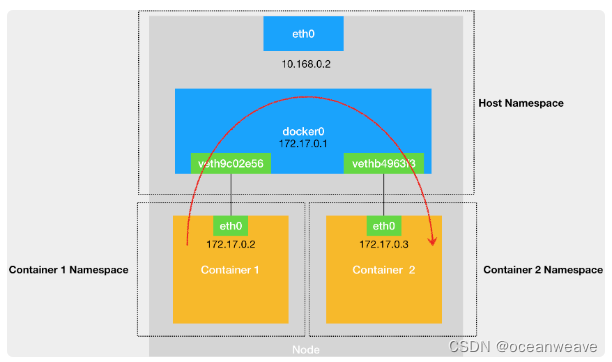
docker 为 container-1 创建的 veth pair,一端插在容器 net namespace 内,名称为 eth0;另一端插在宿主机 net namespace 内的 docker0 网桥上,名称为 vethXXXXXX —— 分为在容器内和宿主机内执行
ifconfig命令可查看到这些设备 -
container-1 想要发送数据给 container-2,该怎么走?
-
首先 container-1 会查自己容器 net namespace 内的本地路由表 —— 通过
route命令可查看 -
container-1 根据路由表的匹配规则,知道要通过 eth0 设备,发送到网关 0.0.0.0
-
$ route Kernel IP routing table Destination Gateway Genmask Flags Metric Ref Use Ifacedefault 172.17.0.1 0.0.0.0 UG 0 0 0 eth0 172.17.0.0 0.0.0.0 255.255.0.0 U 0 0 0 eth0 -
【网关0.0.0.0】意味着这是一条直连规则
- 即:凡是匹配到这条规则的 IP 包,应该经过本机的 eth0 网卡,通过二层网络直接发往目的主机。
-
-
而目前 container-1 只知道目的 container-2 的 ip 地址,但不知道其对应的 mac 地址
- 因此便通过自身的 eth0 设备发送一个 ARP 查询包(查询 container-2 ip 对应的 mac 地址)
-
发出的 ARP 包,通过 veth 设备,传输到了 docker0 网桥上,docker0 会将其广播到所有插到自身网桥上的 veth 设备,此时 container-2 发现查询是自身,因此相应了自身的 mac 地址
- 一旦一张虚拟网卡被“插”在网桥上,它就会变成该网桥的“从设备”。从设备会被“剥夺”调用网络协议栈处理数据包的资格,从而“降级”成为网桥上的一个端口。而这个端口唯一的作用,就是接收流入的数据包,然后把这些数据包的“生杀大权”(比如转发或者丢弃),全部交给对应的网桥。
- 在收到这些 ARP 请求之后,docker0 网桥就会扮演二层交换机的角色,把 ARP 广播转发到其他被“插”在 docker0 上的虚拟网卡(vethxxx)上。
-
有了目标 container-2 的 mac 地址后,container-1 便可以正常封包将数据发给 container-2 了
-
docker0 处理转发的过程,则继续扮演二层交换机的角色。此时,docker0 网桥根据数据包的目的 MAC 地址,在它的 CAM 表(即交换机通过 MAC 地址学习维护的端口和 MAC 地址的对应表)里查到对应的端口(Port)为:vethb4963f3,然后把数据包发往这个端口。
-
需要注意的是,在实际的数据传递时,上述数据的传递过程在网络协议栈的不同层次,都有 Linux 内核 Netfilter 参与其中。所以,如果感兴趣的话,你可以通过打开 iptables 的 TRACE 功能查看到数据包的传输过程,具体方法如下所示:
-
# 在宿主机上执行 $ iptables -t raw -A OUTPUT -p icmp -j TRACE $ iptables -t raw -A PREROUTING -p icmp -j TRACE
-
-
-
-
-
不同主机的容器如何通信?
