文章目录
- 0.远程拷贝
- 1.重入函数与volatile关键字
- 2.认识SIGCHILD信号
- 3.普通信号/实时信号
0.远程拷贝
- 打包资源:
tar czf code.tgz * - 远程传输:
scp code.tgz usr@服务器ip:/home/usr/路径 - 解压:
tar xzf code.tgz
1.重入函数与volatile关键字
先看一个现象
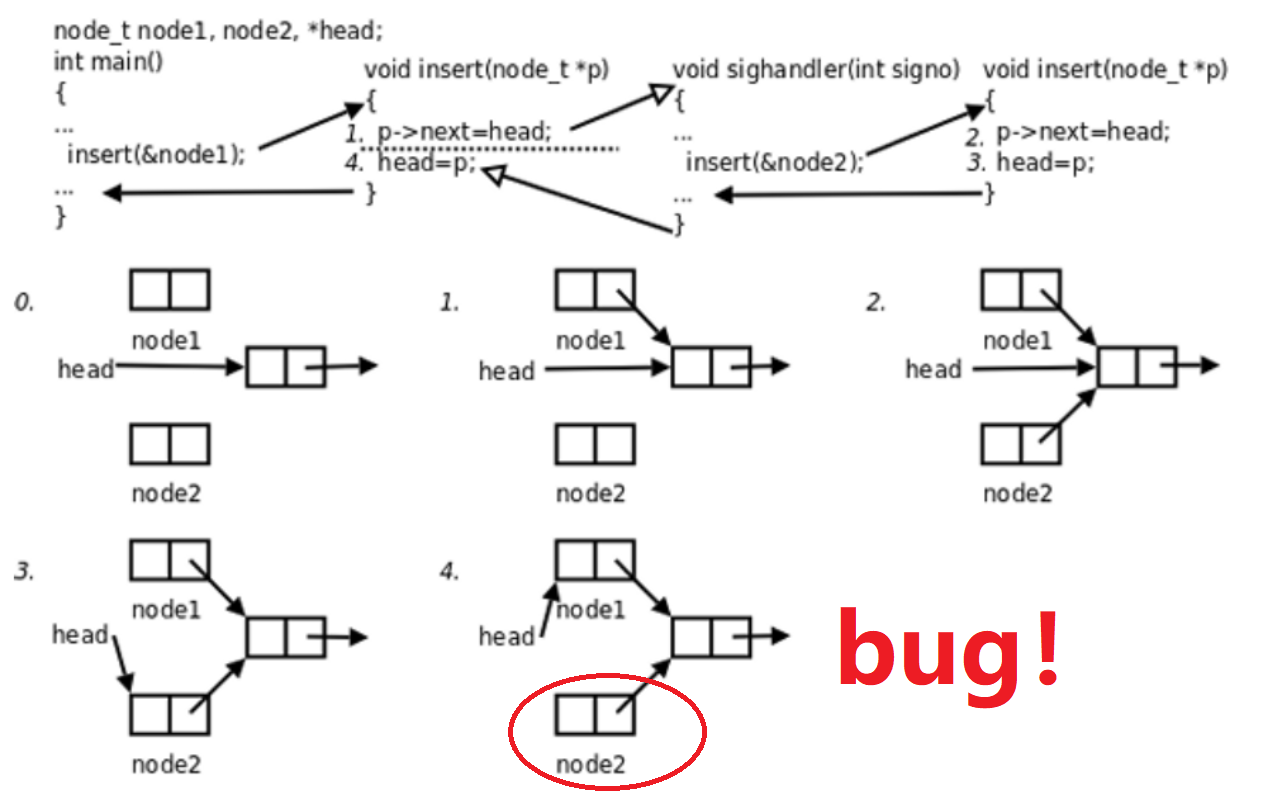
main函数调用insert函数向一个链表中插入节点node1,插入操作分为两步,刚做完第一步时,因为某种原因(如硬件中断)使进程切换到内核态,从内核态返回用户态之前检查到有信号待处理,于是切换到用户态执行sighandler函数,sighandler也调用insert函数向同一个链表head中插入节点node2,插入操作的两步都做完之后从用户态返回内核态,此时信号处理完毕,从内核态返回用户态就从main函数调用的insert函数中继续往下执行,先前做第一步之后被打断,现在继续做完第二步。⇒ main函数和sighandler先后 向链表中插入两个节点,而最后只有一个节点真正插入链表中了。而node2的地址无法得知 ⇒ 内存泄漏
insert函数被不同的执行流调用,有可能在第一次调用还没返回时就再次进入该函数 ⇒ 函数的重入。insert函数访问一个全局链表,有可能因为重入而造成错乱,像这样的函数称为不可重入函数。反之,如果一个函数在被重入执行的过程中不会出现任何错误,则别称为可重入函数。
什么样的函数为不可重入函数
不可重入函数是指在函数执行过程中会使用全局变量或静态变量的函数。这些函数没有保护它们的共享资源,因此在多个线程或中断同时调用时,可能会产生不可预测的结果。它们不能运行在多任务环境下,除非能保证互斥。
具体来说,满足以下任一条件的函数多数为不可重入函数:
函数体内使用了静态的数据结构。
函数体内调用了malloc()或free()函数。
函数体内调用了标准I/O函数,因为标准I/O库很多实现都以不可重入的方式使用全局数据结构。
函数体内访问了全局变量。
函数进行了浮点运算,在许多的处理器/编译器中,浮点一般都是不可重入的。
另外,一些常见的函数如printf(),由于内部包含了semTake操作,而在中断服务程序中不能有阻塞操作,因此也被视为不可重入函数。
请注意,不可重入函数在实时系统设计中被视为不安全函数,因为它们在多线程或中断环境下的行为可能会导致数据错误或不可预料的后果。因此,在编写多线程或中断驱动的代码时,应尽量避免使用不可重入函数,或采取适当的互斥措施来保护共享资源。
可重入函数怎么编写
编写可重入函数(也称为可重入代码或线程安全函数)是确保在多线程环境下函数能够安全地被并发调用而不产生数据竞争或不可预测行为的关键。以下是一些编写可重入函数的基本指导原则:
避免使用全局变量和静态变量:
全局变量和静态变量在多线程环境中是共享的,因此如果不加以保护,就可能导致数据竞争。尽量避免在函数内部使用它们。
如果必须使用全局或静态变量,确保使用互斥锁(如互斥量、信号量或读写锁)来保护对这些变量的访问。
使用局部变量:
局部变量是线程私有的,因此不会引起数据竞争。尽可能地使用局部变量来存储函数执行过程中的中间结果。
不要调用不可重入的函数:
确保你的函数不调用任何不可重入的函数,例如标准库中的某些I/O函数或其他可能使用全局状态的函数。
避免使用某些库函数:
一些库函数,尤其是那些涉及I/O操作或静态内存分配的函数,可能不是线程安全的。查阅相关文档以确定哪些函数是线程安全的,并避免使用那些不是线程安全的函数。
