说明
最实用的一种利用大语言模型的方式是进行微调。预训练模型与我们的使用场景一定会存在一些差异,而我们又不可能重头训练。
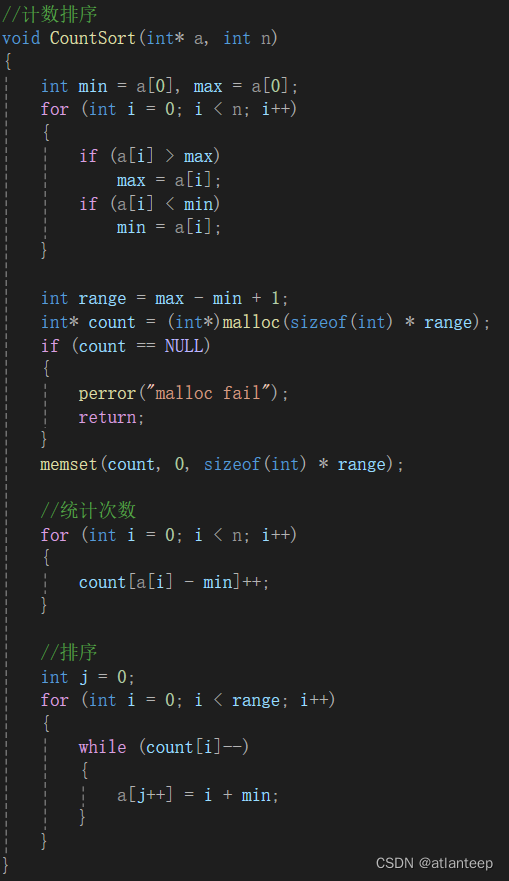
微调的原理并不复杂,载入模型,灌新的数据,然后运行再训练,保留checkpoints。但是不同项目的代码真的不太一样,每一个都要单独去看的话比较费神。
本篇简单讨论一下用LLaMA-Factory微调模型的体验。
内容
1 LLaMA-Factory
LLaMA-Factory(https://github.com/hiyouga/LLaMA-Factory)是零隙智能(SeamLessAI)开源的低代码大模型训练框架,它集成了业界最广泛使用的微调方法和优化技术,并支持业界众多的开源模型的微调和二次训练,开发者可以使用私域数据、基于有限算力完成领域大模型的定制开发。LLaMA-Factory还为开发者提供了可视化训练、推理平台,一键配置模型训练,实现零代码微调LLM。自2023年5月开源以来,成为社区内最受欢迎的微调框架,github星数已超9K。
github项目地址
从目前的开源三大系(LLaMA, ChatGLM, BLOOM )来看,数量上的确还是Lamma系的多。

2 部署环境
用仙宫云部署,价格比较实惠,且环境比较新。
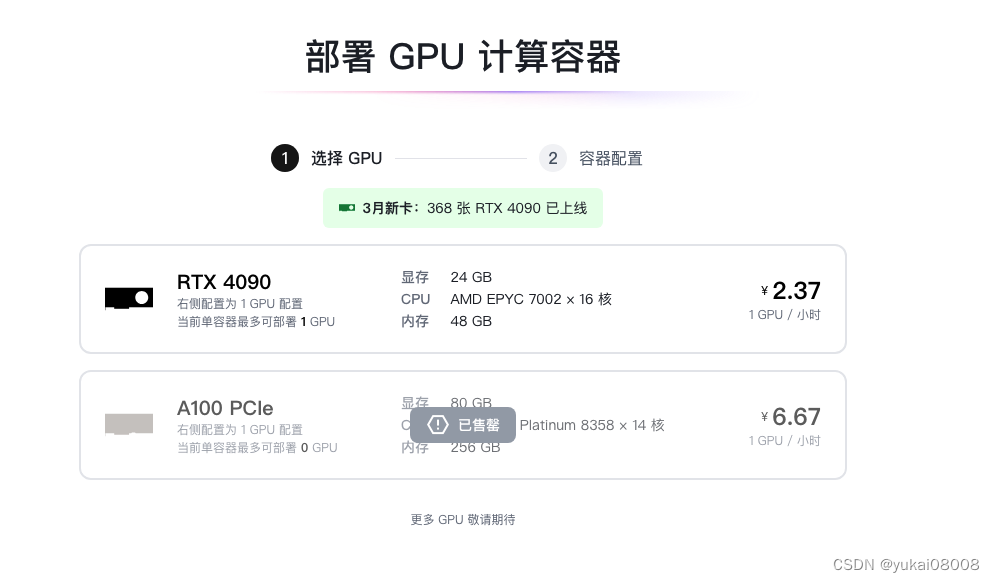
注意,云盘默认挂在 /root/cloud下,所以文件可以存在这里。
3 拉取项目并启动服务
由于环境基本已经适配好的,安装过程也很快
git clone https://github.com/hiyouga/LLaMA-Factory.git
cd LLaMA-Factory
pip3 install -r requirements.txt -i https://mirrors.aliyun.com/pypi/simple/
然后执行web前端的启动命令
python3 ./scr/train_web.py
就会唤起一个前端(因为服务已经关掉了,忘了截图)
4 拉取模型文件
我使用chatglm3-6b-base进行测试。
由于hugging face有墙, modelscope就是比较好的选择。
两种方式:
包方式:事实证明不是那么好,模型包存放的位置还要靠grep找出来
pip install modelscope
from modelscope import snapshot_download
model_dir = snapshot_download("ZhipuAI/chatglm3-6b", revision = "v1.0.0")
git方式
git lfs install
git clone https://www.modelscope.cn/ZhipuAI/chatglm3-6b.git
5 在web端配置
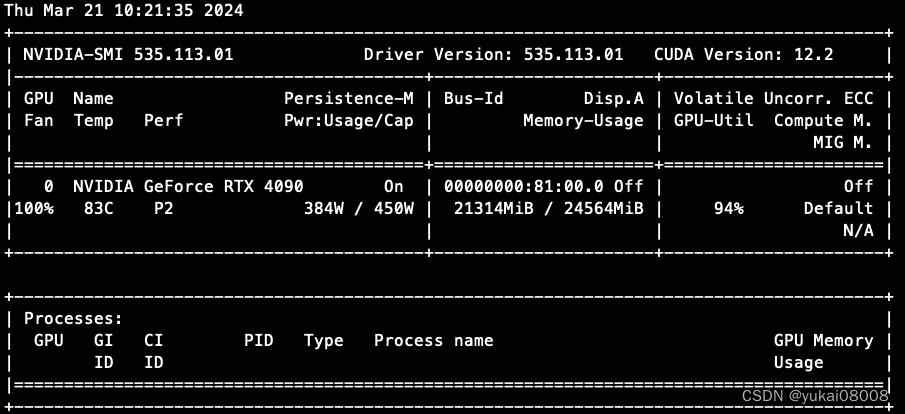
本次是连通性测试,我就修改了一下模型所在的文件夹位置,然后选择lora,别的都没改,就开始跑了。
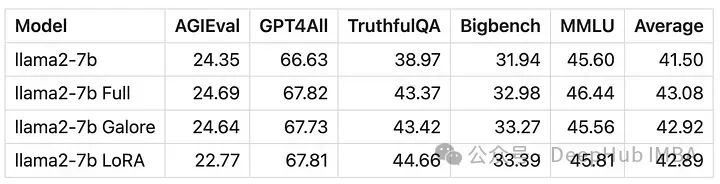
整个微调的时间大约在4小时,期间显存慢慢上升到21G,总体上应该是可用的。
今天主要就是调通,后续再更新。