- 答 —— overlay 网络
- 简单来说,就是在现在【源container ip,目的container ip】上,通过 SNAT、DNAT、路由表等,进行封装,使其能在真正的物理网络上通行
- 简单理解为,ip 头为【源container ip,目的container ip】的容器包视为数据段,进行再次 ip 头封装等,实现可以到达对面的宿主机
- 此部分简单了解就行,不看也行,后面也有详解
- 在 Docker 的默认配置下,不同宿主机上的容器通过 IP 地址进行互相访问是根本做不到的。
- 在 Docker 的默认配置下,不同宿主机上的容器通过 IP 地址进行互相访问是根本做不到的。(flannel、calico 等)
常用网络命令
- 常用命令总结
# 可以看到当前 net namespace 下的所有网络设备,veth pair 、bridge、宿主机网卡 eth0 等
$ ifconfig
# 推荐使用ip link show来看veth-eth映射关系
# 查看 bridge 上插入的 veth pair 设备
$ brctl show
# 查看路由表
$ route
# 在宿主机上
$ docker exec -it nginx-1 /bin/bash
# 在容器里
root@2b3c181aecf1:/# ifconfig
eth0: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500
inet 172.17.0.2 netmask 255.255.0.0 broadcast 0.0.0.0
inet6 fe80::42:acff:fe11:2 prefixlen 64 scopeid 0x20<link>
ether 02:42:ac:11:00:02 txqueuelen 0 (Ethernet)
RX packets 364 bytes 8137175 (7.7 MiB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 281 bytes 21161 (20.6 KiB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
lo: flags=73<UP,LOOPBACK,RUNNING> mtu 65536
inet 127.0.0.1 netmask 255.0.0.0
inet6 ::1 prefixlen 128 scopeid 0x10<host>
loop txqueuelen 1000 (Local Loopback)
RX packets 0 bytes 0 (0.0 B)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 0 bytes 0 (0.0 B)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
$ route
Kernel IP routing table
Destination Gateway Genmask Flags Metric Ref Use Iface
default 172.17.0.1 0.0.0.0 UG 0 0 0 eth0
172.17.0.0 0.0.0.0 255.255.0.0 U 0 0 0 eth0
- 找 docker 和 宿主机上 veth 设备的关系
#看到有位同学问怎么找 docker 和 宿主机上 veth 设备的关系,学完后我也有这个疑问,查了一下,
# 结论是没有命令可以直接查到。但是可以查看 container 里的 eth0 网卡的 iflink 找到对应关系。
# 方法1
# 宿主机上
$ ip link
......
9: veth0e9cd8d@if8: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue master docker0 state UP mode DEFAULT group default
link/ether 6a:fb:59:e5:7e:da brd ff:ff:ff:ff:ff:ff link-netnsid 1
# 容器内
$ sudo docker exec -it e151 bash
root@e1517e9d9e1a:/# cat /sys/class/net/eth0/iflink
9
# 这样就可以确定 container e1517e9d9e1a 在物理机上对应的 veth pair 是 veth0e9cd8d 了。
# 这种方式需要登录到 docker 里执行命令,不是所有的容器都能这么做,不过 github 上有人专门做了个脚本来用实现这个功能,可以参考一下:
# https://github.com/micahculpepper/dockerveth
# 方法2
容器内执行 ethtool -S eth0 | grep peer_ifindex, 可以看到对端序列号,
然后宿主机上 ip link | grep 那个序列号也可以找到