使用线程局部存储(Thread-Local Storage, TLS):
如果确实需要某种形式的持久性状态,并且这个状态需要在多个函数调用之间保持,可以考虑使用线程局部存储。这样,每个线程都会拥有自己独立的变量副本,从而避免了数据竞争。
使用原子操作:
对于简单的、不涉及复杂数据结构或大量计算的共享变量访问,可以使用原子操作来确保操作的原子性。原子操作通常提供对单个变量或内存位置的不可分割的访问。
确保函数的可重入性经过测试:
编写单元测试和多线程测试来验证函数的可重入性。确保在不同线程中同时调用该函数时不会产生错误的结果或行为。
下面是一个简单的可重入函数示例,它使用局部变量来避免数据竞争:
c
#include <stdio.h>
#include <stdlib.h>
// 假设这是一个线程安全的锁函数
void lock(void);
// 假设这是一个线程安全的解锁函数
void unlock(void);
// 可重入函数示例
int safe_increment(int *counter) {
int local_copy;
lock(); // 获取锁以保护对counter的访问
local_copy = *counter;
local_copy++;
*counter = local_copy;
unlock(); // 释放锁
return local_copy;
}
在这个示例中,safe_increment 函数使用了一个局部变量 local_copy 来存储 counter 的当前值,对其进行递增操作,然后再将结果写回 counter。在访问 counter 的过程中,使用了 lock 和 unlock 函数来保护对它的访问,确保同一时间只有一个线程能够修改 counter 的值。
请注意,上述示例中的 lock 和 unlock 函数需要是线程安全的,并且在实际应用中可能需要使用具体的同步原语(如互斥量)来实现。此外,具体的同步机制的选择和实现将取决于你所使用的编程语言和线程库。
可重入函数和不可重入函数的优缺点
可重入函数和不可重入函数在多任务环境中各有其优缺点。他们是是函数的一种特征,目前我们用的90%函数,都是不可重入的。
可重入函数的优点主要体现在:
灵活性:可重入函数通过在函数内部调用自身,可以提高程序实现的灵活性,实现多种重叠功能,如大量的并发任务处理、fork/join模式或服务器/客户端系统。
稳定性:可重入函数使得程序更加稳定,因为它可以用于错误控制。当发生错误时,可以直接把调用过程重复执行,实现异常情况的处理。
代码重用性:可重入函数能够大大减少函数的代码量,使代码更加紧凑,更易于理解和维护,提高了代码的可重用性。
运行效率:在一些特定情况下,如逐步累加的操作中,可重入函数的使用可以提高编译器的优化效果,从而提高程序的运行效率。
然而,不可重入函数在某些情况下也有其使用的价值,但它们的缺点也很明显:
安全性问题:不可重入函数由于使用了未受保护的系统资源,如全局变量区或中断向量表,因此在多任务环境下可能会引发数据竞争和不可预测的行为,这被视为不安全函数。
限制使用场景:不可重入函数不能运行在多任务环境中,除非能保证互斥,这限制了它们的使用范围。
综上所述,可重入函数和不可重入函数各有其适用场景和优缺点。在选择使用哪种函数时,需要根据具体的程序需求、运行环境以及资源使用情况进行综合考虑。
优化/不优化的代码运行结果
编译器有时候会自动的给我们进行代码优化;一些程序员写Makefile的时候会添加选项让编译时进行优化;
不加优化选项 -fpermissive是为了类型抓换不让报错(我们就想这么操作)这个选项在本文无用,这个makefile是上篇文章讲信号时用的