总结
| 设备 | 非专业术语 | 作用 |
|---|---|---|
| Docker0 | 网桥 | 理解为二层交换机,处理包头为 mac 的数据包 |
| net namespace | 网络栈 | 存储用于通信的网络设备和规则等(网卡、路由表、iptables规则等) |
| 一个 net namespace 可以简单理解为,一个主机 | ||
| –net=host,表示容器共享宿主机的网络栈(此时可理解为两个人共用一套设备),此时可提高通信效率,但可能会端口冲突 | ||
| docker run –d –net=host --name nginx-host nginx | ||
| veth pair | 网线 | 用于联通不同的 net namespace,可以理解为连接两个主机间的网线 |
| veth-pair 会生成两个 veth 设备,其可以理解为两个虚拟网卡 | ||
| 其中一个,一般放在宿主机 net namespace 内,插在 docker0 网桥上,名称为 vethXXXX | ||
| 另一个,一般放在容器 net namespace 内,也就是插在容器内,名称为 eth0(一般表示这是容器的主网卡) | ||
| 本机通信路径 | container-1 发包给 container-2:首先 container-1 不知道 container-2,通过路由表查询, 需要通过 eth0 网卡(也就是veth pair 设备的一端)发包,之后container-1 发送 ARP 数据包 (用于查询container-2 mac 地址),通过 veth 转发到 docker0 网桥上,网桥会广播给所有插在自身的 veth 网卡, 匹配的 container-2 会进行相应,返回 mac地址;之后 container-1 封装二层数据包(包头为 mac 地址),然后通过 veth 发送到 docker0 上,docker0 网桥将其转发到 container-2 |
flannel
udp 模式
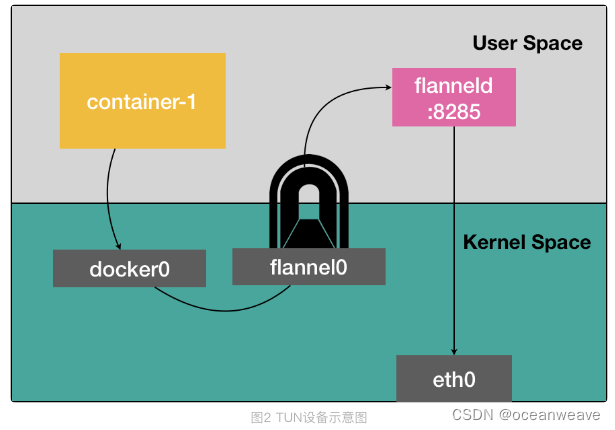
| Flannel0 | Tunnel设备 (网络设备) | 在 Linux 中,TUN 设备是一种工作在三层(Network Layer)的虚拟网络设备。TUN 设备的功能非常简单,即:在操作系统内核和用户应用程序之间传递 IP 包 |
| 以 flannel0 设备为例:像上面提到的情况,当操作系统将一个 IP 包发送给 flannel0 设备之后,flannel0 就会把这个 IP 包,交给创建这个设备的应用程序,也就是 Flannel 进程。这是一个从内核态(Linux 操作系统)向用户态(Flannel 进程)的流动方向。 | ||
| 以 flannel0 设备为例:像上面提到的情况,当操作系统将一个 IP 包发送给 flannel0 设备之后,flannel0 就会把这个 IP 包,交给创建这个设备的应用程序,也就是 Flannel 进程。这是一个从内核态(Linux 操作系统)向用户态(Flannel 进程)的流动方向。 | ||
| flanneld | 守护程序(用户态程序,是个进程) | 维护容器 IP 子网范围和 Node 的对应关系,保存在 etcd 中 |
| 事实上,在由 Flannel 管理的容器网络里,一台宿主机上的所有容器,都属于该宿主机被分配的一个“子网”。在我们的例子中,Node 1 的子网是 100.96.1.0/24,container-1 的 IP 地址是 100.96.1.2。Node 2 的子网是 100.96.2.0/24,container-2 的 IP 地址是 100.96.2.3。 | ||
| flanneld 进程在处理由 flannel0 传入的 IP 包时,就可以根据目的 IP 的地址(比如 100.96.2.3),匹配到对应的子网(比如 100.96.2.0/24),从 Etcd 中找到这个子网对应的宿主机的 IP 地址是 10.168.0.3 | ||
| 每台宿主机上的 flanneld,都监听着一个 8285 端口,所以 Node1 flanneld 只要把 UDP 包发往 Node 2 的 8285 端口即可 (涉及到端口通信,当然需要用到传输层协议,此处用的就是 UDP) | ||
| docker0 | 网桥 | docker0 网桥的地址范围必须是 Flannel 为宿主机分配的子网。这个很容易实现,以 Node 1 为例,你只需要给它上面的 Docker Daemon 启动时配置如下所示的 bip 参数即可: |
| $ FLANNEL_SUBNET=100.96.1.1/24 $ dockerd --bip=$FLANNEL_SUBNET … | ||
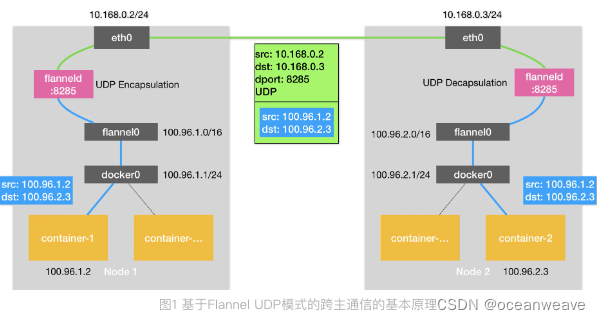
| 通信过程 | Container-1 向 container-2 发包【源container-1 ip,目的container-2 ip】 | |
| 1. 首先 container-1 通过 veth-pair,将数据包从 container(容器) net namespace 传输到 host(宿主机) net namespace 中,也就是数据包到达了 docker0 网桥上【这是一个从用户态(容器内应用程序)向内核态(Linux操作系统的流动方向】 | ||
| 2. 接下来根据 host net namespace 中的路由表,发现 container-2 ip 不在当前 node 的 docker0 网桥上,因此匹配了另一条路由规则,发送给 flannel0 设备 | ||
| 3. fannel0 设备就会把这个 IP 包,交给创建这个设备的应用程序,也就是 flanneld 进程。【这是一个从内核态(Linux 操作系统)向用户态(flanneld 进程)的流动方向。 | ||
| 4. flanneld 通过查询 etcd 知道,该 container-2 ip 属于 Node2 的管辖范围,因此发送到 Node2 的 flanneld 程序(也就是8285端口),才能顺利的完成解包,所以又进行 UDP 封包(可指定端口),并通过宿主机 eth0 端口发出【这是一个从用户态(flanneld 进程)向内核态(Linux 操作系统)的流动方向。】 | ||
| 5. 最后变为如下形式【mac包头(源node1,目的node2】【ip头(源node1,目的node2)】【udp头(源端口8285,目的端口8285】【udp数据帧(也就是容器包【源container-1 ip,目的container-2 ip】【要发送的数据】) | ||
| TUN 设备工作原理 | 也是 udp 模式废弃原因 | UDP 模式有严重的性能问题,所以已经被废弃了。通过我上面的讲述,你有没有发现性能问题出现在了哪里呢? |
| 实际上,相比于两台宿主机之间的直接通信,基于 Flannel UDP 模式的容器通信多了一个额外的步骤,即 flanneld 的处理过程。而这个过程,由于使用到了 flannel0 这个 TUN 设备,仅在发出 IP 包的过程中,就需要经过三次用户态与内核态之间的数据拷贝 | ||
| 第一次,用户态的容器进程发出的 IP 包经过 docker0 网桥进入内核态; 第二次,IP 包根据路由表进入 TUN(flannel0)设备,从而回到用户态的 flanneld 进程; 第三次,flanneld 进行 UDP 封包之后重新进入内核态,将 UDP 包通过宿主机的 eth0 发出去。 | ||
| 可以看到,Flannel 进行 UDP 封装(Encapsulation)和解封装(Decapsulation)的过程,也都是在用户态完成的。在 Linux 操作系统中,上述这些上下文切换和用户态操作的代价其实是比较高的,这也正是造成 Flannel UDP 模式性能不好的主要原因。 | ||
| 在进行系统级编程的时候,有一个非常重要的优化原则,就是要减少用户态到内核态的切换次数,并且把核心的处理逻辑都放在内核态进行。这也是为什么,Flannel 后来支持的VXLAN 模式,逐渐成为了主流的容器网络方案的原因。 |
- flannel UDP 模式通信
- Flannel UDP 模式提供的其实是一个三层的 Overlay 网络,即:它首先对发出端的 IP 包进行 UDP 封装,然后在接收端进行解封装拿到原始的 IP 包,进而把这个 IP 包转发给目标容器。这就好比,Flannel 在不同宿主机上的两个容器之间打通了一条“隧道”,使得这两个容器可以直接使用 IP 地址进行通信,而无需关心容器和宿主机的分布情况。
- TUN 设备工作原理
- 相比于两台宿主机之间的直接通信,基于 Flannel UDP 模式的容器通信多了一个额外的步骤,即 flanneld 的处理过程。而这个过程,由于使用到了 flannel0 这个 TUN 设备,仅在发出 IP 包的过程中,就需要经过三次用户态与内核态之间的数据拷贝
- 我们在进行系统级编程的时候,有一个非常重要的优化原则,就是要减少用户态到内核态的切换次数,并且把核心的处理逻辑都放在内核态进行。这也是为什么,Flannel 后来支持的VXLAN 模式,逐渐成为了主流的容器网络方案的原因。
vxlan 模式
| 首先简单了解 | ||
| 隧道通信 | 就是交给隧道通信设备,自动完成了数据包的跨Node传输,类似覆盖一层“网桥”似的,连接两个Node 所以这个“覆盖的虚拟网桥”,也就是在虚拟的容器网络上覆盖一层网络,称之为 Overlay 网络 | |
| 我们知道,容器的 IP 是“虚拟IP”,也就是只限本机上使用(同一 Node 上内的容器通信) 出了所在 Node 到真实物理网络中,所有Node 都不认识,也就是不能到其他网络 | ||
| 而在不同 Node 上“覆盖的虚拟网桥”,可将容器 IP 包,传输到不同 Node 上,实现了跨节点通信 | ||
| flannel UDP 模式 | 三层 Overlay | 传输的是 IP 包,也就是传给隧道设备的是 IP 包,关注 IP地址 |