加优化选项

优化后程序变大了

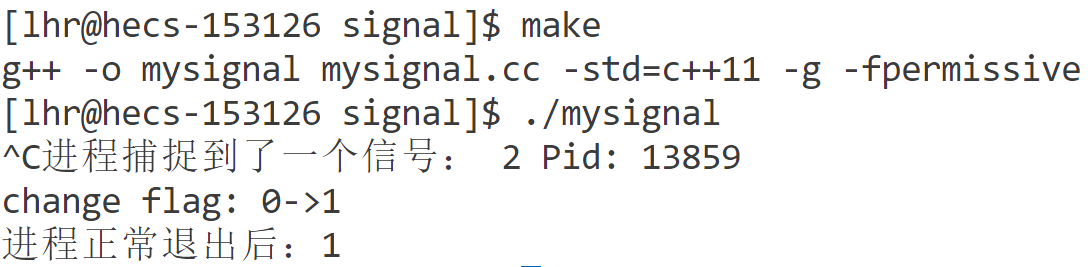
对flag进行volatile修饰后
volatile ⇒ 保持内存的可见性,告知编译器,被该关键字修饰的变量,不允许被优化,对该变量
的任何操作,都必须在真实的内存中进行操作

对上述场景的认识和解读
编译器在编译过程中监测到变量flag在主控制流main的整个执行过程中都未发生变化【主观臆断】,所以将其优化为寄存器变量。导致while语句的每次条件判断都是直接取寄存器中的值,而遮盖了flag在内存中的数据。即使进程收到2号信号后(中断处理)将flag在内存中的数值改为1,但寄存器数据被初始化为0且不发生改变,所以程序仍然保持循环,不会退出。 ⇒ 因为优化使得cpu在执行while时为了更快从寄存器读flag的值而没有从内存的实时最新值导致了错误。
“优化”的这个动作是发生在什么时候的?
发生在编译的时候。cpu只管执行和运算,不会进行代码的优化,他也没有这个能力。
volatile关键字的简述
volatile关键字在编程中,特别是Java编程中,起着非常重要的作用。volatile是Java虚拟机提供的一种轻量级的同步机制,它主要具有以下三个作用:
保证可见性:volatile关键字确保所有线程都能看到某个变量的最新值。当一个线程修改了一个被volatile修饰的共享变量时,其他线程能立即感知到这个修改,从而确保所有线程对这个变量的访问都是一致的。这有助于避免多线程环境下的数据竞争问题。
保证有序性:volatile关键字还能保证代码的执行顺序。对于volatile修饰的变量,volatile之前的代码不能调整到它的后面,volatile之后的代码也不能调整到它的前面。这有助于防止编译器优化时可能导致的指令重排问题。
禁止指令重排:volatile关键字可以禁止编译器对内存操作的指令进行重排优化,确保指令按照程序员期望的顺序执行。
需要注意的是,虽然volatile关键字提供了上述的同步机制,但它并不能保证原子性。也就是说,volatile并不能保证复合操作的原子性,例如自增操作(i++)等。因此,在需要保证原子性的场景中,还需要使用其他的同步机制,如synchronized关键字或Lock接口的实现类。
总的来说,volatile关键字是Java多线程编程中一个非常重要的工具,它可以帮助开发者在多线程环境下正确地处理共享变量的访问和修改,确保程序的正确性和稳定性。
C/CPP下volatile关键字的简述
在C和C++编程语言中,volatile关键字用于告知编译器某个变量可能会被程序无法控制的因素(如操作系统、硬件或其他并发执行的线程)改变。使用volatile关键字可以防止编译器对这些变量进行某些优化,从而确保每次从变量中读取值时都直接从内存中读取,而不是从可能被编译器优化的缓存中读取。
具体来说,volatile关键字的主要作用包括:
防止编译器优化:编译器在优化代码时,可能会将变量的值存储在寄存器中,以便更快地访问。然而,如果变量在程序执行期间可能被其他因素改变,那么从寄存器中读取的值可能就不再是最新的。使用volatile关键字可以阻止编译器进行这种优化,确保每次访问变量时都从内存中读取最新的值。
保证可见性:在多线程环境中,一个线程对volatile变量的修改对其他线程是可见的。这有助于避免由于线程间通信延迟或缓存不一致而导致的数据竞争问题。
不保证原子性:虽然volatile关键字可以确保变量的可见性,但它并不保证对变量的操作是原子的。也就是说,对于涉及多个步骤的复合操作(如自增或自减),即使使用了volatile关键字,也可能在多线程环境下出现竞态条件。在这种情况下,还需要使用其他的同步机制(如互斥锁或原子操作)来确保操作的原子性。