| flannel VXLAN 模式 | 二层 Overlay | 传输的是 MAC 包,也就是传给隧道设备的是 MAC 包,关注 MAC 地址 |
| Fannel VXLAN 模式 | 引入原因 | Flannel 进行 UDP 封装(Encapsulation)和解封装(Decapsulation)的过程,也都是在用户态完成的。 在 Linux 操作系统中,上述这些上下文切换和用户态操作的代价其实是比较高的,这也正是造成 Flannel UDP 模式性能不好的主要原因 |
| VXLAN 可以完全在内核态实现上述封装和解封装的工作,从而通过与前面相似的“隧道”机制,构建出覆盖网络(Overlay Network)。 | ||
| VXLAN | VXLAN 的覆盖网络的设计思想是:在现有的三层网络之上,“覆盖”一层虚拟的、由内核 VXLAN 模块负责维护的二层网络, 使得连接在这个 VXLAN 二层网络上的“主机”(虚拟机或者容器都可以)之间,可以像在同一个局域网(LAN)里那样自由通信。当然,实际上,这些“主机”可能分布在不同的宿主机上,甚至是分布在不同的物理机房里。 | |
| 为了能够在二层网络上打通“隧道”,VXLAN 会在宿主机上设置一个特殊的网络设备作为“隧道”的两端。这个设备就叫作 VTEP,即:VXLAN Tunnel End Point(虚拟隧道端点)。 | ||
| VTEP 设备的作用,其实跟前面的 flanneld 进程非常相似。只不过,它进行封装和解封装的对象,是二层数据帧(Ethernet frame);而且这个工作的执行流程,全部是在内核里完成的(因为 VXLAN 本身就是 Linux 内核中的一个模块)。 | ||
| 宿主机上的 VTEP 设备都叫作 flannel.1 | ||
| 通信过程 | Container-1 向 container-2 发包【源container-1 ip,目的container-2 ip】 | |
| 1. 首先容器 IP 包,会通过 veth 到达 host net namespace,之后根据路由表,交由给 flannel.1 VTEP 设备处理 【源container-1 ip,目的container-2 ip】 | ||
| 2. 之后 flannel.1 设备会根据容器的目的 ip,为其添加上目的 VTEP 设备的 MAC 地址(该信息由 fanneld 进程维护,是个 ARP 表) 每新增一个 Node VTEP 设备,Flannel 网络会将该 Node VTEP 对应的 ARP 记录下放到所有其他 Node 上 【目标 VTEP Mac地址,源 MAC 地址(是变动的)】【源container-1 ip,目的container-2 ip】 | ||
| 3. 再上面基础上,加上一个特殊的 VXLAN 头,用来表示这个“乘客”实际上是一个 VXLAN 要使用的数据帧。 而这个 VXLAN 头里有一个重要的标志叫作 VNI,它是 VTEP 设备识别某个数据帧是不是应该归自己处理的重要标识。而在 Flannel 中,VNI 的默认值是 1,这也是为何,宿主机上的 VTEP 设备都叫作 flannel.1 的原因,这里的“1”,其实就是 VNI 的值。 | ||
| 4. Linux 内核会把这个数据帧封装进一个 UDP 包里发出去。 那如何知道,对面 Node IP 地址呢? | ||
| 答:FDB(Forwarding Database)的转发数据库,该数据库维护【 目标 VTEP 设备 MAC 地址 — 所在 Node IP】的对应关系。 不难想到,这个 flannel.1“网桥”对应的 FDB 信息,也是 flanneld 进程负责维护的。它的内容可以通过 bridge fdb 命令查看到 | ||
| 5. 对面 Node 收到包后,根据 VXLAN 头和 VNI 号,知道要转给自己的 flannel.1 设备,从解包后发到目标容器 |
-
flannel vxlan 通信模式

-
封帧

calico-ipip
在了解了 BGP 之后,Calico 项目的架构就非常容易理解了。它由三个部分组成:
- Calico 的 CNI 插件。这是 Calico 与 Kubernetes 对接的部分。
- Felix。它是一个 DaemonSet,负责在宿主机上插入路由规则(即:写入 Linux 内核的 FIB 转发信息库),以及维护 Calico 所需的网络设备等工作。
- BIRD。它就是 BGP 的客户端,专门负责在集群里分发路由规则信息。
-
除了对路由信息的维护方式之外,Calico 项目与 Flannel 的 host-gw 模式的另一个不同之处,就是它不会在宿主机上创建任何网桥设备。
-
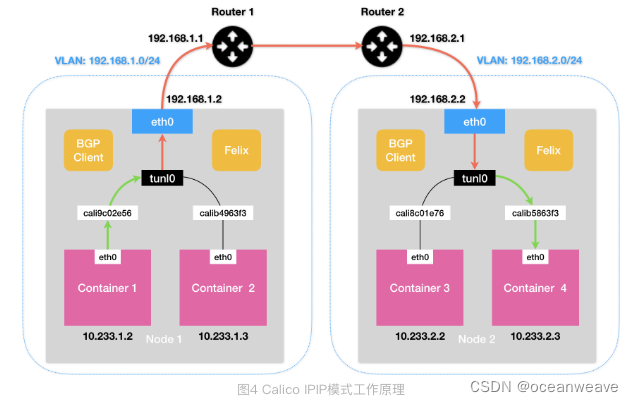
可以看出与 flannel vxlan 的差异
- 没有网桥
- 隧道设备不一致
- flannel 隧道是 TUN 设备类型,是个(Mac 层 tunnel)设备
- calico 隧道是 tunl0 设备类型,是一个 IP 隧道(IP 层 tunnel)设备
- 这两个设备类型很相似,但是不同功能
- 从封包差异可以看出来
- flannel 需要封装 VTEP 设备 MAC 地址
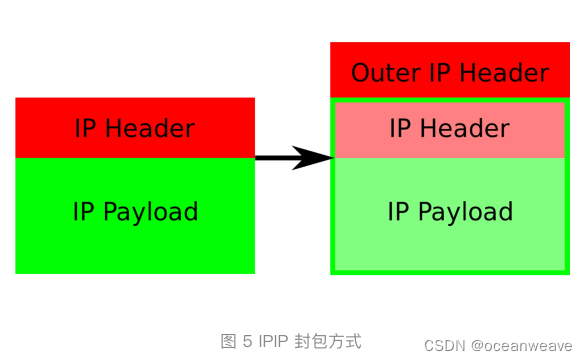
- calico 直接在容器 ip 外层,封装一层 Node ip 层,容器数据作为 Node ip 包的 Payload(负载),容器 ip 与 node ip 的映射关系由本地的 Felix 组件负责,不需要 UDP 封包
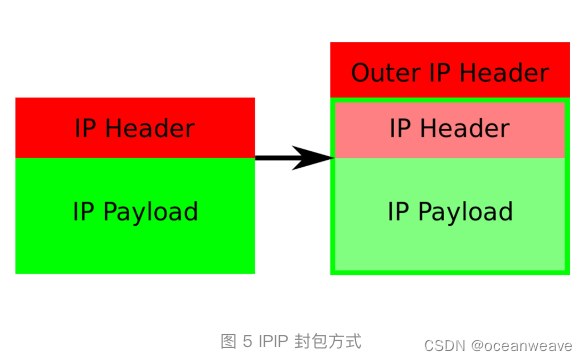
- IP 包进入 IP 隧道设备之后,就会被 Linux 内核的 IPIP 驱动接管。IPIP 驱动会将这个 IP 包直接封装在一个宿主机网络的 IP 包中
- 查本地路由表,可知 目的容器 ip 对应的目的 Node ip
- 【目的 Node ip、源 tunl0 设备 ip】(【目的容器ip、源容器 ip】【数据】 此部分可视为 Payload)
- 目的 Node 网络内核栈会使用 IPIP 驱动进行解包,从而拿到原始的 IP 包。然后,原始 IP 包就会经过路由规则和 Veth Pair 设备到达目的容器内部。
- 在实际测试中,Calico IPIP 模式与 Flannel VXLAN 模式的性能大致相当。
- 封包
host-gw
- 必须二层连通
- Pod 通信时相当于,把对方的宿主机当做网关
- 本机上会有路由规则: 【对方 Pod IP 段】 —— 【对方主机 MAC 地址】
- 这样本机 Pod 要发送给对方 Pod,就会直接发给对方主机,对方主机上当然会有自己所有 Pod 的路由信息,这样完成了通信
- 同样,对方需要发回数据时,也是直接将数据发到本宿主机上,然后转发给对应的 Pod
- 封装的数据包为 【对方主机mac地址】【Pod IP 地址】【端口】 【数据信息】
- 因此这样要求必须二层连通,直接可以到达对方宿主机
- 若是三层,中间的路由器不认识【Pod IP 地址】,也无法解析到【下一跳】,因此【不知道该发到哪】,所以只能二层连通
- 不过 Calico BGP 解决了此问题,支持 BGP 的路由器中也会存储着 【Pod IP】—— 【宿主机MAC地址】的映射信息
- 因此知道该如何转发
- 这个信息的分发和维护,是BGP的内在机制 (好像是 Brid 组件)
flannel
- flannel
calico
- calico
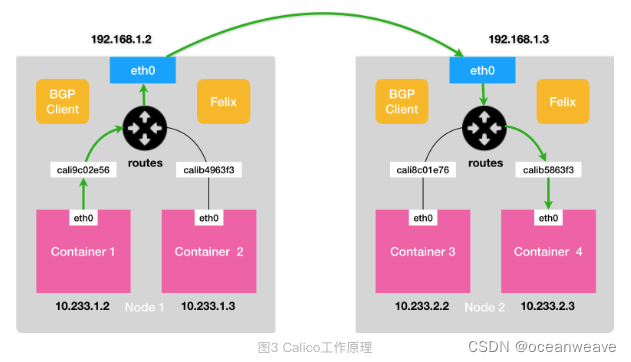
- Calico 项目的架构就非常容易理解了。它由三个部分组成
- Calico 的 CNI 插件。这是 Calico 与 Kubernetes 对接的部分。
- Felix。它是一个 DaemonSet,负责在宿主机上插入路由规则(即:写入 Linux 内核的 FIB 转发信息库),以及维护 Calico 所需的网络设备等工作。
- 这里最核心的“下一跳”路由规则,就是由 Calico 的 Felix 进程负责维护的
- BIRD。它就是 BGP 的客户端,专门负责在集群里分发路由规则信息。
- 两种模式 Node-to-Node Mesh 和 BGP Route Reflector
- Calico 维护的网络在默认配置下,是一个被称为“Node-to-Node Mesh”的模式。
- Node-to-Node Mesh 每台宿主机上的 BGP Client 都需要跟其他所有节点的 BGP Client 进行通信以便交换路由信息。但是,随着节点数量 N 的增加,这些连接的数量就会以 N²的规模快速增长,从而给集群本身的网络带来巨大的压力。就是每个 Node 都要连接其他 N-1 个 Node
- Node-to-Node Mesh 模式一般推荐用在少于 100 个节点的集群里。而在更大规模的集群中,你需要用到的是一个叫作 Route Reflector 的模式。
- 在这种模式下,Calico 会指定一个或者几个专门的节点,来负责跟所有节点建立 BGP 连接从而学习到全局的路由规则。而其他节点,只需要跟这几个专门的节点交换路由信息,就可以获得整个集群的路由规则信息了。
- felix 和 bird 在部署时候,其实统一部署在一个组件内,叫做 calico-node
- 除了对路由信息的维护方式之外,Calico 项目与 Flannel 的 host-gw 模式的另一个不同之处,就是它不会在宿主机上创建任何网桥设备。
- Calico 项目的架构就非常容易理解了。它由三个部分组成
cni 插件
-
在 k8s 中
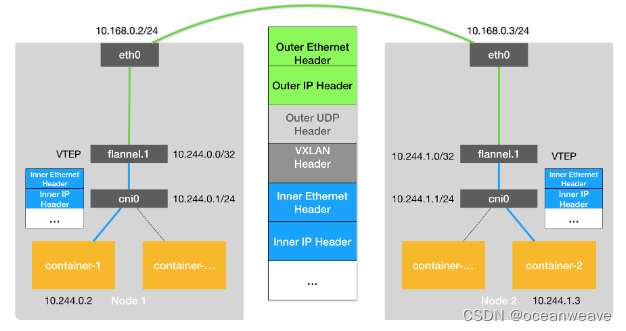
- Kubernetes 是通过一个叫作 CNI 的接口,维护了一个单独的网桥来代替 docker0。这个网桥的名字就叫作:CNI 网桥,它在宿主机上的设备名称默认是:cni0。
- 以 Flannel 的 VXLAN 模式为例,在 Kubernetes 环境里,它的工作方式跟我们在上一篇文章中讲解的没有任何不同。只不过,docker0 网桥被替换成了 CNI 网桥而已
-
分类