在C语言中,volatile是一个关键字,用于声明一个变量是“易变的”(volatile)。
当一个变量被声明为volatile时,编译器会确保对该变量的读写操作不会被优化、保持内存可见性。这是因为volatile变量的值可能会被意外地改变,例如由于硬件操作、中断处理程序或者其他线程的影响。
使用volatile关键字的主要场景包括:
并行处理:当多个线程或者进程共享一个变量时,如果这个变量可能会被其他线程或者进程改变,那么应该将这个变量声明为volatile,以确保每次读取时都是从内存中读取而不是使用缓存值。
中断处理:在中断处理程序中,通常需要访问硬件寄存器或者其他外部设备。由于这些设备的状态可能会在任何时候发生变化,因此必须将相关的变量声明为volatile,以确保每次访问都是从内存中读取最新的值。
优化禁用:有些变量的值可能会被外部因素改变,但是编译器无法检测到这种改变,因此可能会对这些变量进行优化。通过将这些变量声明为volatile,可以告诉编译器不要对这些变量进行优化。
需要注意的是,过度使用volatile关键字可能导致性能下降,因为编译器无法对某些操作进行优化。因此,在使用volatile关键字时应该谨慎,确保只在确实需要的情况下使用它。
总之,volatile关键字在C和C++编程中用于处理可能被程序无法控制的因素改变的变量,确保从变量中读取的值始终是最新的,并在多线程环境中提供可见性保证。然而,它并不保证操作的原子性,因此在需要确保原子性的情况下还需要使用其他同步机制。
2.认识SIGCHILD信号
回顾什么是僵尸进程
僵尸进程(Zombie Process)是在Unix/Linux系统中已经终止运行,但其父进程尚未对其进行善后处理(获取终止状态以及资源清理)的进程。这些进程不占用除进程表外的任何系统资源,但仍然会在进程表中占据一个位置。由于进程表有大小限制,因此如果系统中的僵尸进程过多,就可能导致无法创建新的进程。
僵尸进程的形成原因通常是因为父进程在fork子进程后,子进程先于父进程退出,而父进程没有对子进程进行wait或waitpid操作,导致子进程的进程描述符仍然留在系统中。
为了避免僵尸进程的问题,有几种解决方案:
父进程使用wait()或waitpid()系统调用来获取子进程的结束状态,并释放其占用的资源。
使用信号机制,让父进程在接收到子进程结束的信号时,调用wait()或waitpid()来处理子进程。
如果父进程不关心子进程的结束状态,可以将其设置为忽略SIGCHLD信号,这样当子进程结束时,内核会自动回收其资源,不会产生僵尸进程。
需要注意的是,僵尸进程本身并不危害系统安全,它们只是占用了进程表的位置。但是,如果系统中的僵尸进程数量过多,可能会影响到系统的性能和新进程的创建。因此,在编写涉及多进程的程序时,应妥善处理子进程的结束状态,避免产生过多的僵尸进程。
进程等待交互进程信号
进程一章讲过用wait和waitpid函数清理僵尸进程,父进程可以阻塞等待子进程结束,也可以非阻塞地查询是否有子进程结束等待清理(也就是轮询的方式)。采用第一种方式,父进程阻塞了就不能处理自己的工作了,采用第二种方式,父进程在处理自己的工作的同时还要记得时不时地轮询一 下,程序不是最优。
其实,子进程在终止时会给父进程发SIGCHLD信号,该信号的默认处理动作是忽略,父进程可以自定义SIGCHLD信号的处理函数,这样父进程只需专心处理自己的工作,不必关心子进程了,子进程终止时会通知父进程,父进程在信号处理函数中调用wait清理子进程即可。
事实上,由于UNIX 的历史原因,要想不产生僵尸进程还有另外一种办法:父进程调用sigaction将SIGCHLD的处理动作置为SIG_IGN,这样fork出来的子进程在终止时会自动清理掉,不会产生僵尸进程,也不会通知父进程。系统默认的忽略动作和用户用sigaction函数自定义的忽略通常是没有区别的,但这是一个特例。此方法对于Linux可用,但不保证在其它UNIX系统上都可用。
认识SIGCHILD信号
SIGCHLD(17)信号是在一个子进程终止或停止时由操作系统发送给其父进程的信号。它是一个通知父进程子进程状态改变的信号。父进程可以通过捕捉SIGCHLD信号,并使用相应的信号处理函数来处理子进程的状态改变。
SIGCHLD信号的处理方式:
- 忽略信号(默认处理)【OS级别】:SIGCHLD信号的默认处理方法就是忽略(ign)。但是如果父进程不主动去等待子进程,子进程会变为僵尸进程一直等待父进程获取其退出状态。
- 忽略信号(手动设置)【用户级别】:通过signal或sigaction函数手动的选择忽略SIGCHLD信号(SIG_IGN),这样系统会直接回收子进程资源,释放僵尸进程。不再需要父进程等待子进程了。通常用于父进程不关心子进程退出状态的情况。
- 捕捉信号:父进程通过注册一个SIGCHLD信号处理函数来捕捉SIGCHLD信号。当子进程终止或停止时,操作系统会调用该信号处理函数。
- 阻塞信号:父进程可以选择在某些时候阻塞SIGCHLD信号,以延迟对子进程状态改变的处理。这可以通过调用sigprocmask函数设置信号屏蔽字来实现。
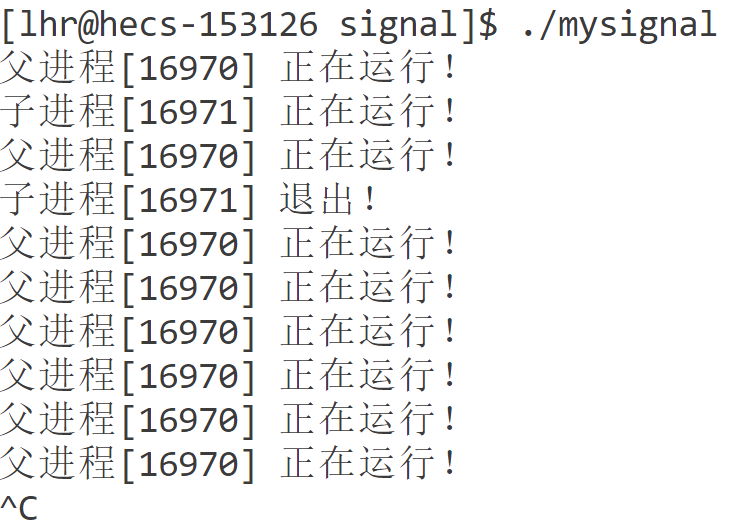
测试1:忽略信号(默认处理)
忽略信号(默认处理):SIGCHLD信号的默认处理方法就是忽略(ign)。但是如果父进程不主动去等待子进程,子进程会变为僵尸进程一直等待父进程获取其退出状态。
#include <iostream>
#include <unistd.h>
#include <signal.h>
#include <cassert>
using namespace std;
int main()
{
pid_t id = fork();
assert(id != -1);
if (id == 0)
{
cout << "子进程[" << getpid() << "] 正在运行!" << endl;
sleep(1);
cout << "子进程[" << getpid() << "] 退出!" << endl;
exit(0);
}
while (true)
{
cout << "父进程[" << getpid() << "] 正在运行!" << endl;
sleep(1);
}
return 0;
}

测试2:忽略信号(手动设置)
忽略信号(手动设置):通过signal或sigaction函数手动的选择忽略SIGCHLD信号(SIG_IGN),这样系统会直接回收子进程资源,释放僵尸进程。不再需要父进程等待子进程了。通常用于父进程不关心子进程退出状态的情况。
#include <iostream>
#include <unistd.h>
#include <signal.h>
#include <cassert>
#include <sys/types.h>
#include <sys/wait.h>
using namespace std;
int main()
{
signal(SIGCHLD, SIG_IGN);
pid_t id = fork();
assert(id != -1);
if (id == 0)
{
cout << "子进程[" << getpid() << "] 正在运行!" << endl;