| 设备创建类 | Main | 第一类,叫作 Main 插件,它是用来创建具体网络设备的二进制文件。比如,bridge(网桥设备)、ipvlan、loopback(lo 设备)、macvlan、ptp(Veth Pair 设备),以及 vlan。 |
| ip 分配类 | IPAM | 第二类,叫作 IPAM(IP Address Management)插件,它是负责分配 IP 地址的二进制文件。 比如,dhcp,这个文件会向 DHCP 服务器发起请求;host-local,则会使用预先配置的 IP 地址段来进行分配。 |
| 网络管控类 | 第三类,是由 CNI 社区维护的内置 CNI 插件。比如:flannel,就是专门为 Flannel 项目提供的 CNI 插件; tuning,是一个通过 sysctl 调整网络设备参数的二进制文件; portmap,是一个通过 iptables 配置端口映射的二进制文件; bandwidth,是一个使用 Token Bucket Filter (TBF) 来进行限流的二进制文件。 | |
| 从这些二进制文件中,我们可以看到,如果要实现一个给 Kubernetes 用的容器网络方案,其实需要做两部分工作,以 Flannel 项目为例: | ||
| 基础网络构建 | 首先,实现这个网络方案本身。这一部分需要编写的,其实就是 flanneld 进程里的主要逻辑。比如,创建和配置 flannel.1 设备、配置宿主机路由、配置 ARP 和 FDB 表里的信息等等。 | |
| 容器网络构建 | 然后,实现该网络方案对应的 CNI 插件。这一部分主要需要做的,就是配置 Infra 容器里面的网络栈,并把它连接在 CNI 网桥上。 | |
| cni插件放置 | 由于 Flannel 项目对应的 CNI 插件已经被内置了,所以它无需再单独安装。 而对于 Weave、Calico 等其他项目来说,我们就必须在安装插件的时候,把对应的 CNI 插件的可执行文件放在 /opt/cni/bin/ 目录下。 | |
| cni插件配置文件 | flanneld 启动后会在每台宿主机上生成它对应的 CNI 配置文件(它其实是一个 ConfigMap),从而告诉 Kubernetes,这个集群要使用 Flannel 作为容器网络方案。路径 /etc/cni/net.d/ | |
| cni配置文件加载 | 需要注意的是,在 Kubernetes 中,处理容器网络相关的逻辑并不会在 kubelet 主干代码里执行, 而是会在具体的 CRI(Container Runtime Interface,容器运行时接口)实现里完成。对于 Docker 项目来说,它的 CRI 实现叫作 dockershim,你可以在 kubelet 的代码里找到它。 | |
| 所以,接下来 dockershim 会加载上述的 CNI 配置文件。 | ||
| 多个配置文件 | 需要注意,Kubernetes 目前不支持多个 CNI 插件混用。如果你在 CNI 配置目录(/etc/cni/net.d)里放置了多个 CNI 配置文件的话,dockershim 只会加载按字母顺序排序的第一个 cni 配置文件。 | |
| 多个配置插件 | 另一方面,CNI 允许你在一个 CNI 配置文件里,通过 plugins 字段,定义多个插件进行协作 | |
| 比如,在我们上面这个例子里,Flannel 项目就指定了 flannel 和 portmap 这两个插件。 这时候,dockershim 会把这个 CNI 配置文件加载起来,并且把列表里的第一个插件、也就是 flannel 插件,设置为默认插件。而在后面的执行过程中,flannel 和 portmap 插件会按照定义顺序被调用,从而依次完成“配置容器网络”和“配置端口映射”这两步操作。 | ||
| CNI 插件的工作原理 | 当 kubelet 组件需要创建 Pod 的时候,它第一个创建的一定是 Infra 容器。 所以在这一步,dockershim 就会先调用 Docker API 创建并启动 Infra 容器,紧接着执行一个叫作 SetUpPod 的方法。 这个方法的作用就是:为 CNI 插件准备参数,然后调用 CNI 插件为 Infra 容器配置网络。 | |
| 这里要调用的 CNI 插件,就是 /opt/cni/bin/flannel;而调用它所需要的参数,分为两部分。 | ||
| 指定动作(创建or删除) | 第一部分,是由 dockershim 设置的一组 CNI 环境变量。其中,最重要的环境变量参数叫作:CNI_COMMAND。 它的取值只有两种:ADD 和 DEL。这个 ADD 和 DEL 操作,就是 CNI 插件唯一需要实现的两个方法。 其中 ADD 操作的含义是:把容器添加到 CNI 网络里; DEL 操作的含义则是:把容器从 CNI 网络里移除掉。 而对于网桥类型的 CNI 插件来说,这两个操作意味着把容器以 Veth Pair 的方式“插”到 CNI 网桥上,或者从网桥上“拔”掉。 | |