sleep(1);
cout << "子进程[" << getpid() << "] 退出!" << endl;
exit(0);
}
while (true)
{
cout << "父进程[" << getpid() << "] 正在运行!" << endl;
sleep(1);
}
return 0;
}
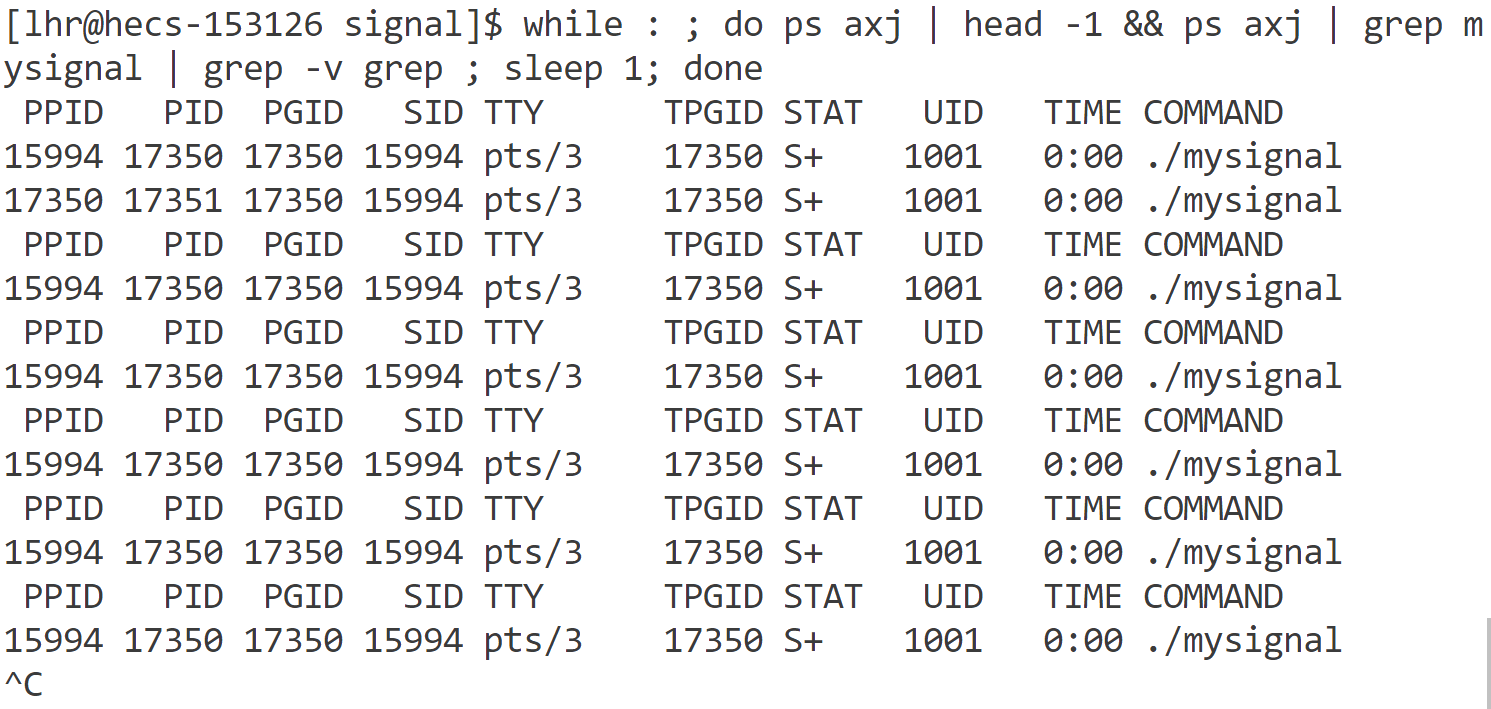
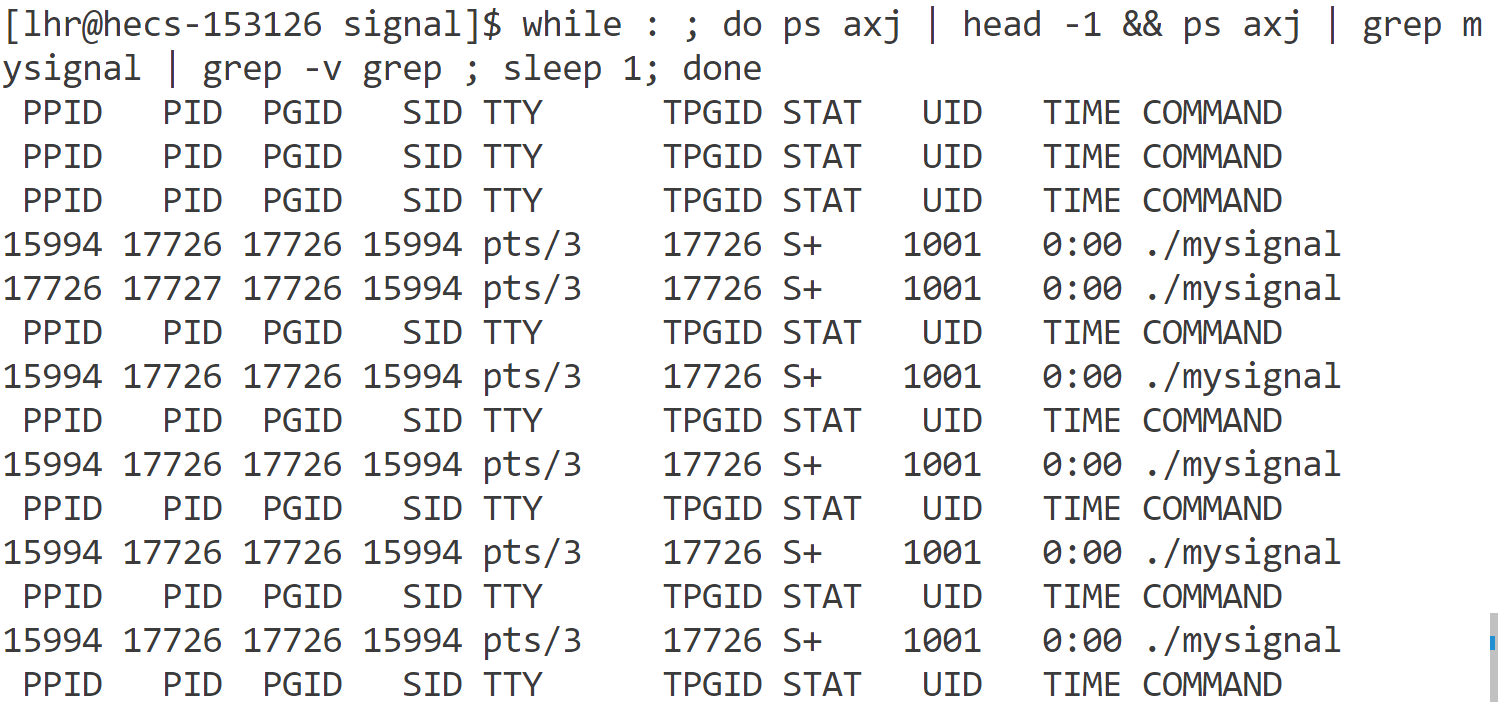
测试3:捕捉信号
- 父进程通过注册一个SIGCHLD信号处理函数来捕捉SIGCHLD信号。当子进程终止或停止时,操作系统会调用该信号处理函数。
- 当父进程收到SIGCHLD(17)信号时,只是知道某些子进程的状态发生了改变,不能确定:
特别注意:如果同一时间有多个子进程退出,由于SIGCHILD的比特位只有一个,他最多只能记录一个信号的存无。所以父进程收到了SIGCHILD他并不知道有几个子进程退出,所以如果在信号处理函数中不信号等待,那么同时退出的其他几个子进程就无法获取他们的退出状态导致僵尸进程的出现。
有多少个子进程退出;⇒ while循环等待多个进程退出,直到获取完所有退出进程的退出状态。
哪个子进程退出了;⇒ waitpid的第一个参数传-1表示等待任意一个子进程退出。
子进程到底是终止还是暂停 ⇒ waitpid的第三个参数传WNOHANG采用非阻塞等待,否则如果没有子进程退出,父进程将阻塞等待
#include <iostream>
#include <unistd.h>
#include <signal.h>
#include <cassert>
#include <sys/types.h>
#include <sys/wait.h>
using namespace std;
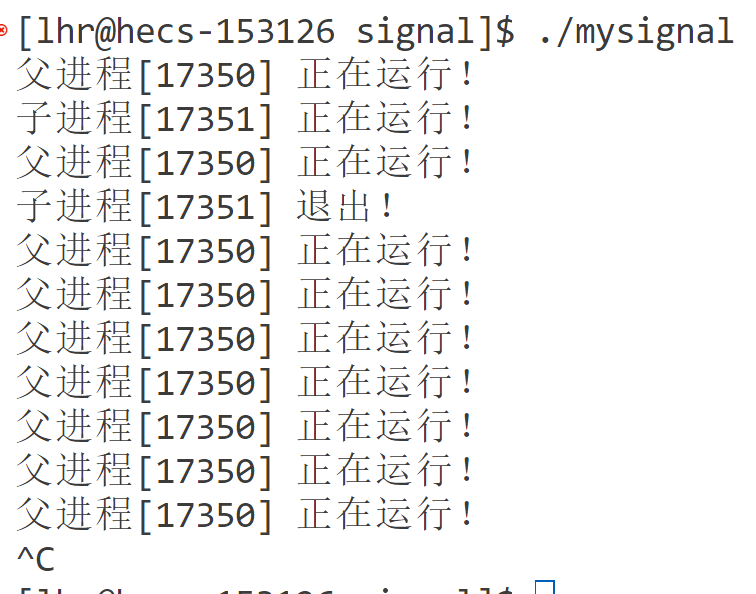
void handler(int signum)
{
cout << "进程[" << getpid() << "] 捕获了一个信号(" << signum << ")" << endl;
pid_t child_pid = 0;
while ((child_pid = waitpid(-1, nullptr, WNOHANG)) > 0)
{
cout << "father: "
<< "子进程[" << child_pid << "] 退出!" << endl;
}
}
int main()
{
signal(SIGCHLD, handler);
pid_t id = fork();
assert(id != -1);
if (id == 0)
{
cout << "子进程[" << getpid() << "] 正在运行!" << endl;
sleep(1);
cout << "子进程[" << getpid() << "] 退出!" << endl;
exit(0);
}
while (true)
{
cout << "父进程[" << getpid() << "] 正在运行!" << endl;
sleep(1);
}
return 0;
}

3.普通信号/实时信号
Linux进程间通信中的信号是一种软件中断机制,用于处理异步通信和响应突发事件。在Linux中,信号分为普通信号(也称为常规信号或标准信号)和实时信号两大类。以下是它们之间的异同点:
相同点:
命名和编号:普通信号和实时信号都遵循以SIG开头的命名规则,并且在头文件signal.h中定义为正整数常量(信号编号)。