| 接下来,我以 ADD 操作为重点进行讲解。CNI 的 ADD 操作需要的参数包括:容器里网卡的名字 eth0(CNI_IFNAME)、Pod 的 Network Namespace 文件的路径(CNI_NETNS)、容器的 ID(CNI_CONTAINERID)等。这些参数都属于上述环境变量里的内容。其中,Pod(Infra 容器)的 Network Namespace 文件的路径,我在前面讲解容器基础的时候提到过,即:/proc/< 容器进程的 PID>/ns/net。 | ||
| 除此之外,在 CNI 环境变量里,还有一个叫作 CNI_ARGS 的参数。通过这个参数,CRI 实现(比如 dockershim)就可以以 Key-Value 的格式,传递自定义信息给网络插件。这是用户将来自定义 CNI 协议的一个重要方法。 | ||
| 补充配置文件(执行哪些cni插件) | 第二部分,则是 dockershim 从 CNI 配置文件里加载到的、默认插件的配置信息。 | |
| 这个配置信息在 CNI 中被叫作 Network Configuration,它的完整定义你可以参考这个文档。dockershim 会把 Network Configuration 以 JSON 数据的格式,通过标准输入(stdin)的方式传递给 Flannel CNI 插件。 | ||
| dockershim 对 Flannel CNI 插件的调用,其实就是走了个过场。Flannel CNI 插件唯一需要做的,就是对 dockershim 传来的 Network Configuration 进行补充。比如,将 Delegate 的 Type 字段设置为 bridge,将 Delegate 的 IPAM 字段设置为 host-local 等。 | ||
| Delegate 字段的意思是,这个 CNI 插件并不会自己做事儿,而是会调用 Delegate 指定的某种 CNI 内置插件来完成。 |
- cni 配置文件
$ cat /etc/cni/net.d/10-flannel.conflist
{
"name": "cbr0",
"plugins": [
{
"type": "flannel",
"delegate": {
"hairpinMode": true,
"isDefaultGateway": true
}
},
{
"type": "portmap",
"capabilities": {
"portMappings": true
}
}
]
}
k8s service
-
Service 是由 kube-proxy 组件,加上 iptables 来共同实现的。
-
Kube-proxy 通过监听 Service 对象的创建,创建出相应的 iptables 规则
- 如创建一个 3副本的 deployment,并暴露该 deployment 为一个 k8s Service
- kube-proxy 监听到该 Service 的创建,首先会创建一个 iptables,过滤 IP 包(目的 ip 是该 Service IP,目的端口是该 Service 端口),然后跳转到另一个 iptables 链 A
- 该 iptables 链有一组 iptables 规则(共三条,对应3个副本),进行随机跳转(各1/3概率选中),选中一条规则,跳转到另一条 iptables链(B 或 C 或 D)
- 假如上面选中了 iptables 链 B,该链对应了 Pod-1,包含一组操作,进行 DNAT,将上面的 Service IP + Port 替换为 Pod-1 IP + Pod-1 Port,实现真正的流量导向
-
在 Kubernetes 中,Service 和 Pod 都会被分配对应的 DNS A 记录(从域名解析 IP 的记录)。
- 对于 ClusterIP 模式的 Service 来说(比如我们上面的例子),它的 A 记录的格式是:…svc.cluster.local。当你访问这条 A 记录的时候,它解析到的就是该 Service 的 VIP 地址。
- 而对于指定了 clusterIP=None 的 Headless Service 来说,它的 A 记录的格式也是:…svc.cluster.local。但是,当你访问这条 A 记录的时候,它返回的是所有被代理的 Pod 的 IP 地址的集合。当然,如果你的客户端没办法解析这个集合的话,它可能会只会拿到第一个 Pod 的 IP 地址。
- 此外,对于 ClusterIP 模式的 Service 来说,它代理的 Pod 被自动分配的 A 记录的格式是:…pod.cluster.local。这条记录指向 Pod 的 IP 地址。
- 而对 Headless Service 来说,它代理的 Pod 被自动分配的 A 记录的格式是:…svc.cluster.local。这条记录也指向 Pod 的 IP 地址。
- 但如果你为 Pod 指定了 Headless Service,并且 Pod 本身声明了 hostname 和 subdomain 字段,那么这时候 Pod 的 A 记录就会变成:pod 的 hostname…svc.cluster.local