处理机制:进程可以通过三种方式来响应信号:忽略信号、捕捉信号和执行缺省操作。无论是普通信号还是实时信号,进程对信号的处理方式都取决于传递给相应API函数的参数。
不同点:
信号范围与用途:普通信号的信号范围相对较小,主要用于系统级操作,如SIGKILL用于强制终止进程,SIGSTOP用于暂停进程等。而实时信号的信号范围有所扩大,可应用于程序自定义的目的,提供了更多的灵活性。
投递方式:普通信号的投递顺序是未定义的,且信号不排队,可能会丢失。而实时信号采取的是队列化管理,如果某一个信号多次发送给一个进程,那么该进程会多次收到这个信号,保证了信号的完整性和顺序性。
伴随数据:发送实时信号时,可以为信号指定伴随数据,供接收进程的信号处理器使用。虽然现代Linux系统也允许为标准信号指定伴随数据,但这一特性在实时信号中更为常见和强调。
优先级:对于实时信号,不同的信号传递顺序是有保障的,通常信号的编号越小,优先级越高。而普通信号的传递顺序则是未定义的,取决于具体的实现。
综上所述,普通信号和实时信号在Linux进程间通信中各有其特点和用途。普通信号主要用于系统级操作,而实时信号则提供了更大的灵活性和可靠性,特别适用于需要处理大量异步事件和保证信号顺序的场景。
为什么在linux下man 7 signal显示的信号类型中,有些信号的数字表示有多个?
Signal Value Action Comment
──────────────────────────────────────────────────────────────────────
SIGHUP 1 Term Hangup detected on controlling terminal
or death of controlling process
SIGINT 2 Term Interrupt from keyboard
SIGQUIT 3 Core Quit from keyboard
SIGILL 4 Core Illegal Instruction
SIGABRT 6 Core Abort signal from abort(3)
SIGFPE 8 Core Floating point exception
SIGKILL 9 Term Kill signal
SIGSEGV 11 Core Invalid memory reference
SIGPIPE 13 Term Broken pipe: write to pipe with no
readers
SIGALRM 14 Term Timer signal from alarm(2)
SIGTERM 15 Term Termination signal
SIGUSR1 30,10,16 Term User-defined signal 1
SIGUSR2 31,12,17 Term User-defined signal 2
SIGCHLD 20,17,18 Ign Child stopped or terminated
SIGCONT 19,18,25 Cont Continue if stopped
SIGSTOP 17,19,23 Stop Stop process
SIGTSTP 18,20,24 Stop Stop typed at terminal
SIGTTIN 21,21,26 Stop Terminal input for background process
SIGTTOU 22,22,27 Stop Terminal output for background process
The signals SIGKILL and SIGSTOP cannot be caught, blocked, or ignored.
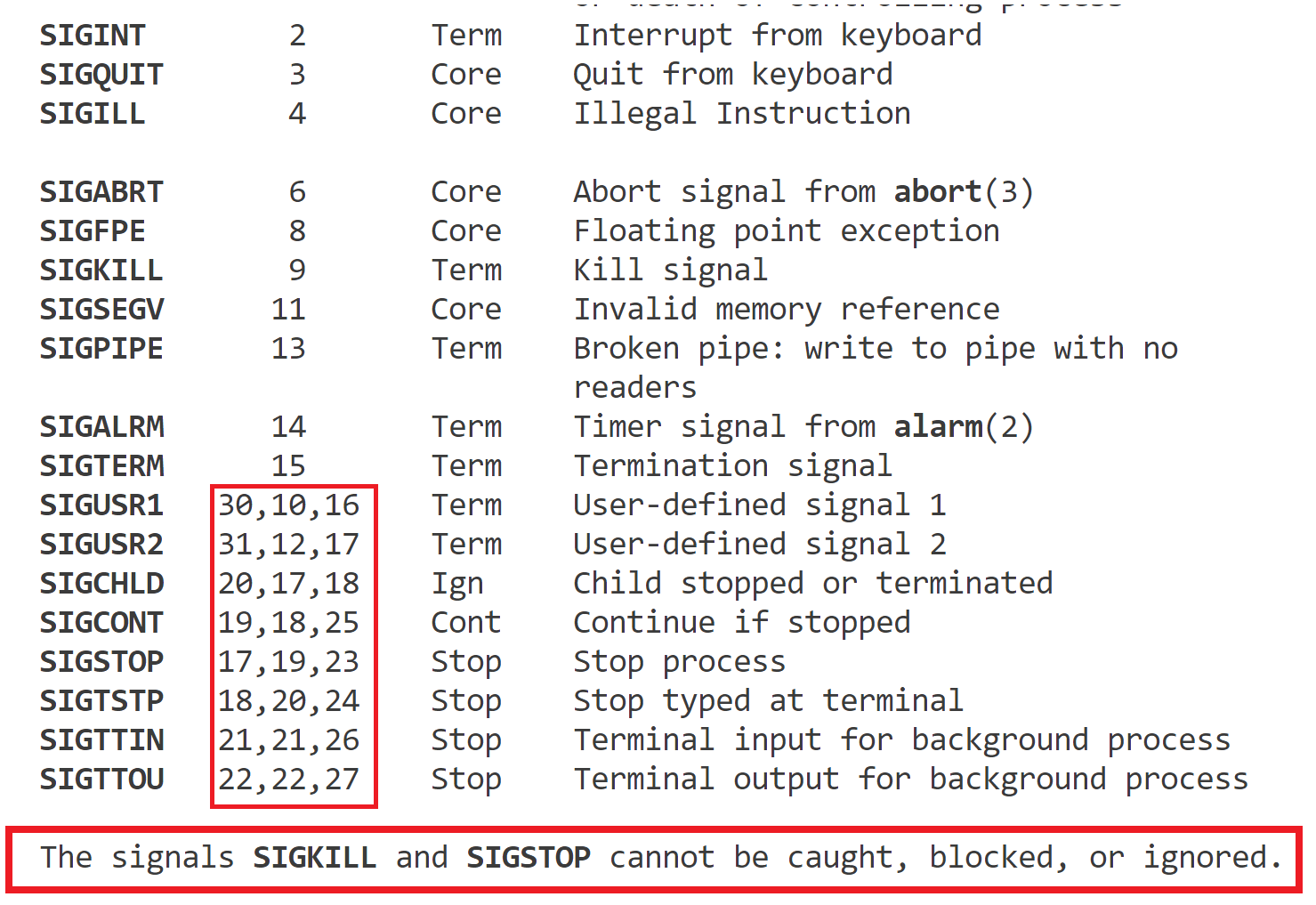
在Linux下,当你使用man 7 signal命令查看信号时,可能会发现某些信号的数字表示有多个。这通常是因为不同的系统或架构可能为某些信号分配了不同的数字。尽管大部分信号的数字表示在Unix和类Unix系统(包括Linux)中是一致的,但仍然存在一些差异。
以下是一些可能导致信号数字表示有多个的原因:
架构差异:不同的硬件架构(如x86、ARM、MIPS等)可能会为某些信号分配不同的数字。这是因为不同的架构可能有不同的中断机制和处理方式,因此需要为信号分配不同的数字以适应这些差异。
历史原因:Unix和类Unix系统的发展历史悠久,不同的版本和分支可能在不同的时间点引入了新的信号或修改了现有信号的数字表示。因此,在某些系统中,某些信号可能具有不同的数字表示。
兼容性考虑:为了确保与旧版本的应用程序或系统的兼容性,某些系统可能保留了旧的信号数字表示。这样,即使在新版本的系统中引入了新的信号或修改了信号的数字表示,旧的应用程序仍然能够正常工作。
当你看到man 7 signal中某些信号有多个数字表示时,通常意味着这些数字表示对应于不同的系统或架构。在实际编程中,为了编写可移植的代码,最好使用信号的宏名称(如SIGINT、SIGTERM等)而不是直接使用数字表示。这样可以确保代码在不同的系统和架构上都能正确工作。
需要注意的是,尽管某些信号可能有多个数字表示,但它们的语义和功能通常是相同的。因此,在理解和使用这些信号时,你应该关注它们的名称和描述,而不是仅仅关注它们的数字表示。